Free yourself from operations with Elastic Cloud Serverless. Scale automatically, handle load spikes, and focus on building—start a 14-day free trial to test it out yourself!
You can follow these guides to build an AI-Powered search experience or search across business systems and software.
Sizing an Elasticsearch cluster correctly is not easy. The optimal size of the cluster depends on the workload that the cluster is experiencing, which may change over time. Autoscaling adapts the cluster size to the workload automatically without human intervention. It avoids over-provisioning resources for the cluster only to accommodate peak usage and it also prevents degrading cluster performance in case of under-provisioning.
We rely on this mechanism to free users of our Elastic Cloud Serverless offering from having to make sizing decisions for the indexing tier. Ingest autoscaling requires continuously estimating the resources required to handle the incoming workload, and provisioning and de-provisioning these resources in a timely manner.
In this blog post we explore ingest autoscaling in Elasticsearch, covering the following:
- How ingest autoscaling works in Elasticsearch
- Which metrics we use to quantify the indexing workload the cluster experiences in order to estimate resources required to handle that workload
- How these metrics drive the autoscaling decisions.
Ingest autoscaling overview
Ingest autoscaling in Elasticsearch is driven by a set of metrics that is exposed by Elasticsearch itself. These metrics reflect the ingestion load and the memory requirement of the indexing tier. Elasticsearch provides an autoscaling metrics API that serves these metrics which allows an external component to monitor these metrics and make decisions whether the cluster size needs to change (see Figure 1).
In the Elastic Cloud Serverless service, there is an autoscaler component which is a Kubernetes Controller. The autoscaler polls the Elasticsearch autoscaling metrics API periodically and calculates the desired cluster size based on these metrics. If the desired cluster size is different from the current one, the autoscaler changes the cluster size to consolidate the available resources in the cluster towards the desired resources. This change is both in terms of the number of Elasticsearch nodes in the cluster and the CPU, memory and disk available to each node.
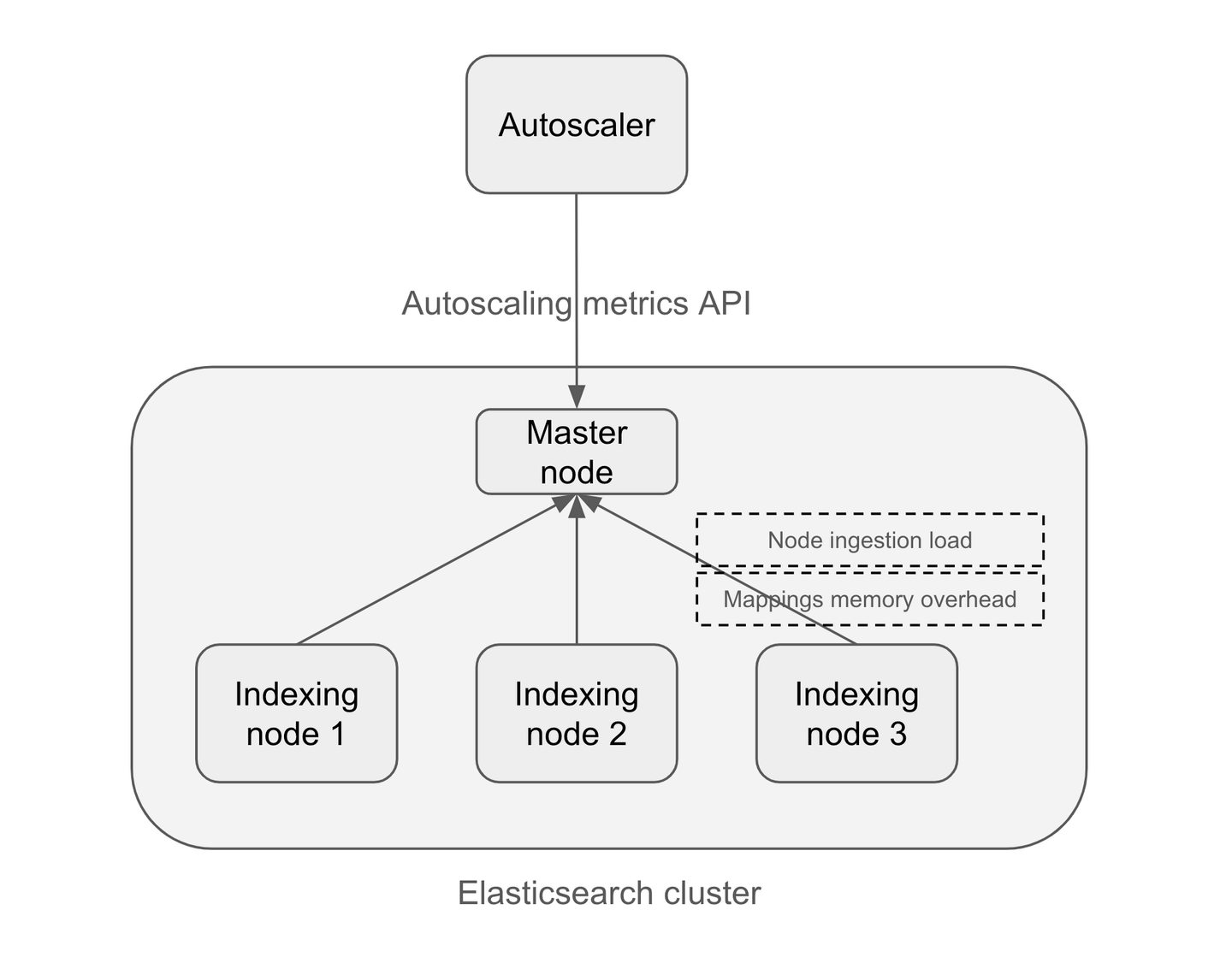
Figure 1: ingestion autoscaling overview
An important consideration for ingest autoscaling is that when the cluster receives a spike in the indexing load the autoscaling process can take some time until it effectively adapts the cluster size. While we try to keep this reaction time as low as possible, it cannot be instantaneous. Therefore, while the cluster is scaling up, the Elasticsearch cluster should be able to temporarily push back on the load it receives if the increased load is otherwise going to cause cluster instability issues. The increase in the indexing load can manifest itself in the cluster requiring more resources, i.e., CPU, memory or disk. Elasticsearch has protection mechanisms that allows nodes to push back on the indexing load if any of these resources becomes a bottleneck.
