Deploy Elastic Serverless Forwarder
editDeploy Elastic Serverless Forwarder
editTo deploy Elastic Serverless Forwarder, you have to:
Prerequisites
editThis documentation assumes you have some familiarity with AWS services, and you have correctly created and configured the necessary AWS objects.
This page describes the basic steps required to deploy Elastic Serverless Forwarder for AWS— for additional information on configuration topics such as permissions and automatic routing, and parsing and enriching data, see Configuration options.
Deploying directly without SAR
editIf the customization options available when deploying via Serverless Application Repository (SAR) are not sufficient, from version 1.6.0 and above you can deploy the Elastic Serverless Forwarder directly to your AWS Account without using SAR. This enables you to customize the event source settings for the inputs (i.e. triggers) one-by-one.
Install AWS integration assets in Kibana
edit- Go to Integrations in Kibana and search for AWS (or select the AWS category to filter the list).
- Click the AWS integration, select Settings and click Install AWS assets and confirm to install all the AWS integration assets.
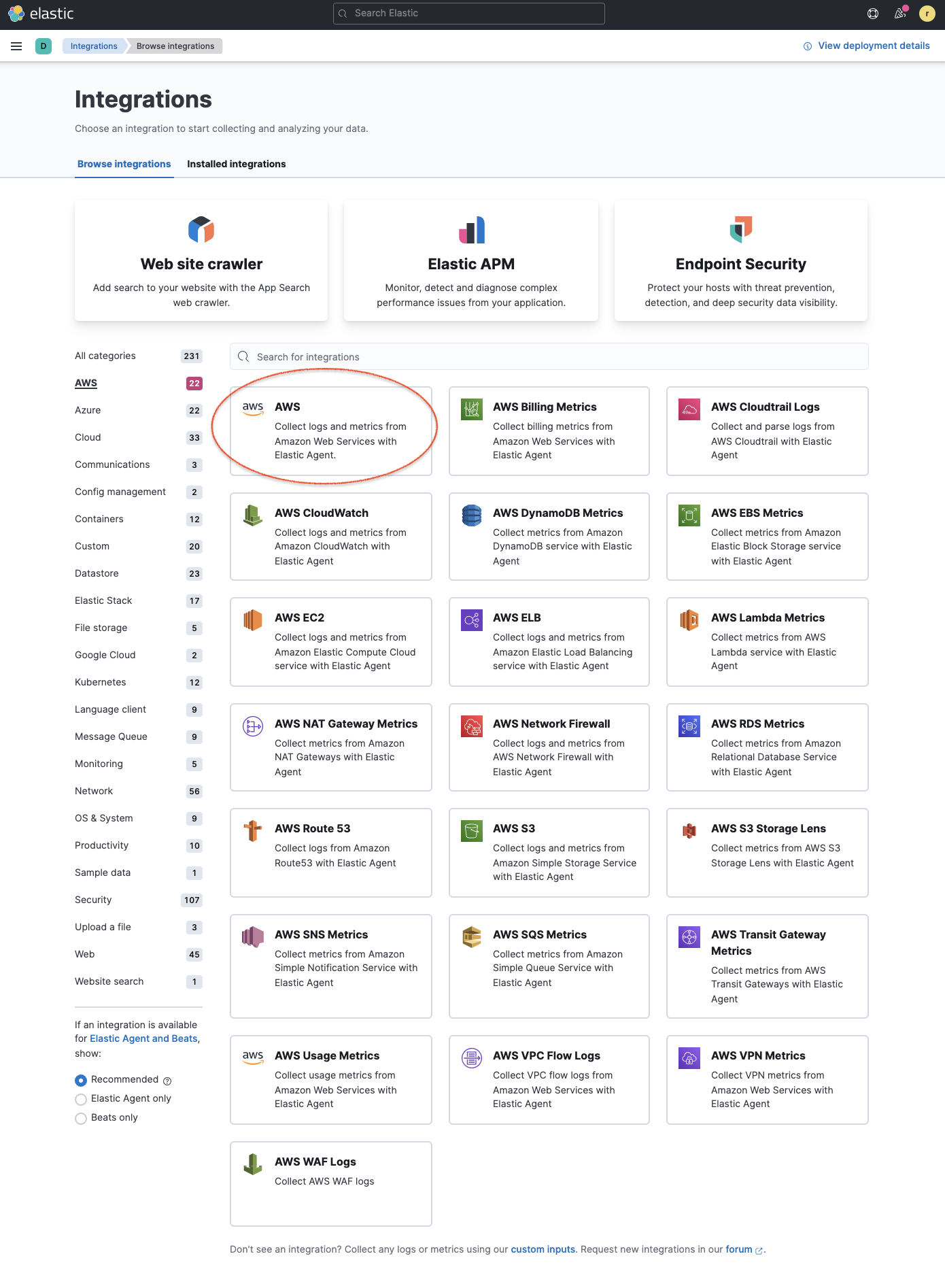
Adding integrations from Kibana provides appropriate pre-built dashboards, ingest node configurations, and other assets that help you get the most out of the data you ingest. The integrations use data streams with specific naming conventions that provide you with more granular controls and flexibility on managing data ingestion.
