From vector search to powerful REST APIs, Elasticsearch offers developers the most extensive search toolkit. Dive into sample notebooks on GitHub to try something new. You can also start your free trial or run Elasticsearch locally today.
We're happy to announce that Elasticsearch now supports Azure OpenAI embeddings in our open inference API, enabling developers to store generated embeddings into our highly scalable and performant vector database.
This new functionality further solidifies our commitment to not only working with Microsoft and the Azure platform, but also toward our commitment to offering our customers more flexibility with their AI solutions.
Ongoing Investment in AI at Elastic
This is the latest in a series of additional features and integrations on AI enablement for Elasticsearch following on from:
- Elasticsearch open inference API adds Azure AI Studio support
- Elasticsearch open inference API adds support for Azure OpenAI chat completions
- Elasticsearch open inference API adds support for OpenAI chat completions
- Elasticsearch open inference API adds support for Cohere Embeddings
- Introducing Elasticsearch vector database to Azure OpenAI Service On Your Data (preview)
The new inference embeddings service provider for Azure OpenAI is already available in our stateless offering on Elastic Cloud, and will be soon available to everyone in an upcoming Elastic release.
Using Azure OpenAI Embeddings with the Elasticsearch Inference API
Deploying an Azure OpenAI Embeddings Model
To get started, you will need a Microsoft Azure Subscription as well as access to Azure OpenAI service. Once you have registered and have access, you will need to create a resource in your Azure Portal, and then deploy an embedding model to Azure OpenAI Studio. To do this, if you do not already have an Azure OpenAI resource in your Azure Portal, create a new one from the “Azure OpenAI” type which can be found in the Azure Marketplace, and take note of your resource name as you will need this later. When you create your resource, the region you choose may impact what models you have access to. See the Azure OpenAI deployment model availability table for additional details.

Once you have your resource, you will also need one of your API keys which can be found in the “Keys and Endpoint” information from the Azure Portal's left side navigation:
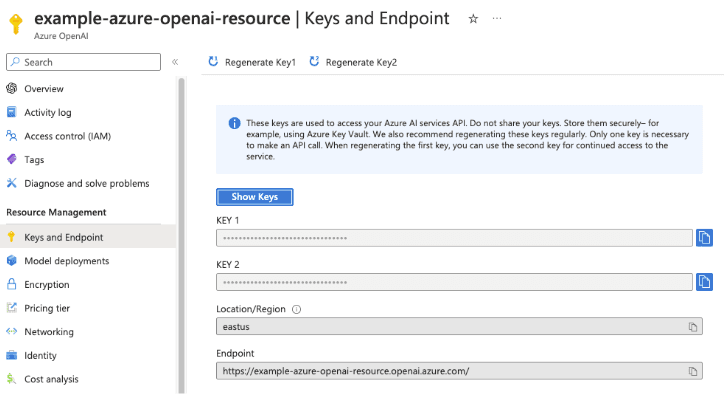
Now, to deploy your Azure OpenAI Embedding model, go into your Azure OpenAI Studio's console and create your deployment using an OpenAI Embeddings model such as text-embedding-ada-002. Once your deployment is created, you should see the deployment overview. Also take note of the deployment name, in the example below it is “example-embeddings-model”.

Using your deployed Azure OpenAI embeddings model with the Elasticsearch Inference API
With an Azure OpenAI embeddings model deployed, we can now configure your Elasticsearch deployment's _inference API and create a pipeline to index embeddings vectors in your documents. Please refer to the Elastic Search Labs GitHub repository for more in-depth guides and interactive notebooks.
To perform these tasks, you can use the Kibana Dev Console, or any REST console of your choice.
First, configure your inference endpoint using the create inference model endpoint - we'll call this “example_model”:
For your inference endpoint, you will need your API key, your resource name, and the deployment id that you created above. For the “api_version”, you will want to use an available API version from the Azure OpenAI embeddings documentation - we suggest always using the latest version which is “2024-02-01” as of this writing. You can also optionally add a username in the task setting's “user” field which should be a unique identifier representing your end-user to help Azure OpenAI to monitor and detect abuse. If you do not want to do this, omit the entire “task_settings” object.
After running this command you should receive a 200 OK status indicating that the model is properly set up.
Using the perform inference endpoint, we can see an example of your inference endpoint at work:
The output from the above command should provide the embeddings vector for the input text:
Now that we know our inference endpoint works, we can create a pipeline that uses it:
This will create an ingestion pipeline named “azureopenai_embeddings” that will read the contents of the “name” field upon ingestion and apply the embeddings inference from our model to the “name_embedding” output field. You can then use this ingestion pipeline when documents are ingested (e.g. via the _bulk ingest endpoint), or when reindexing an index that is already populated.
This is currently available through the open inference API in our stateless offering on Elastic Cloud. It'll also be soon available to everyone in an upcoming versioned Elasticsearch release, with additional semantic text capabilites that will make this step even simpler to integrate into your existing workflows.
For an additional use case, you can walk through the semantic search with inference tutorial for how to perform ingestion and semantic search on a larger scale with Azure OpenAI and other services such as reranking or chat completions.
Plenty more on the horizon
This new extensibility is only one of many new features we are bringing to the AI table from Elastic. Bookmark Elastic Search Labs now to stay up to date! Ready to build RAG into your apps? Want to try different LLMs with a vector database? Check out our sample notebooks for LangChain, Cohere and more on Github, and join the Elasticsearch Engineer training starting soon!
Related Content

January 28, 2026
Apache Lucene 2025 wrap-up
2025 was a stellar year for Apache Lucene; here are our highlights.

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.
January 20, 2026
Context engineering vs. prompt engineering
Learn how context engineering and prompt engineering differ and why mastering both is essential for building production AI agents and RAG systems.
January 2, 2026
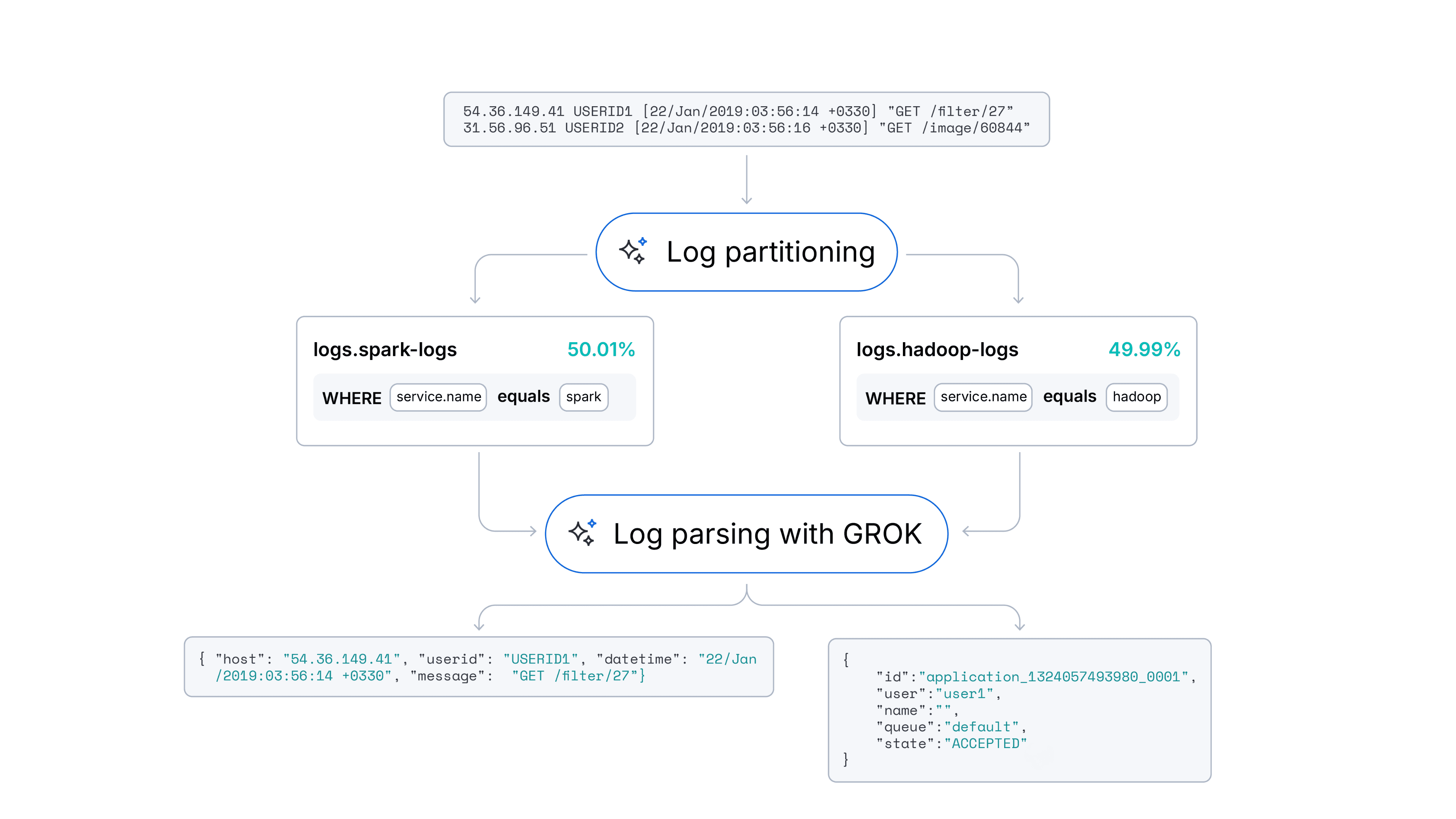
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.
