Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.

This blog will walk through implementing RAG using two approaches.
- Elastic, Llamaindex, Llama 3 (8B) version running locally using Ollama.
- Elastic, Langchain, ELSER v2, Llama 3 (8B) version running locally using Ollama.
The notebooks are available at this GitHub location.
Before we get started, let's take a quick dive into Llama 3.
Llama 3 overview
Llama 3 is an open source large language model recently launched by Meta. This is a successor to Llama 2 and based on published metrics, is a significant improvement. It has good evaluation metrics, when compared to some of the recently published models such as Gemma 7B Instruct, Mistral 7B Instruct, etc. The model has two variants, which are the 8 billion and 70 billion parameter. An interesting thing to note is that at the time of writing this blog, Meta was still in the process of training 400B+ variant of Llama 3.
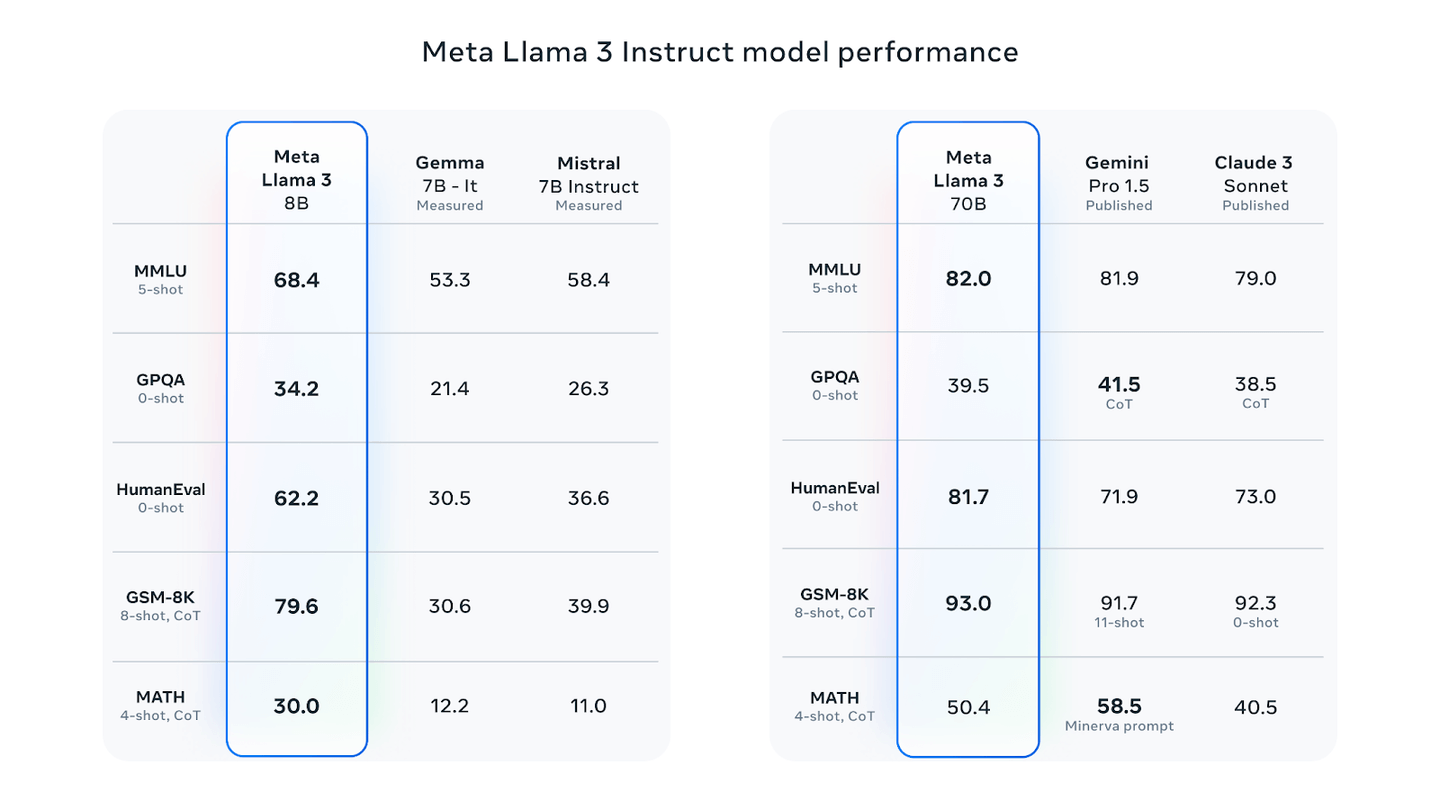
Meta Llama 3 Instruct Model Performance. (from https://ai.meta.com/blog/meta-llama-3/)
The above figure shows data on Llama3 performance across different datasets as compared to other models. In order to be optimized for performance for real world scenarios, Llama3 was also evaluated on a high quality human evaluation set.
