OpenTelemetry-native Monitoring der Anwendungsleistung (meist: APM)
Instrumentieren Sie Ihre Anwendungen automatisch, visualisieren und korrelieren Sie Abhängigkeiten und ermitteln Sie schnell die Ursachen – bis hin zum Code.
Geführte Demo
100 % Sichtbarkeit, null Ausfallzeiten
Erkennen Sie Anomalien und beschleunigen Sie die Fehlerbehebung bei verteilten Microservices, serverlosen Funktionen, KI-Modellen, Drittanbieter-APIs und mehr.
WARUM OTEL-NATIVE WICHTIG IST
APM sollte geöffnet sein. Punkt.
Datensilos, proprietäre Formate und geschlossene Ökosysteme bremsen Sie aus. Elastic ist Open Source und OTel-nativ und bietet umfassende Sprachunterstützung, verbesserte Interoperabilität und detaillierten Kontext zur Fehlerbehebung.




VISUALISIEREN & ANALYSIEREN
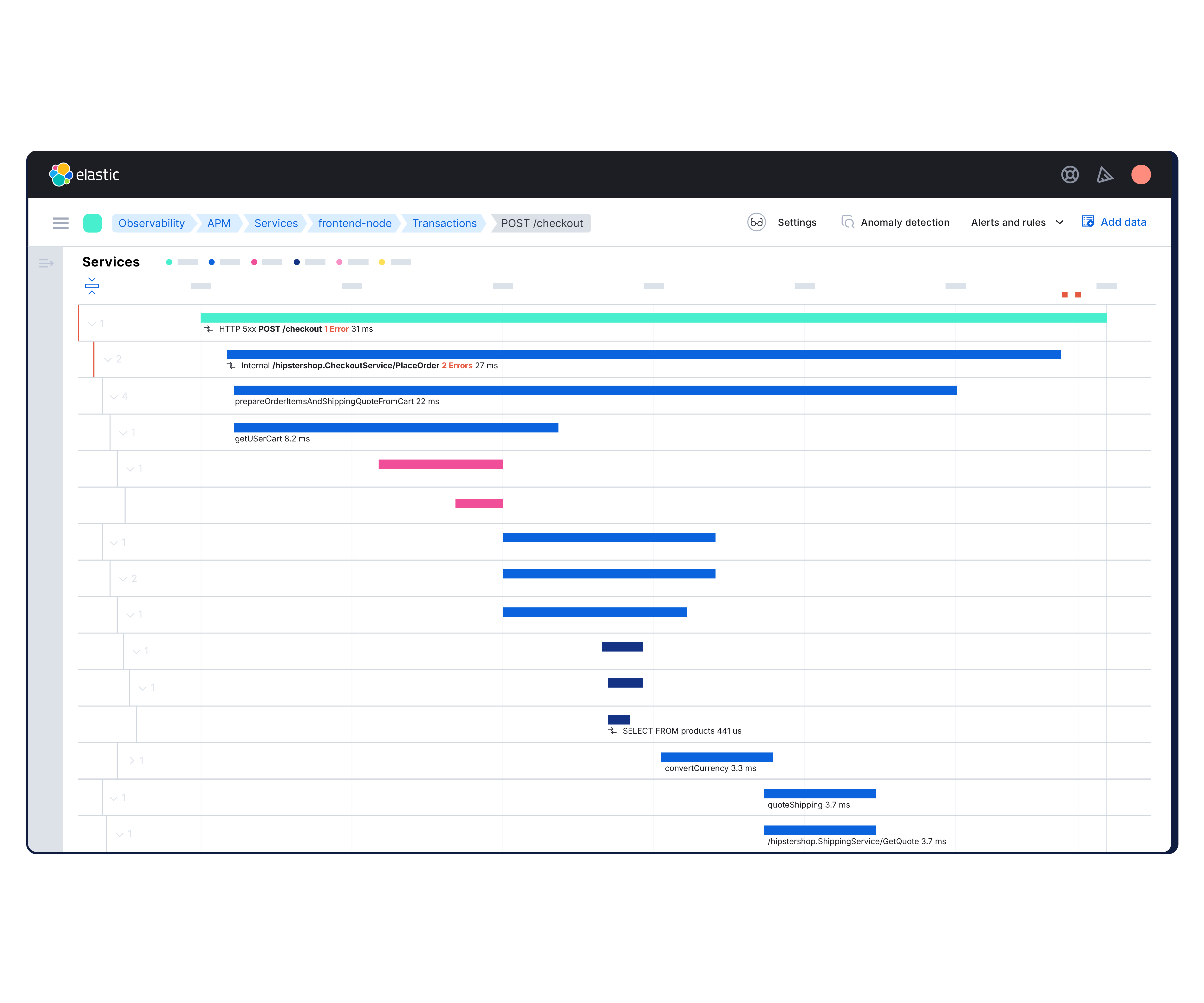
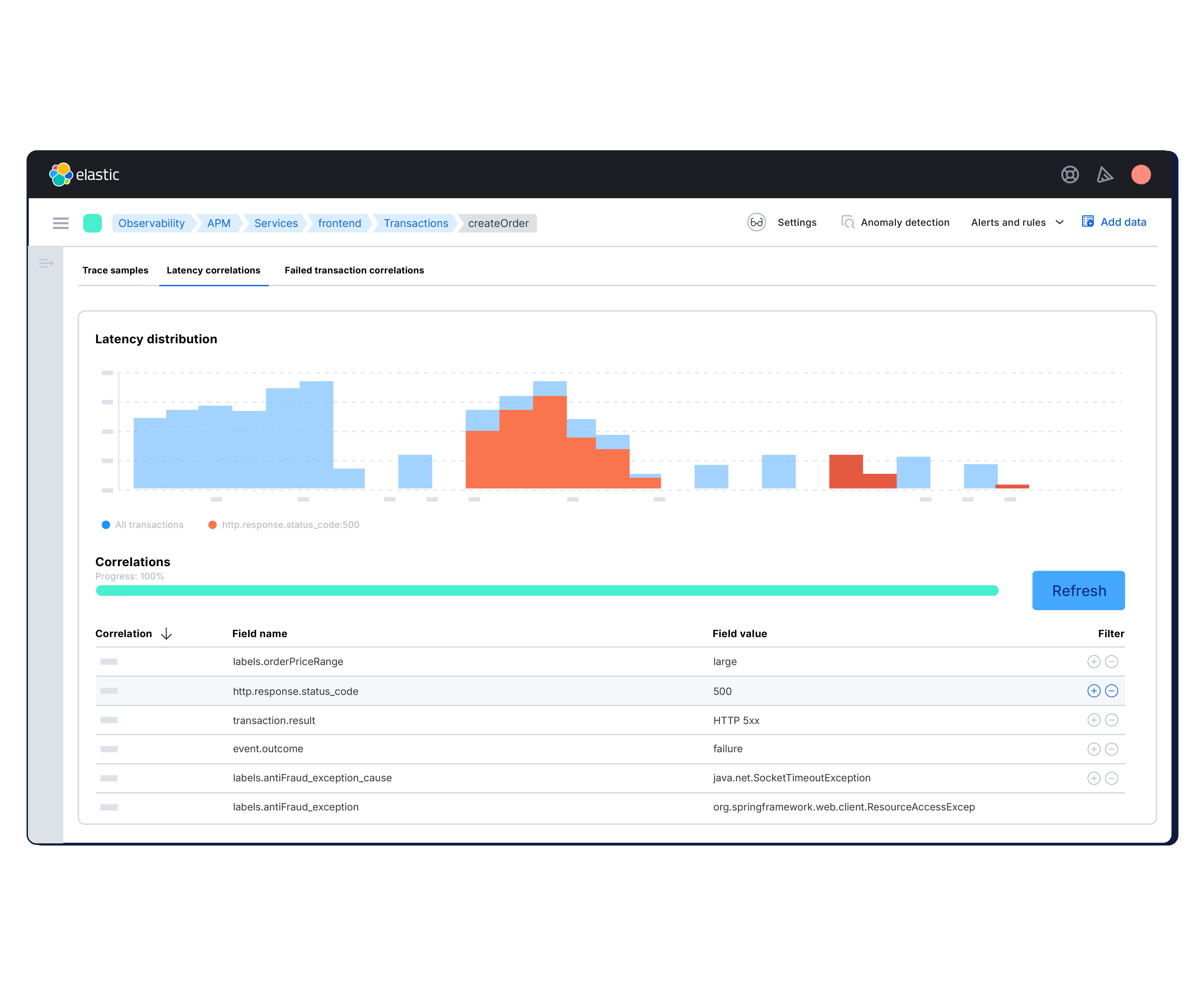
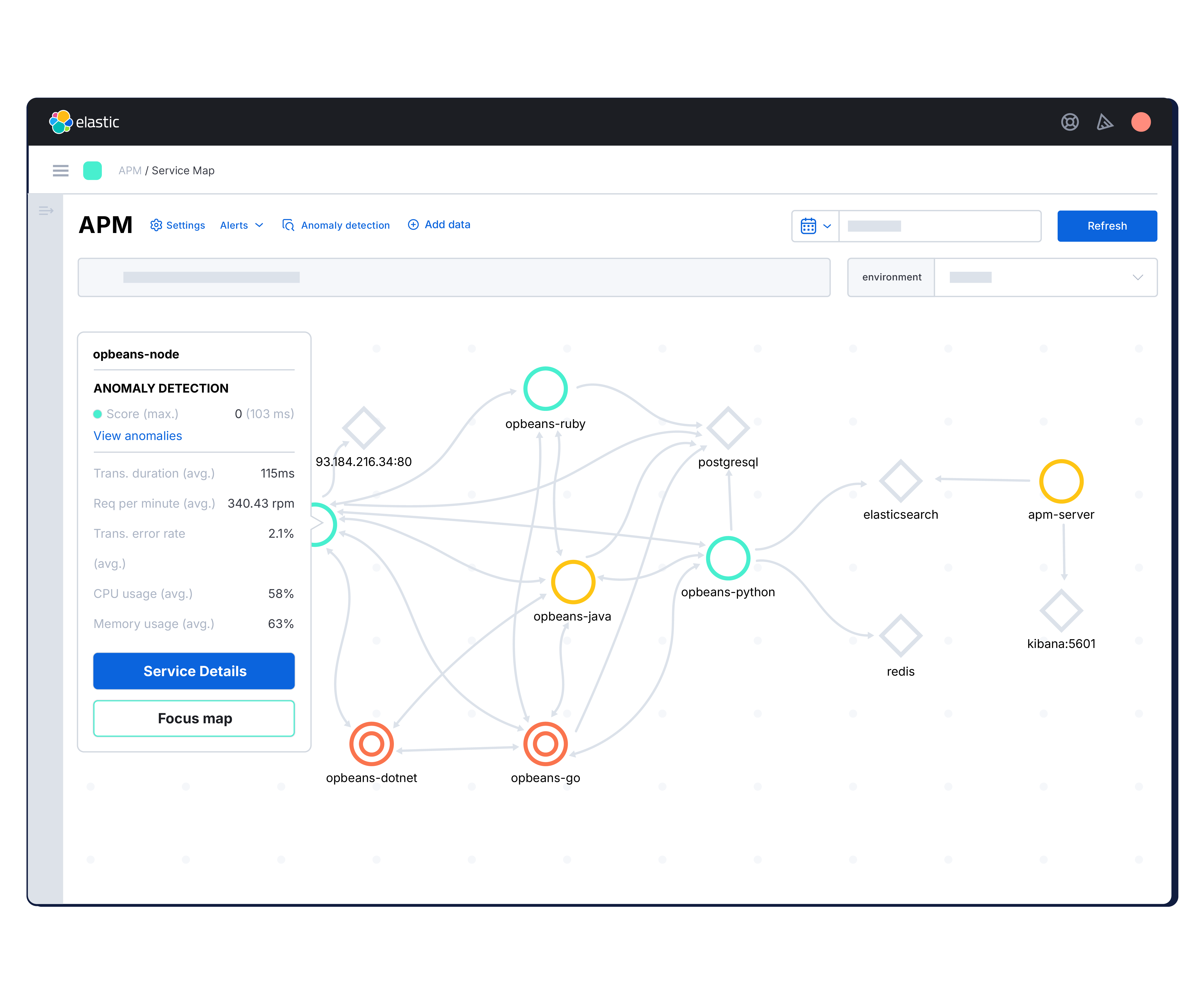
