Observability mit dem Elastic Stack
In meiner Rolle als Product Lead für Observability bei Elastic erlebe ich unterschiedliche Reaktionen auf den Begriff „Observability“. Die mit Abstand häufigste Reaktion ist bis heute immer noch: „Was ist Observability?“ Aber ich höre auch immer öfter Reaktionen wie: „Wir haben vor kurzem eine Initiative zur Observability angestoßen, sind uns aber über die genauen Details noch nicht ganz klar.“ Und zuletzt ist „Observability“ in einigen der Unternehmen, mit denen wir das Glück haben zu arbeiten, bereits ein unverzichtbarer Teil der Entwicklung und Erstellung von Produkten und Diensten.
Da dieser Begriff immer noch nicht besonders weit verbreitet ist, möchte ich gerne etwas dazu schreiben, was „Observability“ für Elastic bedeutet, was wir von unseren innovativen Kunden gelernt haben und wie wir den Begriff aus der Produktperspektive bei der Weiterentwicklung unseres Stacks für praxisnahe Anwendungsfälle sehen.
Was ist Observability?
Der Begriff „Observability“ stammt nicht von uns. Wir haben ihn zuerst von unseren Benutzern gehört, hauptsächlich in der Community für Site Reliability Engineering (SRE). Der Ursprung des Begriffs wird laut verschiedener Quellen in den SRE-Abteilungen von Silicon-Valley-Giganten wie Twitter verortet. Und obwohl das wegweisende SRE-Buch von Google (in englischer Sprache) den Begriff zwar nicht erwähnt, tauchen dort viele der heute unter „Observability“ zusammengefassten Prinzipien auf.
Observability ist keine Komponente, die in einer Kiste ausgeliefert wird, sondern ein Attribut eines Systems, das Sie aufbauen, ebenso wie Benutzerfreundlichkeit, Hochverfügbarkeit und Stabilität. Bei der Gestaltung und der Erstellung beobachtbarer Systeme geht es darum, dass die verantwortlichen Personen im Produktionsbetrieb unerwünschte Verhaltensweisen (z. B. Dienstausfälle, Fehler, langsame Reaktionszeiten) erkennen können und aussagekräftige Informationen erhalten, um die Ursache effektiv bestimmen zu können (z. B. ausführliche Ereignis-Logs, differenzierte Informationen zur Ressourcenauslastung und Anwendungs-Traces). Viele Unternehmen haben Schwierigkeiten dabei, diese scheinbar offensichtlichen Ziele zu erreichen, weil sie nicht genügend oder zu viele Informationen sammeln, jedoch keine Erkenntnisse daraus gewinnen, oder weil sie den Zugang zu den Informationen fragmentieren.
Der erste Aspekt - die Erkennung unerwünschter Verhaltensweisen - beginnt normalerweise mit der Festlegung von Service Level Indicators (SLIs) und Objectives (SLOs) (Indikatoren und Ziele für die Diensterfüllung). Dabei handelt es sich um interne Erfolgsmessungen, um die Leistung der Produktionssysteme in Unternehmen zu messen, die sich mit Observability beschäftigen. Falls die Erfüllung dieser Ziele vertraglich garantiert wurde, kann sich aus SLIs/SLOs auch eine Service Level Agreement (SLA, Vereinbarung über die Diensterfüllung) ergeben. Ein gängiges Beispiel für einen SLI ist die Systemverfügbarkeit, für die Sie beispielsweise ein SLO von 99,9999 % festlegen können. Die Systemverfügbarkeit ist eine der gängigsten SLA-Formen für externe Kunden. Ihre internen SLIs/SLOs sind jedoch möglicherweise viel differenzierter, und Überwachungs- und Warnungsfunktionen für diese wichtigen Verhaltensfaktoren in Ihrem Produktionssystem sind das Fundament für jegliche Initiative zur Observability. Dieser Aspekt der Observability wird auch als „Überwachung“ bezeichnet.
Beim zweiten Aspekt geht es darum, zuständige Personen schnell und effizient mit differenzierten Informationen bei der Behebung von Produktionsproblemen zu unterstützen. In diesem Bereich sehen wir viel Bewegung und Innovation. Sie haben bestimmt schon von den drei Grundpfeilern der Observability gehört: Metriken, Logs und Anwendungs-Traces. Es herrscht Einigkeit darüber, dass die einfache Erfassung dieser differenzierten Daten mit einer Mischung von Tools nicht immer zielführend und häufig wenig kosteneffektiv ist.
