Elastic Serverless Forwarder for AWS
editElastic Serverless Forwarder for AWS
editThe Elastic Serverless Forwarder is an Amazon Web Services (AWS) Lambda function that ships logs from your AWS environment to Elastic.
The Elastic Serverless Forwarder works with Elastic Stack 7.17 and later.
Using Elastic Serverless Forwarder may result in additional charges. To learn how to minimize additional charges, refer to Preventing unexpected costs.
Overview
editThe Elastic Serverless Forwarder can forward AWS data to cloud-hosted, self-managed Elastic environments, or [preview] This functionality is in technical preview and may be changed or removed in a future release. Elastic will work to fix any issues, but features in technical preview are not subject to the support SLA of official GA features. Logstash. It supports the following inputs:
- Amazon S3 (via SQS event notifications)
- Amazon Kinesis Data Streams
- Amazon CloudWatch Logs subscription filters
- Amazon SQS message payload
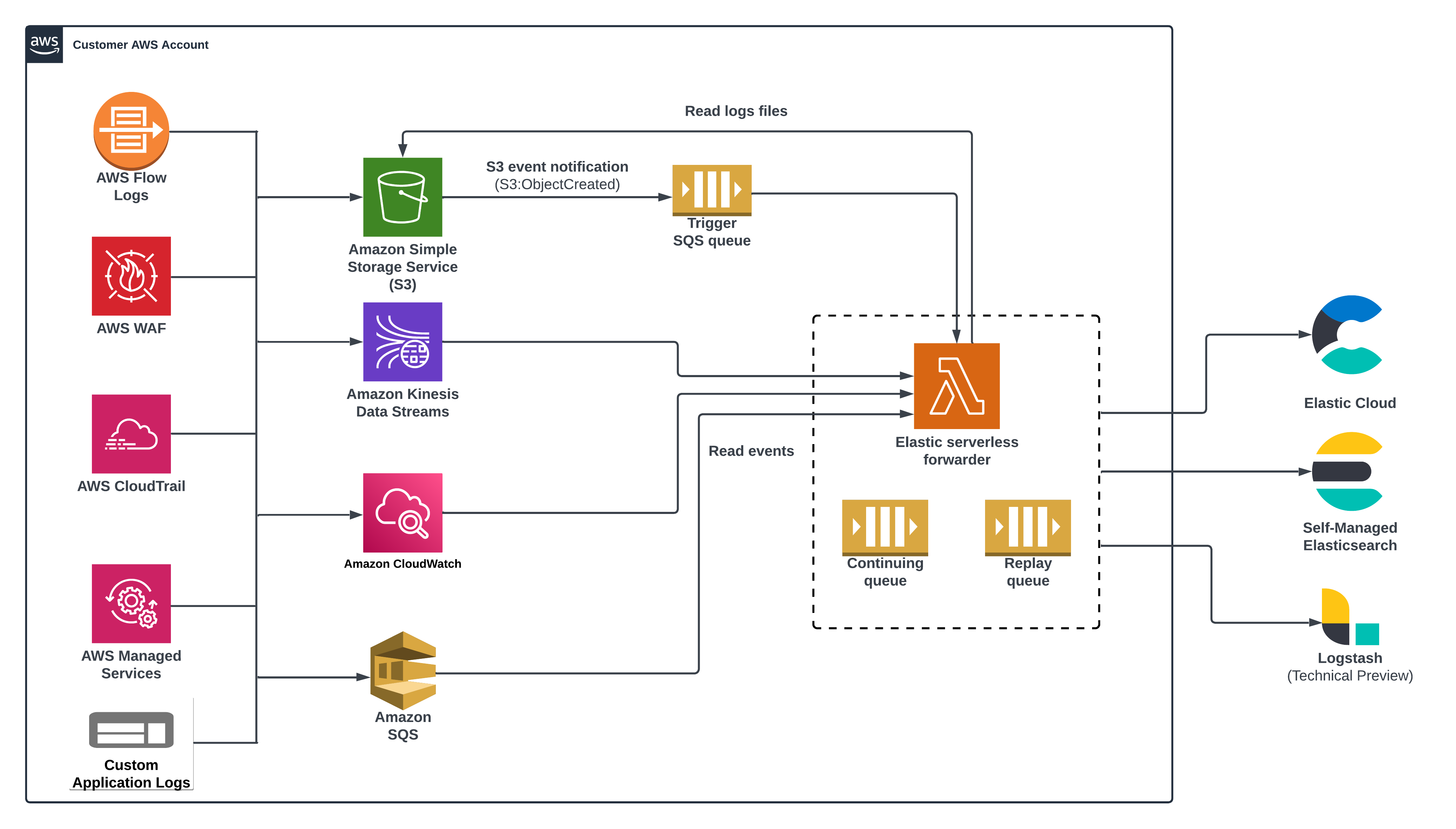
Elastic Serverless Forwarder ensures at-least-once delivery of the forwarded message.