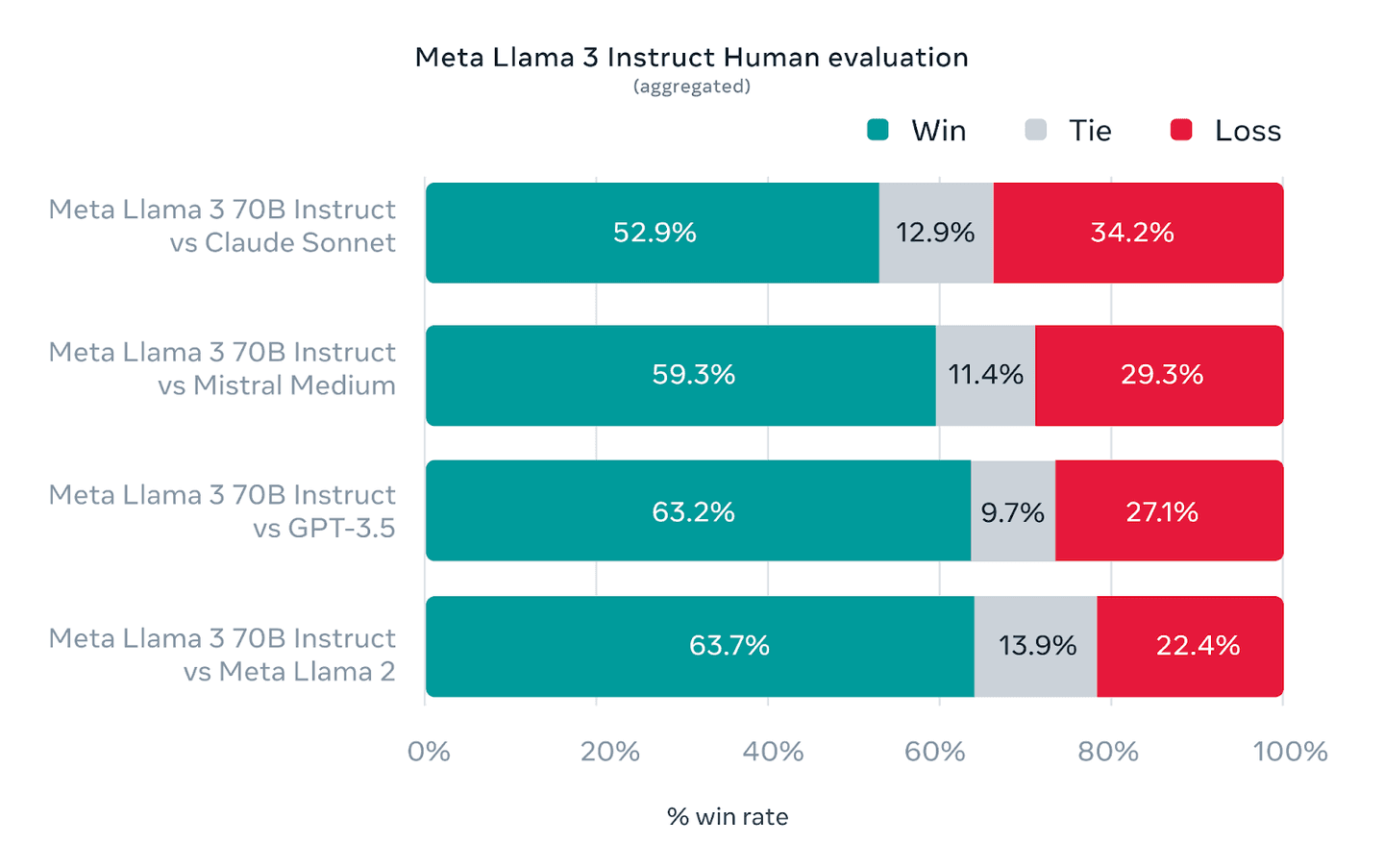
Aggregated results of Human Evaluations across multiple categories and prompts (from https://ai.meta.com/blog/meta-llama-3/)
How to build RAG with Llama 3 open-source and Elastic
Dataset
For the dataset, we will use a fictional organization policy document in json format, available at this location.
