From vector search to powerful REST APIs, Elasticsearch offers developers the most extensive search toolkit. Dive into sample notebooks on GitHub to try something new. You can also start your free trial or run Elasticsearch locally today.
Red Hat and Elastic have collaborated to enable integration for the Elasticsearch vector database on Red Hat OpenShift AI. Red Hat OpenShift users can implement Elasticsearch for vector search and Retrieval-Augmented Generation (RAG) applications via the Red Hat Ecosystem Catalog.
Elastic Cloud on Kubernetes (ECK) is a certified offering on Red Hat OpenShift. Elastic is an IBM partner, and IBM Watsonx Assistant and Watsonx Discovery use Elastic vector search for question-answering and retrieval augmentation use cases.
With this collaboration, Elasticsearch users can benefit from Red Hat OpenShift AI, a flexible, scalable MLOps platform for building, training, testing, and serving models for AI-enabled applications.
Elasticsearch vector database for generative AI and RAG apps
Elasticsearch Relevance Engine (ESRE) is a comprehensive suite of developer tools for building generative AI and RAG applications. ESRE incorporates a vector database that stores embeddings for text, image, and video data. ESRE’s native hybrid search can effectively combine results containing text, vectors, and geospatial data, with filtering, aggregations, and document-level security.
With ESRE, developers can implement vector search and semantic search, including k-nearest neighbors (kNN) and approximate nearest neighbor (ANN) search, along with support for both built-in and third-party natural language processing (NLP) models. ESRE also seamlessly integrates with key third-party ecosystem products from providers such as Cohere, LangChain, and LlamaIndex. Elasticsearch can be self-managed or deployed with Elastic Cloud.
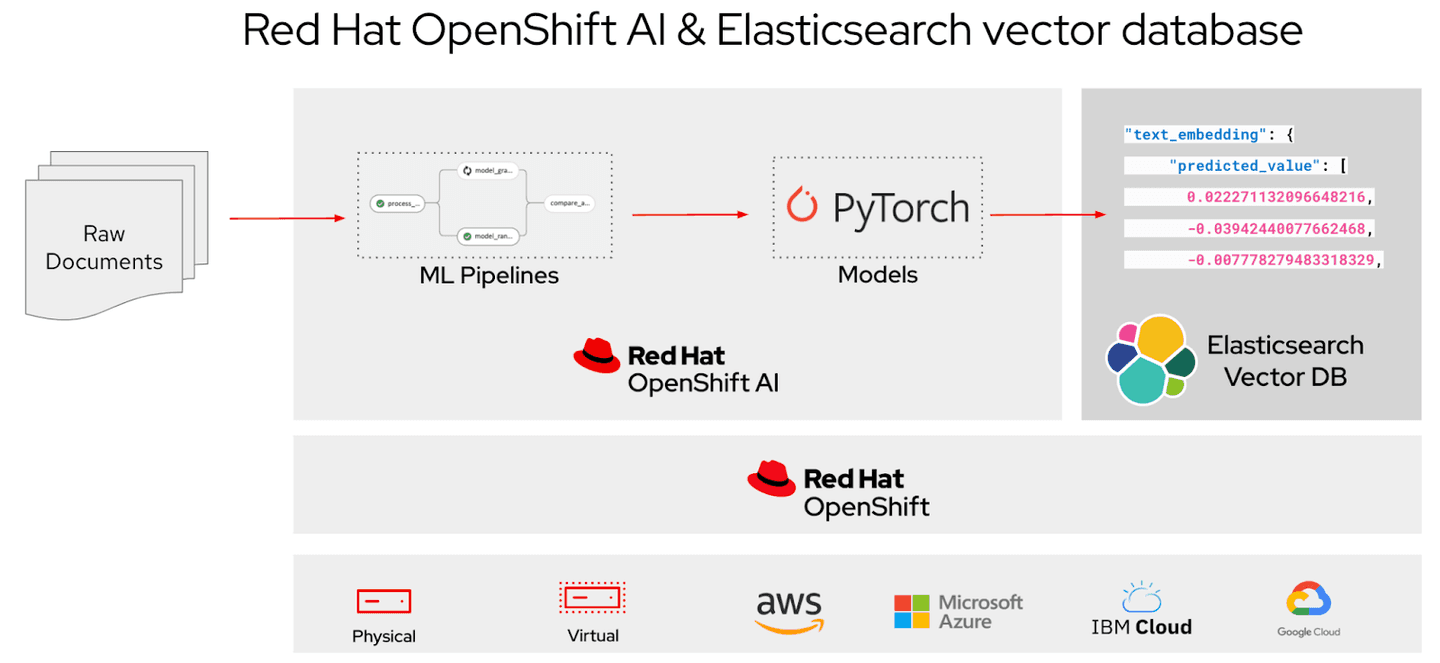
As part of this collaboration, users are now able to leverage ESRE capabilities by downloading Elasticsearch directly from the Red Hat Ecosystem Catalog.
