Seamlessly connect with leading AI and machine learning platforms. Start a free cloud trial to explore Elastic’s gen AI capabilities or try it on your machine now.
In our previous post we discussed the importance of obtaining deep markups of search results for effective evaluation. We showed that even widely used benchmarks, like those comprising the MTEB retrieval challenge, have relatively few judgments in the top 10 result sets returned by many state of the art retrieval models. Furthermore, we did some exploration regarding how missing judgments can lead to incorrect evaluation of model quality, identifying a high proportion of false negatives in the MS MARCO benchmark for the queries we analyzed.
Large generative models (LLMs) hold the promise of providing many capabilities in a zero- or few-shot fashion. In the context of search relevance, this amounts to providing expert judgments of the relevance of supplied documents to a query. This can help to significantly lower the effort needed to obtain high quality benchmark datasets for your own search systems. However, as with all tasks involving LLMs there are many design choices and these can significantly affect the quality of results one obtains.
In this post, we present a case study of tuning a Phi-3-mini pipeline to provide the best possible agreement with human relevance judgments on the same sample of 100 queries we used to explore missing markup in MS MARCO in our previous post.
Phi models: A short introduction
Phi-3 is a recent generation of Small Language Models (SLMs) from Microsoft. It was shown that properly curated collections of publicly available web data combined with LLM-created synthetic data, enabled "small" language models to match the performance of much larger language models (in some cases 25 times larger) trained on regular data.
The release of Phi models under the name "Phi-3" has introduced a family of models of varied sizes. More specifically,
- Phi-3-mini: a 3.8B parameter model trained on approximately 3.3T tokens that follows the transformer decoder architecture. It comes in two different flavors of context sizes, namely: the 4K which is the default and an enlarged version to 128K. Phi-3-mini’s size allows running inference on edge devices like a modern mobile phone.
- Phi-3-small: a 7B parameter model with a default context length of 8192.
- Phi-3-medium: a model with 14B parameters which uses the same tokenizer and architecture as Phi-3-mini and is trained on the same data for slightly more epochs.
Phi-3-mini has also undergone a post-training process in two stages including supervised finetuning and direct preference optimization to further improve performance and safety of the model. Its strong reasoning capabilities and ability to follow instructions makes it a great choice for our purposes. Typically, the information needed to judge relevance is self-contained in the query and document and so general language skills and reasoning are more important than knowledge for this task.
A note on terminology
Pairwise and pointwise denote two choices of ranking function. A pointwise ranker gets to see the query and one document at a time and decide how relevant that document is to the query. A pairwise ranking function gets to see the query and two documents at a time and decides which is more relevant.
Our experiment: Evaluating search relevance
As we alluded, there are multiple choices in the prompt and the way an LLM is used that can influence its effectiveness for any given task. These should be evaluated systematically before it is deployed for real. Although details of the optimal prompt wording may change between LLMs, general principles have emerged that work for a variety of tasks and models. Furthermore, task specific strategies can transfer to different datasets, much as task specific finetuning does.
For our annotation task we have clearly defined quality metrics: the number of agreements between the relevance judgment (0 or 1) assigned by the LLM and that we assign ourselves. This constitutes a confusion matrix for each design choice. As well as presenting the optimal choices, we perform some ablation studies for the different choices we found. This guides us on where to expend optimization effort when creating judgment lists for different retrieval tasks.
We explore the impact on quality of the following broad design choices:
- Prompt wording for a zero-shot pointwise approach
- A pairwise approach where you have one relevant document for each query
- Few-shot chain-of-thought
- Ensembling
We note in passing that, although we did not explore this, these approaches are often compatible and we expect certain combinations are likely to achieve further improvements.
About the annotation task
In our previous blog post we touched upon the issue of incomplete markup in the MTEB benchmark and as a proof concept we created a dataset from the dev portion of the MS MARCO dataset. More specifically, we pulled 100 queries and kept the top-5 negative documents (based on the original relevance judgments file) that were retrieved with BM25 and reranked with Cohere-v2. We then manually scored all 500 (query, document) pairs.
Regarding the manual annotation task we decided to go with a strict approach and mark documents as positives when there was high enough confidence. We tried to be consistent by adhering to the following criteria:
- The retrieved documents are on-topic and contain all the necessary information to address the query.
- In the case of ambiguous queries we resort to the positive document (labeled through the original relevance judgments supplied with MS MARCO) to infer some additional metadata.