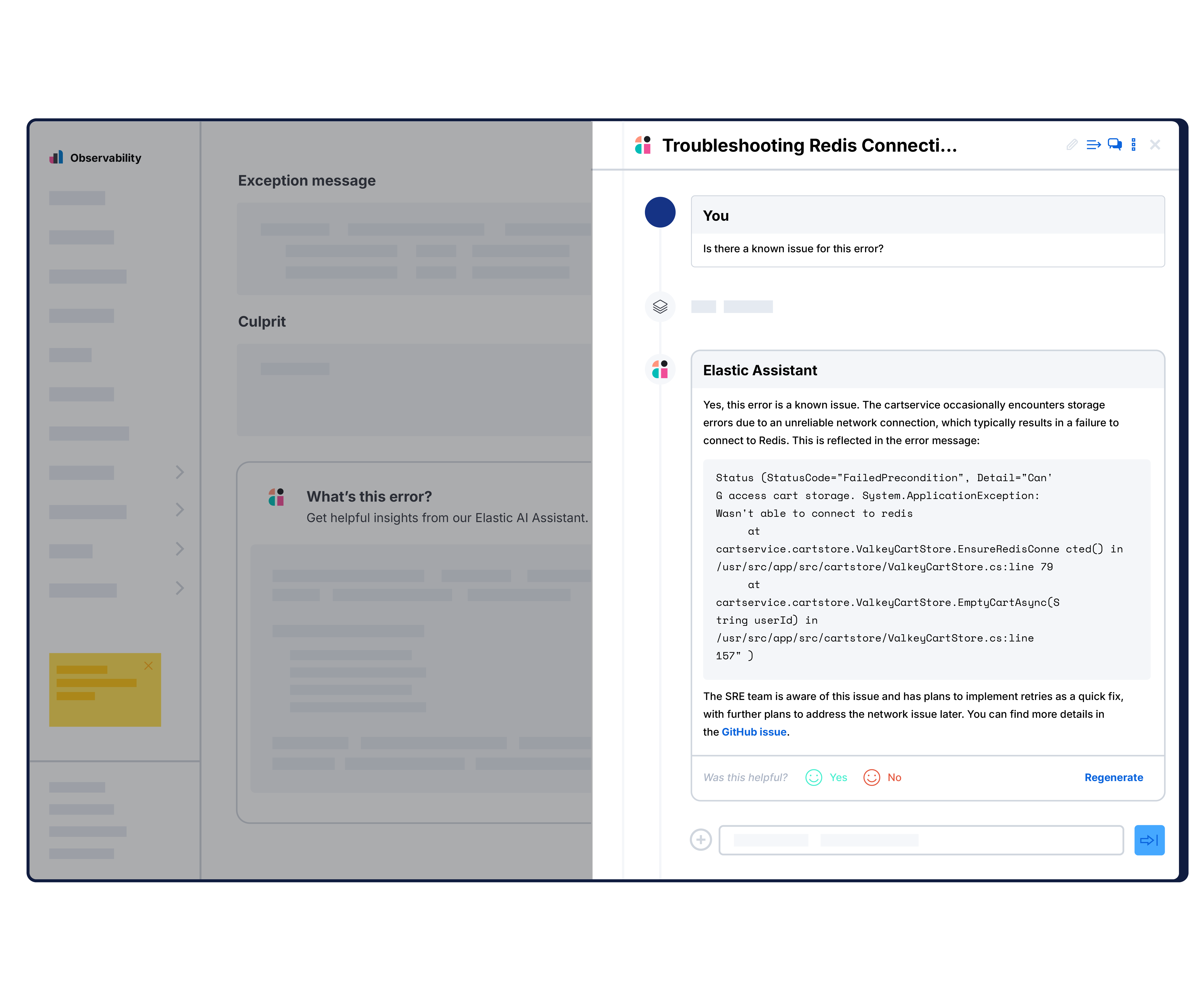
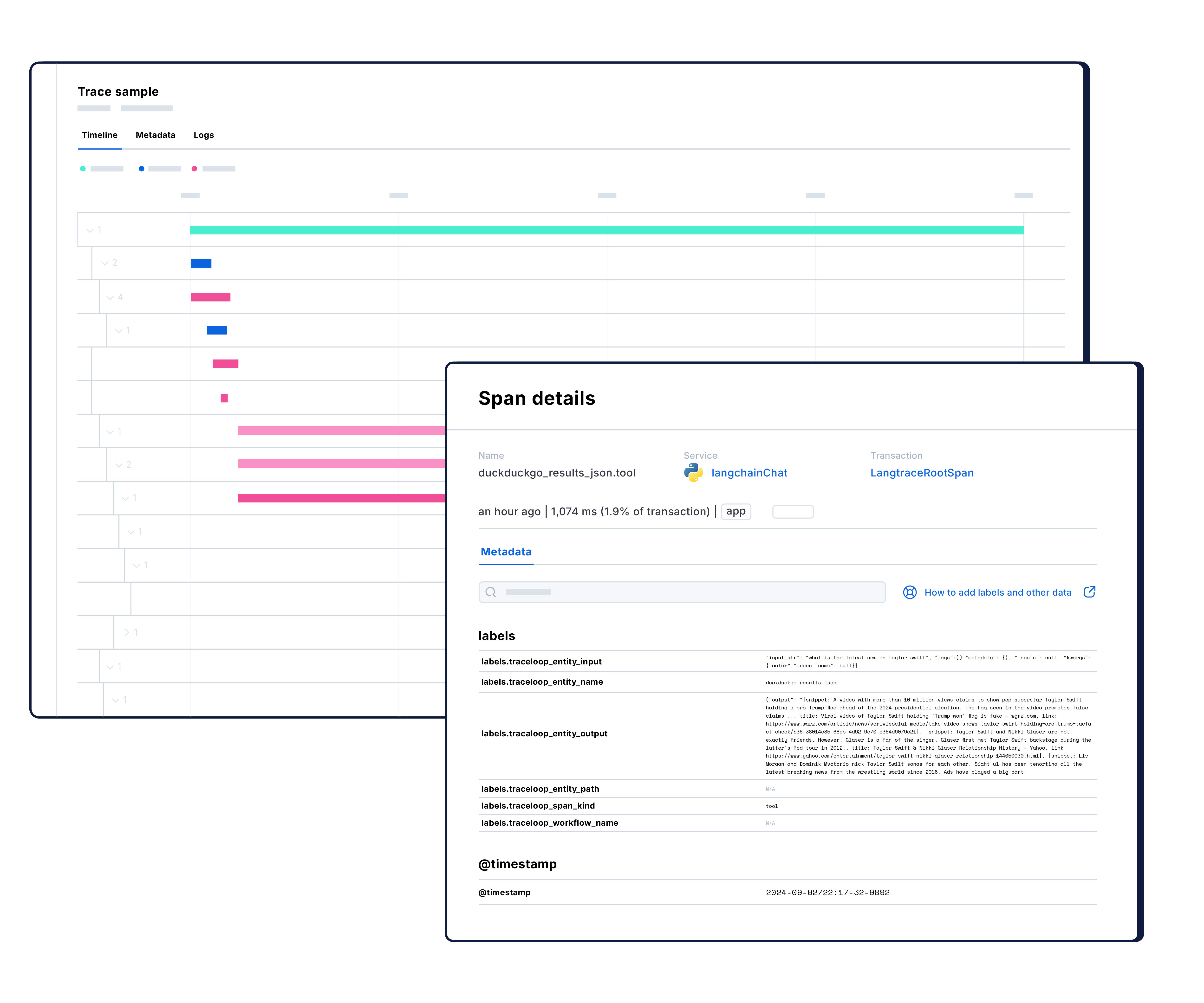
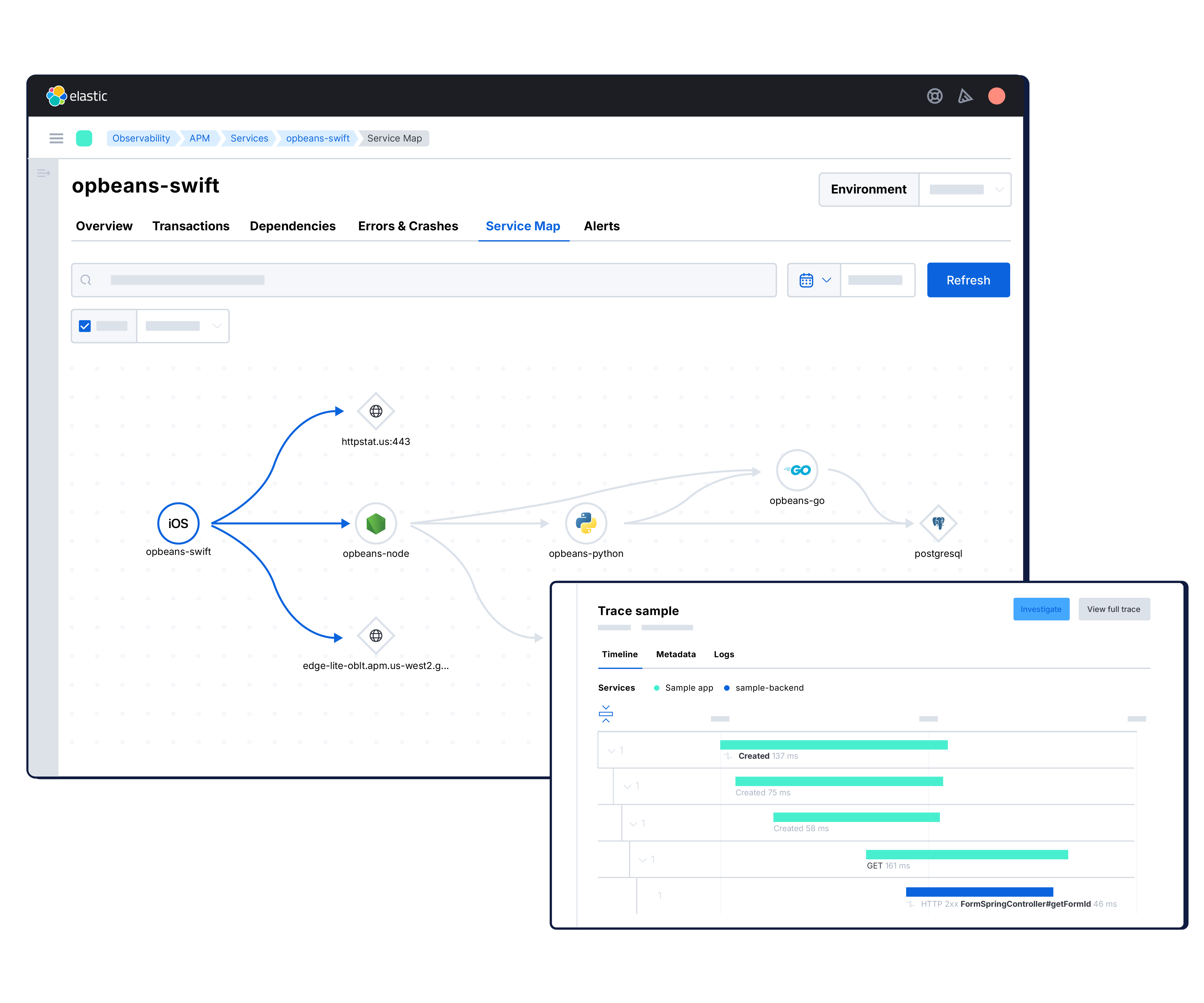
Codeprobleme lokalisieren und schneller Fehler beheben
Verfolgen Sie Anfragen in Ihrem Stack mit leichtgewichtigem, OpenTelemetry-basiertem verteiltem Tracing. Head- und Tail-basiertes Sampling reduziert den Overhead, ohne den Kontext zu beeinträchtigen. Erhalten Sie die kritischen Traces, die Sie benötigen, ohne Leistungseinbußen.
