Driver installation
editDriver installation
editThe Elasticsearch SQL ODBC Driver can be installed on Microsoft Windows using an MSI package. The installation process is simple and is composed of standard MSI wizard steps.
Installation Prerequisites
editThe recommended installation platform is Windows 10 64 bit or Windows Server 2016 64 bit.
Before you install the Elasticsearch SQL ODBC Driver you need to meet the following prerequisites;
- .NET Framework 4.0 full - https://www.microsoft.com/en-au/download/details.aspx?id=17718
-
Microsoft Visual C++ Redistributable for Visual Studio 2017 - https://support.microsoft.com/en-au/help/2977003/the-latest-supported-visual-c-downloads
- The 64 bit driver requires the x64 redistributable
- The 32 bit driver requires the x86 or the x64 redistributable (the latter also installs the components needed for the 32 bit driver)
- Elevated privileges (administrator) for the User performing the installation.
If you fail to meet any of the prerequisites the installer will show an error message and abort the installation.
It is not possible to inline upgrade using the MSI. In order to upgrade, you will first have to uninstall the old driver and then install the new driver.
When installing the MSI, the Windows Defender SmartScreen might warn
about running an unrecognized app. If the MSI has been downloaded from
Elastic’s web site, it is safe to acknowledge the message by allowing the
installation to continue (Run anyway).
Download the .msi package(s)
editDownload the .msi package for Elasticsearch SQL ODBC Driver 7.7.1 from:
https://www.elastic.co/downloads/odbc-client
There are two versions of the installer available:
- 32 bit driver (x86) for use with the Microsoft Office 2016 suite of applications; notably Microsoft Excel and Microsoft Access and other 32 bit based programs.
- 64 bit driver (x64) recommended for use with all other applications.
Users should consider downloading and installing both the 32 and 64 bit drivers for maximum compatibility across applications installed on their system.
Installation using the graphical user interface (GUI)
editDouble-click the downloaded .msi package to launch a GUI wizard that will guide you through the installation process.
You will first be presented with a welcome screen:
Clicking Next will present the End User License Agreement. You will need to accept the license agreement in order to continue the installation.
The following screen allows you to customise the installation path for the Elasticsearch ODBC driver files.
The default installation path is of the format: %ProgramFiles%\Elastic\ODBCDriver\7.7.1
You are now ready to install the driver.
You will require elevated privileges (administrator) for installation.
Assuming the installation takes place without error you should see progress screen, followed by the finish screen:
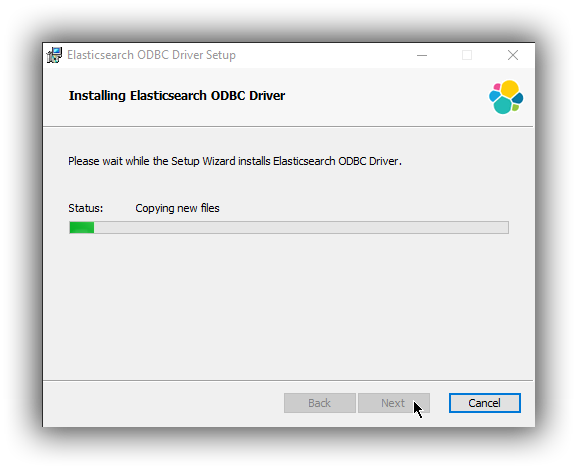
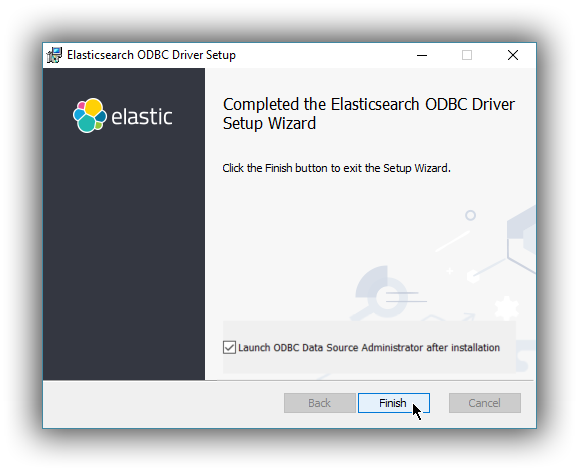
On the finish screen you can launch the ODBC Data Source Administration screen by checking the dialog checkbox. This will automatically launch the configuration screen on close (either 32 bit or 64 bit) where you can configure a DSN.
As with any MSI installation package, a log file for the installation process can be found within the %TEMP% directory, with a randomly generated name adhering to the format MSI<random>.LOG.
If you encounter an error during installation we would encourage you to open an issue https://github.com/elastic/elasticsearch-sql-odbc/issues, attach your installation log file and provide additional details so we can investigate.
Installation using the command line
editThe examples given below apply to installation of the 64 bit MSI package. To achieve the same result with the 32 bit MSI package you would instead use the filename suffix windows-x86.msi
The .msi can also be installed via the command line. The simplest installation using the same defaults as the GUI is achieved by first navigating to the download directory, then running:
msiexec.exe /i esodbc-7.7.1-windows-x86_64.msi /qn
By default, msiexec.exe does not wait for the installation process to complete, since it runs in the Windows subsystem. To wait on the process to finish and ensure that %ERRORLEVEL% is set accordingly, it is recommended to use start /wait to create a process and wait for it to exit:
start /wait msiexec.exe /i esodbc-7.7.1-windows-x86_64.msi /qn
As with any MSI installation package, a log file for the installation process can be found within the %TEMP% directory, with a randomly generated name adhering to the format MSI<random>.LOG. The path to a log file can be supplied using the /l command line argument
start /wait msiexec.exe /i esodbc-7.7.1-windows-x86_64.msi /qn /l install.log
Supported Windows Installer command line arguments can be viewed using:
msiexec.exe /help
…or by consulting the Windows Installer SDK Command-Line Options.