We recommend using integration assets to get started but the forwarder supports writing to any index, alias, or custom data stream. This enables existing Elasticsearch users to re-use index templates, ingest pipelines, or dashboards that are already created and connected to existing processes or systems. If you already have an existing index or data stream you intend to send data to, then you can skip this deployment step.
Create and upload config.yaml to S3 bucket
editElastic Serverless Forwarder requires a config.yaml file to be uploaded to an S3 bucket and referenced by the S3_CONFIG_FILE environment variable.
Save the following YAML content as config.yaml and edit as required before uploading to an S3 bucket. You should remove any inputs or arguments you are not using, and ensure you have entered the correct URLs and credentials as per the inline comments.
inputs:
- type: "s3-sqs"
id: "arn:aws:sqs:%REGION%:%ACCOUNT%:%QUEUENAME%"
outputs:
- type: "elasticsearch"
args:
# either elasticsearch_url or cloud_id, elasticsearch_url takes precedence if both are included
elasticsearch_url: "http(s)://domain.tld:port"
cloud_id: "cloud_id:bG9jYWxob3N0OjkyMDAkMA=="
# either api_key or username/password, username/password takes precedence if both are included
api_key: "YXBpX2tleV9pZDphcGlfa2V5X3NlY3JldAo="
username: "username"
password: "password"
es_datastream_name: "logs-generic-default"
es_dead_letter_index: "esf-dead-letter-index" # optional
batch_max_actions: 500 # optional: default value is 500
batch_max_bytes: 10485760 # optional: default value is 10485760
- type: "logstash"
args:
logstash_url: "http(s)://host:port"
username: "username" #optional
password: "password" #optional
max_batch_size: 500 #optional
compression_level: 1 #optional
ssl_assert_fingerprint: "22:F7:FB:84:1D:43:3E:E7:BB:F9:72:F3:D8:97:AD:7C:86:E3:08:42" #optional
- type: "sqs"
id: "arn:aws:sqs:%REGION%:%ACCOUNT%:%QUEUENAME%"
outputs:
- type: "elasticsearch"
args:
# either elasticsearch_url or cloud_id, elasticsearch_url takes precedence if both are included
elasticsearch_url: "http(s)://domain.tld:port"
cloud_id: "cloud_id:bG9jYWxob3N0OjkyMDAkMA=="
# either api_key or username/password, username/password takes precedence if both are included
api_key: "YXBpX2tleV9pZDphcGlfa2V5X3NlY3JldAo="
username: "username"
password: "password"
es_datastream_name: "logs-generic-default"
es_dead_letter_index: "esf-dead-letter-index" # optional
batch_max_actions: 500 # optional: default value is 500
batch_max_bytes: 10485760 # optional: default value is 10485760
- type: "logstash"
args:
logstash_url: "http(s)://host:port"
username: "username" #optional
password: "password" #optional
max_batch_size: 500 #optional
compression_level: 1 #optional
ssl_assert_fingerprint: "22:F7:FB:84:1D:43:3E:E7:BB:F9:72:F3:D8:97:AD:7C:86:E3:08:42" #optional
- type: "kinesis-data-stream"
id: "arn:aws:kinesis:%REGION%:%ACCOUNT%:stream/%STREAMNAME%"
outputs:
- type: "elasticsearch"
args:
# either elasticsearch_url or cloud_id, elasticsearch_url takes precedence if both are included
elasticsearch_url: "http(s)://domain.tld:port"
cloud_id: "cloud_id:bG9jYWxob3N0OjkyMDAkMA=="
# either api_key or username/password, username/password takes precedence if both are included
api_key: "YXBpX2tleV9pZDphcGlfa2V5X3NlY3JldAo="
username: "username"
password: "password"
es_datastream_name: "logs-generic-default"
es_dead_letter_index: "esf-dead-letter-index" # optional
batch_max_actions: 500 # optional: default value is 500
batch_max_bytes: 10485760 # optional: default value is 10485760
- type: "logstash"
args:
logstash_url: "http(s)://host:port"
username: "username" #optional
password: "password" #optional
max_batch_size: 500 #optional
compression_level: 1 #optional
ssl_assert_fingerprint: "22:F7:FB:84:1D:43:3E:E7:BB:F9:72:F3:D8:97:AD:7C:86:E3:08:42" #optional
