Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
In this post we will look at ways to protect Personal Identifiable Information (PII) and sensitive data when using public LLMs in a RAG (Retrieval Augmented Generation) flow. We will explore masking PII and sensitive data using open source libraries and regular expressions as well as using local LLMs to mask data before invoking a public LLM.
Before we begin, let us review some terminology we use in this post.
Terminology
LlamaIndex is a leading data framework for building LLM (Large Language Model) applications. LlamaIndex provides abstractions for various stages of building a RAG (Retrieval Augmented Generation) application. Frameworks like LlamaIndex and LangChain provide abstractions so that applications don’t get tightly coupled to the APIs of any specific LLM.
Elasticsearch is offered by Elastic. Elastic is an industry leader behind Elasticsearch, a scalable data store and vector database that supports full text search for precision, vector search for semantic understanding, and hybrid search for the best of both worlds. Elasticsearch is a distributed, RESTful search and analytics engine, scalable data store, and vector database. The Elasticsearch capabilities we use in this blog are available in the Free and Open version of Elasticsearch.
Retrieval-Augmented Generation (RAG) is an AI technique/pattern where LLMs are provided with external knowledge to generate responses to user queries. This allows LLM responses to be tailored to a specific context and less generic.
Embeddings are numerical representations of the meaning of text/media. They are lower-dimensional representations of high-dimensional information.
RAG and Data Protection
Generally, Large Language Models (LLMs) are good at generating responses based on information available in the model which may be trained on internet data. However, for those queries where information is not available in the model LLMs need to be supplied with external knowledge or specific details not contained within the model. Such information might be in your database or internal knowledge system. Retrieval-Augmented Generation (RAG) is a technique where, for a given user query, you first retrieve relevant context/information from external (to the LLMs) systems (e.g your database) and send that context along with the userquery to LLM to generate a more specific and relevant response.
This makes RAG technique highly effective for applications in question answering, content creation, and anywhere a deep understanding of context and detail is beneficial.
As a result, in a RAG pipeline you run the risk of exposing internal information like PII (Personal Identifiable Information) and sensitive information (e.g names, date of births, account numbers etc ) to public LLMs.
Although your data is secure when using a vector database like Elasticsearch (through various levers like Role based Access Control, Document Level Security etc), care must be taken when you send data outside to a public LLM.
Protecting Personally Identifiable Information (PII) and sensitive data is crucial when using large language models (LLMs) for several reasons:
- Privacy Compliance: Many regions have strict regulations, such as the General Data Protection Regulation (GDPR) in Europe or the California Consumer Privacy Act (CCPA) in the United States, which mandate the protection of personal data. Compliance with these laws is necessary to avoid legal consequences and fines.
- User Trust: Ensuring the confidentiality and integrity of sensitive information builds user trust. Users are more likely to use and interact with systems that they believe will safeguard their privacy.
- Data Security: Protection against data breaches is essential. Sensitive data exposed to LLMs without adequate safeguards can be susceptible to theft or misuse, leading to potential harm such as identity theft or financial fraud.
- Ethical Considerations: Ethically, it's important to respect users' privacy and handle their data responsibly. Mishandling PII can lead to discrimination, stigmatization, or other negative societal impacts.
- Business Reputation: Companies that fail to protect sensitive data may suffer damage to their reputation, which can have long-term negative effects on their business, including loss of customers and revenue.
- Reduction of Abuse Risks: Secure handling of sensitive data helps in preventing malicious use of the data or the model, such as training the models on biased data or using the data to manipulate or harm individuals.
Overall, robust protection of PII and sensitive data is necessary to ensure legal compliance, maintain user trust, ensure data security, uphold ethical standards, protect business reputation, and reduce the risk of abuse.
Quick recap
In the previous post we discussed how to implement Q&A experience using a RAG technique with Elasticsearch as a vector database while using LlamaIndex and a locally running Mistral LLM. Here we build upon that.
Reading the previous post is optional as we will now quickly discuss/recap what we did in the previous post.
We had a sample dataset of call center conversations between agents and customers of a fictional Home insurance company. We built a simple RAG application which answered questions like “What kind of water related issues are customers filing claims for ?”.
At a high level this is how the flow looked.
