From vector search to powerful REST APIs, Elasticsearch offers developers the most extensive search toolkit. Dive into sample notebooks on GitHub to try something new. You can also start your free trial or run Elasticsearch locally today.
Elastic Cloud Vector Search optimized hardware profile is available for Elastic Cloud on Microsoft Azure users. This hardware profile is optimized for applications that use Elasticsearch as a vector database to store dense or sparse embeddings for search and Generative AI use cases powered by RAG (retrieval augmented generation).
Vector Search optimized hardware profile: what you need to know
Elastic Cloud users benefit from having Elastic managed infrastructure across all major cloud providers (Azure, GCP and AWS) along with wide region support for Microsoft Azure users. This release follows the previous announcement of a Vector Search optimized hardware profile for GCP. AWS users have had access to the Vector Search optimized profile since November 2023. For more specific details on the instance configuration for this Azure hardware profile, refer to our documentation for instance type: azure.es.datahot.lsv3
Vector Search, HNSW, and Memory
Elasticsearch uses the Hierarchical Navigable Small World graph (HNSW) data structure to implement its Approximate Nearest Neighbor search (ANN). Because of its layered approach, HNSW's hierarchical aspect offers excellent query latency. To be most performant, HNSW requires the vectors to be cached in the node's memory. This caching is done automatically and uses the available RAM not taken up by the Elasticsearch JVM. Because of this, memory optimizations are important steps for scalability.
Consult our vector search tuning guide to determine the right setup for your vector search embeddings and whether you have adequate memory for your deployment.
