Verteiltes Tracing, OpenTracing und Elastic APM
Die Welt der Microservices
Immer mehr Unternehmen setzen Microservice-Architekturen ein. Die Zahl der entwickelten und bereitgestellten Microservices steigt täglich. Diese Services werden oft in unterschiedlichen Programmiersprachen entwickelt, in separaten Laufzeitcontainern bereitgestellt und von unterschiedlichen Teams und Abteilungen verwaltet. Manche große Unternehmen wie Twitter haben zehntausende Microservices, die gemeinsam zum Erreichen der Geschäftsziele beitragen. Wie Twitter in diesem Blogeintrag beschreibt, sind Einblicke in die Integrität und Leistung der facettenreichen Servicetopologie extrem wichtig, um Fehlerursachen schnell bestimmen zu können und die Zuverlässigkeit und Effizienz von Twitter als Ganzes zu verbessern.
Dabei kann verteiltes Tracing eine große Hilfe leisten. Verteiltes Tracing löst zwei grundsätzliche Herausforderungen im Zusammenhang mit Microservices:
- Latenzüberwachung
Jede Anforderung oder Transaktion eines Benutzers kann viele verschiedene Dienste in unterschiedlichen Laufzeitumgebungen durchlaufen. Es ist wichtig, die Latenz dieser einzelnen Services für eine bestimmte Anforderung zu kennen, um die Leistungseigenschaften des gesamten Systems besser zu verstehen und wertvolle Erkenntnisse für Verbesserungsmöglichkeiten zu gewinnen. - Ursachenanalyse
Ursachenanalysen sind besonders komplex für Anwendungen, die auf einem umfangreichen Ökosystem aus Microservices basieren. In jedem dieser Services kann jederzeit ein Problem auftreten. Verteiltes Tracing ist unverzichtbar beim Debuggen von Problemen in einem solchen System.
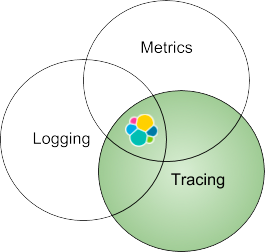
Gehen wir einen Schritt zurück. Tracing ist nur eines der Puzzleteile der drei Grundpfeiler der Beobachtbarkeit: Logs, Metriken und Tracing. Wie Sie gleich sehen werden, ist der Elastic Stack eine einheitliche Plattform für alle drei Grundpfeiler der Beobachtbarkeit. Wenn Sie Logs, Metriken und APM-Daten im gleichen Repository speichern, analysieren und miteinander korrelieren, erhalten Sie besonders kontextreiche Einblicke in Ihre Geschäftsanwendungen und Systeme. In diesem Blogeintrag konzentrieren wir uns ausschließlich auf den Tracing-Aspekt.
Verteiltes Tracing mit Elastic APM
Elastic APM ist ein System zum Monitoring der Anwendungsleistung und basiert auf dem Elastic Stack. Mit diesem System können Sie Softwareservices und Anwendungen in Echtzeit überwachen, ausführliche Leistungsdaten zu Reaktionszeiten für eingehende Anforderungen, Datenbankabfragen, Cache-Aufrufe, externe HTTP-Anforderungen usw. erfassen. Elastic APM enthält umfassende vorkonfigurierte Auto-Instrumentierungen (z. B. Timing von DB-Abfragen) für unterstützte Frameworks und Technologien. Sie können die Instrumentierung auch für Ihre eigenen Zwecke anpassen. Auf diese Weise können Sie Leistungsprobleme schneller eingrenzen und beheben.