Breite Sprachunterstützung








Erfahren Sie, warum Unternehmen wie Ihres Elastic APM wählen
Kunden-Spotlight
 Equinox verwendet Elastic APM zur Überwachung von über 200 Microservices, wodurch die Zeit für die Bereitstellung von Fixes um bis zu 50 % verkürzt und die Problemlösung im gesamten Stack beschleunigt wird.
Equinox verwendet Elastic APM zur Überwachung von über 200 Microservices, wodurch die Zeit für die Bereitstellung von Fixes um bis zu 50 % verkürzt und die Problemlösung im gesamten Stack beschleunigt wird.Kunden-Spotlight
 Wells Fargo verlässt sich auf Elastic APM, um Geldbewegungs-Apps im großen Maßstab zu überwachen. Es erfasst 100 % der verteilten Spuren und korreliert sie mit Logs und anderen Signalen.
Wells Fargo verlässt sich auf Elastic APM, um Geldbewegungs-Apps im großen Maßstab zu überwachen. Es erfasst 100 % der verteilten Spuren und korreliert sie mit Logs und anderen Signalen.Kunden-Spotlight
 Das Miles & More Treueprogramm der Lufthansa nutzt Elastic APM zur Überwachung wichtiger Dienste und verwendet einheitliche Ansichten für eine schnellere Erkennung und Ursachenanalyse.
Das Miles & More Treueprogramm der Lufthansa nutzt Elastic APM zur Überwachung wichtiger Dienste und verwendet einheitliche Ansichten für eine schnellere Erkennung und Ursachenanalyse.