With this in mind, the Vector Search optimized hardware profile is configured with a smaller than standard Elasticsearch JVM heap setting. This provides more RAM for caching vectors on a node, allowing users to provision fewer nodes for their vector search use cases.
If you’re using compression techniques like scalar quantization, the memory requirement is lowered by a factor of 4. To store quantized embeddings (available in versions Elasticsearch 8.12 and later) simply ensure that you’re storing in the correct element_type: byte. To utilize our automatic quantization of float vectors update your embeddings to use index type: int8_hnsw like in the following mapping example.
In upcoming versions, Elasticsearch will provide this as the default mapping, removing the need for users to adjust their mapping. For further reading, we provide an evaluation of scalar quantization in Elasticsearch in this blog.
Combining this optimized hardware profile with Elasticsearch’s automatic quantization are two examples where Elastic is focused on vector search and our vector database to be cost-effective while still being extremely performant.
Getting started with Elastic Cloud Vector Search optimized hardware profile
Start a free trial on Elastic Cloud and simply select the new Vector Search optimized profile to get started.
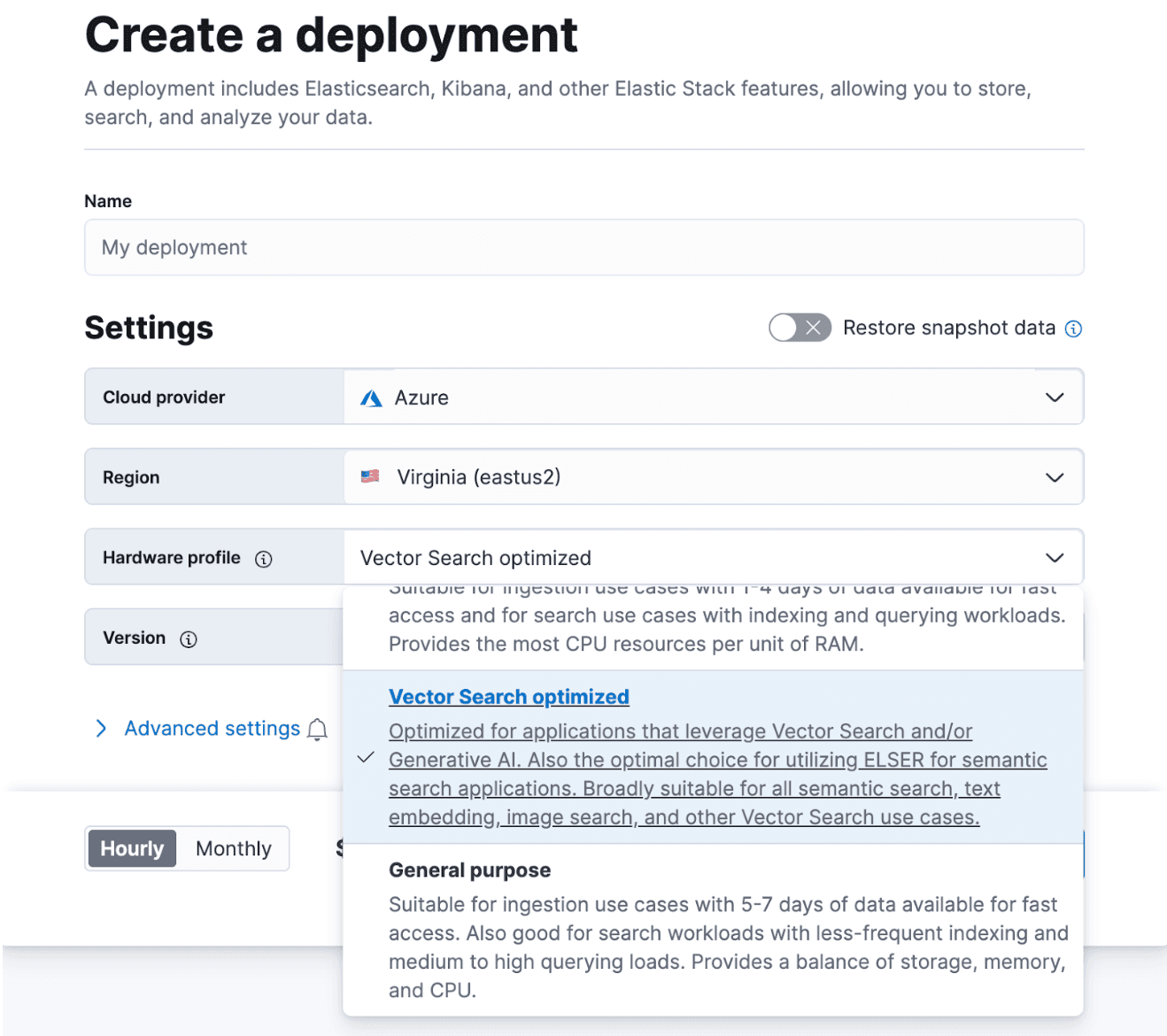
Migrating existing Elastic Cloud deployments
Migrating to this new Vector Search optimized hardware profile is a few clicks away. Simply navigate to your Elastic Cloud management UI, click to manage the specific deployment, and edit the hardware profile. In this example, we are migrating from a ‘Storage optimized’ profile to the new ‘Vector Search’ optimized profile. When choosing to do so, there is a small reduction to the available storage, but what is gained is the ability to store more vectors per memory with vector search at a lower cost.
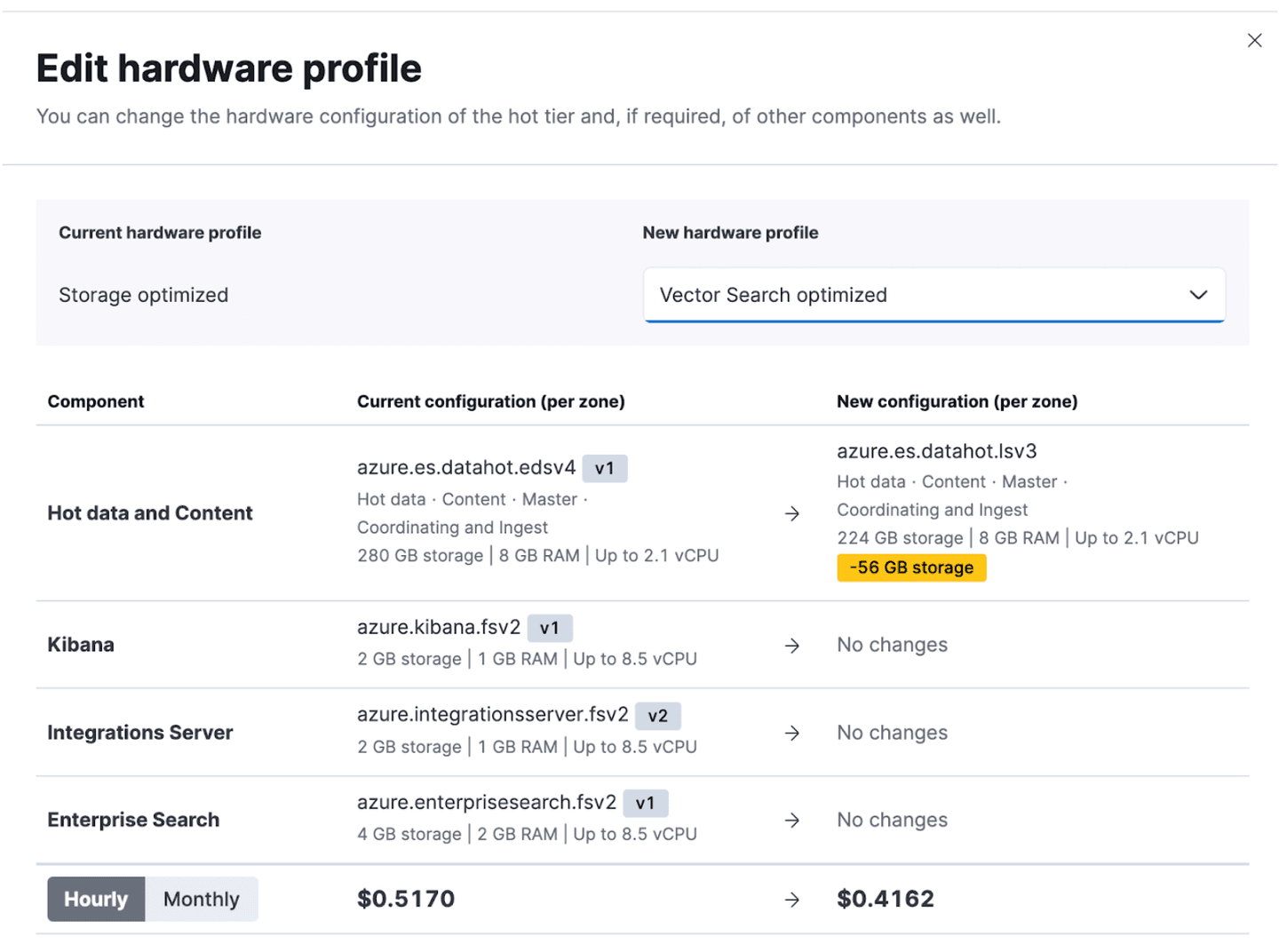