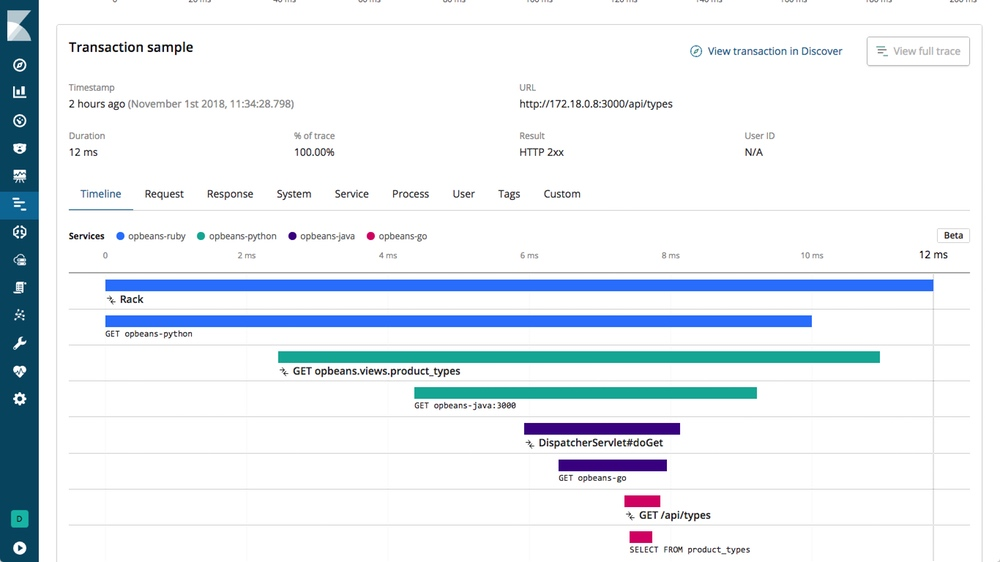
Elastic APM unterstützt verteiltes Tracing und OpenTracing. Mit dieser Lösung können Sie die Leistung Ihrer gesamten Microservice-Architektur in einer einzigen Ansicht analysieren. Dazu überwacht Elastic APM sämtliche Anforderungen, von der ursprünglichen Webanforderung an Ihren Front-End-Service bis hin zu Anforderungen an Ihre Back-End-Services. Damit können Sie potenzielle Engpässe in Ihrer Anwendung viel schneller und einfacher finden. Die Zeitleisten-Visualisierung in der APM-Benutzeroberfläche zeigt eine Wasserfallansicht sämtlicher Transaktionen aus einzelnen Services, die in einer Ablaufverfolgung miteinander verbunden sind:
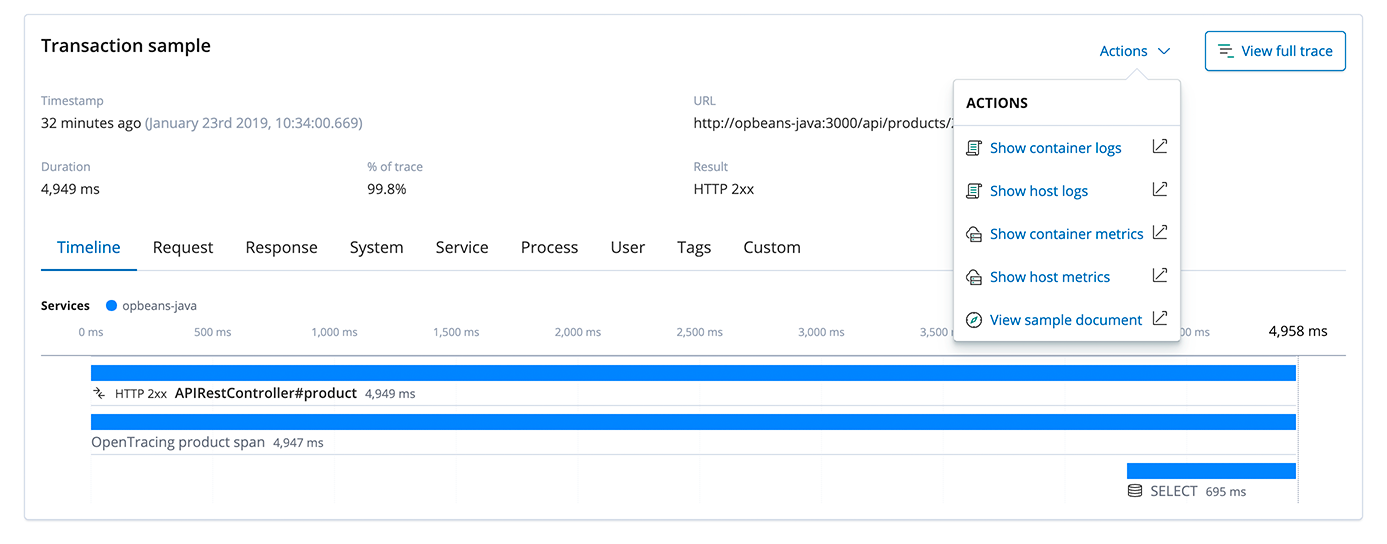
Der Elastic Stack ist außerdem eine hervorragende Plattform zum Aggregieren von Logs und für Metrikanalysen. Durch die Speicherung und Indexierung von Logs, Metriken und APM-Traces in Elasticsearch ergeben sich ungeahnte Möglichkeiten. Sie können Datenquellen wie Infrastrukturmetriken, Logs und Traces schnell miteinander abgleichen und Problemursachen viel schneller ermitteln. In der APM-Benutzeroberfläche können Sie aus einem Trace mühelos zum Host, zu Containermetriken oder zu Logs wechseln, indem Sie auf das Menü Aktionen klicken, falls diese Metriken und Logs ebenfalls erfasst werden.