- type: "cloudwatch-logs"
id: "arn:aws:logs:%AWS_REGION%:%AWS_ACCOUNT_ID%:log-group:%LOG_GROUP_NAME%:*"
outputs:
- type: "elasticsearch"
args:
# either elasticsearch_url or cloud_id, elasticsearch_url takes precedence if both are included
elasticsearch_url: "http(s)://domain.tld:port"
cloud_id: "cloud_id:bG9jYWxob3N0OjkyMDAkMA=="
# either api_key or username/password, username/password takes precedence if both are included
api_key: "YXBpX2tleV9pZDphcGlfa2V5X3NlY3JldAo="
username: "username"
password: "password"
es_datastream_name: "logs-generic-default"
es_dead_letter_index: "esf-dead-letter-index" # optional
batch_max_actions: 500 # optional: default value is 500
batch_max_bytes: 10485760 # optional: default value is 10485760
- type: "logstash"
args:
logstash_url: "http(s)://host:port"
username: "username" #optional
password: "password" #optional
max_batch_size: 500 #optional
compression_level: 1 #optional
ssl_assert_fingerprint: "22:F7:FB:84:1D:43:3E:E7:BB:F9:72:F3:D8:97:AD:7C:86:E3:08:42" #optional
- type: "cloudwatch-logs"
id: "arn:aws:logs:%AWS_REGION%:%AWS_ACCOUNT_ID%:log-group:%LOG_GROUP_NAME%:log-stream:%LOG_STREAM_NAME%"
outputs:
- type: "elasticsearch"
args:
# either elasticsearch_url or cloud_id, elasticsearch_url takes precedence if both are included
elasticsearch_url: "http(s)://domain.tld:port"
cloud_id: "cloud_id:bG9jYWxob3N0OjkyMDAkMA=="
# either api_key or username/password, username/password takes precedence if both are included
api_key: "YXBpX2tleV9pZDphcGlfa2V5X3NlY3JldAo="
username: "username"
password: "password"
es_datastream_name: "logs-generic-default"
es_dead_letter_index: "esf-dead-letter-index" # optional
batch_max_actions: 500 # optional: default value is 500
batch_max_bytes: 10485760 # optional: default value is 10485760
- type: "logstash"
args:
logstash_url: "http(s)://host:port"
username: "username" #optional
password: "password" #optional
max_batch_size: 500 #optional
compression_level: 1 #optional
ssl_assert_fingerprint: "22:F7:FB:84:1D:43:3E:E7:BB:F9:72:F3:D8:97:AD:7C:86:E3:08:42" #optional
All versions up to 1.14.0 (included) only allow one output per type. So if the output.type chosen by a user is elasticsearch, then the user can only configure one output for it.
Fields
editinputs.[]:
A list of inputs (i.e. triggers) for the Elastic Serverless Forwarder Lambda function.
inputs.[].type:
The type of trigger input (cloudwatch-logs, kinesis-data-stream, sqs and s3-sqs are currently supported).
inputs.[].id:
The ARN of the trigger input according to the type. Multiple input entries can have different unique ids with the same type.
Inputs of type cloudwatch-logs accept both CloudWatch Logs Log Group and CloudWatch Logs Log Stream ARNs.
inputs.[].outputs:
A list of outputs (i.e. forwarding targets) for the Elastic Serverless Forwarder Lambda function. You can have multiple outputs for an input, but only one output can be defined per type.
inputs.[].outputs.[].type:
The type of the forwarding target output. Currently only the following outputs are supported:
-
elasticsearch -
[preview]
This functionality is in technical preview and may be changed or removed in a future release. Elastic will work to fix any issues, but features in technical preview are not subject to the support SLA of official GA features.
logstash
Each type can only be used for a maximum of one output up to and including 1.14.0 version. If Logstash is chosen as an output, Elastic Serverless Forwarder expects the elastic_serverless_forwarder Logstash input to be installed, enabled, and properly configured. For more information about installing Logstash plugins, refer to the Logstash documentation.
inputs.[].outputs.[].args:
Custom init arguments for the specified forwarding target output.