Configure Ollama and Llama3
As we are using the Llama 3 8B parameter size model, we will be running that using Ollama. Follow the steps below to install Ollama.
- Browse to the URL https://ollama.com/download to download the Ollama installer based on your platform.
Note: The Windows version is in preview at the moment.
- Follow the instructions to install and run Ollama for your OS.
- Once installed, follow the commands below to download the Llama3 model.
This should take some time depending upon your network bandwidth. Once the run completes, you should end with the interface below.
To test Llama3, run the following command from a new terminal or enter the text at the prompt itself.
At the prompt, the output looks like below.
We now have Llama3 running locally using Ollama.
Elasticsearch setup
We will use Elastic cloud setup for this. Please follow the instructions here. Once successfully deployed, note the API Key and the Cloud ID, we will require them as part of our setup.
Application setup
There are two notebooks, one for RAG implemented using Llamaindex and Llama3, the other one with Langchain, ELSER v2 and Llama3. In the first notebook, we use Llama3 as a local LLM as well as provide embeddings. For the second notebook, we use ELSER v2 for the embeddings and Llama3 as the local LLM.
Method 1: Elastic, Llamaindex, Llama 3 (8B) version running locally using Ollama.
Step 1 : Install required dependencies
The above section installs the required llamaindex packages.
Step 2: Import required dependencies
We start with importing the required packages and classes for the app.
We start with providing a prompt to the user to capture the Cloud ID and API Key values.
If you are not familiar with obtaining the Cloud ID and API Key, please follow the links in the code snippet above to guide you with the process.
Step 3: document processing
We start with downloading the json document and building out Document objects with the payload.
We now define the Elasticsearch vector store (ElasticsearchStore), the embedding created using Llama3 and a pipeline to help process the payload constructed above and ingest into Elasticsearch.
The ingestion pipeline allows us to compose pipelines using different components, one of which allows us to generate embeddings using Llama3.
ElasticsearchStore is defined with the name of the index to be created, the vector field and the content field. And this index is created when we run the pipeline.
The index mapping created is as below:

The pipeline is executed using the step below. Once this pipeline run completes, the index workplace_index is now available for querying. Do note that the vector field content_vector is created as a dense vector with dimension 4096. The dimension size comes from the size of the embeddings generated from Llama3.
Step 4: LLM configuration
We now setup Llamaindex to use the Llama3 as the LLM. This as we covered before is done with the help of Ollama.
Step 5: Semantic search
We now configure Elasticsearch as the vector store for the Llamaindex query engine. The query engine is then used to answer your questions with contextually relevant data from Elasticsearch.
The response I received with Llama3 as the LLM and Elasticsearch as the Vector database is below.
This concludes the RAG setup based on using Llama3 as a local LLM and to generate embeddings.
Let's now move to the second method, which uses Llama3 as a local LLM, but we use Elastic’s ELSER v2 to generate embeddings and for semantic search.
Method 2: Elastic, Langchain, ELSER v2, Llama 3 (8B) version running locally using Ollama.
Step 1: Install required dependencies
The above section installs the required langchain packages.
Step 2: Import required dependencies
We start with importing the required packages and classes for the app. This step is similar to Step 2 in Method 1 above.
Next, provide a prompt to the user to capture the Cloud ID and API Key values.
Step 3: Document processing
Next, we move to downloading the json document and building the payload.
This step differs from the Method 1 approach, from how we use the LlamaIndex provided pipeline to process the document. Here we use the RecursiveCharacterTextSplitter to generate the chunks.
We now define the Elasticsearch vector store ElasticsearchStore.