To handle indexing requests Elasticsearch uses dedicated thread pools sized based on the number of cores available to the node. If the increased indexing load results in CPU or other resources becoming a bottleneck, incoming indexing requests are queued. The maximum size of this queue is limited and any request arriving at the node when the queue is full will be rejected with a 429 HTTP code.
Elasticsearch also keeps track of the required memory to address ongoing indexing requests and rejects incoming requests (with a 429) if the indexing buffer grows beyond 10% of the available heap memory. This limits the memory used for indexing and ensures the node will not go out of memory.
The Elastic Cloud Serverless offering relies on the object store as the main storage for indexed data. The local disk on the nodes are used temporarily to hold indexed data. Periodically, Elasticsearch uploads the indexed data to the object store which allows freeing up the local disk space as we rely on the object store for durability of the indexed document. Nonetheless, under high indexing load, it is possible for the node to run out of disk space before the periodic upload task gets a chance to run and free up the local disk space. To handle these cases, Elasticsearch monitors the available local disk space and if necessary throttles the indexing activity while it attempts to free up space by enforcing an upload to the object store rather than waiting for the periodic upload to take place. Note that this throttling in turn results in queueing of the incoming indexing requests.
These protection mechanisms allow an Elasticsearch cluster to temporarily reject requests and provide the client with a response that indicates that the cluster is overloaded while the cluster tries to scale up. This push-back signal from Elasticsearch provides the client with a chance to react by reducing the load if possible or retrying the request which should eventually succeed if retried when the cluster is scaled up.
Metrics
The two metrics that are used for ingest autoscaling in Elasticsearch are ingestion load and memory.
Ingestion load
Ingestion load represents the number of threads that is needed to cope with the current indexing load. The autoscaling metrics API exposes a list of ingestion load values, one for each indexing node. Note that as the write thread pools (which handle indexing requests) are sized based on the number of CPU cores on the node, this essentially determines the total number of cores that is needed in the cluster to handle the indexing workload.
The ingestion load on each indexing node consists of two components:
- Thread pool utilization: the average number of threads in the write thread pool processing indexing requests during that sampling period.
- Queued ingestion load: the estimated number of threads needed to handle queued write requests.
The ingestion load of each indexing node is calculated as the sum of these two values for all the three write thread pools. The total ingestion load of the Elasticsearch cluster is the sum of the ingestion load of the individual nodes.
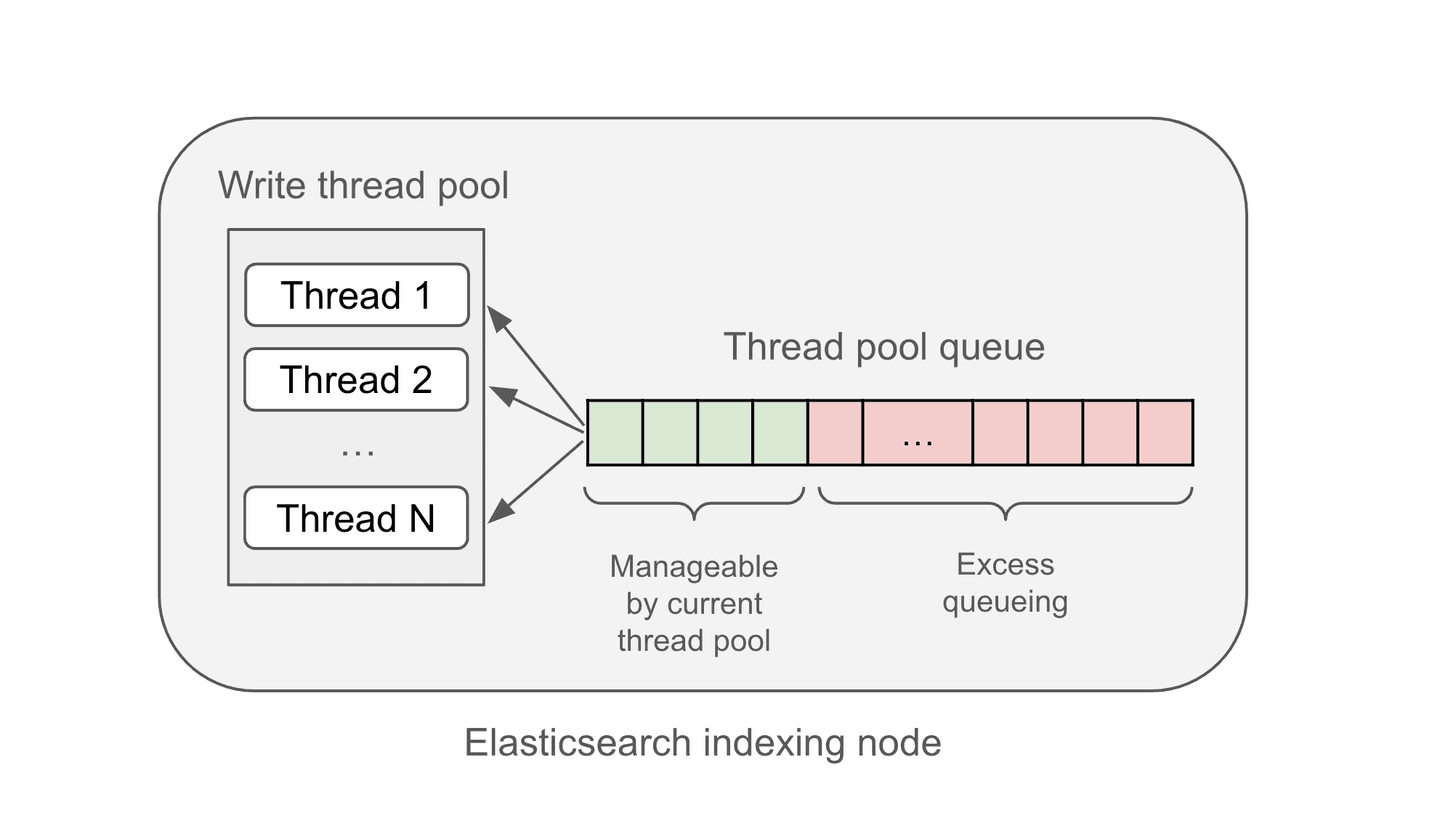
Figure 2: ingestion load components
The thread pool utilization is an exponentially weighted moving average (EWMA) of the number of busy threads in the thread pool, sampled every second. The EWMA of the sampled thread pool utilization values is configured such that the sampled values of the past 10 seconds have the most effect on the thread pool utilization component of the ingestion load and samples older than 60 seconds have very negligible impact.
To estimate the resources required to handle the queued indexing requests in the thread pool, we need to have an estimate for how long each queued task can take to execute. To achieve this, each thread pool also provides an EWMA of the request execution time. The request execution time for an indexing request is the (wall-clock) time taken for the request to finish once it is out of the queue and a worker thread starts executing it. As some queueing is acceptable and should be manageable by the thread pool, we try to estimate the resources needed to handle the excess queueing. We consider up to 30s worth of tasks in the queue manageable by the existing number of workers and account for an extra thread proportional to this value. For example, if the average task execution time is 200ms, we estimate that each thread is able to handle 150 indexing requests within 30s, and therefore account for one extra thread for each 150 queued items.
Note that since the indexing nodes rely on pushing indexed data into the object store periodically, we do not need to scale the indexing tier based on the total size of the indexed data. However, the disk IO requirements of the indexing workload needs to be considered for the autoscaling decisions. The ingestion load represents both CPU requirements of the indexing nodes as well as disk IO since both CPU and IO work is done by the write thread pool workers and we rely on the wall clock time to estimate the required time to handle the queued requests.