For elasticsearch the following arguments are supported:
-
args.elasticsearch_url: URL of elasticsearch endpoint in the formathttp(s)://domain.tld:port. Mandatory whenargs.cloud_idis not provided. Will take precedence overargs.cloud_idif both are defined. -
args.cloud_id: Cloud ID of elasticsearch endpoint. Mandatory whenargs.elasticsearch_urlis not provided. Will be ignored ifargs.elasticsearch_urlis defined. -
args.username: Username of the elasticsearch instance to connect to. Mandatory whenargs.api_keyis not provided. Will take precedence overargs.api_keyif both are defined. -
args.passwordPassword of the elasticsearch instance to connect to. Mandatory whenargs.api_keyis not provided. Will take precedence overargs.api_keyif both are defined. -
args.api_key: API key of elasticsearch endpoint in the formatbase64encode(api_key_id:api_key_secret). Mandatory whenargs.usernameandargs.passwordare not provided. Will be ignored ifargs.username/args.passwordare defined. -
args.es_datastream_name: Name of data stream or index where logs should be forwarded to. Lambda supports automatic routing of various AWS service logs to the corresponding data streams for further processing and storage in the Elasticsearch cluster. It supports automatic routing ofaws.cloudtrail,aws.cloudwatch_logs,aws.elb_logs,aws.firewall_logs,aws.vpcflow, andaws.waflogs. For other log types, if using data streams, you can optionally set its value in the configuration file according to the naming convention for data streams and available integrations. If thees_datastream_nameis not specified and it cannot be matched with any of the above AWS services, then the value will be set tologs-generic-default. In versions v0.29.1 and below, this configuration parameter was namedes_index_or_datastream_name. Rename the configuration parameter toes_datastream_namein yourconfig.yamlfile on the S3 bucket to continue using it in the future version. The older namees_index_or_datastream_nameis deprecated as of version v0.30.0. The related backward compatibility code is removed from version v1.0.0. -
args.es_dead_letter_index: Name of data stream or index where logs should be redirected to, in case indexing toargs.es_datastream_namereturned an error. The elasticseach output will NOT forward retryable errors (connection failures, HTTP status code 429) to the dead letter index. -
args.batch_max_actions: (Optional) Maximum number of actions to send in a single bulk request. Default value: 500. -
args.batch_max_bytes: (Optional) Maximum size in bytes to send in a single bulk request. Default value: 10485760 (10MB). -
args.ssl_assert_fingerprint: (Optional) SSL fingerprint for self-signed SSL certificate on HTTPS transport. The default value is an empty string, meaning the HTTP client requires a valid certificate.-
Here is a sample error indexed in the dead letter index:
{ "@timestamp": "2024-10-07T05:57:59.448925Z", "message": "{\"hey\":{\"message\":\"hey there\"},\"_id\":\"e6542822-4583-438d-9b4d-1a3023b5eeb9\",\"_op_type\":\"create\",\"_index\":\"logs-succeed.pr793-default\"}", "error": { "message": "[1:30] failed to parse field [hey] of type [keyword] in document with id 'e6542822-4583-438d-9b4d-1a3023b5eeb9'. Preview of field's value: '{message=hey there}'", "type": "document_parsing_exception" }, "http": { "response": { "status_code": 400 } } }
-
For logstash the following arguments are supported:
-
args.logstash_url: URL of Logstash endpoint in the formathttp(s)://host:port -
args.username: (Optional) Username of the Logstash instance to connect to. Mandatory if HTTP Basic authentication is enabled in Logstash. -
args.password: (Optional) Password of the Logstash instance to connect to. Mandatory if HTTP Basic authentication is enabled in Logstash. -
args.max_batch_size: (Optional) Maximum number of events to send in a single HTTP(s) request. Default value: 500 -
args.compression_level: (Optional) The GZIP compression level for HTTP(s) requests towards Logstash. It can be any integer value between 1 (minimum compression, best performance, highest amount of bytes sent) and 9 (maximum compression, worst performance, lowest amount of bytes sent). Default value: 1 -
args.ssl_assert_fingerprint: (Optional) SSL fingerprint for self-signed SSL certificate on HTTPS transport. The default value is an empty string, meaning the HTTP client requires a valid certificate.
Define deployment parameters
editWhichever SAR deployment method you choose, you must define the following parameters correctly for your setup. This section explains the types of parameters and provides guidance on how to set them to match your deployment(s).
General configuration
editThese parameters define the general configuration and behaviour for the forwarder.
-
ElasticServerlessForwarderS3ConfigFile: Set this value to the location of yourconfig.yamlin S3 URL format:s3://bucket-name/config-file-name. This will populate theS3_CONFIG_FILEenvironment variable for the forwarder. -
ElasticServerlessForwarderSSMSecrets: Add a comma delimited list of AWS SSM Secrets ARNs used in theconfig.yml(if any). -
ElasticServerlessForwarderKMSKeys: Add a comma delimited list of AWS KMS Keys ARNs to be used for decrypting AWS SSM Secrets, Kinesis Data Streams, SQS queue, or S3 buckets (if any).
Make sure you include all the KMS keys used to encrypt the data. For example, S3 buckets are often encrypted, so the Lambda function needs access to that key to get the object.
Inputs
editThese parameters define your specific Inputs or event triggers.
-
ElasticServerlessForwarderSQSEvents: Add a comma delimited list of Direct SQS queue ARNs to set as event triggers for the forwarder (if any). -
ElasticServerlessForwarderSQSEvents2: Add a comma delimited list of Direct SQS queue ARNs to set as event triggers for the forwarder (if limit is reach on ElasticServerlessForwarderSQSEvents). -
ElasticServerlessForwarderS3SQSEvents: Add a comma delimited list of S3 SQS Event Notifications ARNs to set as event triggers for the forwarder (if any). -
ElasticServerlessForwarderS3SQSEvents2: Add a comma delimited list of S3 SQS Event Notifications ARNs to set as event triggers for the forwarder (if limit is reach on ElasticServerlessForwarderS3SQSEvents). -
ElasticServerlessForwarderKinesisEvents: Add a comma delimited list of Kinesis Data Stream ARNs to set as event triggers for the forwarder (if any). -
ElasticServerlessForwarderKinesisEvents2: Add a comma delimited list of Kinesis Data Stream ARNs to set as event triggers for the forwarder (if limit is reach on ElasticServerlessForwarderKinesisEvents). -
ElasticServerlessForwarderCloudWatchLogsEvents: Add a comma delimited list of Cloudwatch Logs log group ARNs to set subscription filters on the forwarder (if any). -
ElasticServerlessForwarderCloudWatchLogsEvents2: Add a comma delimited list of Cloudwatch Logs log group ARNs to set subscription filters on the forwarder (if limit is reach on ElasticServerlessForwarderCloudWatchLogsEvents).