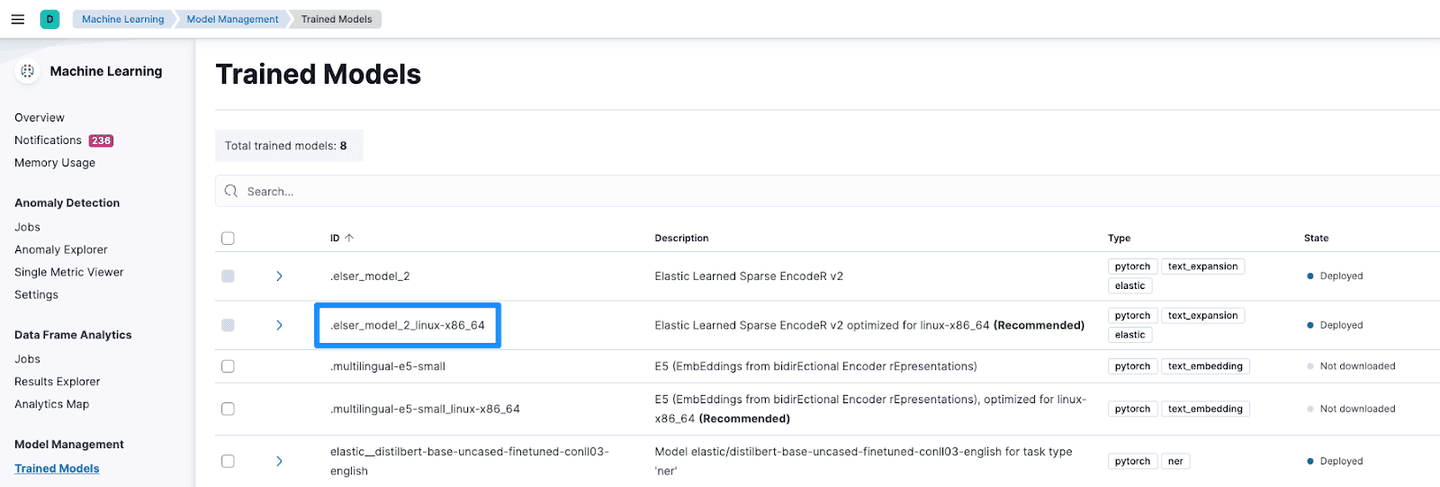
The vector store is defined with the index to be created and the model to be used for embedding and retrieval. You can retrieve the model_id by navigating to Trained Models under Machine Learning.
This also results in the creation of an ingest pipeline in Elastic, which generates and stores the embeddings as the documents are ingested into Elastic.
We now add the documents processed above.
Step 4: LLM configuration
We set up the LLM to be used with the following. This is again different from method 1, where we used Llama3 for embeddings too.
Step 5: Semantic search
The necessary building blocks are all in place now. We tie them up together to perform semantic search using ELSER v2 and Llama3 as the LLM. Essentially, Elasticsearch ELSER v2 provides the contextually relevant response to the users question using its semantic search capabilities. The user's question is then enriched with the response from ELSER and structured using a template. This is then processed with Llama3 to generate relevant responses.
The response with Llama3 as the LLM and ELSER v2 for semantic search is as below:
This concludes the RAG setup based on using Llama3 as a local LLM and ELSER v2 for semantic search.
Conclusion
In this blog we looked at two approaches to RAG with Llama3 and Elastic. We explored Llama3 as an LLM and to generate embeddings. Next we used Llama3 as the local LLM and ELSER for embeddings and semantic search. We utilized two different frameworks, LlamaIndex and Langchain. You could implement the two methods using either of these frameworks. The notebooks were tested with the Llama3 8B parameter version. Both the notebooks are available at this GitHub location.
Frequently Asked Questions
What is Llama 3?
Llama 3 is an open-source large language model recently launched by Meta. It's a successor to Llama 2.
Related Content

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.
January 20, 2026
Context engineering vs. prompt engineering
Learn how context engineering and prompt engineering differ and why mastering both is essential for building production AI agents and RAG systems.
January 2, 2026
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.
December 31, 2025
How to build an agent knowledge base with LangChain and Elasticsearch
Learn how to build an agent knowledge base and test its ability to query sources of information based on context, use WebSearch for out-of-scope queries, and refine recommendations based on user intention.

December 29, 2025
Creating reliable agents with structured outputs in Elasticsearch
Explore what structured outputs are and how to leverage them in Elasticsearch to ground agents in the most relevant context for data contracts.