Es wäre wunderbar, wenn Elastic APM überall zur Instrumentierung von Anwendungen und Services eingesetzt würde. Elastic APM ist jedoch nicht die einzige verfügbare Lösung für verteiltes Tracing. Andere beliebte Open Source-Tracingprogramme wie Zipkin und Jaeger sind ebenfalls erhältlich. Konzepte wie Polyglot-Programmierung und Polyglot-Persistenz sind in der Welt der Microservices weit verbreitet und akzeptiert. Analog dazu wird „Polyglot-Tracing“ ebenfalls immer häufiger zum Einsatz kommen. Aufgrund der unabhängigen und entkoppelten Funktionsweise von Microservices werden die verantwortlichen Personen vermutlich unterschiedliche Tracingsysteme verwenden.
Herausforderungen für Entwickler
Angesichts der vielen verfügbaren Tracingsysteme stehen Entwickler vor wichtigen Herausforderungen. Schlussendlich sind die Tracer im Anwendungscode beheimatet. Einige dieser Herausforderungen:
- Welches Tracingsystem soll ich verwenden?
- Was passiert, wenn ich ein anderes Tracingsystem verwenden möchte? Ich möchte nicht meinen gesamten Quellcode ändern.
- Was ist mit gemeinsam genutzten Bibliotheken, die unterschiedliche Tracer verwenden?
- Was passiert, wenn meine externen Services unterschiedliche Tracer verwenden?
Wenig überraschend brauchen wir eine Standardisierung, um diese Probleme zu lösen. Bevor wir über den Stand der Standardisierung sprechen, lassen Sie uns einen Schritt zurück gehen und das verteilte Tracing als ganzheitliches System aus der Architekturperspektive betrachten, um zu verstehen, was wir brauchen, um das „Nirvana“ des verteilten Tracing zu erreichen.
Architekturkomponenten für verteiltes Tracing
Moderne Softwaresysteme können in einige wenige wichtige Komponenten unterteilt werden, die normalerweise von unterschiedlichen Abteilungen geplant und entwickelt werden und in unterschiedlichen Laufzeitumgebungen ausgeführt werden.
- Ihr eigener Anwendungscode und Ihre Services
- Gemeinsam genutzte Bibliotheken und Services
- Externe Services
Um ein solches System ganzheitlich und integriert mit verteiltem Tracing zu überwachen, benötigen wir vier Architekturkomponenten:
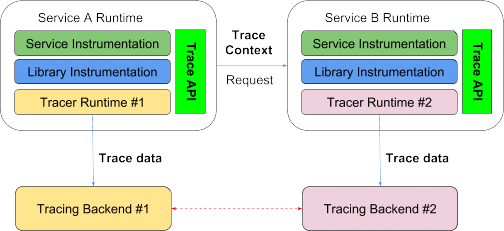
- Standardisierte API für verteiltes Tracing. Mit einer standardisierten herstellerneutralen API können Entwickler ihren Code auf standardisierte Art instrumentieren, ohne dass es einen Unterschied macht, welcher Tracer später zur Laufzeit eingesetzt wird. Dies ist der erste Schritt, egal was später passiert.
- Standardisierte Definition und Verbreitung des Tracingkontexts. Für umgebungsübergreifendes Tracing müssen beide Seiten den Tracingkontext kennen, und dieser Kontext muss auf eine standardisierte Weise verbreitet werden. Die Mindestanforderung an den Kontext ist eine Trace-ID.
- Standardisierte Definition von Tracingdaten. Um Daten aus einem Tracer in einem anderen Tracer verarbeiten zu können, muss ein standardisiertes und erweiterbares Format definiert werden.