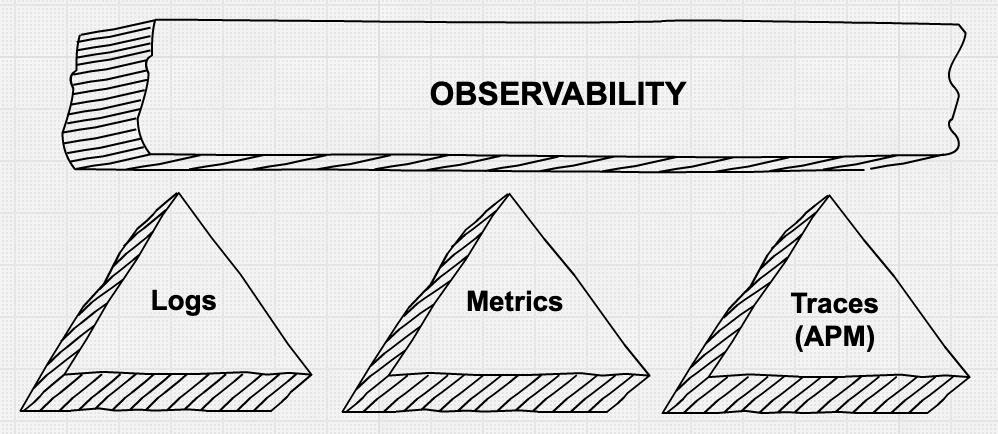
Grundpfeiler der Observability
Lassen Sie uns diese Aspekte der Datenerfassung ausführlicher betrachten. Wir erleben häufig, dass Unternehmen ihre Metriken in einem System sammeln (etwa eine Zeitreihendatenbank oder ein SaaS-Dienst als Ressourcenüberwachung), ihre Logs in einem zweiten System (wenig überraschend taucht in unseren Gesprächen oft der ELK-Stack auf), und dazu noch ein drittes Tool zur Vermessung von Anwendungen mit Nachverfolgung auf Abfrageebene. Wenn ein Alarm für eine Verletzung einer Dienstebene ausgelöst wird, sprinten die Verantwortlichen zu ihren Systemen und versuchen, sich einen Überblick zu verschaffen, indem sie ihre Metriken aus dem Browserfenster manuell zu den Logs in einem anderen Fenster zuordnen und bei Bedarf Traces in einem dritten Fenster abrufen.
Dieser Ansatz hat mehrere Nachteile. Einerseits geht während einer Dienstbeeinträchtigung oder einem Ausfall wertvolle Zeit dabei verloren, verschiedene Datenquellen zueinander zuzuordnen, die jeweils dieselbe Geschichte erzählen. Außerdem entstehen unnötige Kosten für die Pflege von drei verschiedenen Datenspeichern: Lizenzkosten, zusätzliche Mitarbeiter für die Administration einzelner Tools, uneinheitliche Machine-Learning-Funktionen in den verschiedenen Datenspeichern und unnötig komplizierte Denkmuster für unterschiedliche Warnungsmeldungen. Sämtliche Unternehmen, mit denen ich mich unterhalte, kennen all diese Herausforderungen.
Es spricht sich immer weiter herum, wie wichtig es ist, all diese Informationen in einem einzelnen Datenspeicher aufzubewahren und in einer intuitiven Benutzeroberfläche automatisch zuordnen zu können. Die Benutzer, mit denen wir sprechen, möchten ihren Verantwortlichen gerne sämtliche relevanten Daten für die ihnen unterstellten Dienste auf eine einheitliche Art bereitstellen, egal ob es sich um eine Log-Zeile aus der Anwendung, Trace-Daten aus einer Instrumentierung oder die Ressourcenauslastung in Form von Metriken in einer Zeitserie handelt. Die wichtigsten Anforderungen sind ein einheitlicher Ad-hoc-Zugriff auf Daten aus beliebigen Quellen, Such- und Filterfunktionen, Aggregationen und Visualisierungen. Mit einem Drilldown von Metriken zu Logs und Traces innerhalb von wenigen Klicks und ohne Kontextwechsel können Sie Ihre Untersuchungen beschleunigen. Die extrahierten numerischen Werte aus strukturierten Logs sehen den Metriken überraschend ähnlich, und ein visueller Vergleich der Werte ist aus der Betriebsperspektive von unschätzbarem Wert.