Command line options
editAll settings exposed within the GUI are also available as command line arguments (referred to as properties within Windows Installer documentation) that can be passed to msiexec.exe:
|
|
The installation directory.
Defaults to |
To pass a value, simply append the property name and value using the format <PROPERTYNAME>="<VALUE>" to
the installation command. For example, to use a different installation directory to the default one:
start /wait msiexec.exe /i esodbc-7.7.1-windows-x86_64.msi /qn INSTALLDIR="c:\CustomDirectory"
Consult the Windows Installer SDK Command-Line Options for additional rules related to values containing quotation marks.
Uninstall using Add/Remove Programs
editThe .msi package handles uninstallation of all directories and files added as part of installation.
Uninstallation will remove all contents created as part of installation.
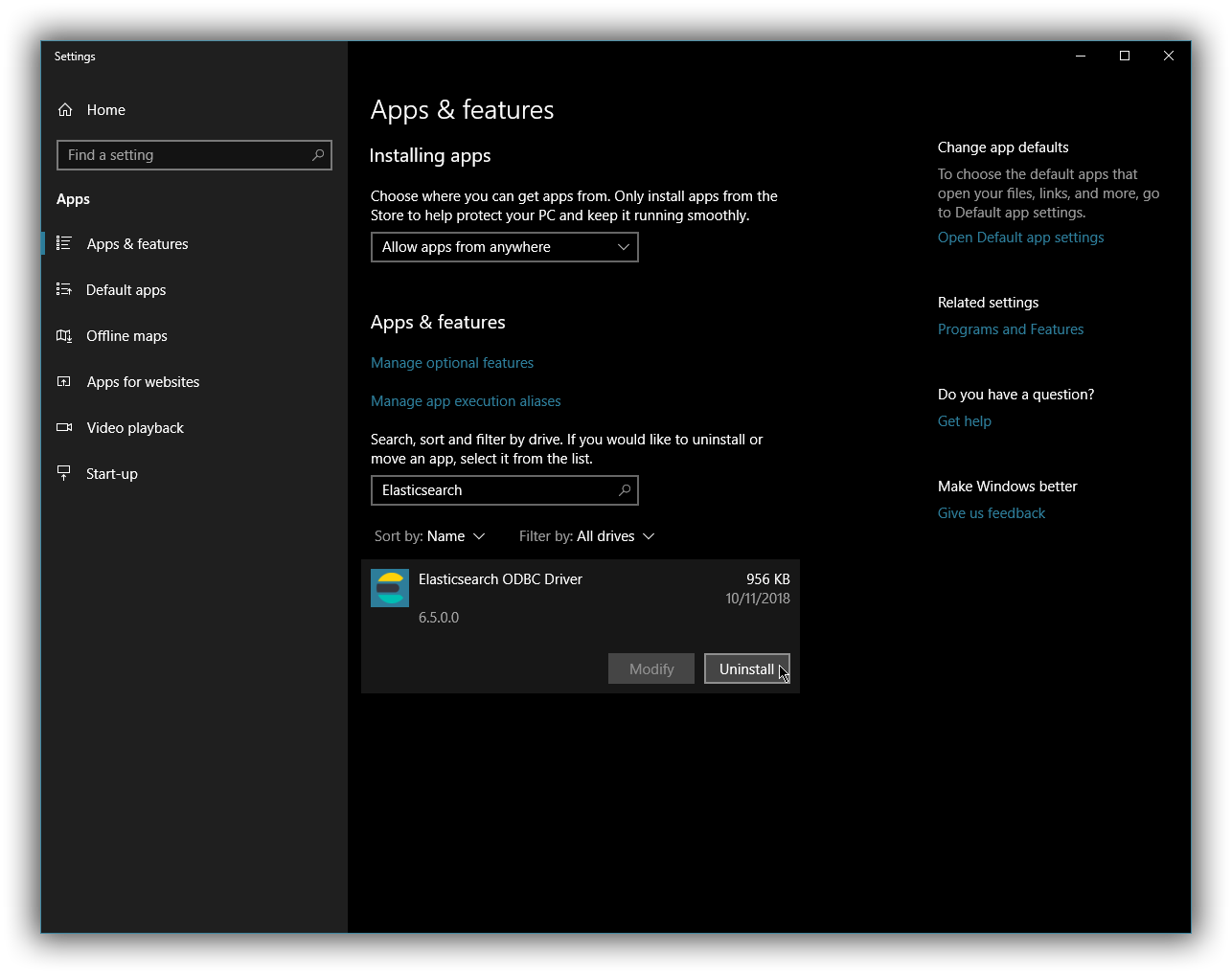
An installed program can be uninstalled by pressing the Windows key and typing add or remove programs to open the system settings.
Once opened, find the Elasticsearch ODBC Driver installation within the list of installed applications, click and choose Uninstall:
Uninstall using the command line
editUninstallation can also be performed from the command line by navigating to the directory
containing the .msi package and running:
start /wait msiexec.exe /x esodbc-7.7.1-windows-x86_64.msi /qn
Similar to the install process, a path for a log file for the uninstallation process can be passed using the /l command line argument
start /wait msiexec.exe /x esodbc-7.7.1-windows-x86_64.msi /qn /l uninstall.log