Migrating to a new hardware profile uses the grow and shrink approach for deployment changes. This approach adds new instances, migrates data from old instances to the new ones, and then shrinks the deployment by removing the old instances. This approach allows for high availability during configuration changes even for single availability zones.
The following image shows a typical architecture for a deployment running in Elastic Cloud, where vector search will be the primary use case.

This example deployment uses our new Vector Search optimized hardware profile, now available in Azure. This setup includes:
- Two data nodes in our hot tier with our vector search profile
- One Kibana node
- One Machine Learning node
- One integration server
- One master tiebreaker
By deploying these two “full-sized” data nodes with the Vector Search optimized hardware profile and while taking advantage of Elastic’s automatic dense vector scalar quantization, you can index roughly 60 million vectors, including one replica (with 768 dimensions).
Conclusion
Vector search is a powerful tool when building modern search applications, be it for semantic document retrieval on its own or integrating with an LLM service provider in a RAG setup. Elasticsearch provides a full-featured vector database natively integrated with a full-featured search platform. Along with improving vector search feature set and usability, Elastic continues to improve scalability. The vector search node type is the latest example, allowing users to scale their search application.
Elastic is committed to providing scalable, price effective infrastructure to support enterprise grade search experiences. Customers can depend on us for reliable and easy to maintain infrastructure and cost levers like vector compression, so you benefit from the lowest possible total cost of ownership for building search experiences powered by AI.
Related Content

January 28, 2026
Apache Lucene 2025 wrap-up
2025 was a stellar year for Apache Lucene; here are our highlights.