What is Red Hat OpenShift AI for generative AI apps
Red Hat OpenShift AI is a hybrid MLOps platform that brings IT, data science, and app dev teams together. Designed to simplify Generative AI application development and deployment, it provides a comprehensive infrastructure stack tailored for distributed workloads. This includes training, optimizing, fine-tuning, and deploying foundational and predictive AI models. Collaborating with model builders helps provide access to a variety of pre-built models. Developers and data scientists can work together on the same platform, greatly enhancing collaboration. The platform facilitates end-to-end AI lifecycle management—from model development and training to deployment, serving, and continuous monitoring.
- Model development: Conduct exploratory data science in JupyterLab with access to core AI / ML libraries and frameworks, including TensorFlow and PyTorch using our notebook images or your own.
- Model serving & monitoring: Deploy models across on-premise or any cloud, either in a fully managed or self-managed Red Hat OpenShift footprint and centrally monitor their performance.
- Lifecycle Management: Create repeatable data science pipelines for model training and validation and integrate them with DevOps pipelines for the delivery of models across your enterprise.
- Increased capabilities and collaboration: Create projects and share them across teams. Combine Red Hat components, open-source software, and ISV-certified software.
Get started with Red Hat and Elasticsearch
To get started, just follow the installation instructions provided in the Red Hat Ecosystem Catalog, and start building your next generative AI application with RAG!
Visit Elasticsearch Labs for articles and sample notebooks on vector search, RAG, and more.
Related Content

January 28, 2026
Apache Lucene 2025 wrap-up
2025 was a stellar year for Apache Lucene; here are our highlights.

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.
January 20, 2026
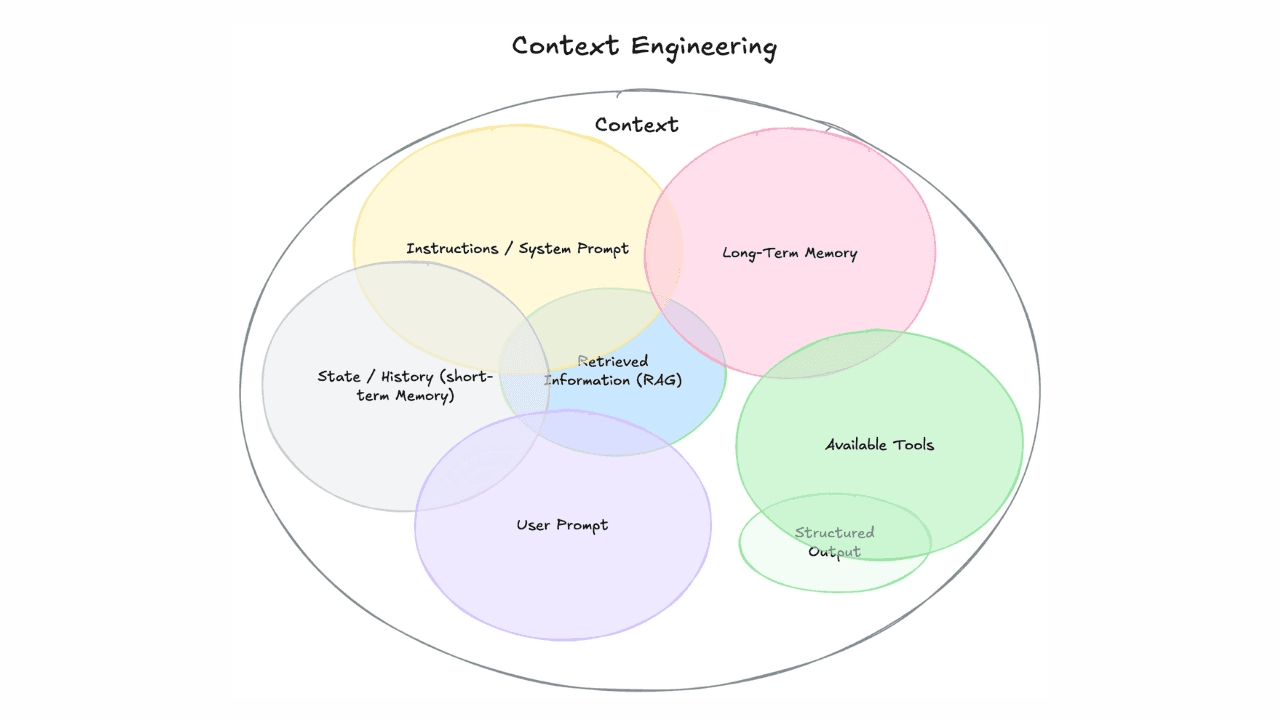
Context engineering vs. prompt engineering
Learn how context engineering and prompt engineering differ and why mastering both is essential for building production AI agents and RAG systems.