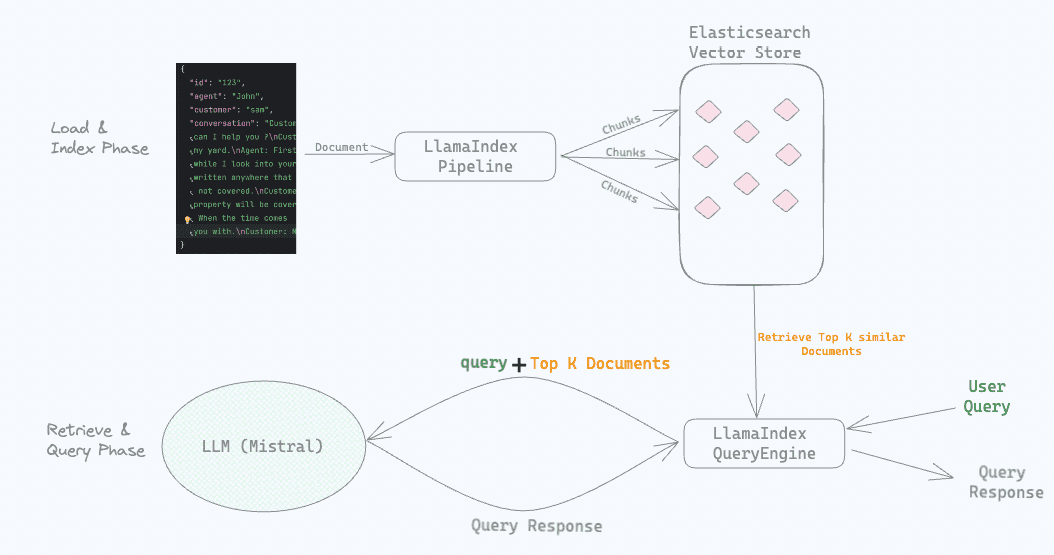
During the Indexing phase, we loaded and Indexed Documents using the LlamaIndex pipeline. The documents were chunked and stored in the Elasticsearch vector database along with their embeddings.
During the query phase when the user asked a question, LlamaIndex retrieved top-K similar documents that were relevant to the query. These top-K relevant documents along with the query were sent to the locally running Mistral LLM which then generated the response to be sent back to the user. Feel free to go through the previous post or explore the code.
In the previous post we had the LLM running locally. However, in production you may want to use an external LLM provided by various companies like OpenAI, Mistral, Anthropic etc. It could be because your use case needs a larger foundational model or running locally is not an option due to enterprise production needs like scalability, availability, performance etc.
Introducing an external LLM in your RAG pipeline exposes you to a risk of inadvertently leaking sensitive and PII to the LLMs. In this post we will explore options on how to Mask PII information as part of your RAG pipeline before sending documents to an external LLM.
RAG with a public LLM
Before discussing how to protect your PII and sensitive information in a RAG pipeline, we will first build a simple RAG application using LlamaIndex, Elasticsearch Vector database and OpenAI LLM.
Prerequisites
We will need the following.
- Elasticsearch up and running as the vector database to store the embeddings. Follow the instructions from the previous post on Installing Elasticsearch.
- Open AI API keys.
Simple RAG Application
For reference, the entire code can be found in this Github Repository(branch:protecting-pii). Cloning the repo is optional as we will go through the code below.
In your favorite IDE, create a new Python application with the below 3 files.
index.pywhere code related to indexing data goes.query.pywhere code related to querying and LLM interaction goes..envwhere configuration properties like API keys go.
We need to install a few packages. We begin by creating a new python virtual environment in the root folder of your application.
Activate the virtual environment and install the below required packages.
Configure OpenAI and Elasticsearch connection properties in the .env file.
Indexing Data
Download the conversations.json file which contains conversations between customers and call center agents of our fictional home insurance company. Place the file in the root directory of the application alongside the 2 python files and the .env file you created earlier. Below is an example of the contents of the file.
Past the below code in index.py which takes care of indexing data.
Running the above code to see creates an Index in Elasticsearch, stores the embeddings in the Elasticsearch index named convo_index.
If you need explanation around LlamaIndex IngestionPipeline please refer to the previous post under the section Create IngestionPipeline.
Querying
In the previous post we used a local LLM for querying.
In this post we use public LLM, OpenAI as seen below.
The above code prints the response from OpenAI as below.
Customers have raised various water-related claims, including issues such as water damage in basements, burst pipes, hail damage to roofs, and denial of claims due to reasons like lack of timely notification, maintenance issues, gradual wear and tear, and pre-existing damage. In each case, customers expressed frustration with claim denials and sought fair evaluations and decisions regarding their claims.
Masking PII in RAG
What we have covered so far involves sending documents as-is to OpenAI along with the user query.
In the RAG pipeline after relevant context is retrieved from a Vector store we have an opportunity to mask PII and sensitive information before sending the query and the context to the LLM.
There are various ways one could mask PII information before sending it to an external LLM, each one having its own merit. We look at some of the options below
- Using NLP Libraries like spacy.io or Presidio (Open source library maintained by Microsoft).
- Using LlamaIndex out-of-the-box
NERPIINodePostprocessor. - Using Local LLMs via
PIINodePostprocessor
Once you implement masking logic using any of the above ways, you could configure the LlamaIndex IngestionPipeline with a PostProcessor (your own custom one or any of the out-of-the-box PostProcessors by LlamaIndex).
Using NLP Libraries
As part of the RAG pipeline we could mask sensitive data using NLP libraries. We will use the spacy.io package in this demo.
Create a new file query_masking_nlp.py and add the below code.
Response by the LLM is shown below.
Customers have raised various water-related claims, including issues such as water damage in basements, burst pipes, hail damage to roofs, and flooding during heavy rainfall. These claims have led to frustrations due to claim denials based on reasons such as lack of timely notification, maintenance issues, gradual wear and tear, and pre-existing damage. Customers have expressed disappointment, stress, and financial burden as a result of these claim denials, seeking fair evaluations and thorough reviews of their claims. Some customers have also faced delays in claim processing, causing further dissatisfaction with the service provided by the insurance company.
In the above code when creating the Llama Index QueryEngine we supply a CustomPostProcessor.
The logic that gets invoked by the QueryEngine in defined in the _postprocess_nodes method of CustomPostProcessor. We are using the SpaCy.io library to detect Named Entities in our and then we are using some regular expressions to replace those names as well as sensitive information before sending the documents to the LLM.
As an example below are parts of original conversations and the Masked conversation created by the CustomPostProcessor.
Original text:
Customer: Hi, I'm Matthew Lopez, DOB is October 12th, 1984, and I live at 456 Cedar St, Smalltown, NY 34567. My Policy Number is TUV8901. Agent: Good afternoon, Matthew. How can I assist you today? Customer: Hello, I'm extremely disappointed with your company's decision to deny my claim.
Masked Text by the CustomPostProcessor.
Customer: Hi, I'm [MASKED], [MASKED] is [DOB MASKED], and I live at 456 Cedar St, [MASKED], [MASKED] 34567. My Policy Number is [MASKED]. Agent: Good afternoon, [MASKED]. How can I assist you today? Customer: Hello, I'm extremely disappointed with your company's decision to deny my claim.
Note:
Identifying and masking PII and sensitive information is not a straightforward task. Covering various formats and semantics of sensitive information needs good understanding of your domain and data. Although the code presented above may work for some use cases you may have to modify based on your needs and testing.
Using the LlamaIndex out-of-the-box
LlamaIndex has made it easier to protect PII information in a RAG pipeline by introducing NERPIINodePostprocessor.
Response is as shown below
Customers have raised fire-related claims regarding damage to their properties. In one case, a claim for fire damage to a garage was denied due to arson being excluded from coverage. Another customer filed a claim for fire damage to their home, which was covered under their policy. Additionally, a customer reported a kitchen fire and was assured that fire damage was covered.
Using Local LLMs via
We could also leverage a LLM running locally or in your Private network to do the work of Masking before sending the data to a public LLM.
We will use Mistral running on Ollama on your local machine to do the masking.
Run Mistral locally
Download and install Ollama. After installing Ollama, run this command to download and run mistral
It might take a few minutes to download and run the model locally for the first time. Verify if mistral is running by asking a question like the below “Write a poem about clouds” and verify if the poem is of your liking. Keep ollama running as we will need to interact with the mistral model later through code.
Create a new file called query_masking_local_LLM.py and add the below code.
Response is something like the shown below
Customers have raised fire-related claims regarding damage to their properties. In one case, a claim for fire damage to a garage was denied due to arson being excluded from coverage. Another customer filed a claim for fire damage to their home, which was covered under their policy. Additionally, a customer reported a kitchen fire and was assured that fire damage was covered.
Conclusion
In this post we showed how you could Protect PII and sensitive data when using Public LLMs in a RAG flow. We demonstrated multiple ways of achieving that. It is highly recommended to test these approaches based on your usecase and needs before adopting.
Related Content

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.
January 20, 2026
Context engineering vs. prompt engineering
Learn how context engineering and prompt engineering differ and why mastering both is essential for building production AI agents and RAG systems.
January 2, 2026
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.
December 31, 2025
How to build an agent knowledge base with LangChain and Elasticsearch
Learn how to build an agent knowledge base and test its ability to query sources of information based on context, use WebSearch for out-of-scope queries, and refine recommendations based on user intention.

December 29, 2025
Creating reliable agents with structured outputs in Elasticsearch
Explore what structured outputs are and how to leverage them in Elasticsearch to ground agents in the most relevant context for data contracts.