Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
Elasticsearch vector database now stores and automatically chunks embeddings from the mistral-embed model, with native integrations to the open inference API and the semantic_text field. For developers building RAG applications, this integration eliminates the need to architect bespoke chunking strategies, and makes chunking with vector storage as simple as adding an API key.
Mistral AI provides popular open-source and optimized LLMs, ready for enterprise use cases. The Elasticsearch open inference API enables developers to create inference endpoints and use machine learning models of leading LLM providers. As two companies rooted in openness and community, it was only natural for us to collaborate!
In this blog, we will use Mistral AI’s mistral-embed model in a retrieval augmented generation (RAG) setup.
Get started:
To get started, you’ll need a Mistral account on La Plateforme and an API key generated for your account.
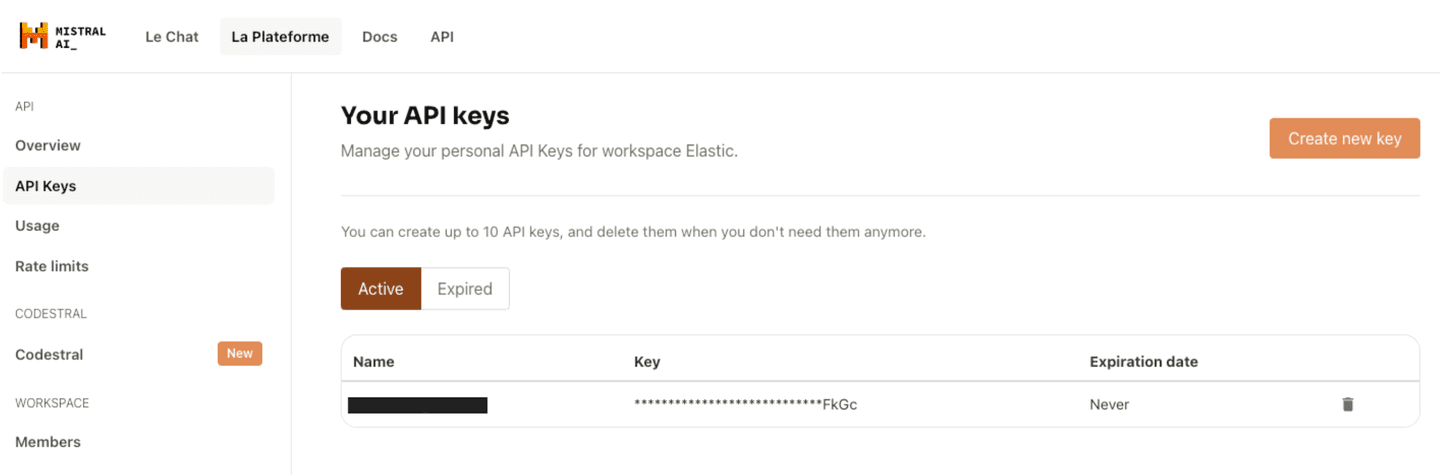
Generate a usage key on Mistral AI’s La Plateforme.
Now, open your Elasticsearch Kibana UI and expand the dev console for the next step.
