New to Elasticsearch? Join our getting started with Elasticsearch webinar. You can also start a free cloud trial or try Elastic on your machine now.
What are we going to do here?
Elastic Open Crawler is the successor to Elastic’s hosted crawler.
Semantic Text is Elastic’s easy on-ramp data type for getting up and running with semantic search.
Together, they are The New(ish) Kids on the Block.
Follow along to learn how to easily configure and run the Open Crawler to crawl a website (Search Labs’ blogs in this case), automatically chunk and generate sparse vector embeddings with ELSER for that web content (blog text), and run a few sample searches to ensure everything worked out.
Choose your own adventure
- If you want to run through this in a free, on-demand workshop environment - click here.
- If you’d rather watch a video of this walkthrough - follow this link.
- If you're ready to get straight to the practical part, check out it's Getting started doc or read more in the beta announcement blog
- Or read a great article on our Discuss forums - Dec 12th, 2024: [EN] Swing through web content like a superhero
- If you like reading blogs, continue!

Elasticsearch
Project or Cluster
The first thing you’ll need is an Elasticsearch cluster or serverless project. If you don’t have one, no problem; you can sign up for a free trial at cloud.elastic.co
Create a mapping template
If you don’t want to customize any mappings, the Open Crawler will index all the data it crawls on the web into Elasticsearch using sane defaults. However, in our case, we want to enhance the default mapping so some of our text can have sparse vectors generated for it.
We will create a new index template for two key fields in our index. The rest are set by default.
- Create a `semantic_text` field named `body_semantic`
- This will:
- Generate chunks from the body of the blog
- Generate sparse vectors with ELSER from chunks
- Note: The semantic text field requires an Inference API, which tells Elasticsearch how to generate embeddings on ingest and search. Since we are using serverless in this example, we will use the default ELSER Inference Endpoint in Elasticsearch.
- If you aren’t using serverless or want to set up your own Inference Endpoint, the docs page for ELSER has an example for creating a new inference endpoint.
- This will:
- Add a mapping for the `body` field to include the `copy_to` param to copy the body text to our semantic text field.
- The body field would normally be auto-mapped to text.
PUT the index template
Create the empty index
Create an ingest pipeline
The crawler can extract some information as it crawls web pages. However, you can configure an ingest pipeline when you need additional parsing.
We will configure a pipeline to extract the following information:
- The publish date from the author field and store it in a new published_date field
- The first author from list_of_authors into a new first_author field
- Remove raw_author and raw_publish_date
PUT the ingest pipeline
Deploy ELSER
If you are using Elastic’s serverless project, you can use the default ELSER inference endpoint (_inference/.elser-2-elasticsearch). If you do, you’ll need to update the mapping for body_semantic in the index template.
We will create a new inference endpoint to give it more resources and so non-serverless readers can have fun too!
PUT the new inference endpoint
Docker
Just a quick note here. You must have docker installed and running on your computer or server where you want to run the crawler.
Check out Docker’s getting started guide for help getting up and running.
The Open Crawler
Download Docker Image
You can download and start the Open Crawler docker image using Elastic’s official image.
Configure the crawler
We are going to crawl the Elastic Search Labs blogs. Search Labs has a lot of excellent search, ML, and GenAI content. But it also links to other parts of elastic.co. We'll configure the crawler to restrict our crawl, ensuring only the blogs are indexed.
Crawler.yaml
- Create a new
crawler.yamlfile and paste the code below - An allow rule for everything under (and including) the /search-labs/blog URL pattern
- A deny everything rule to catch all other URLs
- Use an extraction rule to extract the author’s name and assign it to the field `authors`.
- For more detail on the extraction rules example, check out the blog about the beta release.
- In this example, we use a regex pattern for the deny rule.
Paste the code below into crawler.yml:
Copy the config file to the running docker container
Run the copy command below:
Start a crawl job
We are now ready to crawl some web pages! Run the command below to start it.
Note: You may initially see timeouts in the crawler logs. By default, the ELSER deployment is scaled to 0 allocations to reduce costs when idle. It will take a minute for the deployment to scale out.
To the docs!
Go back to the console in Kibana and enter the following search:
The first five titles I get back are:
- Better Binary Quantization vs. Product Quantization - Search Labs
- Scalar quantization 101 - Search Labs
- RaBitQ binary quantization 101 - Search Labs
- Better Binary Quantization (BBQ) in Lucene and Elasticsearch - Search Labs
- Understanding Int4 scalar quantization in Lucene - Search Labs
All find blogs that can help answer my question.
Discover
You can also hop over to Discover to view a table of docs.
To set it up:
- Click on the Data View selector
- Click “Create a data view”
- In the index pattern box, enter “
search-labs-blogs” - In the Timestamp field, select “publish_date”
- Click “Save data view to Kibana
You’ll probably need to change the time picker to set a wider range.
- Click on the timepicker (usually defaults to “Last 15 minutes.”
- Select “Last 1 year”
You can click the + Next to the name of a field on the left column, make a nicely formatted table like the one below.

Discover view showing Search Labs Blogs indexed from the Open Crawler
Hopefully, this short example gave you an idea of what you can do with Open Crawler and the ever-developing semantic capabilities in Elasticsearch.
On-Demand Workshop
You made it to the end! Why not try out all the above hands-on in a real, on-demand workshop environment
Click here to hop over to it.

Frequently Asked Questions
What is Semantic Text?
Semantic Text is Elastic’s easy on-ramp data type for getting up and running with semantic search.
Related Content

December 19, 2025
Elasticsearch Serverless pricing demystified: VCUs and ECUs explained
Learn how Elasticsearch Serverless pricing works for Elastic’s fully-managed deployment offering. We explain VCUs (Search, Ingest, ML) and ECUs, detailing how consumption is based on actual allocated resources, workload complexity, and Search Power.
December 8, 2025
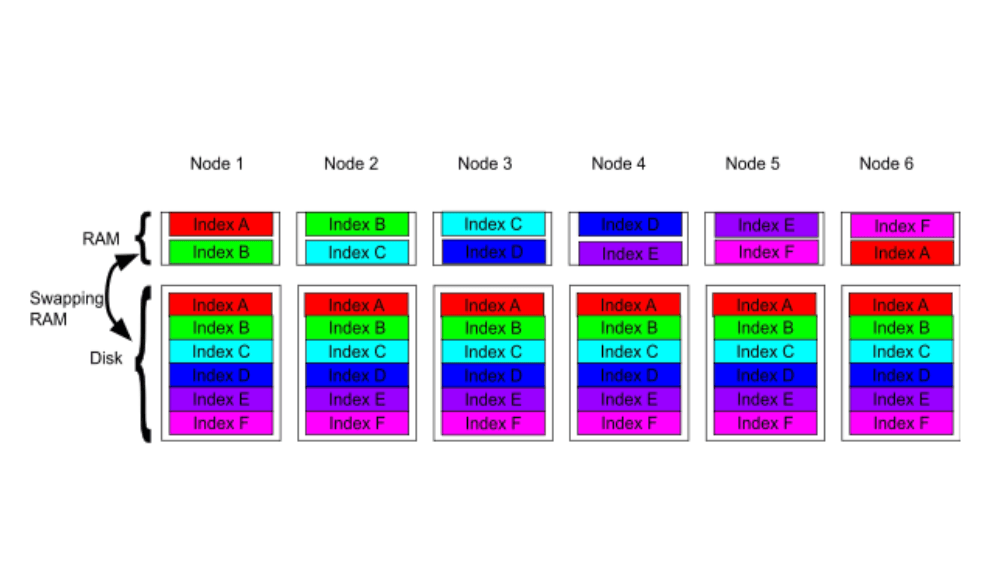
How excessive replica counts can degrade performance, and what to do about it
Learn about the impact of high replica counts in Elasticsearch, and how to ensure cluster stability by right-sizing your replicas.
November 14, 2025
How to deploy Elasticsearch on Azure AKS Automatic
Learn how to deploy Elasticsearch with Kibana on Azure using AKS Automatic and ECK for a partially managed Elasticsearch setup configuration.