Make sure you reference the ARNs specified in your config.yaml, and leave any settings for unused inputs blank.
S3 Bucket permissions
editThese parameters define the permissions required in order to access the associated S3 Buckets.
-
ElasticServerlessForwarderS3Buckets: Add a comma delimited list of S3 bucket ARNs that are sources for the S3 SQS Event Notifications (if any).
Network
editTo attach the Elastic Serverless Forwarder to a specific AWS VPC, specify the security group IDs and subnet IDs that belong to the AWS VPC. This requirement is related to the CloudFormation VPCConfig property.
These are the parameters:
-
ElasticServerlessForwarderSecurityGroups: Add a comma delimited list of security group IDs to attach to the forwarder. -
ElasticServerlessForwarderSubnets: Add a comma delimited list of subnet IDs for the forwarder.
Both parameters are required in order to attach the Elastic Serverless Forwarder to a specific AWS VPC. Leave both parameters blank if you don’t want the forwarder to belong to any specific AWS VPC.
If the Elastic Serverless Forwarder is attached to a VPC, you need to create VPC endpoints for S3 and SQS, and for every service you define as an input for the forwarder. S3 and SQS VPC endpoints are always required for reading the config.yaml uploaded to S3 and managing the continuing queue and the replay queue, regardless of the Inputs used. If you use Amazon CloudWatch Logs subscription filters, you need to create a VPC endpoint for EC2, too.
Refer to the AWS PrivateLink traffic filters documentation to find your VPC endpoint ID and the hostname to use in the config.yml in order to access your Elasticsearch cluster over PrivateLink.
Deploy Elastic Serverless Forwarder from Terraform
editThe terraform files to deploy ESF can be found in esf-terraform repository. There are two requirements to deploy these files: curl and terraform. Refer to the README file to learn how to use it.
Deploy Elastic Serverless Forwarder from SAR
editThere are several deployment methods available via the AWS Serverless Application Repository (SAR):
To deploy the forwarder directly without using SAR, refer to Deploy Elastic Serverless Forwarder directly
Deploy using AWS Console
editOnly one deployment per region is allowed when using the AWS console directly.
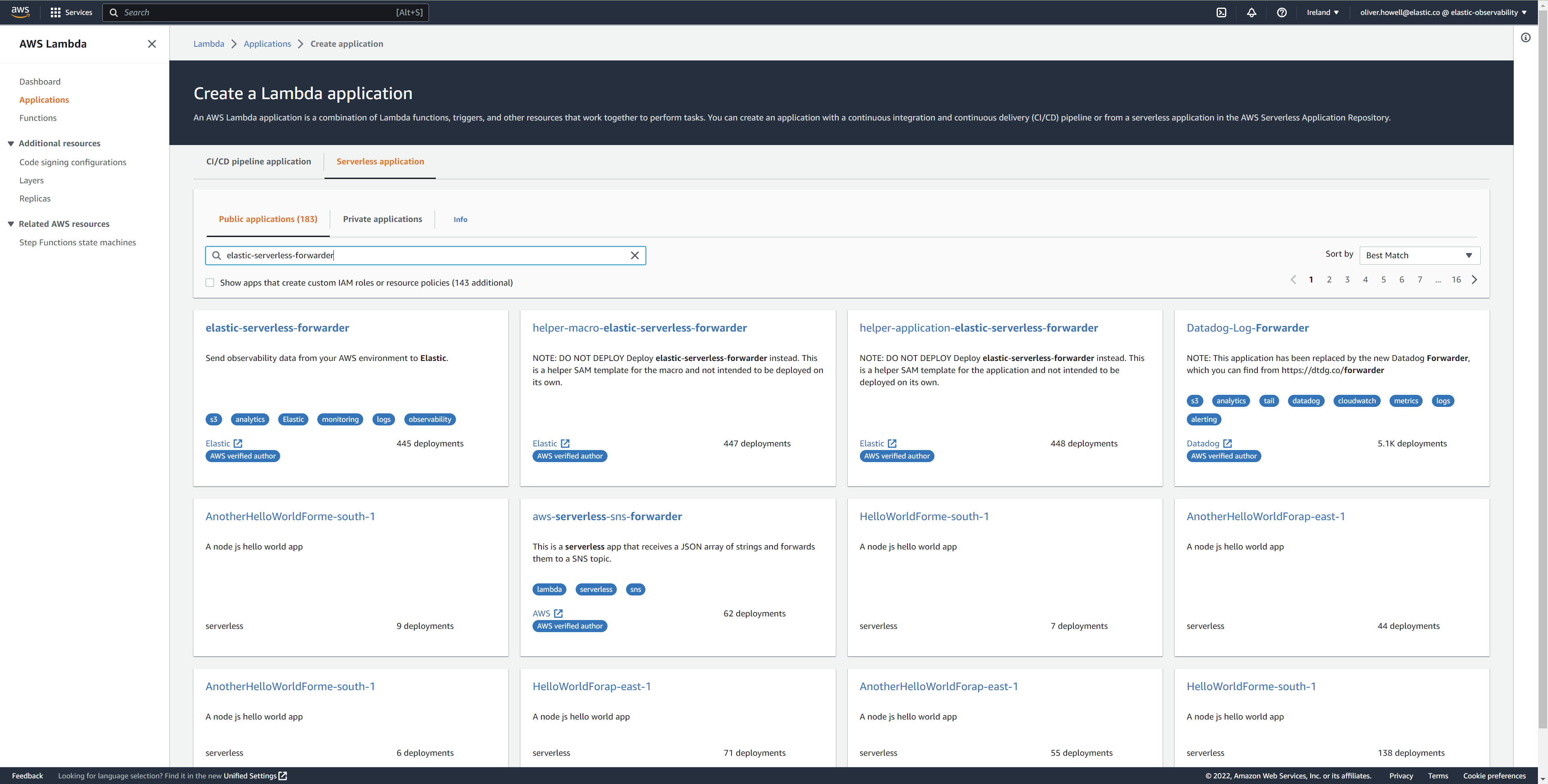
- Log in to AWS console and open Lambda.
- Click Applications and then Create application.
- Click Serverless application and search for elastic-serverless-forwarder.
-
Select elastic-serverless-forwarder from the search results (ignoring any application beginning helper-).
-
Complete the Application settings according to Define deployment parameters.
You must specify the parameters even if they already exist in the
config.yamlfile. Depends on the input type, at least one if the parametersElasticServerlessForwarderSQSEvents,ElasticServerlessForwarderS3SQSEvents,ElasticServerlessForwarderKinesisEvents,ElasticServerlessForwarderCloudWatchLogsEventsshould de defined. - After your settings have been added, click Deploy.