Regarding the second point, we can use as an example the query age requirements for name change (MS MARCO query ID 14151) . In this case, most of the returned documents seemed relevant at first glance as they provided on-topic information for name change in different states, but by reviewing the positive document we saw that the age requirements were localized for the state of California. Thus, documents which contained information for other states were finally marked as irrelevant. Given the metadata are not provided to the relevance model, we would not recommend this approach evaluating your own retrieval systems. However, for this task we decided to try as much as possible to stay in agreement with the intentions of the original annotators.
Finally, there were 33 documents we decided to remove. These included queries and their associated documents for which the positive document did not appear to provide any useful information, judgments we did not feel qualified to make and documents which appeared to answer the question, but provided contradictory information to the positive example. We felt these would introduce errors to the evaluation process without providing any additional useful differentiation between design choices.
In summary, out of the 500 pairs considered, our manual annotation gave us:
- 288 relevant documents
- 179 irrelevant documents
- 33 removed documents
We ended up making some revisions to our initial markup based on reviewing the chain-of-thought judgment errors and their rationale and have updated our previous post to reflect this process. This underlines how challenging it can be to determine relevance. We discuss the revision process in the context of that experiment.
About the language model
We decided to work with the Phi-3-mini-4k-instruct model using the transformers library because:
- It contains only 3.8B parameters that when loaded with 4-bit quantization (through bitsandbytes it can easily fit into a consumer-grade GPU
- As noted in the technical report:
- the model performs quite well on reasoning tasks, and
- the model does not have enough capacity to store too much "factual knowledge" which can be an advantage in the context of retrieval evaluation as we expect a smaller hallucination rate
For details on how we use this model see the notebook.
Results summary
Our baseline performance was obtained by the simple zero-shot pointwise prompt shown below. We choose to measure the quality of the LLM judge using the micro F1 score vs the ground truth labeling. Specifically, this is the fraction of correctly labeled (query, document) pairs or overall accuracy. This prompt achieves an F1 score of 0.7002.
This is the baseline prompt where query_text and retrieved_text are placeholders for the query and document to judge
The figure below summarizes the accuracy we obtain from the various techniques we evaluated. In practice, one would typically want to apply these techniques to unseen queries and documents (or else you don’t save any effort). By ‘fine-tuning’ the behavior of the model on a smaller (validation) set we implicitly assume that these improvements will ‘transfer’ well to the test dataset. Whilst this is usually justified, if you have more data it can be useful to hold out a portion for testing the optimisations you make.
Figure 1. provides a summary of the impact on the accuracy of the various design choices we studied. We discuss these in detail next.
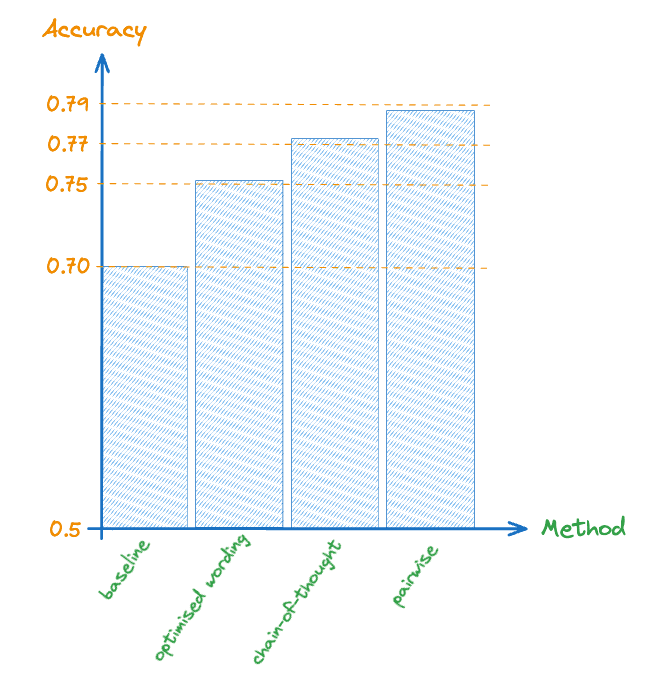
The role of word choice on prompt performance
Optimizing a prompt for a downstream task can be quite challenging; as others have noted, even small paraphrases can have a drastic effect on performance.
Some good general guidelines are that prompts should:
- Maintain consistent style and naming conventions,
- Clearly delineate distinct content
- Unambiguously define the task, and
- Avoid extra verbiage (except for special cases)
Consistent naming of entities minimizes the risk that the LLM becomes confused about task descriptions that reference them. Capitalisation or punctuation can help. In the example below, we always refer to "Query" and "Retrieved Document" making clear that these are proper names we have defined in the context that we reference them.
Keeping separate content clearly delineated helps the attention mechanism avoid confounding content you wish to disambiguate. In the example below we use ##### to surround the supplied "Query" and "Retrieved Document", keeping them distinct from their definition in the task description.
In general, you should strive to make each sentence clear and concise. Clear unambiguous task definitions are particularly important. One can observe dramatic effects, particularly for weaker models, from accidental typos, contradictory content and missing punctuation in key passages. It is always worth printing and proofreading your prompts. Aside from "bugs", there is often a trade off in precision and conciseness; being too brief can introduce ambiguity. Furthermore, some tasks are intrinsically nuanced and so lack a simple clear definition. Judging relevance is such a task since it can depend on multiple factors some of which are left unsaid. We will return to this topic later.
Aside from certain special phrases, such as those which condition for particular behavior in the LLM, irrelevant content usually simply acts as a distraction and should be avoided.
The best zero shot variant of our baseline prompt is shown below. In particular, the variants we compared excluded pairwise and chain-of-thought strategies, which we will discuss later.
This is the best zero-shot pointwise prompt
The results from this first experiment are shown in the table below:
| LLM\Relevant | LLM\Not Relevant | |
|---|---|---|
| Human\Relevant | 244 | 44 |
| Human\Not Relevant | 70 | 109 |
| Table 1. Pointwise results |
The micro F1-score in this case is 0.7559, whereas focusing only on the "Relevant" class we get Precision = 0.7771, Recall = 0.8472 and F1(Relevant class) = 0.8106. It’s worth noting that the LLM output could be parsed without any issues, i.e. the output always contained the tokens either "Relevant" or "Not Relevant".
For the high-level design of the prompt we drew some inspiration from this paper that builds a taxonomy for prompt templates in the context of zero-shot LLM re-rankers and we adapt it to our specific task. The taxonomy is built around the following high-level components:
- Evidence: the query and the associated passage(s) to be judged
- Task Instruction: The instructions associated with our judging task
- Output Type: The instructions that specify the desired format for the output
- Tone Words: Positive or negative expressions that aim to steer the performance of the language model e.g. "please", "good luck"
- Role Playing: The instructions asking the LM to "impersonate" a role
We used the following prompt template to logically group the prompt components (the element tags are for illustrative purposes and were not used to prime the language model).
This is the prompt template structure. The element tags are here just for illustrative purposes, they were not part of the prompt sent to the language model.
A benefit of adding structure to the prompt template is that it makes it easier to iterate on word choices in a more systematic way. We present some of the results of those experiments below.
Tone words
We investigated three different choices for the "Tone words" section as presented above. We tried the following versions:
Good luckwhich gives a micro-F1 score of 0.7473.- A version that urges the LM to produce a good score such as
It's absolutely crucial that you perform well on this task as it will have a direct impact on the quality of the search results for our users. The micro F1-score in this case was 0.7259 - Removing the tone words section gave us the best score (0.7559) as depicted above.
Output instructions
In the prompts above we have set the output instruction as You should provide your answer in the form of a boolean value: "Relevant" or "Not Relevant". We have found that Phi-3 behaves very well and adheres to the output format that we requested with 0 errors. Removing that guideline leads to unparsable output as expected.
"Take a step back" reasoning
In the prompts presented above we have added a line to steer the model into employing a "step back" reasoning (Take a step back and reflect carefully on how best to solve your task). Our experiments show that the role of this component is absolutely critical. By removing this line we observed a significant drop in the accuracy as the model entered a failure mode over-predicting one class over the other (in this case the "Relevant" class). More specifically, the set of prompts that contained this guideline led to a prediction rate of 68.9% on average for the "Relevant" class whereas in prompts with the guideline removed the rate rose to 85.6% rendering the model unusable. (As a reminder from the previous blog post the percentage of "Relevant" data points after manual annotation is ~57%.)
Role playing
For the role-playing section we didn’t observe a clear pattern regarding its effect. Adding or removing this component yielded small differences in absolute terms (mostly positive but also some negative).
