Heartbeat
Leichtgewichtiger Shipper für Ihr Uptime-Monitoring
Überwachen Sie die Verfügbarkeit von Diensten durch aktives Testen. Unter Abarbeitung einer Liste von URLs stellt Heartbeat Komponenten und Diensten im System eine einfache Frage: Bist du noch da? Heartbeat sendet diese Information und die Reaktionszeit zur weiteren Analyse an den Rest des Elastic Stack.
Einfache Handhabung. Leicht zu konfigurieren.
Egal ob Sie einen Dienst auf demselben Host oder über das Internet testen – mit Heartbeat können Sie im Handumdrehen Daten zu Verfügbarkeit und Reaktionszeiten abrufen. Erstellen Sie eigene Visualisierungen in Kibana oder nutzen Sie unsere „schlüsselfertige“ Lösung Elastic Uptime (unterstützt von Heartbeat), um Ihre Apps und Dienste zu überwachen.
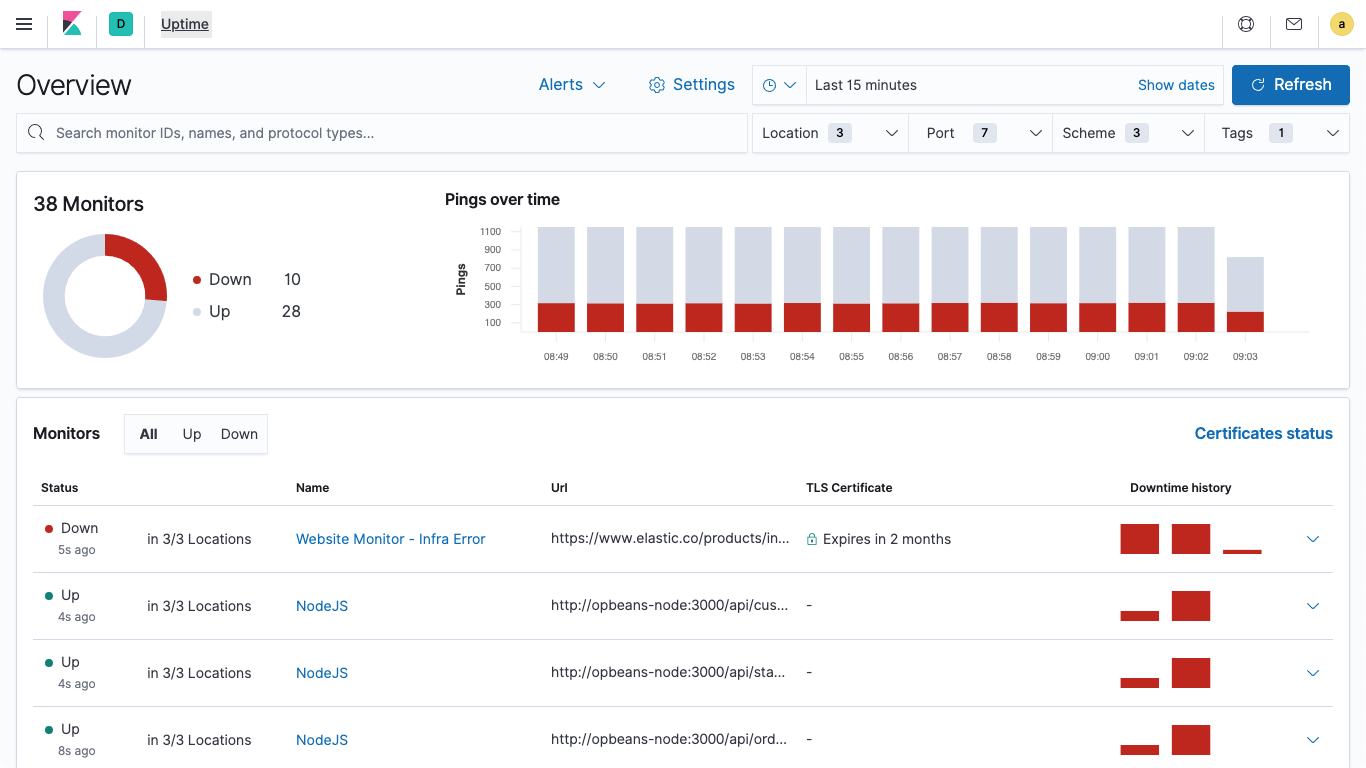
Alles pingen
Heartbeat-Pings laufen über ICMP, TCP und HTTP und unterstützen außerdem TLS, Authentifizierung und Proxys. Dank einfacher DNS-Auflösung können Sie alle Hosts hinter einem Server mit Lastausgleich beobachten.
Dynamisches Hinzufügen und Entfernen von Zielen
In den dynamischen Infrastrukturen von heute ändert sich die Verfügbarkeit von Diensten und Hosts ständig. Mit Heartbeat und einer einfachen, dateibasierten Oberfläche lässt sich der Prozess des Hinzufügens und Entfernens von Monitoring-Zielen ganz einfach automatisieren.
Nichts geht verloren
Sie können Ihre Metriken auf Datenträger spoolen lassen, sodass Ihre Pipeline keinen Datenpunkt mehr auslässt – selbst wenn Netzwerkprobleme oder andere Unterbrechungen auftreten. Heartbeat erfasst die eingehenden Daten und wartet mit dem Senden an Elasticsearch oder Logstash, bis der Normalbetrieb wiederhergestellt ist.
Elasticsearch und Logstash fürs Speichern, Kibana fürs Visualisieren
Heartbeat ist Bestandteil des Elastic Stack und integriert sich daher nahtlos mit Logstash, Elasticsearch und Kibana. Egal, ob Sie Ihre Metriken mit Logstash umwandeln oder anreichern, in Elasticsearch mit den Analytics-Tools herumspielen oder Ihre Dashboards in Kibana einrichten und teilen möchten – mit Heartbeat übertragen Sie Ihre Daten ganz leicht dorthin, wo sie benötigt werden.