- On the Applications page for serverlessrepo-elastic-serverless-forwarder, click Deployments.
-
Refresh the Deployment history until you see the
Create completestatus update. It should take around 5 minutes to deploy — if the deployment fails for any reason, the create events will be rolled back and you will be able to see an explanation for which event failed. -
(Optional) To enable Elastic APM instrumentation for your new deployment:
- Go to Lambda > Functions within AWS console, and find and select the function with serverlessrepo-.
- Go to Configuration tab and select Environment Variables
-
Add the following environment variables:
| Key | Value | |---------------------------|--------| |`ELASTIC_APM_ACTIVE` | `true` | |`ELASTIC_APM_SECRET_TOKEN` | token | |`ELASTIC_APM_SERVER_URL` | url |
If you have already successfully deployed the forwarder but want to update the application (for example, if a new version of the Lambda function is released), you should go through this deploy step again and use the same Application name. This will ensure the function is updated rather than duplicated or created anew.
Deploy using Cloudformation
edit-
Use the following code to get the semantic version of the latest application:
aws serverlessrepo list-application-versions --application-id arn:aws:serverlessrepo:eu-central-1:267093732750:applications/elastic-serverless-forwarder
-
Save the following YAML content as
sar-application.yamland fill in the correct parameters according to Define deployment parameters:Transform: AWS::Serverless-2016-10-31 Resources: SarCloudformationDeployment: Type: AWS::Serverless::Application Properties: Location: ApplicationId: 'arn:aws:serverlessrepo:eu-central-1:267093732750:applications/elastic-serverless-forwarder' SemanticVersion: '%SEMANTICVERSION%' ## SET TO CORRECT SEMANTIC VERSION (MUST BE GREATER THAN 1.6.0) Parameters: ElasticServerlessForwarderS3ConfigFile: "" ElasticServerlessForwarderSSMSecrets: "" ElasticServerlessForwarderKMSKeys: "" ElasticServerlessForwarderSQSEvents: "" ElasticServerlessForwarderSQSEvents2: "" ## IF SEMANTIC VERSION GREATER THAN 1.12.0 ElasticServerlessForwarderS3SQSEvents: "" ElasticServerlessForwarderS3SQSEvents2: "" ## IF SEMANTIC VERSION GREATER THAN 1.12.0 ElasticServerlessForwarderKinesisEvents: "" ElasticServerlessForwarderKinesisEvents2: "" ## IF SEMANTIC VERSION GREATER THAN 1.12.0 ElasticServerlessForwarderCloudWatchLogsEvents: "" ElasticServerlessForwarderCloudWatchLogsEvents2: "" ## IF SEMANTIC VERSION GREATER THAN 1.12.0 ElasticServerlessForwarderS3Buckets: "" ElasticServerlessForwarderSecurityGroups: "" ElasticServerlessForwarderSubnets: "" -
Deploy the Lambda function from SAR by running the following command:
aws cloudformation deploy --template-file sar-application.yaml --stack-name esf-cloudformation-deployment --capabilities CAPABILITY_IAM CAPABILITY_AUTO_EXPAND
Starting from v1.4.0, if you want to update the Events settings for the forwarder, you do not need to manually delete existing settings before applying new settings.
