Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
Elasticsearch’s new semantic_text mapping type was designed to simplify common challenges of building a RAG application. It brings together the steps of chunking text, generating embeddings, and then retrieving them.
In this article, we are going to create an end-to-end RAG application without leaving Elastic, using Amazon Bedrock as our inference service.
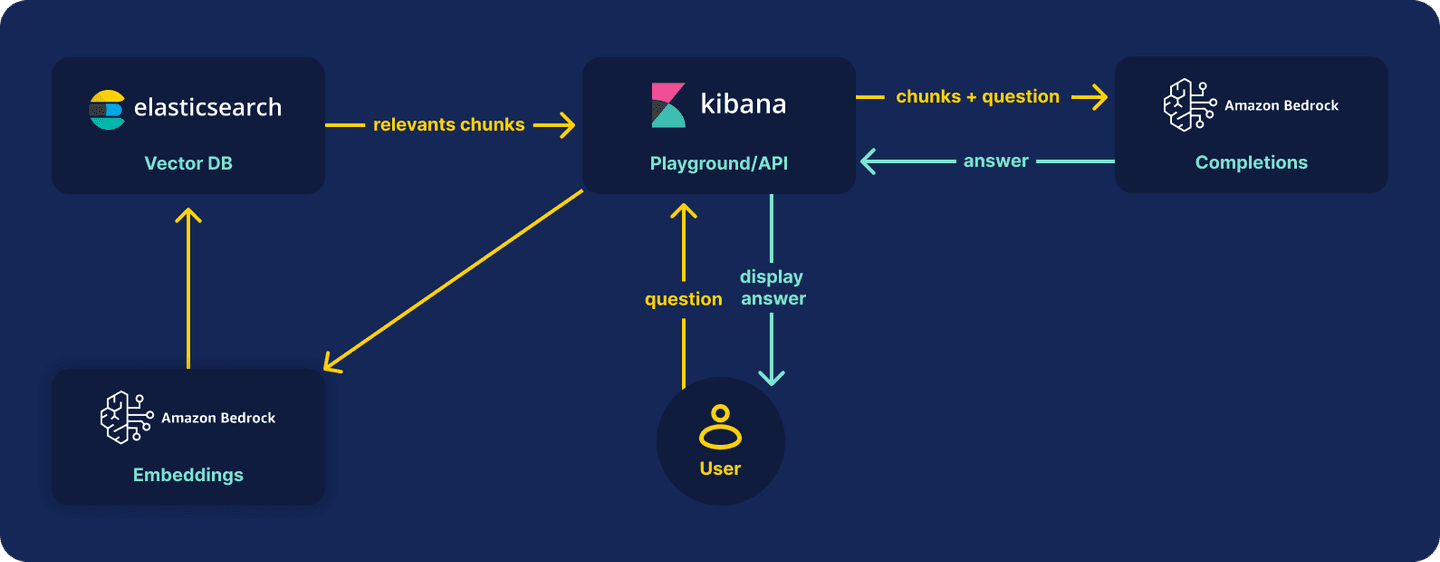
Steps
Creating endpoints
Before creating our index, we must create the endpoints we are going to use for our inference process. The endpoints will be named:
- Embeddings task
- Completion task
We will use Bedrock as our provider for both of them. With these two endpoints we can create a full RAG application only using Elastic tools!
If you want to read more about how to configure Bedrock, I recommend you read this article first.
Embeddings task
This task will help us create vector embeddings for our documents content and for the questions the user will ask.
With these vectors we can find the chunks that are more relevant to the question and retrieve the documents that contain the answer.
Go ahead and run in Kibana DevTools Console to create the endpoint:
providermust be one ofamazontitan, coheremodelmust be one model_id you have access to in Bedrock
Optional additional settings
dimensions: The output dimensions to use for the inferencemax_input_tokens:The maximum number of input tokenssimilarity: The similarity measure to use
Completion task
After we find the best chunks, we must send them to the LLM model so it can generate an answer for us.
Run the following to add the completion endpoint:
providermust be one ofamazontitan, anthropic, ai21labs, cohere, meta, mistralmodelmust be one model_id or ARN you have access to in Bedrock
Creating mappings
The new semantic_text mapping type will make things super easy. It will take care of inferring the embedding mappings and configurations, and doing the passage chunking for you! If you want to read more you can go to this great article.
YES. That's it. super_body is ready to be searched with vectors, and to handle chunking.