January 2, 2026
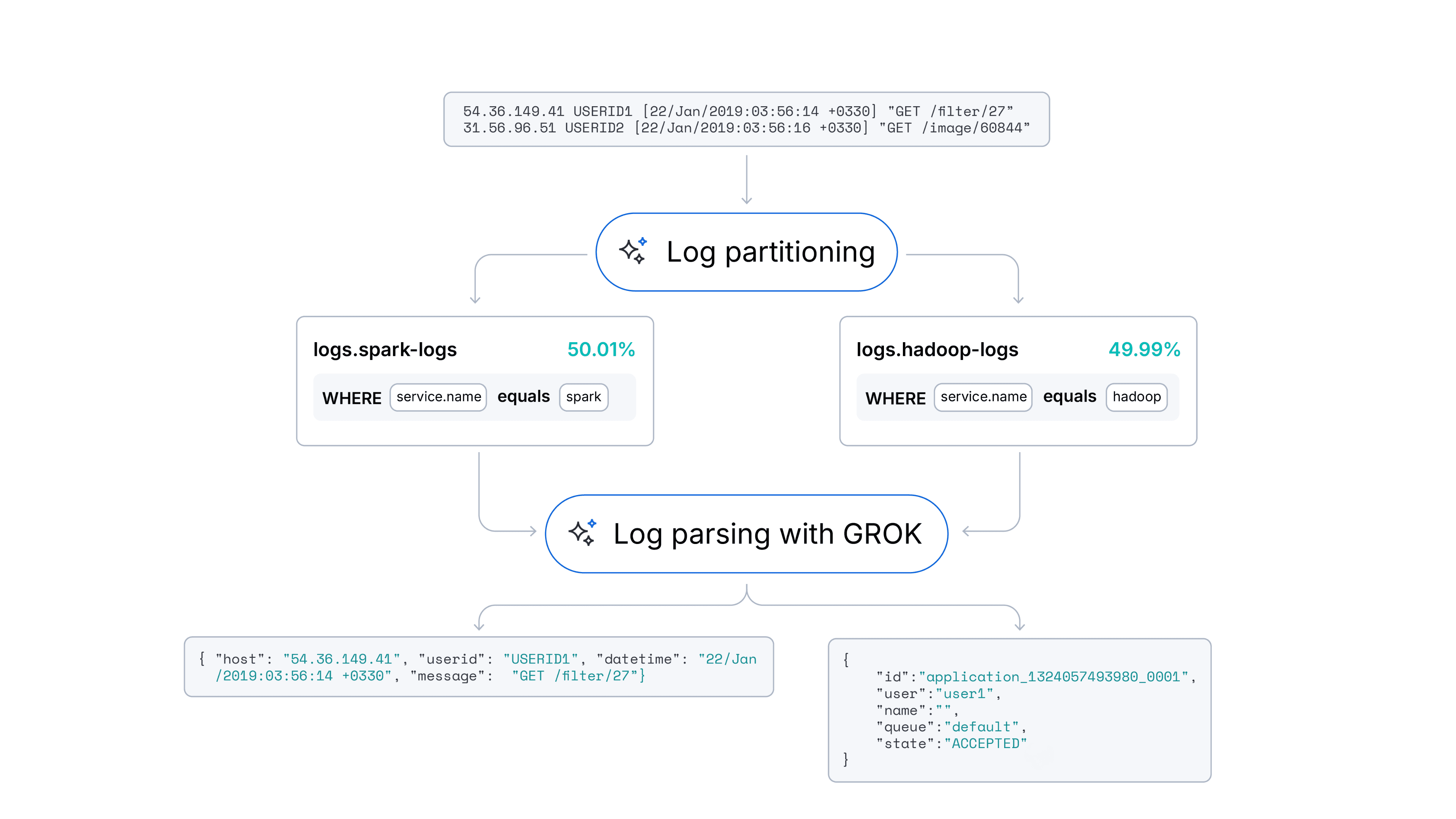
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.