Deploy from SAR using Terraform
edit-
Save the following yaml content as
sar-application.tfand fill in the correct parameters according to Define deployment parameters:provider "aws" { region = "" ## FILL WITH THE AWS REGION WHERE YOU WANT TO DEPLOY THE ELASTIC SERVERLESS FORWARDER } data "aws_serverlessapplicationrepository_application" "esf_sar" { application_id = "arn:aws:serverlessrepo:eu-central-1:267093732750:applications/elastic-serverless-forwarder" } resource "aws_serverlessapplicationrepository_cloudformation_stack" "esf_cf_stak" { name = "terraform-elastic-serverless-forwarder" application_id = data.aws_serverlessapplicationrepository_application.esf_sar.application_id semantic_version = data.aws_serverlessapplicationrepository_application.esf_sar.semantic_version capabilities = data.aws_serverlessapplicationrepository_application.esf_sar.required_capabilities parameters = { ElasticServerlessForwarderS3ConfigFile = "" ElasticServerlessForwarderSSMSecrets = "" ElasticServerlessForwarderKMSKeys = "" ElasticServerlessForwarderSQSEvents = "" ElasticServerlessForwarderS3SQSEvents = "" ElasticServerlessForwarderKinesisEvents = "" ElasticServerlessForwarderCloudWatchLogsEvents = "" ElasticServerlessForwarderS3Buckets = "" ElasticServerlessForwarderSecurityGroups = "" ElasticServerlessForwarderSubnets = "" } } -
Deploy the function from SAR by running the following commands:
terraform init terraform apply
From v1.4.0 and above, if you want to update the Events settings for the deployment, it is no longer required to manually delete existing settings before applying the new settings.
Due to a Terraform bug related to aws_serverlessapplicationrepository_application, if you want to delete existing Event parameters you have to set the related aws_serverlessapplicationrepository_cloudformation_stack.parameters to a blank space value (" ") instead of an empty string ("").
Deploy Elastic Serverless Forwarder directly
editFor more customisation options during deployment, from version 1.6.0 and above you can deploy the Elastic Serverless Forwarder directly to your AWS Account without using SAR. This enables you to customize the event source settings for the inputs (i.e. triggers) one-by-one.
To deploy the forwarder directly, you have to:
Create publish-config.yaml for the publishing script
editTo deploy the forwarder directly, you need to define a publish-config.yaml file and pass this as an argument in the publishing script.
Save the following YAML content as publish-config.yaml and edit as required before running the publishing script. You should remove any inputs or arguments you are not using.
kinesis-data-stream:
- arn: "arn:aws:kinesis:%REGION%:%ACCOUNT%:stream/%STREAMNAME%"
batch_size: 10
batching_window_in_second: 0
starting_position: TRIM_HORIZON
starting_position_timestamp: 0
parallelization_factor: 1
sqs:
- arn: "arn:aws:sqs:%REGION%:%ACCOUNT%:%QUEUENAME%"
batch_size: 10
batching_window_in_second: 0
s3-sqs:
- arn: "arn:aws:sqs:%REGION%:%ACCOUNT%:%QUEUENAME%"
batch_size: 10
batching_window_in_second: 0
cloudwatch-logs:
- arn: "arn:aws:logs:%AWS_REGION%:%AWS_ACCOUNT_ID%:log-group:%LOG_GROUP_NAME%:*"
- arn: "arn:aws:logs:%AWS_REGION%:%AWS_ACCOUNT_ID%:log-group:%LOG_GROUP_NAME%:log-stream:%LOG_STREAM_NAME%"
ssm-secrets:
- "arn:aws:secretsmanager:%AWS_REGION%:%AWS_ACCOUNT_ID%:secret:%SECRET_NAME%"
kms-keys:
- "arn:aws:kms:%AWS_REGION%:%AWS_ACCOUNT_ID%:key/%KMS_KEY_UUID%"
s3-buckets:
- "arn:aws:s3:::%BUCKET_NAME%"
subnets:
- "%SUBNET_ID%"
security-groups:
- "%SECURITY_ID%"
s3-config-file: "s3://%S3_CONFIG_BUCKET_NAME%/%S3_CONFIG_OBJECT_KEY%"
continuing-queue:
batch_size: 10
batching_window_in_second: 0
Fields
edit
|
List of Amazon Kinesis Data Streams (i.e. triggers) for the forwarder, matching those defined in your Create and upload |
|
ARN of the AWS Kinesis Data Stream. |
|
Set this value above the default ( |
|
Set this value above the default ( |
|
Change this value from the default ( |
|
Set this value to the time from which to start reading (in Unix time seconds) if you set |
|
Defines the number of forwarder functions that can run concurrently per shard (default is |
|
List of Amazon SQS message payload (i.e. triggers) for the forwarder, matching those defined in your Create and upload |
|
ARN of the AWS SQS queue trigger input. |
|
Set this value above the default ( |
|
Set this value above the default ( |
|