- Kompatibilität zwischen Tracingsystemen. Um völlige Kompatibilität zur Laufzeit sicherzustellen, müssen die unterschiedlichen Tracer zuletzt auch Mechanismen bereitstellen, um Tracingdaten aus anderen Tracern auf offene Weise zu importieren und zu exportieren. Gemeinsam genutzte Bibliotheken oder Services mit Instrumentierung durch einen Tracer wie Jaeger sollten ihre Daten idealerweise nach einer Konfigurationsänderung im Jaeger Agent direkt an Elastic APM oder einen anderen Tracer senden können.
Auftritt OpenTracing.
Die OpenTracing-Spezifikation
Die OpenTracing-Spezifikation definiert eine offene und herstellerneutrale API für verteiltes Tracing. Damit können sich die Benutzer von einzelnen Anbietern lösen, da sie jederzeit zu einer OpenTracing-Implementierung wechseln können. Außerdem können Entwickler von Frameworks und gemeinsam genutzten Bibliotheken vorkonfigurierte standardisierte Tracingfunktionen bereitstellen, um noch mehr Einblicke in die Frameworks und Bibliotheken zu liefern. Web-weit skalierte Unternehmen wie Uber und Yelp verwenden OpenTracing, um tiefere Einblicke in ihre extrem verteilten und dynamischen Anwendungen zu erhalten.
Das OpenTracing-Datenmodell
Die Grundkonzepte von OpenTracing und das zugrunde liegende Datenmodell stammen aus dem Dapper-Paper von Google. Trace und Span sind wichtige Begriffe.
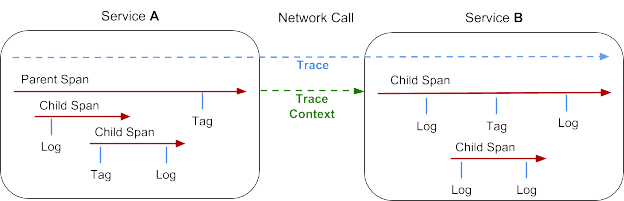
- Ein Trace bildet eine Transaktion ab, die ein verteiltes System durchläuft. Sie können sich Traces als azyklische Graphen von Spans vorstellen.
- Ein Span bildet eine logische Arbeitseinheit mit Name, Startzeit und Dauer ab. Spans können verschachtelt und geordnet werden, um Beziehungen zu modellieren. Spans akzeptieren Tags mit Schlüssel und Wert, sowie differenzierte und strukturierte Logs mit Zeitstempel für die jeweilige Span-Instanz.
- Der Tracing-Kontext sind die Tracinginformationen, die eine verteilte Transaktion begleiten, wenn diese etwa über das Netzwerk oder über einen Nachrichtenbus von Service zu Service weitergegeben wird. Der Kontext identifiziert die Bezeichner für Trace und Span, sowie alle weiteren Daten, die das Tracingsystem braucht, um den nachgeschalteten Service zu verbreiten.
Wie funktioniert das Gesamtkonzept?
Mit der Standardisierung können Tracinginformationen aus benutzerdefiniertem Anwendungscode und gemeinsam genutzten Bibliotheken und Services, die von verschiedenen Abteilungen entwickelt und ausgeführt werden, zur Laufzeit ausgetauscht und wiederverwendet werden, und es macht keinen Unterschied, welchen Tracer diese einzelnen Komponenten verwenden.
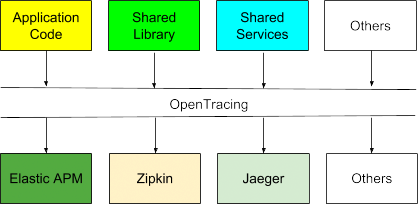
OpenTracing löst jedoch nur die erste der vier architektonischen Herausforderungen, die wir bereits besprochen haben. Wo stehen wir also momentan mit den anderen Komponenten, und was hält die Zukunft für uns bereit?
Wo stehen wir heute?
Wie bereits besprochen definiert OpenTracing einen standardisierten Satz von Tracing-APIs, die von verschiedenen Tracern implementiert werden können. Dies ist ein hervorragender und ermutigender Anfang. Wir brauchen aber immer noch eine Standardisierung für Tracingkontext und Tracingdaten, um diese Komponenten komplett miteinander kompatibel und austauschbar zu machen.