Each indexing node calculates its ingestion load and publishes this value to the master node periodically. The master node serves the per node ingestion load values via the autoscaling metrics API to the autoscaler.
Memory
The memory metrics exposed by the autoscaling metrics API are node memory and tier memory. The node memory represents the minimum memory requirement for each indexing node in the cluster. The tier memory metric represents the minimum total memory that should be available in the indexing tier. Note that these values only indicate the minimum to ensure that each node is able to handle the basic indexing workload and hold the cluster and indices metadata, while ensuring that the tier includes enough nodes to accommodate all index shards.
Node memory must have a minimum of 500MB to be able to handle indexing workloads, as well as a fixed amount of memory per each index. This ensures all nodes can hold metadata for the cluster, which includes metadata for every index. Tier memory is determined by accounting for the memory overhead of the field mappings of the indices and the amount of memory needed for each open shard allocated on a node in the cluster. Currently, the per-shard memory requirement uses a fixed estimate of 6MB. We plan to refine this value.
The estimate for the memory requirements for the mappings of each index is calculated by one of the data nodes that hosts a shard of the index. The calculated estimates are sent to the master node. Whenever there is a mapping change this estimate is updated and published to the master node again. The master node serves the node and total memory metrics based on these information via the autoscaling metrics API to the autoscaler.
Scaling the cluster
The autoscaler is responsible for monitoring the Elasticsearch cluster via the exposed metrics, calculating the desirable cluster size to adapt to the indexing workload, and updating the deployment accordingly. This is done by calculating the total required CPU and memory resources based on the ingestion load and memory metrics. The sum of all the ingestion load per node values determines the total number of CPU cores needed for the indexing tier.
The calculated CPU requirement and the provided minimum node and tier memory resources are mapped to a predetermined set of cluster sizes. Each cluster size determines the number of nodes and the CPU, memory and disk size of each node. All nodes within a certain cluster size have the same hardware specification. There is a fixed ratio between CPU, memory and disk, thus always scaling all 3 resources linearly. The existing cluster sizes for the indexing tier are based on node sizes starting from 4GB/2vCPU/100GB disk to 64GB/32vCPU/1600GB disk. Once the Elasticsearch cluster scales up to the largest node size (64GB memory), any further scale-up adds new 64GB nodes, allowing a cluster to scale up to 32 nodes of 64GB. Note that this is not a hard upper bound on the number of Elasticsearch nodes in the cluster and can be increased if necessary.
Every 5 seconds the autoscaler polls metrics from the master node, calculates the desirable cluster size and if it is different from the current cluster size, it updates the Elasticsearch Kubernetes Deployment accordingly. Note that the actual reconciliation of the deployment towards the desired cluster size and adding and removing the Elasticsearch nodes to achieve this is done by Kubernetes. In order to avoid very short-lived changes to the cluster size, we account for a 10% headroom when calculating the desired cluster size during a scale down and a scale down takes effect only if all desired cluster size calculations within the past 15 minute have indicated a scale-down.
Currently, the time that it takes for an increase in the metrics to lead to the first Elasticsearch node being added to the cluster and ready to process indexing load is under 1 minute.
Conclusion
In this blog post, we explained how ingest autoscaling works in Elasticsearch, the different components involved, and the metrics used to quantify the resources needed to handle the indexing workload. We believe that such an autoscaling mechanism is crucial to reduce the operational overhead of an Elasticsearch cluster for the users by automatically increasing the available resources in the cluster when necessary. Furthermore, it leads to cost reduction by scaling down the cluster when the available resources in the cluster are not required anymore.
Related Content
January 22, 2026
Agent Builder now GA: Ship context-driven agents in minutes
Agent Builder is now GA. Learn how it allows you to quickly develop context-driven AI agents.

January 14, 2026
Higher throughput and lower latency: Elastic Cloud Serverless on AWS gets a significant performance boost
We've upgraded the AWS infrastructure for Elasticsearch Serverless to newer, faster hardware. Learn how this massive performance boost delivers faster queries, better scaling, and lower costs.

March 4, 2025
The AI Agent to manage Elasticsearch Serverless projects
A natural language-powered AI agent that effortlessly manages Elasticsearch Serverless projects—enabling project creation, deletion, and status checks.

December 10, 2024
Autosharding of data streams in Elasticsearch Serverless
In Elastic Cloud Serverless we spare our users from the need to fiddle with sharding by automatically configuring the optimal number of shards for data streams based on the indexing load.

December 2, 2024
Elasticsearch Serverless is now generally available
Elasticsearch Serverless, built on a new stateless architecture, is generally available. It’s fully managed so you can get projects started quickly without operations or upgrades, and you can access the latest vector search and generative AI capabilities.