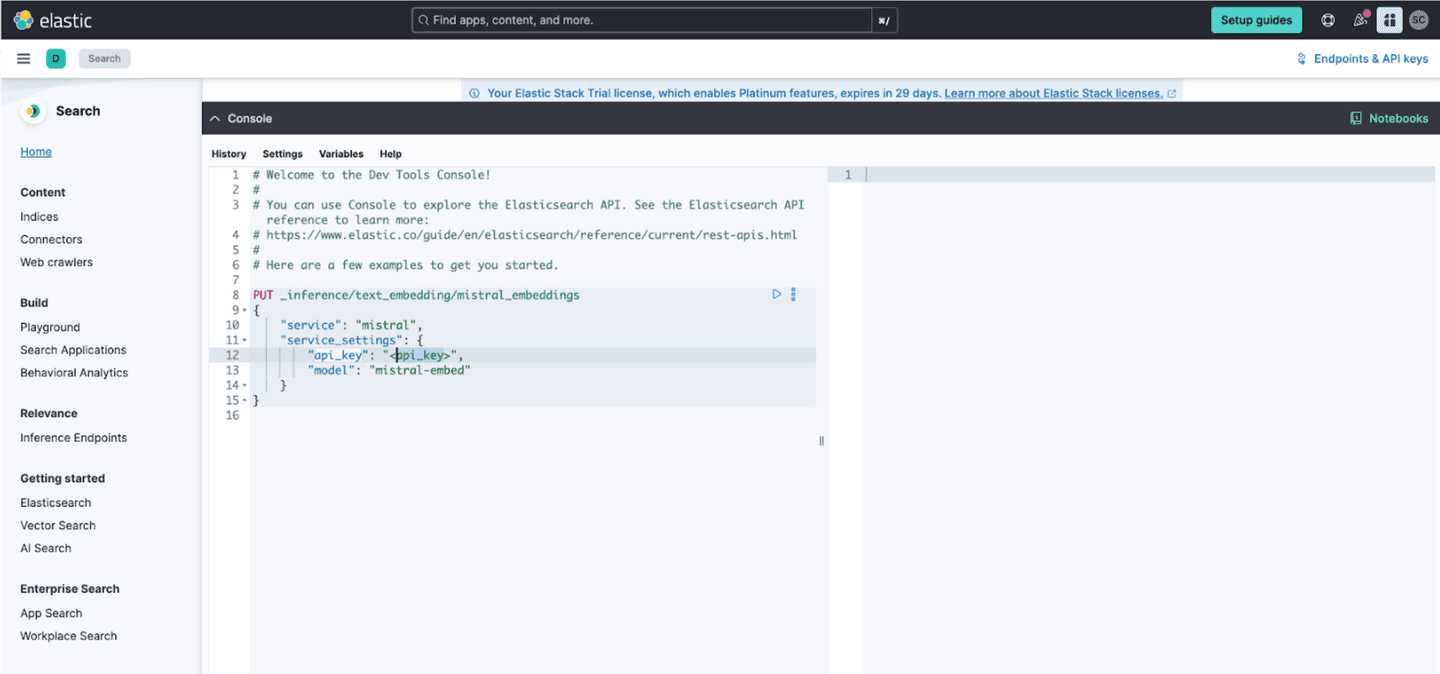
Replace the highlighted API key with the key generated in the Mistral Platform.
You’ll create an inference endpoint by using the create inference API and providing your API key, and the name of the Mistral embedding model. As part of the configuration for an inference endpoint, we will specify the mistral-embed model to create a “text_embedding” endpoint named “mistral_embeddings”
You will receive a response from Elasticsearch with the endpoint that was created successfully:
Note that there are no additional settings for model creation. Elasticsearch will automatically connect to the Mistral platform to test your credentials and the model, and fill in the number of dimensions and similarity measures for you.
Next, let’s test our endpoint to ensure everything is set up correctly. To do this, we’ll call the perform inference API:
The API call will return vthe generated embeddings for the provided input, which will look something like this:
Automated chunking for vectorized data
Now that we have our inference endpoint all set up and verified that it works, we can use the Elasticsearch semantic_text mapping with an index to use it to automatically create our embeddings vectors when we index. To do this, we’ll start by creating an index named “mistral-semantic-index” with a single field to hold our text named content_embeddings:
Once that is set up, we can immediately start using our inference endpoint simply by indexing a document. For example:
Now if we retrieve our document, you will see that internally when the text was indexed our inference endpoint was called and text embeddings were automatically added to our document as well as some additional metadata about the model used for the inference. Under the hood, the semantic_text field type will automatically provide chunking to break larger input text into manageable chunks on which it will perform the inference.
Great! Now that we have that setup and we’ve seen it in action, we can load our data into our index. You can use whatever method you like. We prefer the bulk indexing API. While your data is indexing, the ingest pipeline will use our inference endpoint to perform inference on the content_embedding field data across to the Mistral API.
Semantic Search powered by Mistral AI
Finally, let’s run a semantic search using our data. Using the semantic query type, we’ll search for the phrase “robots you’re searching for”.