- Die OpenTracing-API stellt eine Reihe von Standard-APIs bereit. Das ist momentan so ziemlich die einzige verfügbare Standardisierung. Und selbst für diese Spezifikation gelten Einschränkungen. Sie deckt beispielsweise nicht alle Programmiersprachen ab. Dennoch ist diese Anstrengung bewundernswert und gewinnt immer mehr Zuspruch.
- Noch keine standardisierte Definition des Tracingkontexts. Die W3C Distributed Tracing-Arbeitsgruppe ist momentan dabei, die Definition des Tracingkontexts zu standardisieren, in der W3C-Tracingkontext-Spezifikation. Diese Spezifikation definiert einen einheitlichen Ansatz für Kontext und Ereigniskorrelierung in verteilten Systemen, um eines Tages End-to-End-Transaktionstracing in verteilten Anwendungen über verschiedene Überwachungstools hinweg zu ermöglichen. Elastic APM unterstützt die Anstrengungen der W3C Trace Context-Arbeitsgruppe zur Standardisierung des HTTP-Headerformats für verteiltes Tracing. Unsere Agent-Implementierungen orientieren sich eng am Spezifikationsentwurf für den Tracingkontext, und wir werden die endgültige Spezifikation vollständig unterstützen.
Als Beispiel für den Kompatibilitätsmangel im aktuellen Tracingkontext zeigen wir Ihnen die HTTP-Header von Elastic APN und Jaeger für die Tracing-ID. Wie Sie sehen, unterscheiden sich sowohl die Namen als auch die Codierungen der IDs. Wenn Sie unterschiedliche Tracingheader verwenden, funktionieren die Traces nicht mehr, wenn die Grenzen zwischen den jeweiligen Tracingtools überschritten werden.
Jaeger:
uber-trace-id: 118c6c15301b9b3b3:56e66177e6e55a91:18c6c15301b9b3b3:1
Elastic APM:
elastic-apm-traceparent: 00-f109f092a7d869fb4615784bacefcfd7-5bf936f4fcde3af0-01
Neben der eigentlichen Definition gibt es noch weitere Herausforderungen. Beispielsweise werden nicht alle HTTP-Header von der Serviceinfrastruktur, den Routern usw. automatisch weitergeleitet. Sobald ein Header verworfen wird, funktioniert das Tracing nicht mehr. - Noch keine Standardisierte Definition von Tracingdaten. Laut der W3C Distributed Tracing-Arbeitsgruppe besteht das zweite Puzzlestück für die Tracingkompatibilität aus „einem standardisierten und erweiterbaren Format zur Weitergabe der Tracingdaten, als komplette Traces oder Fragmente von Traces, zur weiteren Auswertung zwischen verschiedenen Tools“. Sie können sich bestimmt vorstellen, dass es nicht einfach ist, mit allen beteiligten Open-Source- und kommerziellen Anbietern ein gemeinsames Format zu finden. Hoffentlich sind wir bald so weit.
- Tracer sind nicht laufzeitkompatibel. Aus all den bereits besprochenen Gründen und dem gemischten Anreiz, das eigene System offen und kompatibel mit dem Rest der Welt zu machen, sind Tracer momentan zur Laufzeit einfach nicht miteinander kompatibel. Ich kann mit einiger Sicherheit sagen, dass sich diese Lage in absehbarer Zeit nicht ändern wird.
Aktuelle Funktionsweise von Elastic APM mit anderen Tracern
Auch wenn wir momentan noch lange keine vollständige Kompatibilität zwischen Tracern erreicht haben, gibt es keinen Grund, den Mut zu verlieren. Der Elastic Stack kann trotzdem auf verschiedene Arten mit anderen Tracern arbeiten.
- Elasticsearch als skalierbarer Backend-Datenspeicher für andere Tracer.