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.
January 20, 2026
Context engineering vs. prompt engineering
Learn how context engineering and prompt engineering differ and why mastering both is essential for building production AI agents and RAG systems.
January 2, 2026
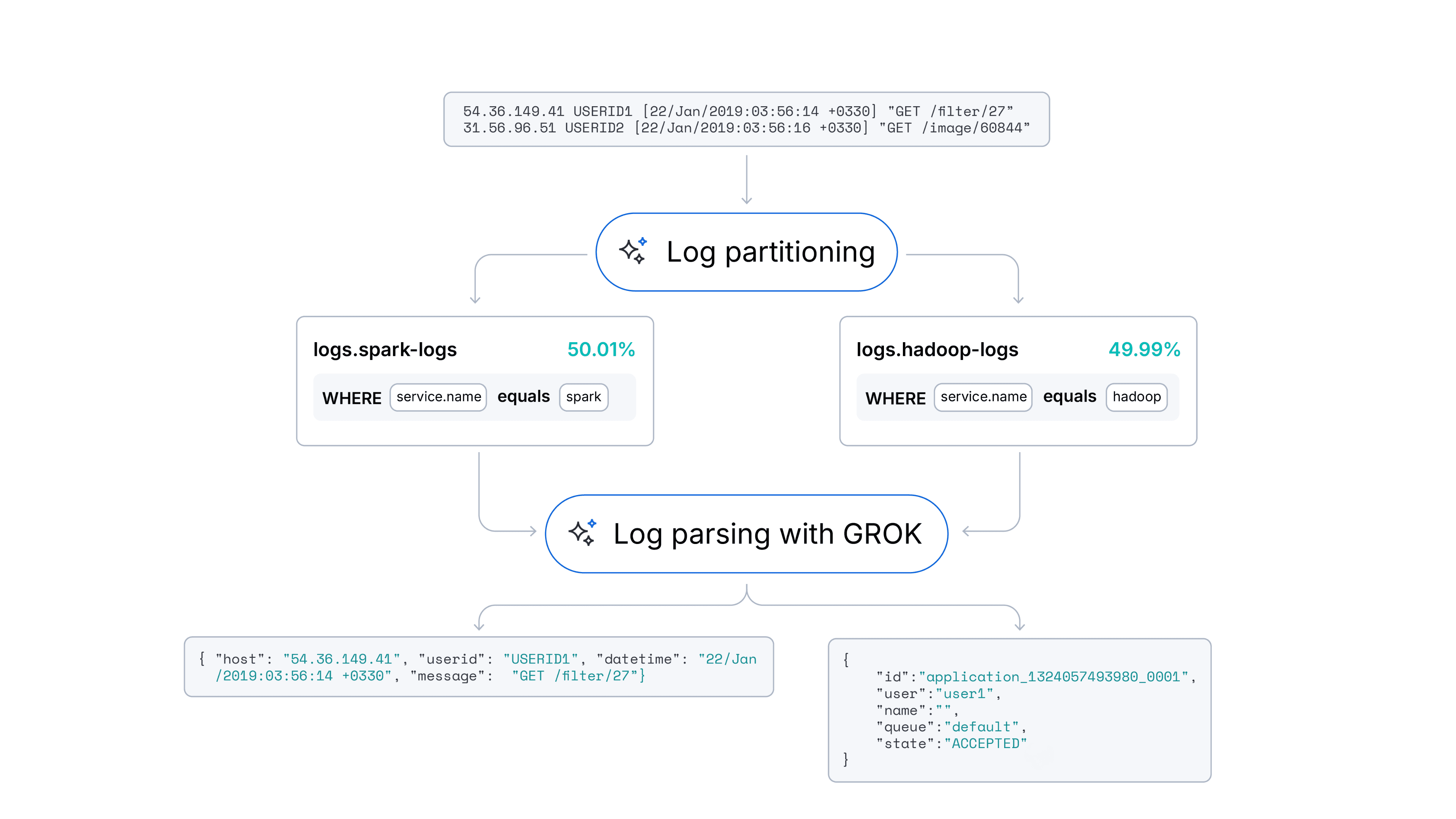
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.
