Collecting Elasticsearch monitoring data with Metricbeat
editCollecting Elasticsearch monitoring data with Metricbeat
editThis functionality is in beta and is subject to change. The design and code is less mature than official GA features and is being provided as-is with no warranties. Beta features are not subject to the support SLA of official GA features.
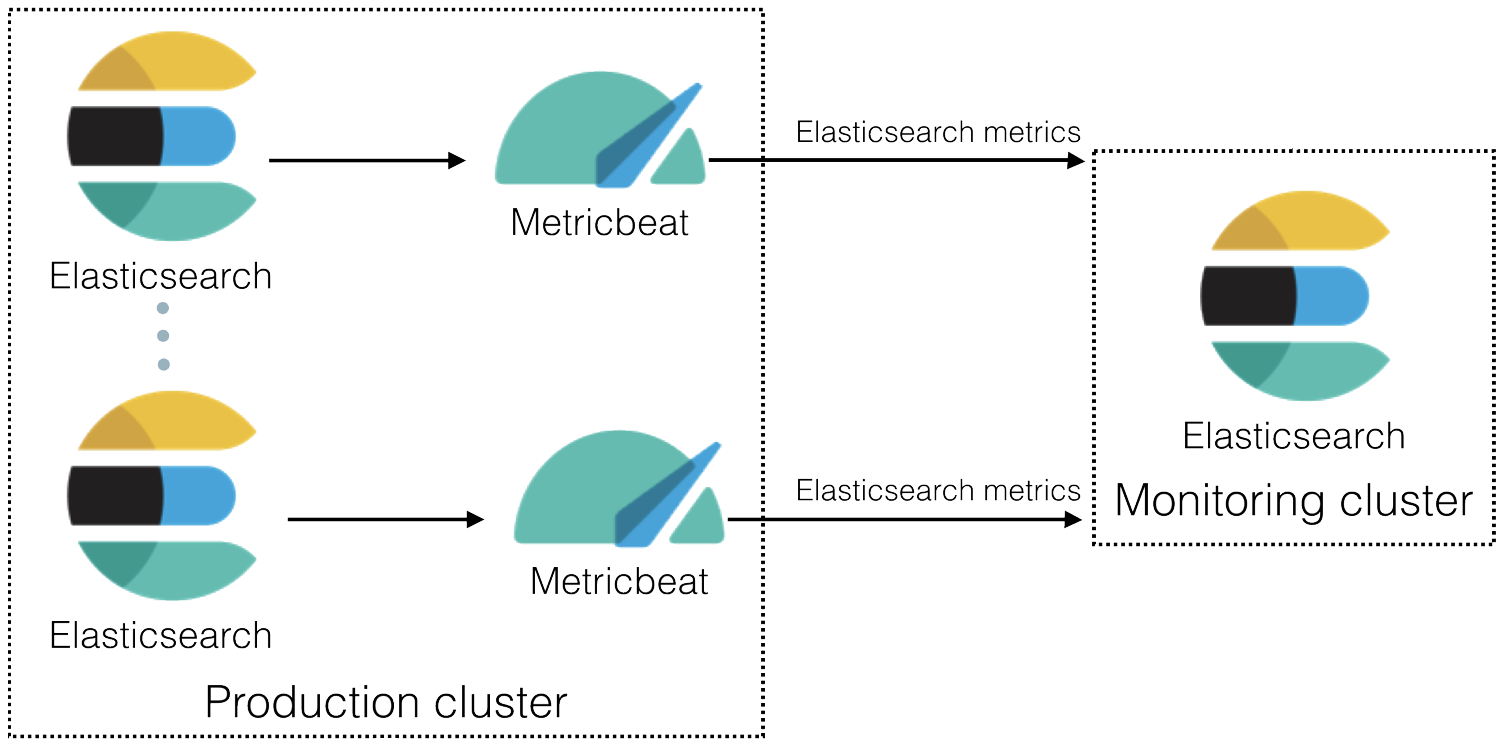
In 6.5 and later, you can use Metricbeat to collect data about Elasticsearch and ship it to the monitoring cluster, rather than routing it through exporters as described in Collecting monitoring data.
To learn about monitoring in general, see Monitoring the Elastic Stack.
