Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
The Elasticsearch open inference API enables developers to create inference endpoints and use machine learning models from leading providers. Models hosted on Amazon Bedrock are available via the Elasticsearch Open Inference API. Developers building RAG applications using the Elasticsearch vector database can store and use embeddings generated from models hosted on Amazon Bedrock (such as Amazon Titan, Anthropic Claude, Cohere Command R, and others). Bedrock integration with open inference API offers a consistent way of interacting with different AI models, such as text embeddings and chat completion, simplifying the development process with Elasticsearch.
- pick a model from Amazon Bedrock
- create and use an inference endpoint in Elasticsearch
- use the model as part of an inference pipeline
Using a base model in Amazon Bedrock
This walkthrough assumes you already have an AWS Account with access to Amazon Bedrock - a fully managed hosted models service that makes foundation models available through a unified API.
From Amazon Bedrock in AWS Console, make sure that you do have access to Amazon Titan Embeddings G1 - Text model. You can check that by going to Amazon Bedrock service in AWS Console and checking for _Model access. _If you don’t have access, you can request it through _Modify model access _from Amazon Bedrock service in AWS Console.
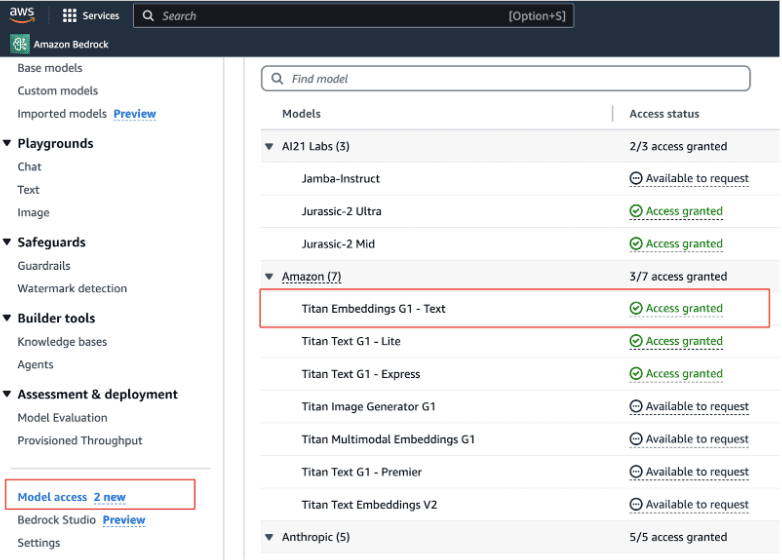
Amazon provides extensive IAM policies to control permissions and access to the models. From within IAM, you’ll also need to create a pair of access and secret keys that allow programmatic access to Amazon Bedrock for your Elasticsearch inference endpoint to communicate.
Creating an inference API endpoint in Elasticsearch
Once your model is deployed, we can create an endpoint for your inference task in Elasticsearch. For the examples below, we are using the Amazon Titan Text base model to perform inference for chat completion.
In Elasticsearch, create your endpoint by providing the service as “amazonbedrock”, and the service settings including your region, the provider, the model (either the base model ID, or if you’ve created a custom model, the ARN for it), and your access and secret keys to access Amazon Bedrock. In our example, as we’re using Amazon Titan Text, we’ll specify “amazontitan” as the provider, and “amazon.titan-text-premier-v1:0” as the model id.
When you send Elasticsearch the command, it should return back the created model to confirm that it was successful. Note that the API key will never be returned and is stored in Elasticsearch’s secure settings.
Adding a model for using text embeddings is just as easy. For reference, if we use the Amazon Titan Embeddings Text base model, we can create our inference model in Elasticsearch with the “text_embeddings” task type by providing the appropriate API key and target URL from that deployment’s overview page:
Let’s perform some inference
That’s all there is to setting up your model. Now that that’s out of the way, we can use the model. First, let’s test the model by asking it to provide some text given a simple prompt. To do this, we’ll call the _inference API with our input text:
And we should see Elasticsearch provide a response. Behind the scenes, Elasticsearch calls out to Amazon Bedrock with the input text and processes the results from the inference. In this case, we received the response:
We’ve tried to make it easy for the end user to not have to deal with all the technical details behind the scenes, but we can also control our inference a bit more by providing additional parameters to control the processing, such as sampling temperature and requesting the maximum number of tokens to be generated:
That was easy. What else can we do?