December 31, 2025
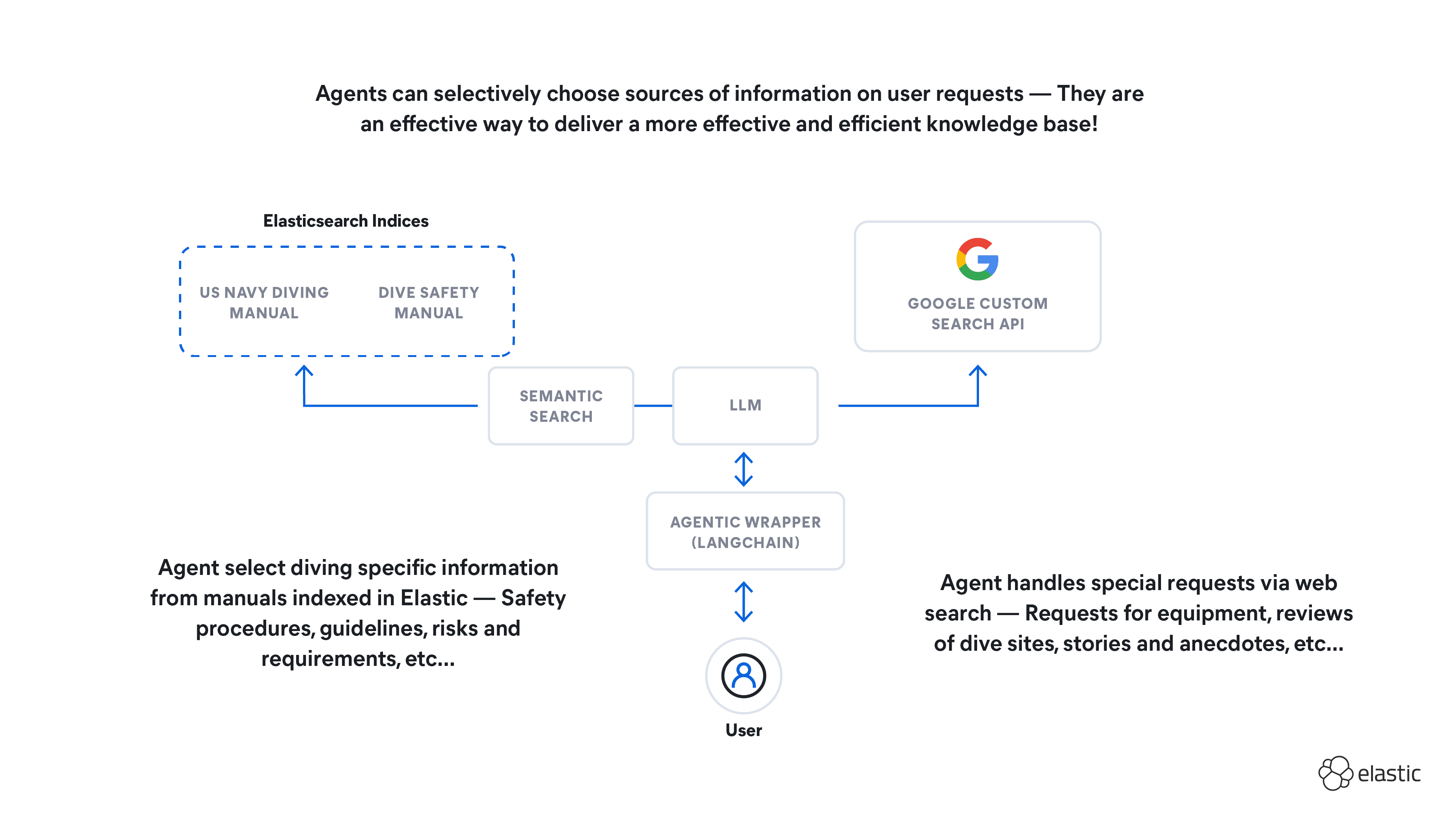
How to build an agent knowledge base with LangChain and Elasticsearch
Learn how to build an agent knowledge base and test its ability to query sources of information based on context, use WebSearch for out-of-scope queries, and refine recommendations based on user intention.