Wenig überraschend wird Elasticsearch aufgrund der herausragenden Skalierbarkeit und der umfassenden Analysefunktionen als Backend-Datenspeicher für andere Tracer wie Zipkin und Jaeger eingesetzt. Sowohl Zipkin als auch Jaeger können mühelos für die Übertragung von Tracingdaten nach Elasticsearch konfiguriert werden. Sobald sich die Tracingdaten in Elasticsearch befinden, können Sie die leistungsstarken Analyse- und Visualisierungsfunktionen von Kibana nutzen, um Ihre Tracinginformationen auszuwerten und ansprechende Visualisierungen zu erstellen, mit denen Sie tiefe Einblicke in die Leistung Ihrer Anwendungen erhalten. - Elastic OpenTracing-Bridge
Mit der Elastic APM OpenTracing-Bridge können Sie Transaktionen und Spans für Elastic APM mit der OpenTracing API erstellen. Diese Komponente übersetzt also die Aufrufe an die OpenTracing API für Elastic APM und ermöglicht die Wiederverwendung vorhandener Instrumentierungen. Sie können beispielsweise eine vorhandene Jaeger-Instrumentierung durch Elastic APM ersetzen, indem Sie lediglich eine Handvoll Codezeilen anpassen.
Ursprüngliche Jaeger-Instrumentierung:
import io.opentracing.Scope; import io.opentracing.Tracer; import io.jaegertracing.Configuration; import io.jaegertracing.internal.JaegerTracer; ... private void sayHello(String helloTo) { Configuration config = ... Tracer tracer = config.getTracer(); try (Scope scope = tracer.buildSpan("say-hello").startActive(true)) { scope.span().setTag("hello-to", helloTo); } ... }Wir ersetzen Jaeger durch die Elastic OpenTracing-Bridge:
import io.opentracing.Scope; import io.opentracing.Tracer; import co.elastic.apm.opentracing.ElasticApmTracer; ... private void sayHello(String helloTo) { Tracer tracer = new ElasticApmTracer(); try (Scope scope = tracer.buildSpan("say-hello").startActive(true)) { scope.span().setTag("hello-to", helloTo); } ... }
Mit dieser einfachen Änderung werden die Tracingdaten komplett nach Elastic APM weitergeleitet, ohne dass Sie den restlichen Tracingcode ändern müssen. So einfach geht OpenTracing!
Elastic APM Real User Monitoring
Während wir uns bei der Besprechung von Tracing, Kontextübergabe usw. hauptsächlich auf die Backend-Services konzentrieren, ist es ebenso wichtig, das Tracing bereits auf der Clientseite im Browser zu beginnen. Auf diese Weise erhalten Sie bereits Tracinginformationen, wenn ein Benutzer ein Element im Browser anklickt. Diese Tracingdaten bilden das tatsächliche Benutzererlebnis Ihrer Anwendungen im Hinblick auf die Leistung ab. Leider gibt es auch hier keinen standardisierten Weg, um diese Informationen weiterzuleiten. Die W3C-Gruppe hat jedoch vor, den Tracingkontext in Zukunft auch bis hin zum Browser auszuweiten.
Elastic APM Real User Monitoring (RUM) liefert genau diese Funktionen bereits heute. Der RUM JS Agent überwacht das tatsächliche Benutzererlebnis in Ihrer clientseitigen Anwendung. Sie können Metriken wie „Zeit bis zum ersten Byte“, domInteractive und domComplete messen, um Leistungsprobleme in Ihrer clientseitigen Anwendung und andere Probleme im Zusammenhang mit der Latenz Ihrer serverseitigen Anwendung zu erkennen. Unser RUM JS Agent ist unabhängig vom Framework und kann daher mit beliebigen JavaScript-basierten Frontend-Anwendungen eingesetzt werden.