Indexing data
For data indexing we have many methods available, you can pick the one of your preference.
For simplicity, and recursivity, I will just copy this whole article as rich text and store it as a document.

We have it. Time to test.
Asking questions
The question and answer is a two steps process. First we must retrieve the text chunks relevant to the question, and then we must send the chunks to the LLM to generate the answer.
We will explore two strategies to do that, as promised, without any additional code or framework.
Strategy 1: API Calls
We can run two API calls: one to the _search endpoint to retrieve the chunk, and another one to the inference endpoint to do the LLM completion step.
Retrieving chunks
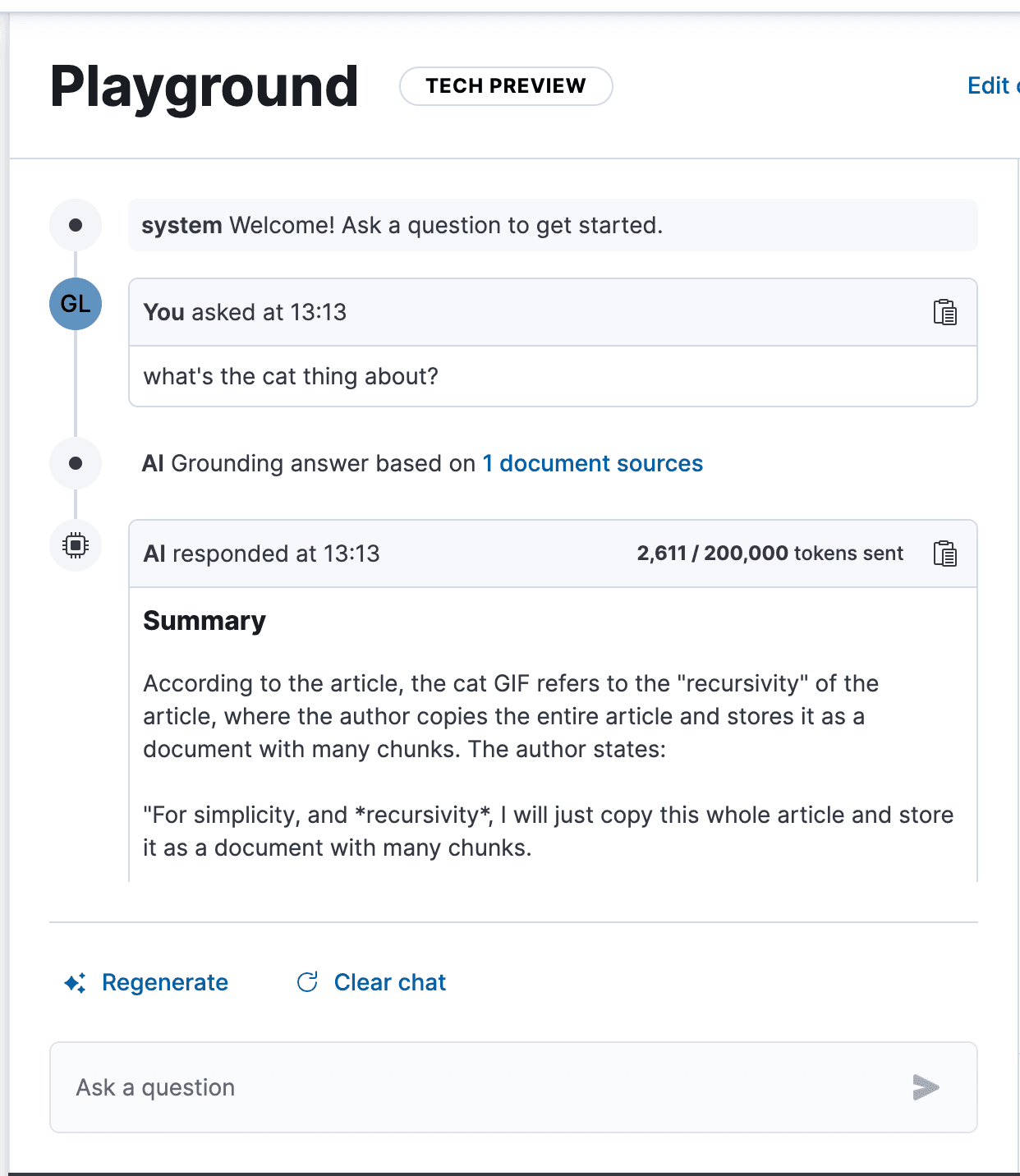
We are going to try a sort of "needle in a haystack" query, to make sure the answer from the LLM is obtained from this article, and not from the LLM base knowledge. We are going to ask about the cat gif referring to the recursivity of this article.