When you successfully deploy the forwarder, an SQS continuing queue is automatically created in Lambda to ensure no data is lost. By default, the forwarder runs for a maximum of 15 minutes, so it’s possible that AWS may exit the function in the middle of processing event data. The forwarder handles this scenario by keeping track of the last offset processed. When the queue triggers a new function invocation, the forwarder will start where the last function run stopped.
The forwarder uses a replay queue (also automatically created during deployment) to handle any ingestion-related exception or fail scenarios. Data in the replay queue is stored as individual events. Lambda keeps track of any failed events and writes them to the replay queue that can then be consumed by adding it as an additional SQS trigger via Lambda.
You can use the config.yaml file to configure the service for each input and output type, including information such as SQS queue ARN (Amazon Resource Number) and Elasticsearch or Logstash connection details. You can create multiple input sections within the configuration file to map different inputs to specific log types.
There is no need to define a specific input in the config.yaml for the continuing queue and the replay queue.
The forwarder also supports writing directly to an index, alias, or custom data stream. This enables existing Elasticsearch users to re-use index templates, ingest pipelines, or dashboards that are already created and connected to other processes.
Inputs
editAmazon S3 (via SQS event notifications)
editThe forwarder can ingest logs contained in an Amazon Simple Storage Service (S3) bucket through a Simple Queue Service (SQS) notification (s3:ObjectCreated) and send them to Elastic. The SQS queue serves as a trigger for the forwarder. When a new log file is written to an S3 bucket and meets the user-defined criteria (including prefix/suffix), an SQS notification is generated that triggers the Lambda function.
You can set up separate SQS queues for each type of log (for example, aws.vpcflow, aws.cloudtrail, aws.waf). A single configuration file can have many input sections, pointing to different SQS queues that match specific log types. The es_datastream_name parameter in the config file is optional. The forwarder supports automatic routing of various AWS service logs to the corresponding data streams for further processing and storage in the Elasticsearch cluster. It supports automatic routing of aws.cloudtrail, aws.cloudwatch_logs, aws.elb_logs, aws.firewall_logs, aws.vpcflow, and aws.waf logs.
For other log types, you can optionally set the es_datastream_name value in the configuration file according to the naming convention of the Elasticsearch data stream and integration. If the es_datastream_name is not specified, and the log cannot be matched with any of the above AWS services, then the dataset will be set to generic and the namespace set to default, pointing to the data stream name logs-generic-default.
For more information on creating SQS event notifications for S3 buckets, read the AWS documentation.
You must set a visibility timeout of 910 seconds for any SQS queues you want to use as a trigger. This is 10 seconds greater than the Elastic Serverless Forwarder Lambda timeout.
Amazon Kinesis Data Streams
editThe forwarder can ingest logs contained in the payload of a Kinesis Data Stream record and send them to Elastic. The Kinesis Data Stream serves as a trigger for the forwarder. When a new record gets written to a Kinesis Data Stream, it triggers the Lambda function.
You can set up separate Kinesis Data Streams for each type of log. The es_datastream_name parameter in the config file is mandatory. If this value is set to an Elasticsearch data stream, the type of log must be correctly defined with configuration parameters. A single configuration file can have many input sections, pointing to different data streams that match specific log types.
Amazon CloudWatch Logs subscription filters
editThe forwarder can ingest logs contained in the message payload of CloudWatch Logs events and send them to Elastic. The CloudWatch Logs service serves as a trigger for the forwarder. When a new event gets written to a CloudWatch Logs log stream, it triggers the Lambda function.
You can set up separate CloudWatch Logs groups for each type of log. The es_datastream_name parameter in the config file is mandatory. If this value is set to an Elasticsearch data stream, the type of log must be correctly defined with configuration parameters. A single configuration file can have many input sections, pointing to different CloudWatch Logs groups that match specific log types.
Amazon SQS message payload
editThe forwarder can ingest logs contained within the payload of an Amazon SQS body record and send them to Elastic. The SQS queue serves as a trigger for the forwarder. When a new record gets written to an SQS queue, the Lambda function triggers.
You can set up a separate SQS queue for each type of log. The config parameter for Elasticsearch output es_datastream_name is mandatory. If this value is set to an Elasticsearch data stream, the type of log must be correctly defined with configuration parameters. A single configuration file can have many input sections, pointing to different SQS queues that match specific log types.
At-least-once delivery
editThe Elastic Serverless Forwarder ensures at-least-once delivery of the forwarded messages by using the continuing queue and replay queue.
