From vector search to powerful REST APIs, Elasticsearch offers developers the most extensive search toolkit. Dive into sample notebooks on GitHub to try something new. You can also start your free trial or run Elasticsearch locally today.
Plagiarism can be direct, involving the copying of parts or the entire content, or paraphrased, where the author's work is rephrased by changing some words or phrases.
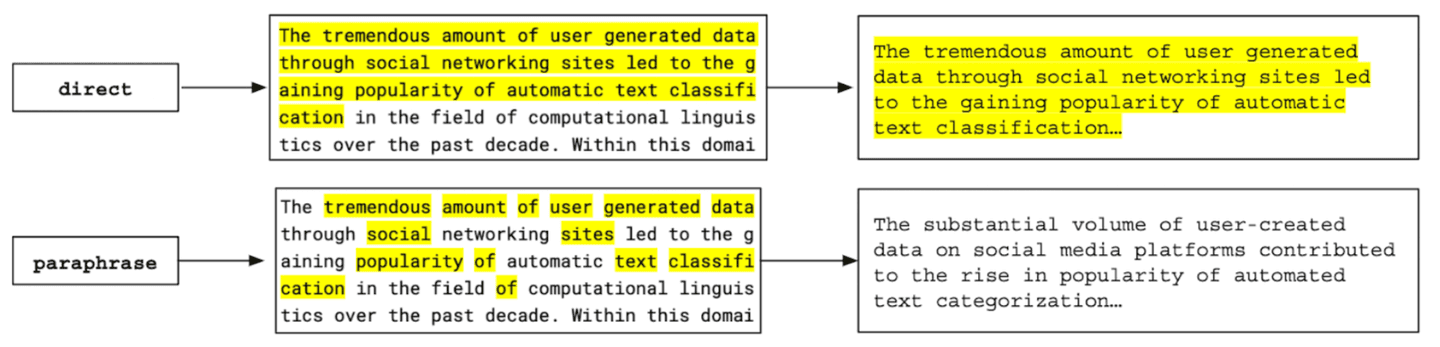
There is a distinction between inspiration and paraphrasing. It is possible to read a content, get inspired, and then explore the idea with your own words, even if you come to a similar conclusion.
While plagiarism has been a topic of discussion for a long time, the accelerated production and publication of content have kept it relevant and posed an ongoing challenge.
This challenge isn't limited to books, academic research, or judicial documents, where plagiarism checks are frequently conducted. It can also extend to newspapers and even social media.
With the abundance of information and easy access to publishing, how can plagiarism be effectively checked on a scalable level?
Universities, government entities, and companies employ diverse tools, but while a straightforward lexical search can effectively detect direct plagiarism, the primary challenge lies in identifying paraphrased content.
Plagiarism detection with Generative AI
A new challenge emerges with Generative AI. Is content generated by AI considered plagiarism when copied?
The OpenAI terms of use, for example, specify that OpenAI will not claim copyright over content generated by the API for users. In this case, individuals using their Generative AI can use the generated content as they prefer without citation.

However, the acceptance of using Generative AI to improve efficiency remains a topic of discussion.
In an effort to contribute to plagiarism detection, OpenAI developed a detection model but later acknowledged that its accuracy is not sufficiently high.
"We believe this is not high enough accuracy for standalone detection and needs to be paired with metadata-based approaches, human judgment, and public education to be more effective."
The challenge persists; however, with the availability of more tools, there are now increased options for detecting plagiarism, even in cases of paraphrased and AI content.
Detecting plagiarism with Elasticsearch
Recognizing this, in this blog we are exploring one more use case with Natural Language Processing (NLP) models and Vector Search, plagiarism detection, beyond metadata searches.
This is demonstrated with Python examples, where we utilize a dataset from SentenceTransformers containing NLP-related articles. We check the abstracts for plagiarism by performing 'semantic textual similarity' considering 'abstract' embeddings generated with a text embedding model previously imported into Elasticsearch. Additionally, to identify AI-generated content — AI plagiarism, an NLP model developed by OpenAI was also imported into Elasticsearch.
The following image illustrates the data flow:
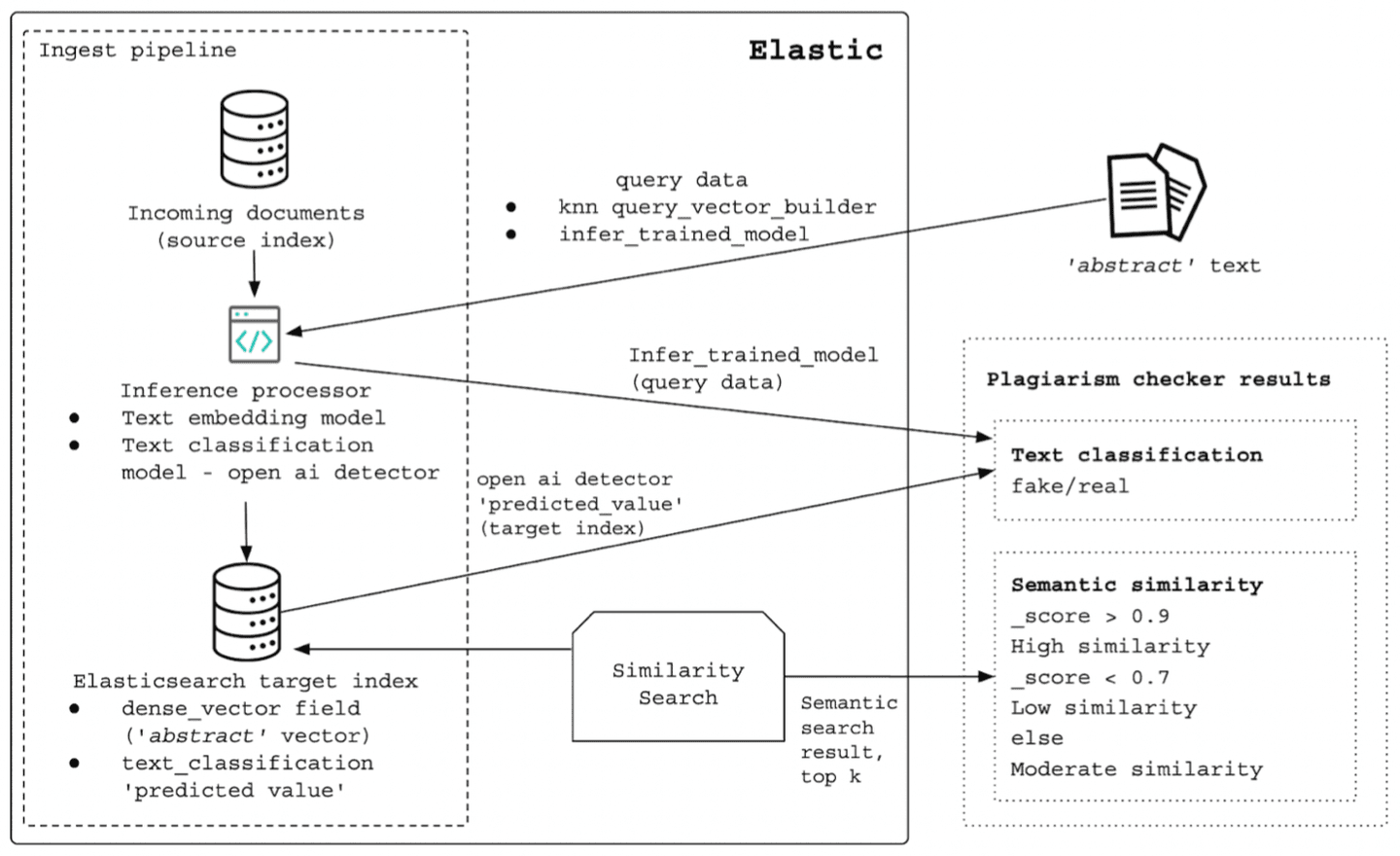
During the ingest pipeline with an inference processor, the 'abstract' paragraph is mapped to a 768-dimensional vector, the 'abstract_vector.predicted_value'.
Mapping:
The similarity between vector representations is measured using a vector similarity metric, defined using the 'similarity' parameter.
Cosine is the default similarity metric, computed as '(1 + cosine(query, vector)) / 2'. Unless you need to preserve the original vectors and cannot normalize them in advance, the most efficient way to perform cosine similarity is to normalize all vectors to unit length. This helps avoid performing extra vector length computations during the search, instead use 'dot_product'.
In this same pipeline, another inference processor containing the text classification model detects whether the content is 'Real' probably written by humans, or 'Fake' probably written by AI, adding the 'openai-detector.predicted_value' to each document.
Ingest Pipeline:
At query time, the same text embedding model is also employed to generate the vector representation of the query 'model_text' in a 'query_vector_builder' object.
A k-nearest neighbor (kNN) search finds the k nearest vector to the query vector measured by the similarity metric.
The _score of each document is derived from the similarity, ensuring that a larger score corresponds to a higher ranking. This means that the document is more similar semantically. As a result, we are printing three possibilities: if score > 0.9, we are considering 'high similarity'; if < 0.7, 'low similarity’, otherwise, 'moderate similarity’. You have the flexibility to set different threshold values to determine what level of _score qualifies as plagiarism or not, based on your use case.
Additionally, text classification is performed to also check for AI-generated elements in the text query.
Query:
Output:
In this example, after utilizing one of the 'abstract' values from our dataset as the text query 'model_text', plagiarism was identified. The similarity score is 1.0, indicating a high level of similarity — direct plagiarism. The vectorized query and document were not recognized as AI-generated content, which was expected.
Query:
Output:
By updating the text query 'model_text' with an AI-generated text that conveys the same message while minimizing the repetition of similar words, the detected similarity was still high, but the score was 0.9302529 instead of 1.0 — paraphrase plagiarism. It was also expected that this query, which was generated by AI, would be detected.
Lastly, considering the text query 'model_text' as a text about Elasticsearch, which is not an abstract of one of these documents, the detected similarity was 0.68991005, indicating low similarity according to the considered threshold values.
Query:
Output:
Although plagiarism was accurately identified in the text query generated by AI, as well as in cases of paraphrasing and direct copied content, navigating the landscape of plagiarism detection involves acknowledging various aspects.
In the context of AI-generated content detection, we explored a model that makes a valuable contribution. However, it is crucial to recognize the inherent limitations in standalone detection, necessitating the incorporation of other methods to boost the accuracy.
The variability introduced by the choice of text embedding models is another consideration. Different models, trained with distinct datasets, result in varying levels of similarity, highlighting the importance of the text embeddings generated.
Lastly, in these examples, we used the document's abstract. However, plagiarism detection often involves large documents, making it essential to address the challenge of text length. It is common for the text to exceed a model's token limit, requiring segmentation into chunks before building embeddings. A practical approach to handling this involves utilizing nested structures with dense_vector.
Conclusion
In this blog, we discussed the challenges of detecting plagiarism, particularly in paraphrased and AI-generated content, and how semantic textual similarity and text classification can be used for this purpose.
By combining these methods, we provided an example of plagiarism detection where we successfully identified AI-generated content, direct and paraphrased plagiarism.
The primary goal was to establish a filtering system that simplifies detection but human assessment remains essential for validation.
If you are interested in learning more about semantic textual similarity and NLP, we encourage you to also check out these links:
Related Content

January 28, 2026
Apache Lucene 2025 wrap-up
2025 was a stellar year for Apache Lucene; here are our highlights.
December 23, 2025
Comparing dense vector search performance with the Profile API in Elasticsearch
Learn how to use the Profile API in Elasticsearch to compare dense vector configurations and tune kNN performance with visual data from Kibana.

December 3, 2025
Up to 12x Faster Vector Indexing in Elasticsearch with NVIDIA cuVS: GPU-acceleration Chapter 2
Discover how Elasticsearch achieves nearly 12x higher indexing throughput with GPU-accelerated vector indexing and NVIDIA cuVS.

November 4, 2025
Multimodal search for mountain peaks with Elasticsearch and SigLIP-2
Learn how to implement text-to-image and image-to-image multimodal search using SigLIP-2 embeddings and Elasticsearch kNN vector search. Project focus: finding Mount Ama Dablam peak photos from an Everest trek.

November 3, 2025
Improving multilingual embedding model relevancy with hybrid search reranking
Learn how to improve the relevancy of E5 multilingual embedding model search results using Cohere's reranker and hybrid search in Elasticsearch.