We could run the nice and short default query for semantic-text:
The problem is this query will not sort the inner hits (chunks) by relevance, which is what we need if we don't want to send the entire document to the LLM as context. It will sort the document´s relevance per document, and not per chunk.
This longer query will sort inner hits (chunks) by relevance, so we can grab the juicy ones.
we set root level _source to false, because we are interested on the relevant chunks only
As you can see, we are using retrievers for this query, and the response looks like this:
Now from the response we can copy the top chunk and combine the text in one big string. What some frameworks do, is to add metadata to each of the chunks.
Answering the question
Now we can use the bedrock completion endpoint we created previously to send this question along with the relevant chunks and get the answer.
Let's take a look at the answer!
Strategy 2: Playground
Now you learned how things work internally, let me show you how you can do this nice and easy, and with a nice UI on top. Using Elastic Playground.
Go to Playground, configure the Bedrock connector, and then select the index we just created and you are ready to go.
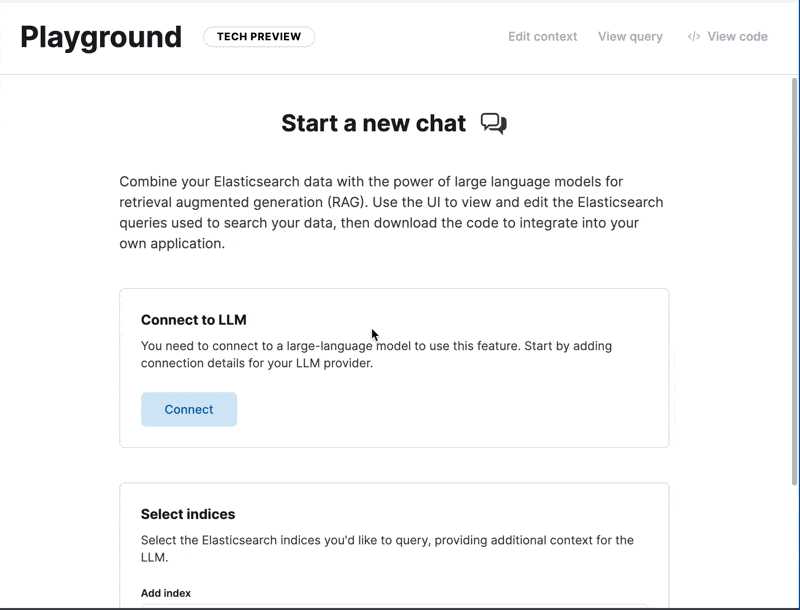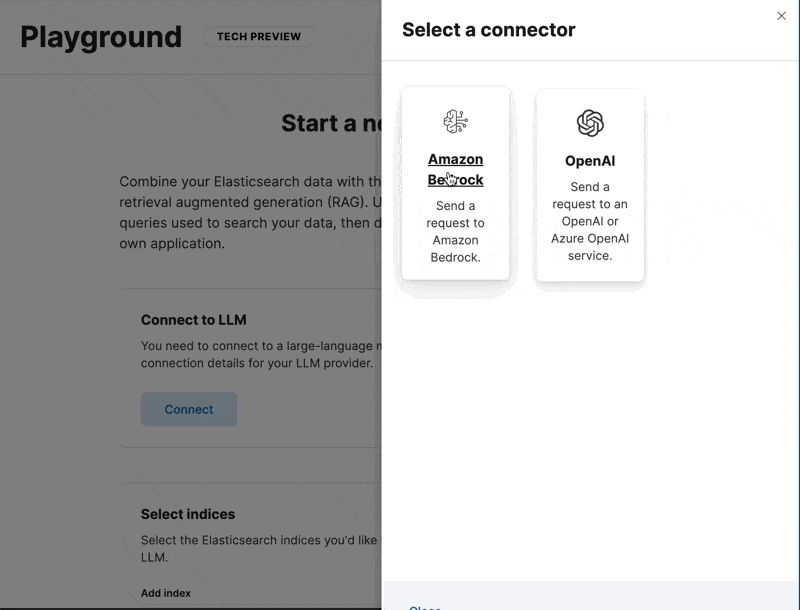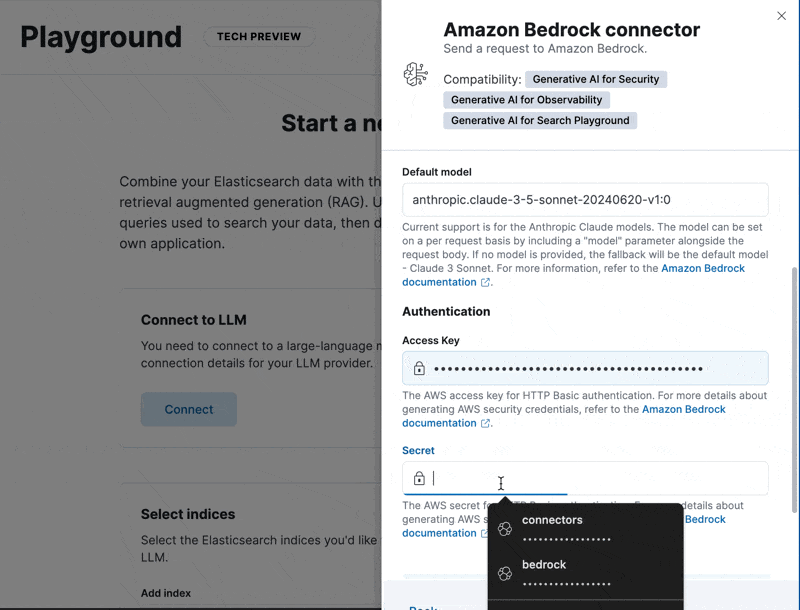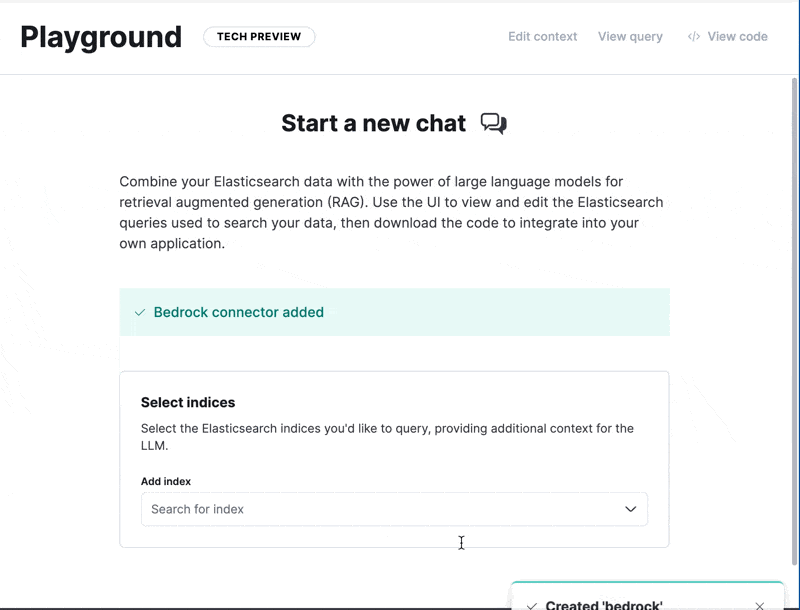
From here you can start asking questions to your brand new index.
If you want to learn another approach to chunk documents, we recommend reading about ingest pipelines, which use nested vector fields.
Conclusion
The new semantic_text mapping type makes creating a RAG setup extremely easy, without having to leave the Elastic ecosystem. Things like chunking and mapping settings are not a challenge anymore (at least not initially!), and there are various alternatives to ask questions to the data.
AWS Bedrock is fully integrated by providing both embeddings and completion endpoints, and also being included as a Playground connector!.
If you are interested on reproducing the examples of this article, you can find the Postman collection with the requests here
Related Content

January 28, 2026
Apache Lucene 2025 wrap-up
2025 was a stellar year for Apache Lucene; here are our highlights.

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.
January 20, 2026
Context engineering vs. prompt engineering
Learn how context engineering and prompt engineering differ and why mastering both is essential for building production AI agents and RAG systems.
January 2, 2026
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.
December 31, 2025
How to build an agent knowledge base with LangChain and Elasticsearch
Learn how to build an agent knowledge base and test its ability to query sources of information based on context, use WebSearch for out-of-scope queries, and refine recommendations based on user intention.