December 31, 2025
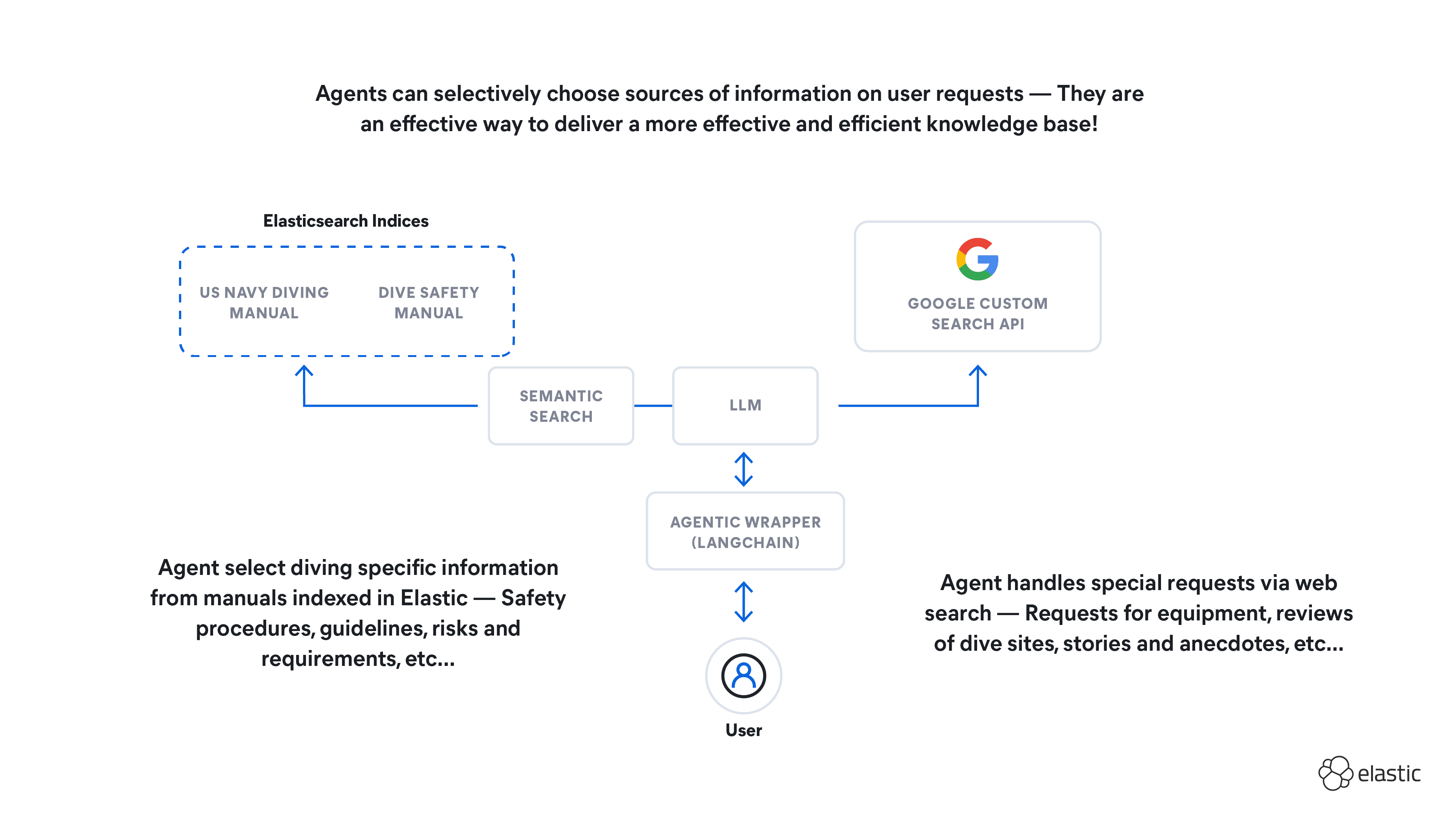
How to build an agent knowledge base with LangChain and Elasticsearch
Learn how to build an agent knowledge base and test its ability to query sources of information based on context, use WebSearch for out-of-scope queries, and refine recommendations based on user intention.