More precise instructions
In the discussion so far we have implicitly assumed that the language model ‘knows’ how to interpret the task instructions in order to assess the relevance between the query and the document. We also investigated the effect of more detailed instructions following the work of Thomas et al. There, the authors elicit a step-by-step reasoning by asking the model to explicitly score two aspects of the problem - namely topicality and trust - prior to deciding on a final score for the query, document pair. Inspired by the methodology of Thomas et al. we incorporated the following guidelines (and variations of it) between the evidence and the output instructions sections:
Adding instructions
In this case we didn’t observe a benefit from adding these guidelines in the accuracy metric and the best score we achieved was 0.7238. One common pattern was the tendency of the language model to be more 'hesitant' into predicting the 'Relevant' class which can be attributed to the additional criteria that need to be satisfied. In other words, it seems like a useful ‘knob’ that can be tuned to regulate the behavior of a language model if you are more sensitive to certain classes of error.
Pairwise
Pairwise methods have been considered in the context of LLM reranking, where an LLM is presented with a query and two candidate passages and it is asked to select the better one. After repeating multiple times for different pairs of documents, these intermediate results are aggregated to produce the final ranking of the documents. It has been shown that pairwise approaches are usually quite effective and also exhibit low variability in the generated results. The superiority, especially compared to pointwise methods, can be potentially explained by the fact that the extra document(s) provide additional context for making individual relevance judgments. Pairwise comparisons have been also applied more broadly in LLM evaluation setups such as MT-Bench where the LLM acting as judge is presented with a question and two answers and is asked to determine which one is better or declare a tie. This is a good way to enhance stability according to recent studies.
Here, we experiment to see if we can improve accuracy by injecting a positive example. This might sound like it defeats the purpose to reduce manual labeling effort. However, it actually aligns well with the deep mark up scenario: it enables you to "transfer" your judgment on one result to label the top-n. The most relevant work is this 1-shot labeling (1SL) study. It explores the effectiveness of extending manual markup with noisy LLM labels using the same pairwise approach. The authors found significant improvements in correlation to full human evaluations of a retrieval system compared to evaluating using single labels alone. This was despite errors in the LLM labels.
The prompt template is adapted as follows:
Pairwise prompting
The results from this adaptation to the prompt are shown in the table below
| LLM\Relevant | LLM\Not Relevant | |
|---|---|---|
| Human\Relevant | 246 | 42 |
| Human\Not Relevant | 58 | 121 |
| Table 2. Pairwise results |
where we observe a micro-F1 score of 0.7859 and focusing on the relevant class we get precision equal to 0.8092, a recall score of 0.8542 and a F1 score of 0.8311
From a high level perspective we ask the language model to perform two sub-tasks before responding:
- Extract the information from the positive document that answers the query
- Look for that piece of information in the retrieved document and respond with a relevance label
Another interesting avenue to explore is to combine this sort of approach with current synthetic data generation techniques like RAGAS to enhance offline evaluation. In these frameworks documents are sampled from the target corpus and are fed to an LLM "asking" it to produce a suitable query. These (query, document) pairs form a test collection that can then be used to evaluate the performance of a QA pipeline or a RAG setup more generally. This process seems likely to also benefit from 1SL.
Few-shot chain-of-thought
In-context learning (ICL) has been a distinctive characteristic of the current state-of-the-art language models where through a few demonstrations the model can generalize to unseen inputs. A recent paper from Microsoft provides some intuition around this behavior by treating ICL as implicit finetuning where the LLMs act as meta-optimizers that produce meta-gradients according to the demonstration examples. Separately, it has been demonstrated in many contexts that getting LLMs to first generate text that provides some analysis of the task can improve performance. This is particularly important for tasks that require some form of reasoning. There are many variants on this theme, the prototype was chain-of-thought prompting. This asks the LLM to break complex tasks into multiple smaller steps and solve them one-by-one. These two techniques can be combined and we study this strategy below.
Giving the LLM examples of our preferred relevance judgments, using the gradient descent analogy, should cause it to better align with our preferences. In the spirit of active learning these examples can be tailored to errors the LLM is observed to make. Furthermore, since judgments typically require weighing multiple factors, having the LLM clearly explain these to itself before it makes its judgment is a good candidate for chain-of-thought. We decided to steer the steps the LLM uses for its chain-of-thought as follows:
- Expand the query to try and infer intent
- Summarize the document to extract the key information it provides
- Justify the relevance judgment
- Make the judgment
Note that autoregressive models only get to attend to the tokens they have already generated, so it is vital that the judgment step comes at the end.