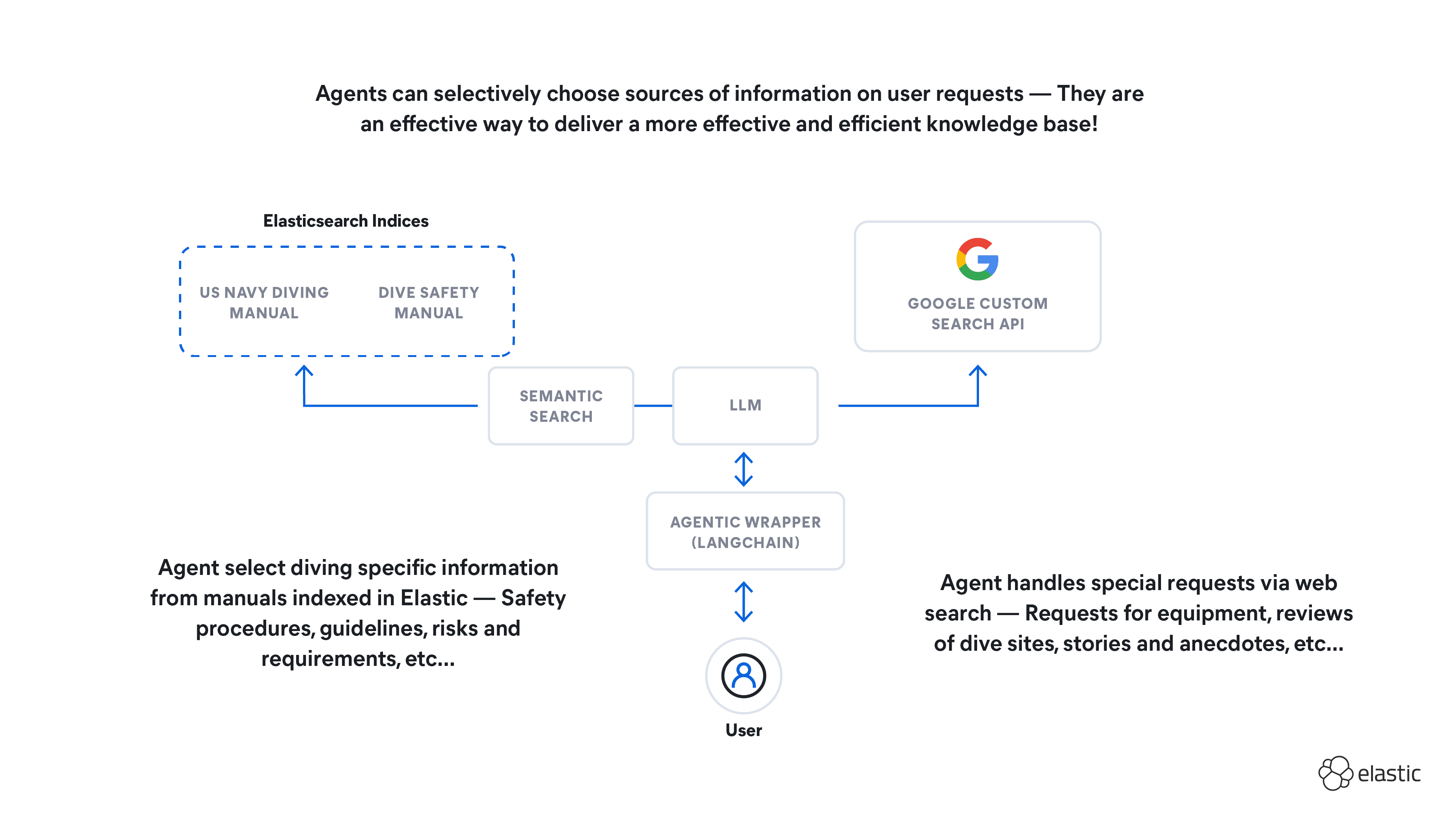
December 31, 2025
How to build an agent knowledge base with LangChain and Elasticsearch
Learn how to build an agent knowledge base and test its ability to query sources of information based on context, use WebSearch for out-of-scope queries, and refine recommendations based on user intention.