List of Amazon S3 (via SQS event notifications) (i.e. triggers) for the forwarder, matching those defined in your Create and upload |
|
ARN of the AWS SQS queue receiving S3 Notifications as trigger input. |
|
Set this value above the default ( |
|
Set this value above the default ( |
|
List of Amazon CloudWatch Logs subscription filters (i.e. triggers) for the forwarder, matching those defined in your Create and upload |
|
ARN of the AWS CloudWatch Logs trigger input (accepts both CloudWatch Logs Log Group and CloudWatch Logs Log Stream ARNs). |
|
List of AWS SSM Secrets ARNs used in your |
|
List of AWS KMS Keys ARNs to be used for decrypting AWS SSM Secrets, Kinesis Data Streams or SQS queues (if any). |
|
List of S3 bucket ARNs that are sources for the S3 SQS Event Notifications (if any). |
|
A list of subnets IDs for the forwarder. Along with |
|
List of security group IDs to attach to the forwarder. Along with |
|
Set this value to the location of your forwarder configuration file in S3 URL format: |
|
Set this value above the default ( |
|
Set this value above the default ( |
Run the publishing script
editA bash script for publishing the Elastic Serverless Forwarder directly to your AWS account is available from the Elastic Serverless Forwarder repository.
Download the publish_lambda.sh script and follow the instructions below.
Script arguments
edit $ ./publish_lambda.sh
AWS CLI (https://aws.amazon.com/cli/), SAM (https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/install-sam-cli.html) and Python3.9 with pip3 required
Please, before launching the tool execute "$ pip3 install ruamel.yaml"
Usage: ./publish_lambda.sh config-path lambda-name forwarder-tag bucket-name region [custom-role-prefix]
Arguments:
config-path: full path to the publish configuration
lambda-name: name of the lambda to be published in the account
forwarder-tag: tag of the elastic serverless forwarder to publish
bucket-name: bucket name where to store the zip artifact for the lambda
(it will be created if it doesn't exists, otherwise
you need already to have proper access to it)
region: region where to publish in
custom-role-prefix: role/policy prefix to add in case customization is needed (optional)
(please note that the prefix will be added to both role/policy naming)
Prerequisites
edit- Python3.9 with pip3 is required to run the script
- AWS CLI, SAM CLI and the ruamel.yaml package must also be installed
$ pip3 install awscli aws-sam-cli ruamel.yaml
Running the script
editAssuming publish-config.yaml in saved in the same directory you intend to run publish_lambda.sh from, here’s an example:
$ ./publish_lambda.sh publish-config.yaml forwarder-lambda lambda-v1.6.0 s3-lambda-artifact-bucket-name eu-central-1
Updating to a new version via script
editYou can update the version of a published Elastic Serverless Forwarder without changing its configuration by running the publishing script again and passing a new forwarder-tag:
$ ./publish_lambda.sh publish-config.yaml forwarder-lambda lambda-v1.7.0 s3-lambda-artifact-bucket-name eu-central-1
The above examples show the forwarder being updated from lambda-v1.6.0 to lambda-v1.7.0.
Changing configuration via script
editIf you want to change the configuration of a published Elastic Serverless Forwarder without changing its version, you can update the publish-config.yaml and run the script again using the same forwarder-tag:
$ ./publish_lambda.sh publish-config.yaml forwarder-lambda lambda-v1.6.0 s3-lambda-artifact-bucket-name eu-central-1
The above example shows an existing lambda-v1.6.0 configuration being updated without changing version.
Using the script for multiple deployments
editIf you want to use the publish script for deploying the forwarder with different configurations, create two different publish-config.yaml files with unique names and run the publishing script twice, with correct references to the config-path and lambda-name:
$ ./publish_lambda.sh publish-config-for-first-lambda.yaml first-lambda lambda-v1.6.0 s3-lambda-artifact-bucket-name eu-central-1 $ ./publish_lambda.sh publish-config-for-second-lambda.yaml second-lambda lambda-v1.6.0 ss3-lambda-artifact-bucket-name eu-central-1
The above example publishes two versions of the forwarder, each with different configurations i.e. publish-config-for-first-lambda.yaml and first-lambda vs. publish-config-for-second-lambda.yaml and second-lambda.