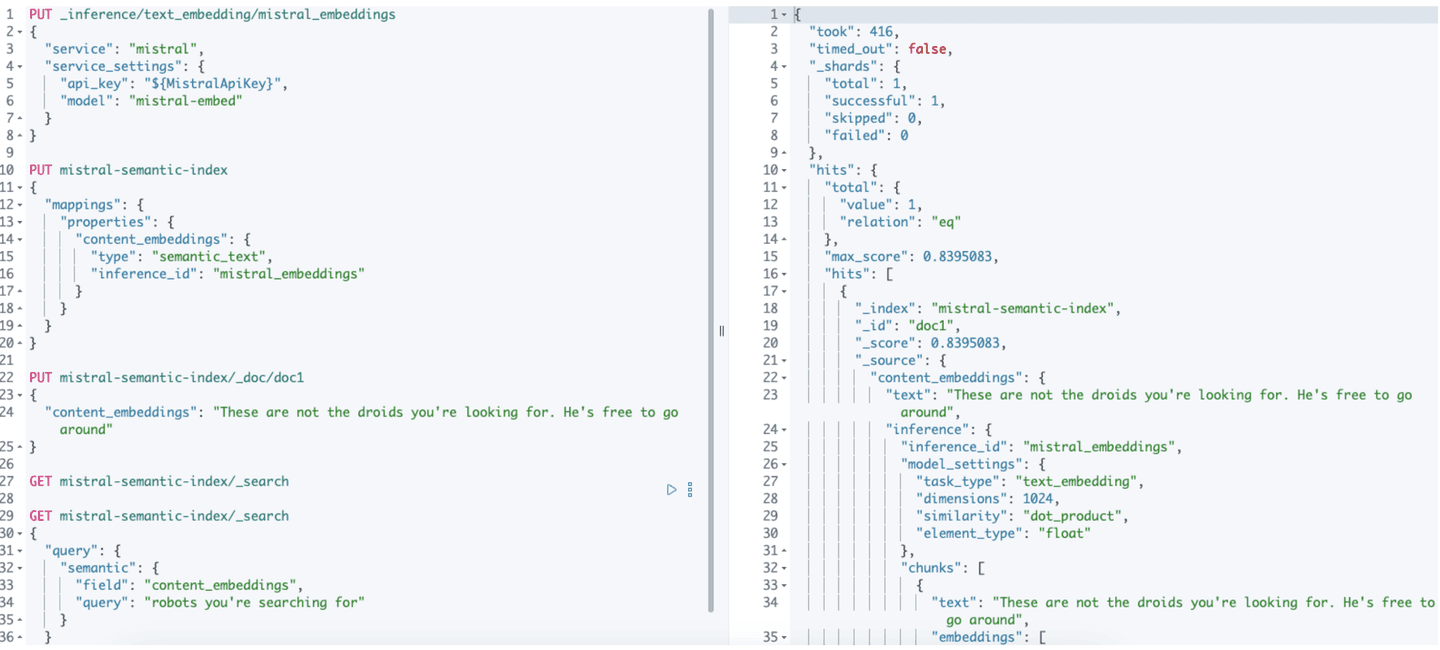
That’s it! When the query is run, Elasticsearch’s semantic text query will use our Mistral inference endpoint to obtain the query vector and use that under the hood to search across our data on the “content_embeddings” field.
We hope you enjoy using this integration, available with Elastic Serverless, or soon on Elastic Cloud Hosted with version 8.15. Head over to the Mistral AI page on Search Labs to get started.
Happy searching!
Related Content

January 28, 2026
Apache Lucene 2025 wrap-up
2025 was a stellar year for Apache Lucene; here are our highlights.

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.
January 20, 2026
Context engineering vs. prompt engineering
Learn how context engineering and prompt engineering differ and why mastering both is essential for building production AI agents and RAG systems.
January 2, 2026
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.
December 31, 2025
How to build an agent knowledge base with LangChain and Elasticsearch
Learn how to build an agent knowledge base and test its ability to query sources of information based on context, use WebSearch for out-of-scope queries, and refine recommendations based on user intention.