Actions
editActions
editWhen a watch’s condition is met, its actions are executed unless it is being throttled. A watch can perform multiple actions. The actions are executed one at a time and each action executes independently. Any failures encountered while executing an action are recorded in the action result and in the watch history.
If no actions are defined for a watch, no actions are executed.
However, a watch_record is still written to the watch history.
Actions have access to the payload in the execution context. They can use it to support their execution in any way they need. For example, the payload might serve as a model for a templated email body.
Watcher supports the following types of actions:
email, webhook, index,
logging, slack,
and pagerduty.
Acknowledgement and throttling
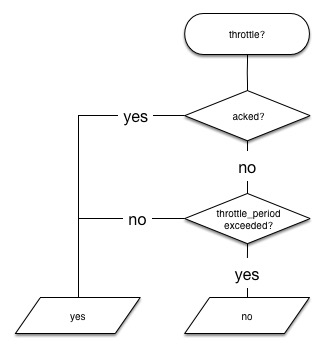
editDuring the watch execution, once the condition is met, a decision is made per configured action as to whether it should be throttled. The main purpose of action throttling is to prevent too many executions of the same action for the same watch.
For example, suppose you have a watch that detects errors in an application’s log entries. The watch is triggered every five minutes and searches for errors during the last hour. In this case, if there are errors, there is a period of time where the watch is checked and its actions are executed multiple times based on the same errors. As a result, the system administrator receives multiple notifications about the same issue, which can be annoying.
To address this issue, Watcher supports time-based throttling. You can define
a throttling period as part of the action configuration to limit how often the
action is executed. When you set a throttling period, Watcher prevents repeated
execution of the action if it has already executed within the throttling period
time frame (now - throttling period).
The following snippet shows a watch for the scenario described above - associating
a throttle period with the email_administrator action:
PUT _watcher/watch/error_logs_alert
{
"metadata" : {
"color" : "red"
},
"trigger" : {
"schedule" : {
"interval" : "5m"
}
},
"input" : {
"search" : {
"request" : {
"indices" : "log-events",
"body" : {
"size" : 0,
"query" : { "match" : { "status" : "error" } }
}
}
}
},
"condition" : {
"compare" : { "ctx.payload.hits.total" : { "gt" : 5 }}
},
"actions" : {
"email_administrator" : {
"throttle_period": "15m",
"email" : {
"to" : "[email protected]",
"subject" : "Encountered {{ctx.payload.hits.total}} errors",
"body" : "Too many error in the system, see attached data",
"attachments" : {
"attached_data" : {
"data" : {
"format" : "json"
}
}
},
"priority" : "high"
}
}
}
}
|
There will be at least 15 minutes between subsequent |
|
|
See Email action for more information. |
You can also define a throttle period at the watch level. The watch-level throttle period serves as the default throttle period for all of the actions defined in the watch:
PUT _watcher/watch/log_event_watch
{
"trigger" : {
"schedule" : { "interval" : "5m" }
},
"input" : {
"search" : {
"request" : {
"indices" : "log-events",
"body" : {
"size" : 0,
"query" : { "match" : { "status" : "error" } }
}
}
}
},
"condition" : {
"compare" : { "ctx.payload.hits.total" : { "gt" : 5 }}
},
"throttle_period" : "15m",
"actions" : {
"email_administrator" : {
"email" : {
"to" : "[email protected]",
"subject" : "Encountered {{ctx.payload.hits.total}} errors",
"body" : "Too many error in the system, see attached data",
"attachments" : {
"attached_data" : {
"data" : {
"format" : "json"
}
}
},
"priority" : "high"
}
},
"notify_pager" : {
"webhook" : {
"method" : "POST",
"host" : "pager.service.domain",
"port" : 1234,
"path" : "/{{watch_id}}",
"body" : "Encountered {{ctx.payload.hits.total}} errors"
}
}
}
}
|
There will be at least 15 minutes between subsequent action executions
(applies to both |
If you do not define a throttle period at the action or watch level, the global
default throttle period is applied. Initially, this is set to 5 seconds. To
change the global default, configure the xpack.watcher.execution.default_throttle_period
setting in elasticsearch.yml:
xpack.watcher.execution.default_throttle_period: 15m
Watcher also supports acknowledgement-based throttling. You can acknowledge a
watch using the ack watch API to prevent the
watch actions from being executed again while the watch condition remains true.
This essentially tells Watcher "I received the notification and I’m handling
it, please do not notify me about this error again". An acknowledged watch action
remains in the acked state until the watch’s condition evaluates to false.
When that happens, the action’s state changes to awaits_successful_execution.
To acknowledge an action, you use the ack watch API:
POST _watcher/watch/<id>/_ack/<action_ids>
Where <id> is the id of the watch and <action_ids> is a comma-separated list
of the action ids you want to acknowledge. To acknowledge all actions, omit the
actions parameter.
The following diagram illustrates the throttling decisions made for each action of a watch during its execution: