From vector search to powerful REST APIs, Elasticsearch offers developers the most extensive search toolkit. Dive into sample notebooks on GitHub to try something new. You can also start your free trial or run Elasticsearch locally today.
Did you know that Elastic can be used as a powerful vector database? In this blog, we’ll explore how to generate, store, and query vector embeddings alongside traditional lexical search. Elastic’s strength lies in its flexibility and scalability, making it an excellent choice for modern search use cases. By integrating vector embeddings with Elastic, you can improve search relevance, and enhance search capabilities across various data types—including non-textual documents like images.
But it gets even better! Learning Elastic’s search features can be fun too. In this article, we’ll show you how to search for your favorite cats using Elastic to search both text descriptions and images of cats. Through a simple Python app that accompanies this article, you’ll learn how to implement both vector and keyword-based searches. We’ll guide you through generating your own vector embeddings, storing them in Elastic and running hybrid queries - all while searching for adorable feline friends.
Whether you're an experienced developer or new to Elasticsearch, this fun project is a great way to understand how modern search technologies work. Plus, if you love cats, you'll find it even more engaging. So let’s dive in and set up the Elasticats app while exploring Elasticsearch’s powerful capabilities.
Before we begin, let’s make sure that you have your Elastic cloud ID and API key ready. Make a copy of the .env-template file, save it as .env and plug in your Elastic cloud credentials.
Application architecture
Here’s a high-level diagram that depicts our application architecture:
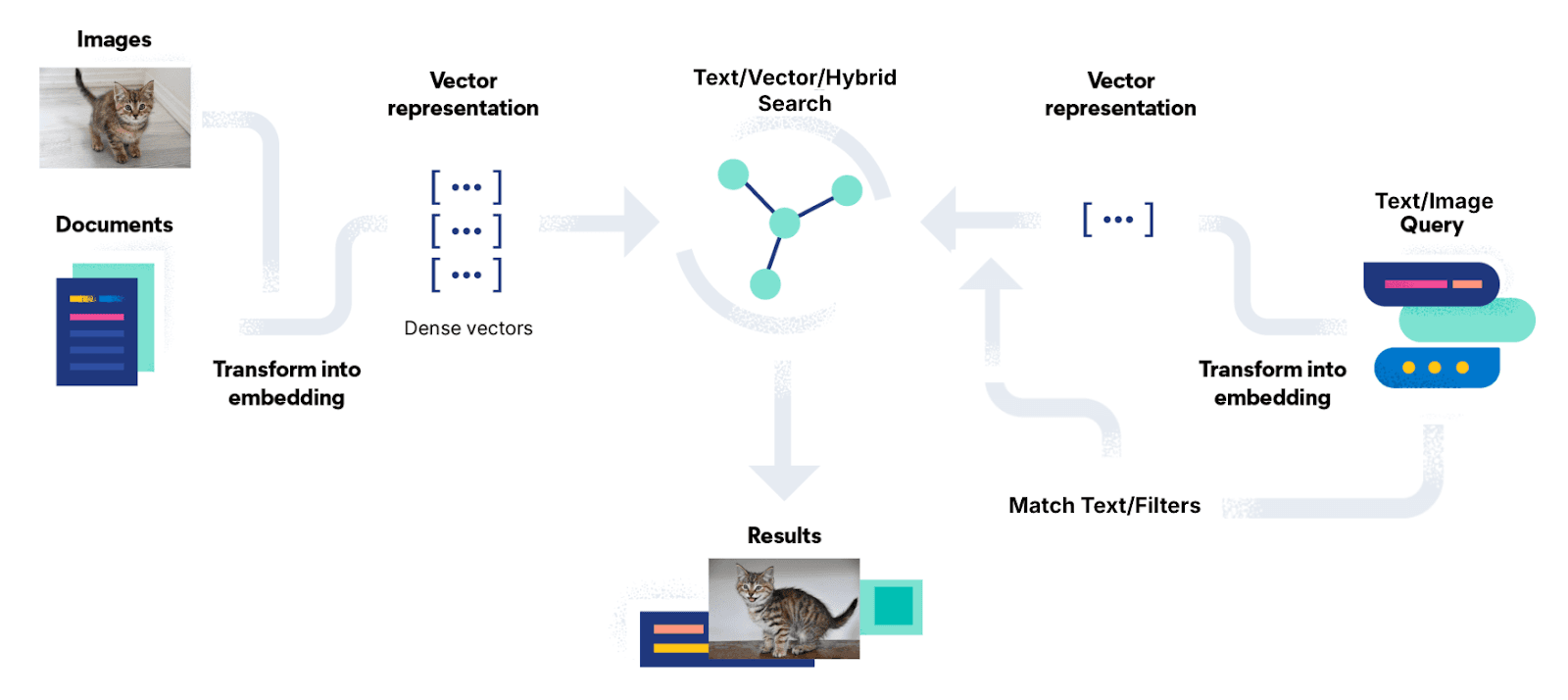
Generating and storing vector embeddings
Before we can perform any type of search, we first need to have data. Our data.json contains the list of cat documents that we will index in Elasticsearch. Each document describes a cat and has the following mappings:
Each cat’s photo property points to the location of the cat’s image. When we call the reindex function in our application, it will generate two embeddings:
1. First is a vector embedding for each cat’s image. We used the clip-ViT-B-32 model. Image models allow you to embed images and text into the same vector space. This allows you to implement image search either as text-to-image or image-to-image search.
2. The second embedding is for the summary text about each cat that is up for adoption. We used a different model which is all-MiniLM-L6-v2.
We then store the embeddings as part of our documents.
We’re now ready to call the reindex function.
From the terminal, run the following command:
We can now run our web application:
Our initial form looks like this:
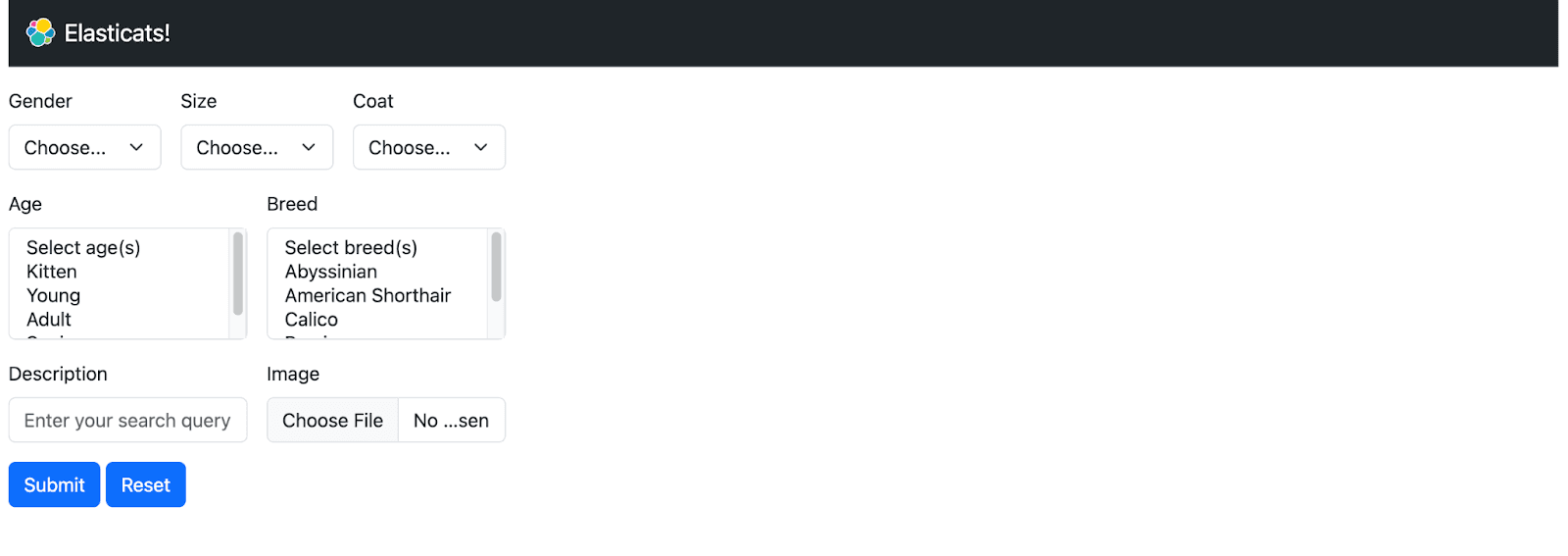
As you can see, we have exposed some of the keywords as filters (e.g. age, gender, size, etc.) that we will use as part of our queries.
Executing different types of searches
The following workflow diagram shows the different search paths available in our web application. We’ll walk through each scenario.
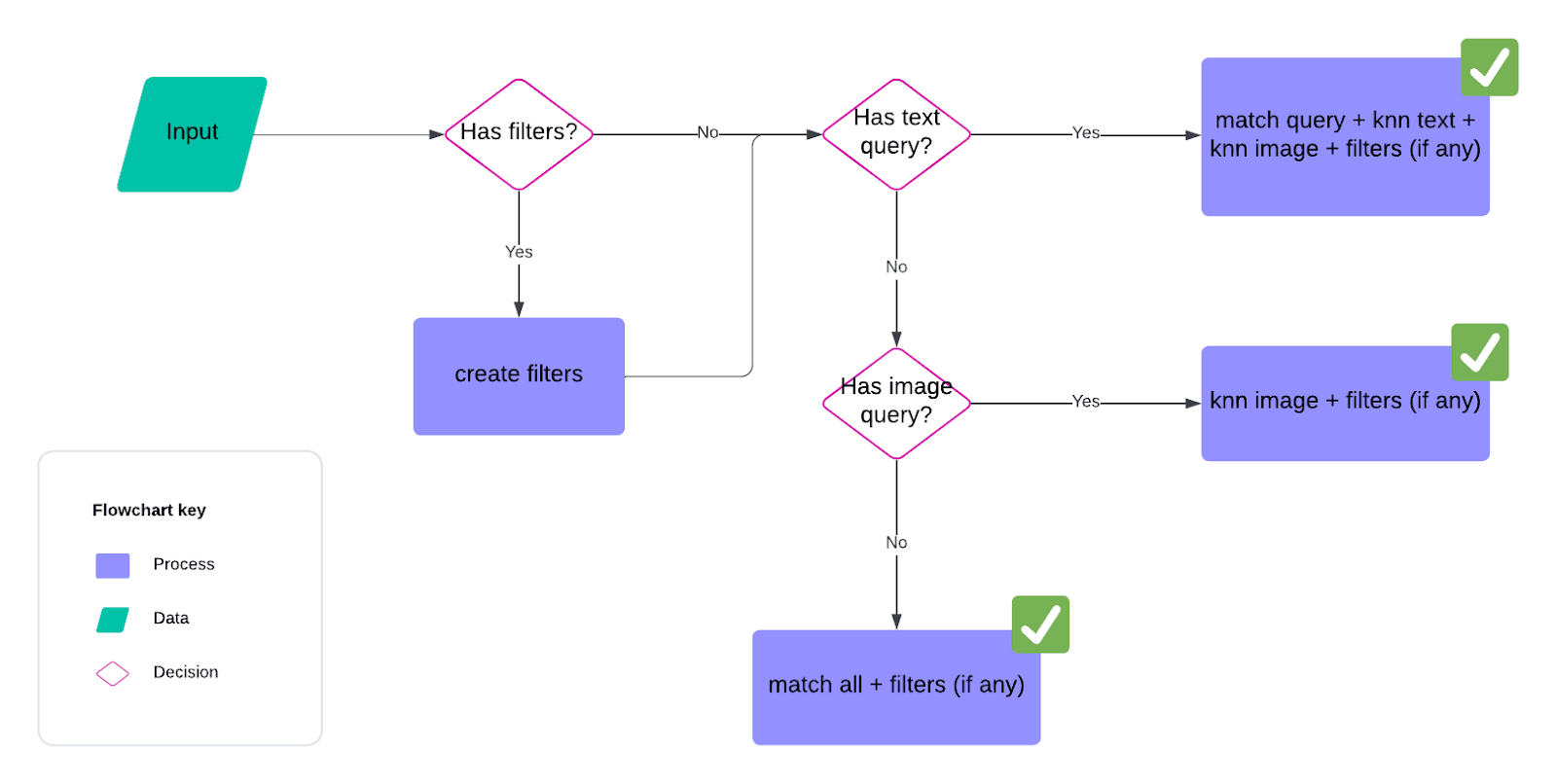
Lexical search
The simplest scenario is a “match all” query which basically returns all cats in our index. We don’t use any of the filters nor enter a description or upload an image.
If any of the filters were supplied in the form, then we perform a boolean query. In this scenario, no description is entered so we’re applying the filters in our “match all” query.
Vector search
In our web form, we are able to upload a similar image of a cat(s). By uploading an image, we can do a vector search by transforming the uploaded image into an embedding and then performing a knn search on the image embeddings that were previously stored.
First, we save the uploaded image in an uploads folder.
We then create a knn query for the image embedding.
Notice that the vector search can be performed with or without the filters (from the boolean query). Also, note that k=5 which means that we’re only returning the top 5 similar documents (cats).
Try any of these images stored in the images/<breed> folder:
- Abyssinian
- Dahlia - 72245105_3.jpg
- American shorthair
- Uni - 64635658_2.jpg
- Sugarplum - 72157682_4.jpeg
- Persian
- Sugar - 72528240_2.jpeg
Hybrid search
The most complex scenario in our application is when some text is entered into the description field. Here, we perform 3 different types of search and combine them into a hybrid search. First, we perform a lexical “match” query on the actual text input.
We also create 2 knn queries:
- Using the model for the text embedding, we generate an embedding for the text input and perform a knn search on the summary embedding.
- Using the model for the image embedding, we generate another embedding for the text input and perform a knn search on the image embedding. I mentioned earlier that image models allow you to do not just an image-to-image search as we’ve seen in the vector search scenario above, but it also allows you to do a text-to-image search. This means that if I type “black cats” in the description, it will search for images that may contain or resemble black cats!
We then utilize the Reciprocal Rank Fusion (RRF) retriever to effectively combine and rank the results from all three queries into a single cohesive result set.
RRF is a method designed to merge multiple result sets, each with potentially different relevance indicators, into one unified set. Unlike simply joining the result arrays, RRF applies a specific formula to rank documents based on their positions in the individual result sets. This approach ensures that documents appearing in multiple queries are given higher importance, leading to improved relevance and quality of the final results. By using RRF, we avoid the complexities of manually tuning weights for each query and achieve a balanced integration of diverse search strategies.
To further illustrate, the following is a table showing the ranking of the individual result sets when we search for “sisters”. Using the RRF formula (with the default ranking constant k=60), we can then derive the final score for each document. Sorting the final scores in descending order then gives us the final ranking of the documents. “Willow & Nova” is our top hit (cat)!
| Cat (document) | Lexical ranking | knn (on img_embedding) ranking | knn (on summary_embedding) ranking | Final Score | Final Ranking |
|---|---|---|---|---|---|
| Sugarplum | 1 | 3 | 0.0322664585 | 2 | |
| Willow & Nova | 2 | 1 | 1 | 0.0489159175 | 1 |
| Zoe & Zara | 2 | 0.01612903226 | 4 | ||
| Sage | 3 | 2 | 0.03200204813 | 3 | |
| Primrose | 4 | 0.015625 | 5 | ||
| Dahlia | 5 | 0.01538461538 | 7 | ||
| Luke & Leia | 4 | 0.015625 | 6 | ||
| Sugar & Garth | 5 | 0.01538461538 | 8 |
Here are some other tests you can use for the description:
- “sisters” vs “siblings”
- “tuxedo”
- “black cats” with “American shorthair” breed filter
- “white”
Conclusion
Besides the obvious — **cats!** — Elasticats is a fantastic way to get to know Elasticsearch. It’s a fun and practical project that lets you explore search technologies while reminding us of the joy that technology can bring. As you dive deeper, you’ll also discover how Elasticsearch’s ability to handle vector embeddings can unlock new levels of search functionality. Whether it’s for cats, images, or other data types, Elastic makes search both powerful and enjoyable!
Feel free to contribute to the project or fork the repository to customize it further. Happy searching, and may you find the cat of your dreams! 😸
Related Content

January 28, 2026
Apache Lucene 2025 wrap-up
2025 was a stellar year for Apache Lucene; here are our highlights.
December 23, 2025
Comparing dense vector search performance with the Profile API in Elasticsearch
Learn how to use the Profile API in Elasticsearch to compare dense vector configurations and tune kNN performance with visual data from Kibana.

December 3, 2025
Up to 12x Faster Vector Indexing in Elasticsearch with NVIDIA cuVS: GPU-acceleration Chapter 2
Discover how Elasticsearch achieves nearly 12x higher indexing throughput with GPU-accelerated vector indexing and NVIDIA cuVS.

November 4, 2025
Multimodal search for mountain peaks with Elasticsearch and SigLIP-2
Learn how to implement text-to-image and image-to-image multimodal search using SigLIP-2 embeddings and Elasticsearch kNN vector search. Project focus: finding Mount Ama Dablam peak photos from an Everest trek.

November 3, 2025
Improving multilingual embedding model relevancy with hybrid search reranking
Learn how to improve the relevancy of E5 multilingual embedding model search results using Cohere's reranker and hybrid search in Elasticsearch.