Wie bereits erwähnt kann es passieren, dass Sie zu viele Daten erhalten und im Ernstfall nicht genügend aussagekräftige Erkenntnisse haben, wenn Sie die Daten einfach nur sammeln. Unsere Kunden erwarten zunehmend, dass die Systeme zur Erfassung von Betriebsdaten interessante Ereignisse, Traces und Anomalien in einer Reihe von Zeitserien automatisch erkennen. Auf diese Weise können die Verantwortlichen die Problemursache schneller eingrenzen. Diese Anomalieerkennungsfunktionen werden manchmal auch als der vierte Grundpfeiler der Observability bezeichnet. Observability-Teams wünschen sich immer häufiger die Möglichkeit, Anomalien in Verfügbarkeitsdaten, Ressourcenauslastung, Anomalien in Loggingmustern und, noch wichtiger, in Traces erkennen zu können.
Observability ... und der ELK Stack?
Was hat Observability also mit dem Elastic Stack zu tun (oder auch ELK Stack, wie er liebevoll von Experten genannt wird)?
Der ELK Stack ist allgemein anerkannt als Standard für die Zentralisierung von Logs aus Computersystemen. Viele Benutzer gehen davon aus, dass Elasticsearch (eine Suchmaschine) ein guter Ort ist, um Logs für eine Freitextsuche abzulegen. Und in der Tat ist es als Ausgangspunkt für viele Benutzer extrem hilfreich, textbasierte Logs nach dem Wort „Error“ zu durchsuchen oder nach einer Reihe bekannter Tags zu filtern.
Wie jedoch bereits viele Benutzer des ELK Stack wissen, bietet Elasticsearch als Datenspeicher viel mehr als nur einen umgekehrten Index für eine effiziente Volltextsuche und einfache Filterfunktionen. Die Lösung enthält zusätzlich einen Speicher im Spaltenformat, der für die Speicherung und Verarbeitung dichter numerischer Zeitreihen optimiert ist. Mit diesem Speicher im Spaltenformat können Sie strukturierte Daten aus Ihren analysierten Logs als Text oder in einem numerischen Format speichern. In Wirklichkeit hat uns die Konvertierung von Logs zu Metriken überhaupt erst auf die Idee gebracht, Elasticsearch für die effiziente Speicherung und Abfrage von Zahlen zu optimieren.
Unsere Benutzer haben immer häufiger numerische Zeitreihen direkt in Elasticsearch gespeichert, um ältere Zeitreihendaten zu ersetzen. Angesichts dieser Nachfrage hat Elastic vor kurzem Metricbeat vorgestellt, eine Anwendung, mit der Sie Metriken, Rollups und weitere Funktionen rund um Metriken im Datenspeicher und in der GUI automatisieren können. In der Folge haben immer mehr Benutzer, die den ELK Stack für Logs verwendeten, auch damit begonnen, ihre Metrikdaten wie etwa die Ressourcenauslastung im Elastic Stack abzulegen. Ein weiterer Anreiz neben den bereits erwähnten Kosteneinsparungen war dabei auch die Freiheit in Elasticsearch hinsichtlich der Kardinalität von Feldern für numerische Aggregationen (ein häufiges Problemthema bei Gesprächen über vorhandene Zeitreihendatenbanken).
Neben den Metriken sind auch Verfügbarkeitsdaten eine wichtige Ergänzung zu den Logs und eine wichtige Quelle für SLO/SLI-Warnungen aus Überwachungskomponenten. Verfügbarkeitsdaten liefern Informationen über Beeinträchtigungen von Diensten, APIs und Websites häufig noch bevor die Benutzer betroffen sind. Außerdem verbrauchen die Verfügbarkeitsdaten kaum Speicherplatz und haben daher ein herausragendes Kosten-Nutzen-Verhältnis.
Im vergangenen Jahr hat Elastic außerdem Elastic APM präsentiert und den Stack um Funktionen für Anwendungs-Tracing und verteilte Tracingfunktionen zu erweitern. Diese Lösung war für uns eine natürliche Weiterentwicklung, da verschiedene Open-Source-Projekte und namhafte APM-Anbieter Elasticsearch bereits zum Ablegen und Durchsuchen von Trace-Daten verwendeten. APM-Daten werden aktuell normalerweise separat von Logs und Metriken aufbewahrt, wodurch sich Datensilos immer weiter fortpflanzen können. Elastic APM enthält eine Reihe von Agenten zur Erfassung von Trace-Daten aus unterstützten Sprachen und Frameworks und unterstützt OpenTracing. Die Trace-Daten werden anschließend automatisch zu Metriken und Logs zugeordnet.