-
Enable the collection of monitoring data. Set
xpack.monitoring.collection.enabledtotrueon each node in the production cluster. By default, it is is disabled (false).You can specify this setting in either the
elasticsearch.ymlon each node or across the cluster as a dynamic cluster setting. If Elasticsearch security features are enabled, you must havemonitorcluster privileges to view the cluster settings andmanagecluster privileges to change them.For example, you can use the following APIs to review and change this setting:
GET _cluster/settings PUT _cluster/settings { "persistent": { "xpack.monitoring.collection.enabled": true } }For more information, see Monitoring settings and Cluster Update Settings.
-
Disable the default collection of Elasticsearch monitoring metrics. Set
xpack.monitoring.elasticsearch.collection.enabledtofalseon each node in the production cluster.You can specify this setting in either the
elasticsearch.ymlon each node or across the cluster as a dynamic cluster setting. If Elasticsearch security features are enabled, you must havemonitorcluster privileges to view the cluster settings andmanagecluster privileges to change them.For example, you can use the following API to change this setting:
PUT _cluster/settings { "persistent": { "xpack.monitoring.elasticsearch.collection.enabled": false } }Leave
xpack.monitoring.enabledset to its default value (true). -
On each Elasticsearch node in the production cluster:
- Install Metricbeat.
-
Enable the Elasticsearch module in Metricbeat.
For example, to enable the default configuration in the
modules.ddirectory, run the following command:metricbeat modules enable elasticsearch
For more information, see Specify which modules to run and Elasticsearch module.
-
Configure the Elasticsearch module in Metricbeat.
You must specify the following settings in the
modules.d/elasticsearch.ymlfile:- module: elasticsearch metricsets: - ccr - cluster_stats - index - index_recovery - index_summary - ml_job - node_stats - shard period: 10s hosts: ["http://localhost:9200"] xpack.enabled: trueThis setting identifies the host and port number that are used to access Elasticsearch.
This setting ensures that Kibana can read this monitoring data successfully. That is to say, it’s stored in the same location and format as monitoring data that is sent by exporters.
-
If Elastic security features are enabled, you must also provide a user ID and password so that Metricbeat can collect metrics successfully.
-
Create a user on the production cluster that has the
remote_monitoring_collectorbuilt-in role. Alternatively, use theremote_monitoring_userbuilt-in user. -
Add the
usernameandpasswordsettings to the Elasticsearch module configuration file.For example, add the following settings in the
modules.d/elasticsearch.ymlfile:- module: elasticsearch ... username: remote_monitoring_user password: YOUR_PASSWORD
-
Create a user on the production cluster that has the
-
If you configured Elasticsearch to use encrypted communications,
you must access it via HTTPS. For example, use a
hostssetting likehttps://localhost:9200in themodules.d/elasticsearch.ymlfile. -
Identify where to send the monitoring data.
In production environments, we strongly recommend using a separate cluster (referred to as the monitoring cluster) to store the data. Using a separate monitoring cluster prevents production cluster outages from impacting your ability to access your monitoring data. It also prevents monitoring activities from impacting the performance of your production cluster.
For example, specify the Elasticsearch output information in the Metricbeat configuration file (
metricbeat.yml):The Elasticsearch monitoring features use ingest pipelines, therefore the cluster that stores the monitoring data must have at least one ingest node.
For more information about these configuration options, see Configure the Elasticsearch output.
-
If Elasticsearch security features are enabled on the monitoring cluster, you must provide a valid user ID and password so that Metricbeat can send metrics successfully.
-
Create a user on the monitoring cluster that has the
remote_monitoring_agentbuilt-in role. Alternatively, use theremote_monitoring_userbuilt-in user. -
Add the
usernameandpasswordsettings to the Elasticsearch output information in the Metricbeat configuration file (metricbeat.yml):output.elasticsearch: ... username: remote_monitoring_user password: YOUR_PASSWORD
-
Create a user on the monitoring cluster that has the
-
If you configured the monitoring cluster to use
encrypted communications, you must access it via
HTTPS. For example, use a
hostssetting likehttps://es-mon-1:9200in themetricbeat.ymlfile.
- Start Elasticsearch.
- Start Metricbeat.
- View the monitoring data in Kibana.