<p?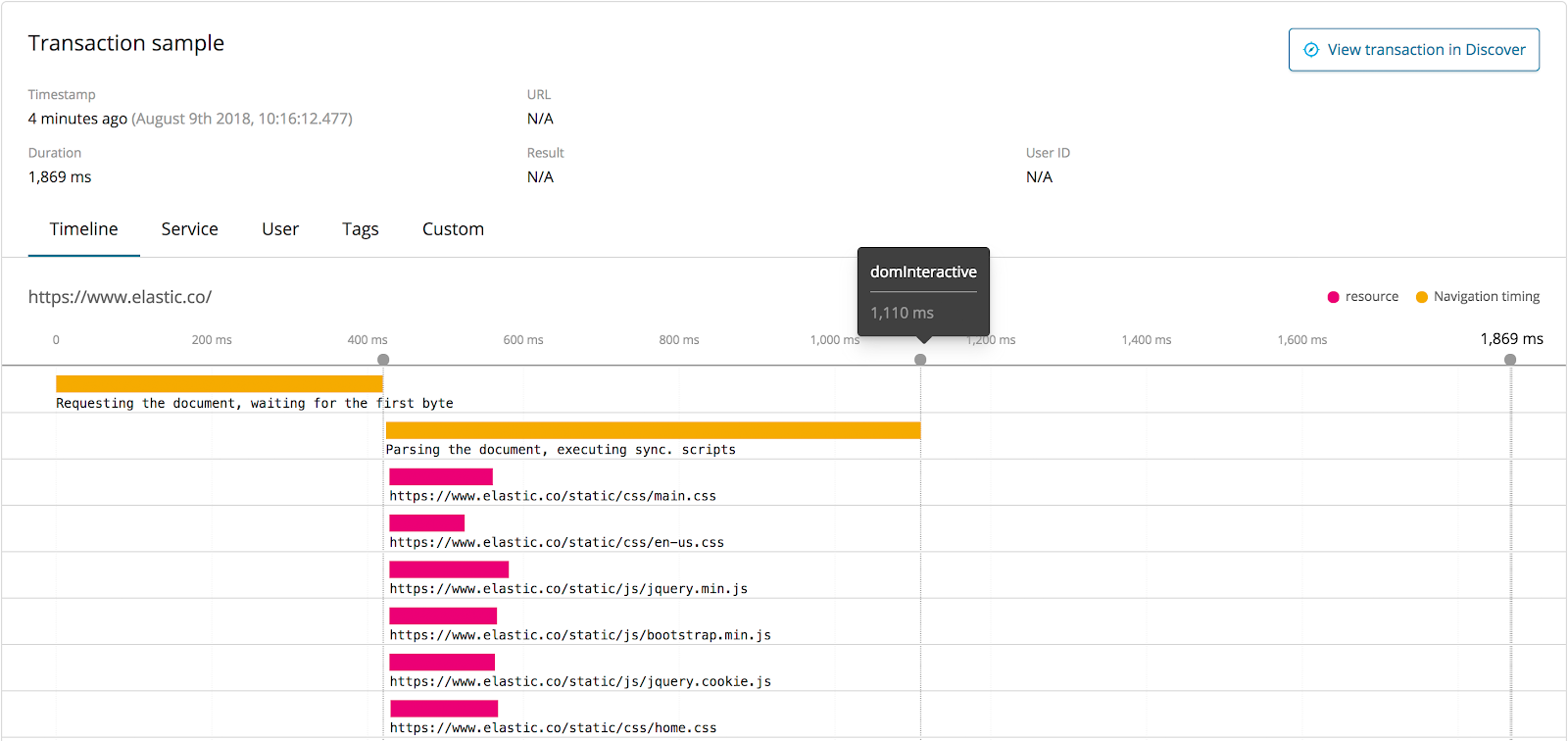
Zusammenfassung
Hoffentlich hat Ihnen dieser Beitrag geholfen, das Thema verteiltes Tracing etwas besser zu verstehen und einige der Missverständnisse zum aktuellen Stand von OpenTracing aufzuklären. Fassen wir unsere Erkenntnisse zum Abschluss zusammen:
- Verteiltes Tracing liefert wertvolle Leistungseinblicke für Microservices.
- OpenTracing ist der erste Standardisierungsschritt der Branche für verteiltes Tracing. Der Weg hin zur vollständigen Kompatibilität ist noch weit.
- Elastic APM unterstützt OpenTracing.
- Mit der Elastic OpenTracing Bridge können Sie Ihre vorhandene Instrumentierung wiederverwenden.
- Der Elastic Stack ist ein hervorragender langfristiger Speicher für andere Tracer wie Zipkin oder Jaeger, auch ohne vollständige Kompatibilität zur Laufzeit.
- Elastic bietet umfassende Analysen für Tracingdaten aus Elastic oder anderen Systemen. Zipkin und Jaeger können mühelos für die Übertragung von Tracingdaten nach Elasticsearch konfiguriert werden.
- Elastic APM Real User Monitoring (RUM) überwacht das tatsächliche Benutzererlebnis in Ihrer clientseitigen Anwendung.
- Elastic ist eine hervorragend skalierbare, leistungsstarke und einheitliche Analyseplattform für alle drei Grundpfeiler der Beobachtbarkeit: Logs, Metriken und Tracing.
Im Elastic APM Forum können Sie wie immer jederzeit eine Diskussion eröffnen oder Fragen stellen. Viel Spaß beim Tracing!