An additional advantage of generating rationales is that these can be useful to present to human annotators. Recent research suggests these should not be considered as an explanation of the LLMs "thought process". However, we found in practice that they are still often useful to diagnose error cases. Furthermore, we found them to be consistently useful to understand a point of view for the relevance judgment and this actually caused us to revise some of our original relevance judgments.
There are downsides with this approach:
- It costs far more in terms of input and output tokens,
- There is a risk that information is hallucinated in the generation process which misinforms the relevance judgment,
- Models can place too much emphasis on examples.
The below shows the prompt we evaluated. The choice of examples to supply is important. These were designed to demonstrate a mixture of skills we thought would be useful as well as fix point issues we were observing:
- Example 1 is a case when matching a synonym, which is often useful, is undesirable because the query intent is rather specific. The user is likely looking for the dictionary definition of a word they do not know, so synonym definitions are not useful. This was responsible for a number of mistakes in our test corpus.
- Example 2 demonstrates inductive reasoning applied to a relevance judgment. This is often useful, with the assessment having to weigh up the probability the document matches the user’s intent.
- Example 3 is an example of entity resolution. Queries that mention specific entities usually require examples related to those specific entities and this overrides other considerations.
Few-shot Chain-of-thought prompt
Before discussing the results, it is worth highlighting some of the subtleties involved in making good judgments.
One recurring challenge we found in marking up this small dataset is how to treat documents that only provide links to information that would likely answer the question. In the context of a web search engine this is a relevant response; however, if the snippet were being supplied to an LLM to generate a response it may be less useful. We followed the positive examples in such cases (which were in fact inconsistent in this respect!). In general, we advise you to carefully consider what constitutes relevant in the context of your own datasets and retrieval tasks and suggest that this is often best done by trying to generalize from example queries and their retrieved results.
Another challenge is where to draw the line in what constitutes relevant information. For example, the main helpline for Amazon may not be directly related to a query for "amazon fire stick customer service" but it would likely be useful. Again we were guided by the positive examples when making our own judgments.
The LLM false negative errors we observed fell into several categories. For the sake of brevity we mention the two dominant ones: we define these as pedantry and selective blindness. For pedantry the LLM is correct in a pedantic sense, but in our opinion it fails to properly assess the balance of probability that the document is useful. For selective blindness the LLM seems to miss important details in its reading of the document content. We give examples below.
| pedantry |
|---|
| blindness |
|---|
Table 3. Examples of false negative LLM relevance judgments
Similarly, we saw several interesting false positive categories: we define two of these as confabulations and invented content. For confabulations the LLM fails to distinguish between entities in the query and document. For invented content it typically invents information about either the query or document which misleads the relevance judgment. We include examples below.
| Confabulations |
|---|
| Invented Content |
|---|
Table 4. Examples of false positive LLM relevance judgments
In the first example, it is interesting that Titanic is misinterpreted as Titan. This is likely in part a side effect of the tokenization: neither titan nor titanic are present in the Phi-3 vocabulary. In the second example, we hypothesize that the question in the retrieved document confuses the LLM regarding what is the actual query. It is possible that better delineation of context could help with this specific problem.
Finally, the process of reading LLM rationales caused us to revise our judgment of 15 cases and exclude one additional example (on the grounds that the positive example was wrong). A typical example is that the LLM includes information which helps us better evaluate relevance itself. We show such a case below. In this context we strongly advise to double check any knowledge beyond the data that the LLM brings since there is risk of hallucination.
The final results with the updated markup are provided in the table below. The micro F1-score in this case is 0.773, whereas focusing only on the "Relevant" class we get Precision = 0.7809, Recall = 0.8785 and F1(Relevant class) = 0.8268. In all cases the LLM output could be parsed without any issues, i.e. it always contained either Answer: "Relevant" or Answer: "Not Relevant".
| LLM\Relevant | LLM\Not Relevant | |
|---|---|---|
| Human\Relevant | 253 | 35 |
| Human\Not Relevant | 71 | 108 |
| Table 5. Chain-of-thought results |
Ensemble
One common technique to increase the performance of AI systems in language tasks is to first perform multiple inferences over the same set of input data and then aggregate the intermediate results - usually through majority voting. Here is also an interesting paper discussing how the number of LM calls and the "hardness" of the queries affect the performance of systems which aggregate LM responses in a similar manner.