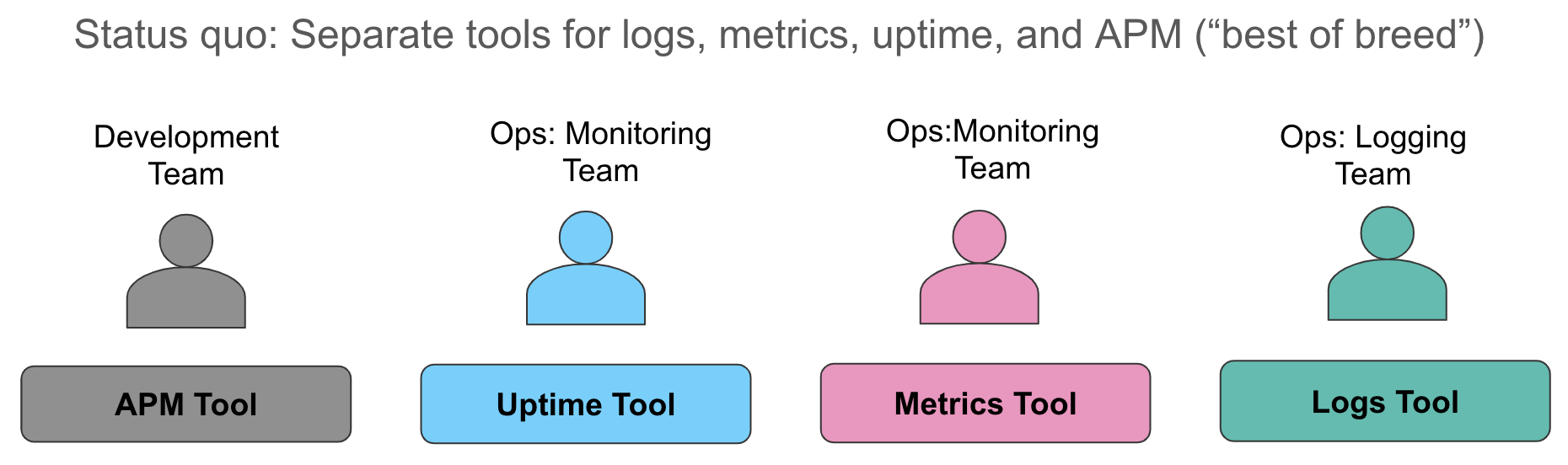
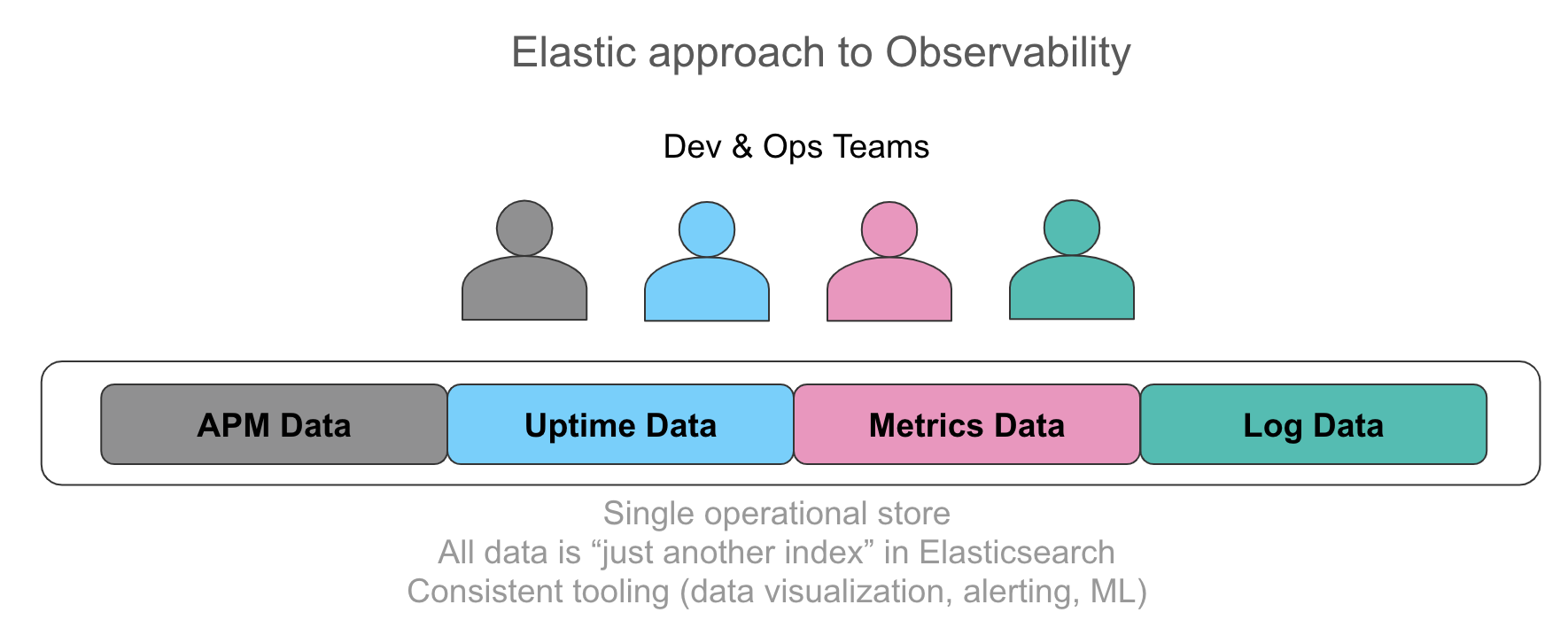
Jeder dieser Dateneingänge ist in Wirklichkeit nur ein weiterer Index in Elasticsearch. Sie können diese Daten beliebig aggregieren, in Kibana visualisieren und die einzelnen Datenquellen für Warnungen oder Machine-Learning-Ansätze verwenden. Sehen Sie sich dieses Video an, um die Lösung in Aktion zu erleben.
Observability für Kubernetes und den Elastic Stack
Eine der Communities, in denen das Thema Observability besonders heiß diskutiert wird, sind die Benutzer, die Kubernetes für ihre Containerorchestrierung einsetzen. Diese „Cloud Natives“, ein von der Cloud Native Computing Foundation (oder CNCF) geprägter Begriff, müssen einzigartige Herausforderungen bewältigen. Sie verwalten eine gigantische Zentralisierung von Anwendungen und Diensten, die in einer Containerorchestrierungsplattform mit Kubernetes entwickelt oder dorthin migriert wurden. Dazu kommt der Trend, monolithische Apps in „Microservices“ aufzuteilen. Die bisher verwendeten Tools und Methoden, um Einblicke in die Anwendungen auf dieser Infrastruktur zu erhalten, funktionieren auf einmal nicht mehr.
Die Observability von Kubernetes verdient einen eigenen Blogeintrag, daher verweise ich Sie fürs Erste auf das Webinar „Observable Kubernetes“ (Observability in Kubernetes) und den Blogeintrag „Distributed Tracing with Elastic APM“ (Verteiltes Tracing mit Elastic APM).