November 11, 2025
Configuring recursive chunking for structured documents in Elasticsearch
Learn how to configure recursive chunking in Elasticsearch with chunk size, separator groups, and custom separator lists for optimal structured document indexing.
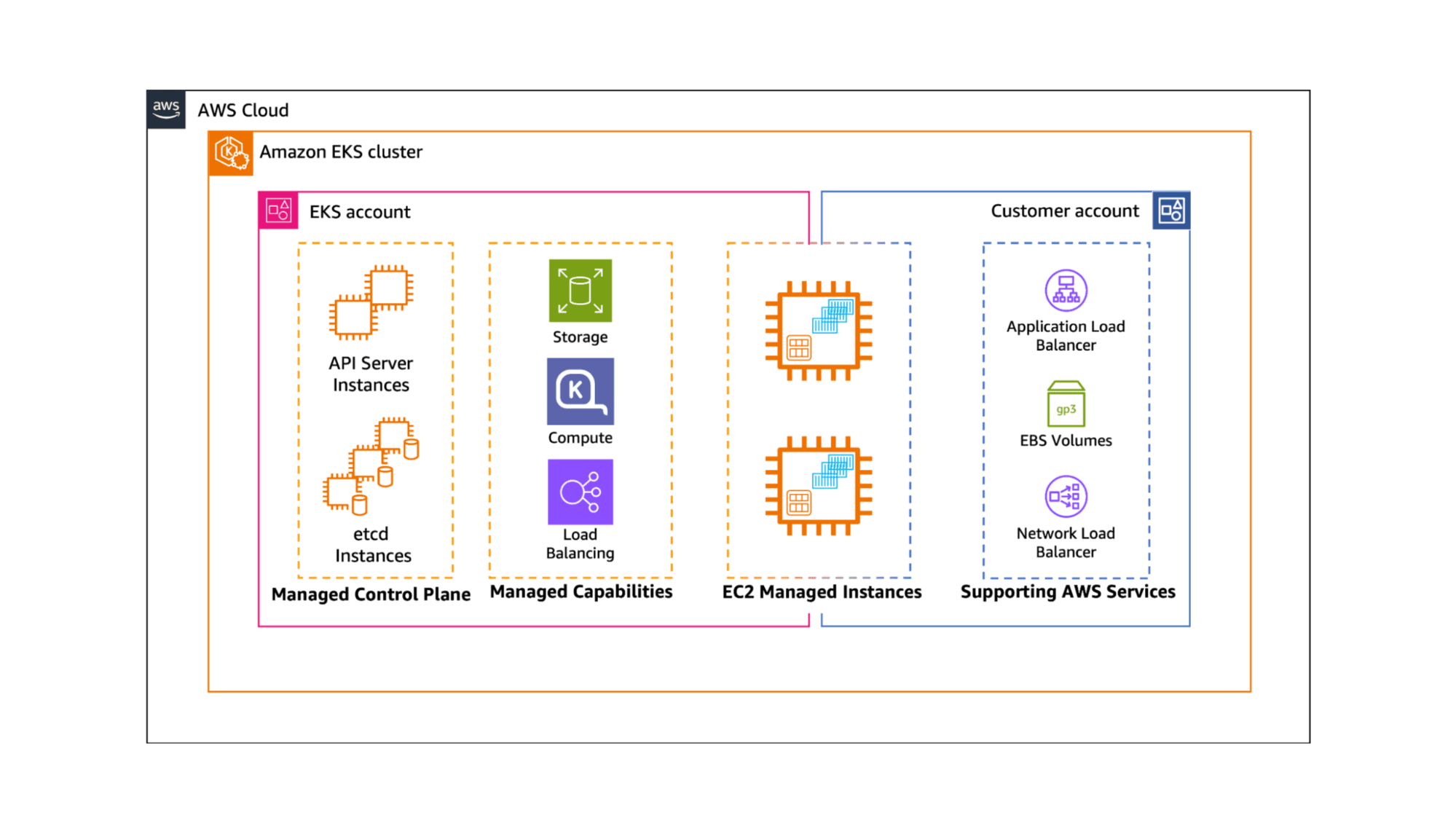
November 10, 2025
How to deploy Elasticsearch and Kibana on AWS EKS auto mode with ECK
Learn how to deploy Elasticsearch and Kibana on Kubernetes using AWS EKS Auto Mode and ECK in this easy-to-follow guide.