We experimented with multiple inferences and majority voting as well: in order to simulate this behavior in our setup we enabled sampling (more in the accompanying notebook), we increased the temperature to 0.5 and finally we asked the model to return 5 sequences through beam search that were aggregated to output a single response via majority voting. As an extra metric we computed the "majority rate" per data point which is simply the percentage of sequences matching the majority response.
It is worth noting that temperature only affects token selection. Therefore, it can only affect matters after the first token is decoded. Even so this can affect outputs from all our prompts. For example, it can insert an extra token at the start of the sequence or it can deviate into alternative forms like "Not sure". We parse the raw output using a regular expression to match the instructed output and discard votes from runs we were unable to parse.
We investigated both pointwise and pairwise prompts: In the pointwise case, we observed a consistent uplift between 0.6 and 1.5 percentage points (in terms of micro-F1) for 'suboptimal' prompts i.e. whose score was below the optimal (~0.76). On the other hand, majority voting did not give us a better top score. In other words, the gains are larger when you are far from the top but as you get closer you reach a plateau in terms of performance. In the pairwise case the increase was much more modest (~0.2 pp) and less robust as we came across cases where the effect was in fact negative.
Another interesting aspect came from the analysis of the majority rate: as data points with values less than 1.0 surfaced queries that they were either ambiguous (e.g. query ID 1089846 - the economics is or are) or "hard to decide" i.e. some of the 33 undefined cases that were eliminated from evaluation.
Overall, such aggregation techniques are becoming more and more common given the performance boost they offer on certain tasks. Nevertheless, it’s an area that requires some additional exploration considering the extra computational cost tied to the additional inference steps. Also bear in mind that the more constrained the output the less scope it has to affect results.
Conclusion
We set out to explore whether we can use an LLM to bootstrap a search evaluation dataset. We took as a test case a sample of queries from MS MARCO together with the most relevant documents found by a strong retrieval system. We showed using a strong, small and permissively-licensed language model (in our case Phi-3 mini) that we are able to achieve good correlation with human judgments.
At the same time we wanted to explore design choices in the use of the LLM. We tested:
- The prompt wording,
- Supplying a known relevant document,
- Chain-of-thought, and
- Ensembling multiple generations.
We found significant gains could be obtained just by changing the prompt wording. We suggest some general guidelines for writing effective prompts. However, small details can have noticeable effects. Generally, some trial and error is required and automation frameworks can be useful when you have a test set.
Chain-of-thought produced further improvements but comes at the cost of expensive generation. Judgment rationales are interesting in their own right and allowed us to improve our original manual markup.
Our best result was obtained with a pairwise approach which supplied an example positive document. We postulate that part of the gain comes because it better aligns with our evaluation criteria, which was strongly steered by the supplied relevant document. However, other studies have shown improvements over pointwise approaches and we think it represents an interesting strategy for obtaining deep markup from shallow markup.
Finally, we explored using multiple generations, via non-zero temperature. This achieved some modest benefits for our baseline strategy, but we expect the main advantage to be associated with complex outputs such as chain-of-thought. A natural next step would be ensembling of prompts.
In this blog, we really just scratched the surface of using LLMs for evaluating search relevance. Longer term we expect them to have a larger and larger role in multiple aspects of building information retrieval systems and this is something we’re actively exploring at Elastic.
Frequently Asked Questions
What are Phi-3 models?
Phi-3 is a recent generation of Small Language Models (SLMs) from Microsoft. It was shown that properly curated collections of publicly available web data combined with LLM-created synthetic data, enabled "small" language models to match the performance of much larger language models (in some cases 25 times larger) trained on regular data.
Related Content
January 2, 2026
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.

November 4, 2025
Multimodal search for mountain peaks with Elasticsearch and SigLIP-2
Learn how to implement text-to-image and image-to-image multimodal search using SigLIP-2 embeddings and Elasticsearch kNN vector search. Project focus: finding Mount Ama Dablam peak photos from an Everest trek.

October 15, 2025
Training LTR models in Elasticsearch with judgement lists based on user behavior data
Learn how to use UBI data to create judgment lists to automate the training of your Learning to Rank (LTR) models in Elasticsearch.
September 19, 2025
Using TwelveLabs’ Marengo video embedding model with Amazon Bedrock and Elasticsearch
Creating a small app to search video embeddings from TwelveLabs' Marengo model.
Using LangExtract and Elasticsearch
Learn how to extract structured data from free-form text using LangExtract and store it as fields in Elasticsearch.