Continuing queue
editThe Elastic Serverless Forwarder can run for a maximum amount of time of 15 minutes. Different inputs can trigger the Elastic Serverless Forwarder, with different payload sizes for each execution trigger. The size of the payload impacts the number of events to be forwarded. Configuration settings may also impact the number of events, such as defining include/exclude filters, expanding events from JSON object lists, and managing multiline messages.
The continuing queue helps ensure at-least-once delivery when the maximum amount of time (15 minutes) is not sufficient to forward all the events resulting from a single execution of the Elastic Serverless Forwarder.
For this scenario, a grace period of two minutes is reserved at the end of the 15 minute timeout to handle any remaining events that have not been processed. At the beginning of this grace period, event forwarding is halted. The remaining time is dedicated to sending a copy of the original messages that contain the remaining events to the continuing queue. This mechanism removes the need to handle partial processing of the trigger at the input level, which is not always possible (for example in the case of Amazon CloudWatch Logs subscription filters) or desirable because it forces users to conform to a specific configuration of the AWS resources used as inputs.
Each message in the continuing queue contains metadata related to the last offset processed and a reference to the original input.
You can remove a specific input as a trigger of the Elastic Serverless Forwarder. However, before removing its definition from the config.yaml, ensure that all the events generated while the input was still a trigger are fully processed, including the ones in the messages copied to the continuing queue. The handling of the messages in the continuing queue requires a lookup of the original input in the config.yml.
In the unlikely scenario that the Elastic Serverless Forwarder exceeds its maximum allocated execution time and is forcefully terminated, the continuing queue will not be properly populated with a copy of the messages left to be processed. In this scenario, all or a portion of the messages might be lost depending on the specific AWS resource used as input and its configuration.
An AWS SQS Dead Letter Queue is created for the continuing queue.
When the Elastic Serverless Forwarder is triggered by the continuing queue, in the unlikely scenario that it exceeds its maximum allocated execution time and is forcefully terminated, the messages in the payload that triggered the Elastic Serverless Forwarder execution are not deleted from the continuing queue and another Elastic Serverless Forwarder execution is triggered. The continuing queue is configured for a number of 3 maximum receives before a message is sent to the DLQ.
Replay queue
editThe Elastic Serverless Forwarder forwards events to the outputs defined for a specific input. Events to be forwarded are grouped in batches that can be configured according to the specific output. Failures can happen when forwarding events to an output. Depending on the output type, the granularity of the failure can either be for the whole batch of events, or for single events in the batch. There are multiple reasons for a failure to happen, including, but not limited to, network connectivity or the output service being unavailable or under stress.
The replay queue helps ensure at-least-once delivery when a failure in forwarding an event happens.
For this scenario, after a batch of events is forwarded, a copy of all the events in the batch that failed to be forwarded is sent to the replay queue. Each message sent to the replay queue contains exactly one event that failed to be forwarded.
It is possible to enable the replay queue as a trigger of the Elastic Serverless Forwarder in order to forward the events in the queue again.
Before enabling or disabling the replay queue as a trigger of the Elastic Serverless Forwarder, consider the specific reason why the forwarding failures occurred. In most cases, you should resolve the underlying issue causing the failures before trying to forward the events in the queue again. Depending on the nature and impact of the issue, forwarding the events again without solving the problem may produce new failures and events going back to the replay queue. In some scenarios, like the output service being under stress, it is recommended that you disable the replay queue as a trigger of the Elastic Serverless Forwarder, since continuing to forward the events could worsen the issue.
When the Elastic Serverless Forwarder is triggered by the replay queue and all events are successfully forwarded, the Elastic Serverless Forwarded execution succeeds, and the messages in the trigger payload are removed automatically from the replay queue.
However, if any events fail again to be forwarded, all messages in the trigger payload that contain successful events are deleted, and a specific expected exception is raised. The Elastic Serverless Forwarder execution is marked as failed, and any failed messages are sent back to the replay queue.
The messages in the replay queue contain metadata with references to the original input and the original output of the events.
You can remove a specific input as a trigger of the Elastic Serverless Forwarder. However, before removing its definition from config.yaml, ensure that all the events that failed to be ingested while the input was still a trigger are fully processed. The handling of the messages in the replay queue requires a lookup of the original input and output in the config.yml.
An AWS SQS Dead Letter Queue (DLQ) is created for the replay queue.
The same message can go back to the replay queue up to three times. After reaching the configured number of 3 maximum receives, the message will be sent to the DLQ. The same message can go back to the replay queue either because it contains an event that failed again to be forwarded, according to the planned design, or in the unlikely scenario that the Elastic Serverless Forwarder triggered by the queue exceeds its maximum allocated execution time and is forcefully terminated. In this scenario the messages will not be lost and will eventually be sent to the DQL.