Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
This article shows you how to combine Microsoft's efficient Phi-3 models with Elastic's semantic search capabilities to create a smart, conversational ordering system. We'll walk through deploying phi-3 on Azure AI Studio, setting up Elastic, and building an application for an Italian restaurant.
In April, Microsoft announced their state-of-the-art phi-3 small models family, which are cost-efficient models, optimized to perform under restricted resource conditions at low latency, making them ideal for massive/real-time tasks.
The phi-3 small family consists of:
- Phi-3-small-8K-instruct
- Phi-3-small-128K-instruct
With a maximum supported context length of 8K and 128K tokens, both models are 7B parameters. Note the instruct suffix means these models, unlike the chat models, are not trained for a conversational role-play flow, but instead to follow specific instructions. You are not intended to chat with them but rather give them tasks to achieve.
Some applications of phi-3 models are local devices, offline environments and scoped/specific tasks. For example, to help interacting with sensor systems using natural language in places like a mine, or a farm where internet is not always available, or analyzing restaurant orders in real time that requires a fast response.
Case study: L'asticco Italian Cuisine
L'asticco Italian Cuisine is a popular restaurant with a wide and customizable menu. Chefs are complaining because orders come with errors, and so they are pushing to have tablets on the tables so clients can directly select what they want to eat. The owners want to keep the human touch, keeping the orders conversational between customers and waiters.
This is a good opportunity to take advantage of the phi-3 small model specs since we can ask the model to listen to the customers and extract the dish and customizations. Also, the waiter can give recommendations to the customer, and confirm the order generated by our application, thus keeping everyone happy. Let's help the staff take orders!
An order is generally taken in many turns, and it may have pauses. So we will allow the application to fill the order on many turns by keeping in memory the state of the order. In addition, to keep the context window small, we will not pass the entire menu to the model, but store the dishes in Elastic and then retrieve them using semantic search.
The flow of the application will look like this:
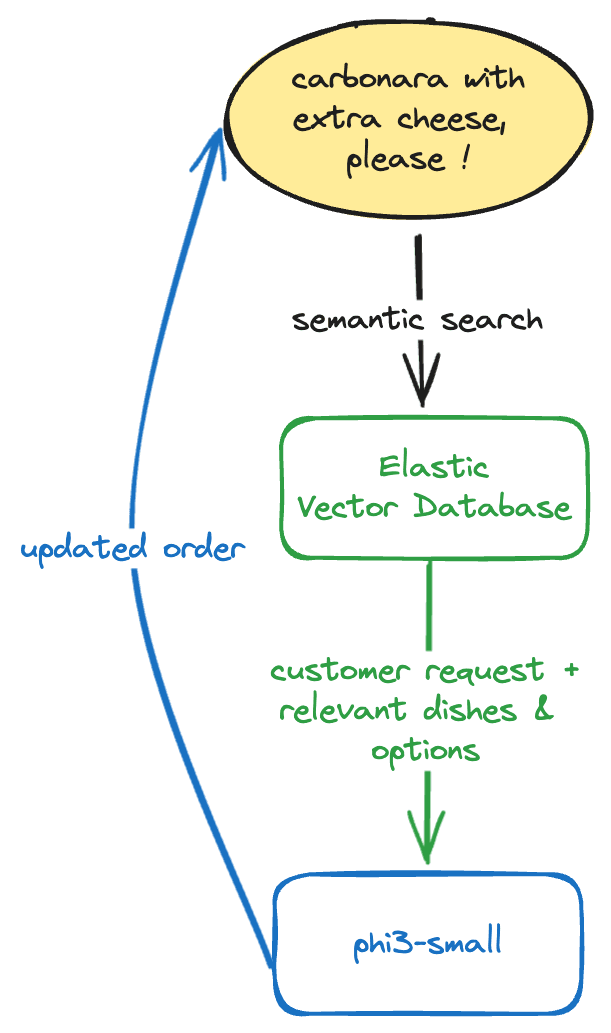
You can follow the notebook to reproduce this article's example here
Steps
- Deploying on Azure AI Studio
- Creating embeddings endpoint
- Creating completion endpoint
- Creating index
- Indexing data
- Taking orders
Deploying on Azure AI Studio
https://ai.azure.com/explore/models?selectedCollection=phi
To deploy a model on Azure AI Studio, you must create an account, find the model in the catalog, and then deploy it:
Select Managed Compute as the deployment option. From there we need to save the target URI and key for the next steps.
If you want to read more about Azure AI Studio, we have an in-depth article about Azure AI Studio you can read here.
Creating embeddings endpoint
For the embeddings endpoint, we are going to use our ELSER model. This will help us find the right dish even if the customer is not using the exact name. Embeddings are also useful for recommending dishes based on semantic similarity between what the customer is saying and the dish description.
To create the ELSER endpoint you can use the Kibana UI:
Or the _inference API:
Creating completion endpoint
We can easily connect to the phi-3 model deployed in Azure AI Studio using Elastic Open Inference Service. You must select "realtime" as the endpoint type, and paste the target uri and key you saved from the first step.
Creating index
We are going to ingest the restaurant dishes, one document per dish, and apply the semantic_text mapping type to the description field. We are going to store the dish customizations as well.
Indexing data
L'asticco menu is very large, so we will ingest only a few dishes:
Orders schema
Before start asking questions, we must define the order schema, which will look like this:
Retrieving documents
For each customer request, we must retrieve the most likely dishes they are referring to using semantic search, to then give that information to the model in the next step.
We get the following dish back:
For this example, we are using the dish description for the search. We can provide the rest of the fields to the model for additional context, or use them as query filters.
Taking orders
Now we have all our relevant pieces:
- Customer request
- Relevant dishes to the request
- Order schema
We can ask phi-3 to help us extract the dishes from the current request, and remember the whole order.
We can try the flow using Kibana and the _inference API.
This will give us the updated order, which will must send in our next request as "current order" until the order is finished:
This will capture the user requests and keep the order status updated, all of this with low latency and high efficiency. A possible optimization is to add recommendations or to consider allergies, so the model can add or remove dishes to the order, or recommend dishes to the user. Do you think you can add that feature?
In the Notebook you will find the full working example capturing the user input in a loop.
Conclusion
Phi-3 small models are a very powerful solution for tasks that demand low cost and latency while solving complex requests like language understanding and data extraction. With Azure AI Studio you can easily deploy the model, and consume it from Elastic seamlessly using the Open Inference Service. To overcome the context length limitation of these small models when managing big data volumes, using a RAG system with Elastic as the vector database is the way to go.
If you are interested in reproducing the examples of this article, you can find the Python Notebook with the requests here
Frequently Asked Questions
What are phi-3 models?
Microsoft's Phi-3 small models are cost-efficient models, optimized to perform under restricted resource conditions at low latency, making them ideal for massive/real-time tasks.
Related Content

January 28, 2026
Apache Lucene 2025 wrap-up
2025 was a stellar year for Apache Lucene; here are our highlights.

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.
January 20, 2026
Context engineering vs. prompt engineering
Learn how context engineering and prompt engineering differ and why mastering both is essential for building production AI agents and RAG systems.
January 2, 2026
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.
December 31, 2025
How to build an agent knowledge base with LangChain and Elasticsearch
Learn how to build an agent knowledge base and test its ability to query sources of information based on context, use WebSearch for out-of-scope queries, and refine recommendations based on user intention.