Wie geht es weiter?
Für diesen Blogeintrag scheint es angemessen, den Lesern einige Ressourcen zur Erkundung anzubieten.
Falls Sie mehr über Best Practices zum Thema Observability erfahren möchten, empfehle ich Ihnen die Lektüre des bereits erwähnten SRE-Buchs von Google. Blogeinträge von Unternehmen, deren Geschäft vom fehlerfreien Betrieb ihrer kritischen Produktions-Apps abhängt, enthalten auch oft interessante Denkanstöße. Dieser Blogeintrag von den Salesforce-Experten ist eine sehr pragmatische und praktische Anleitung zur schrittweisen Verbesserung der Observability.
Um den Elastic Stack für Ihre eigene Initiative zur Observability zu testen, verwenden Sie die neueste Version unseres Stacks im Elasticsearch Service in der Elastic Cloud (eine hervorragende Sandbox, selbst wenn Sie letztendlich selbstverwaltet bereitstellen), oder laden Sie die Elastic Stack-Komponenten für die lokale Installation herunter. Sehen Sie sich die neuen GUIs in Kibana für Logs, Infrastrukturüberwachung, APM und Verfügbarkeit (demnächst in 6.7 verfügbar) an, die speziell für gängige Workflows rund um das Thema Observability entwickelt wurden. Außerdem können Sie uns Ihre Fragen jederzeit in den Diskussionsforenstellen - wir helfen Ihnen gerne!