This becomes even more powerful when we are able to use our new model in other ways, such as adding additional text to a document when it’s used in an Elasticsearch ingestion pipeline. For example, the following pipeline definition will use our model, and anytime a document using this pipeline is ingested, any text in the field “question_field” will be sent through the inference API, and the response will be written to the “completed_text_answer” field in the document. This allows large batches of documents to be augmented.
Limitless possibilities
By harnessing the power of Amazon Bedrock models in your Elasticsearch inference pipelines, you can enhance your search experience’s natural language processing capabilities.
If you’re an AWS developer using Elasticsearch, there is more to look forward to. We recently added support for Amazon Bedrock to our Playground (blog), allowing developers to test and tune RAG workflows. In addition, the new semantic_text mapping lets you easily vectorize and chunk information.
In upcoming versions of Elasticsearch, users can take advantage of new field mapping types that simplify the process described in this blog even further, where designing an ingest pipeline would no longer be necessary. Also, as alluded to in our accelerated roadmap for semantic search the future will provide dramatically simplified support for inference tasks with Elasticsearch retrievers at query time.
These capabilities are available through the open inference API in our stateless offering on Elastic Cloud. They’ll also soon be available to everyone in an upcoming versioned Elasticsearch release.
Related Content

January 28, 2026
Apache Lucene 2025 wrap-up
2025 was a stellar year for Apache Lucene; here are our highlights.

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.
January 20, 2026
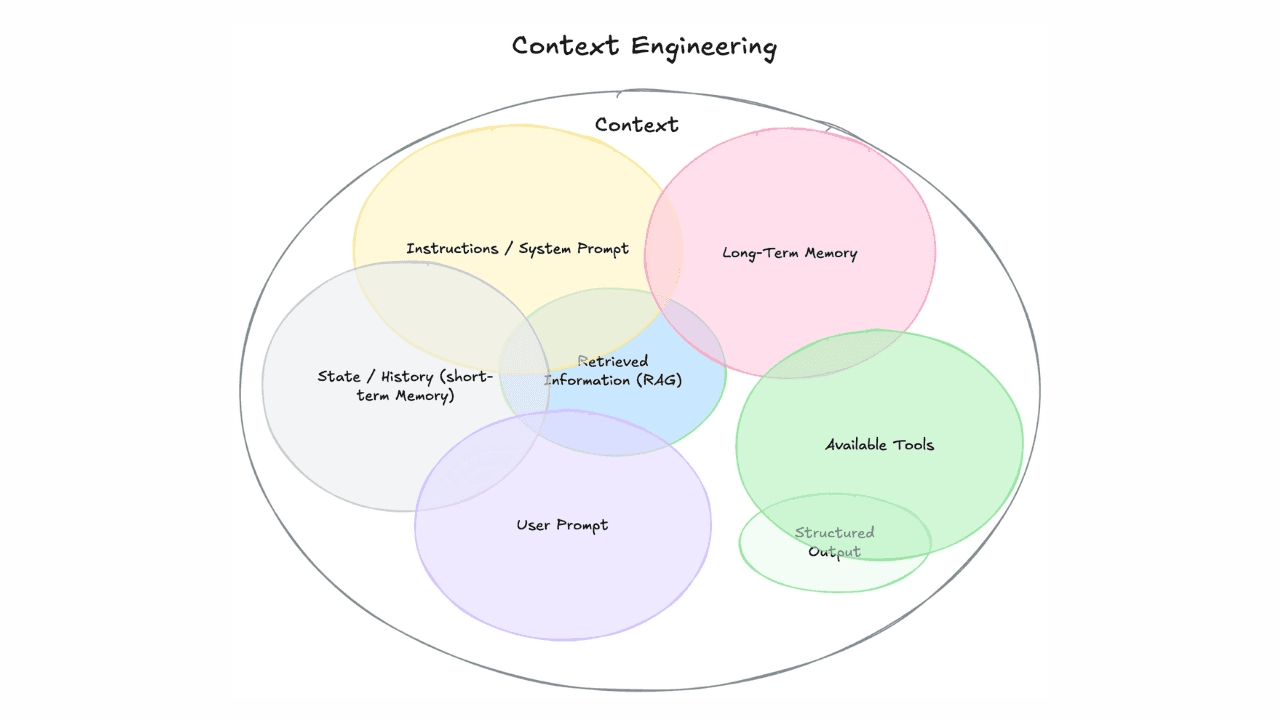
Context engineering vs. prompt engineering
Learn how context engineering and prompt engineering differ and why mastering both is essential for building production AI agents and RAG systems.
January 2, 2026
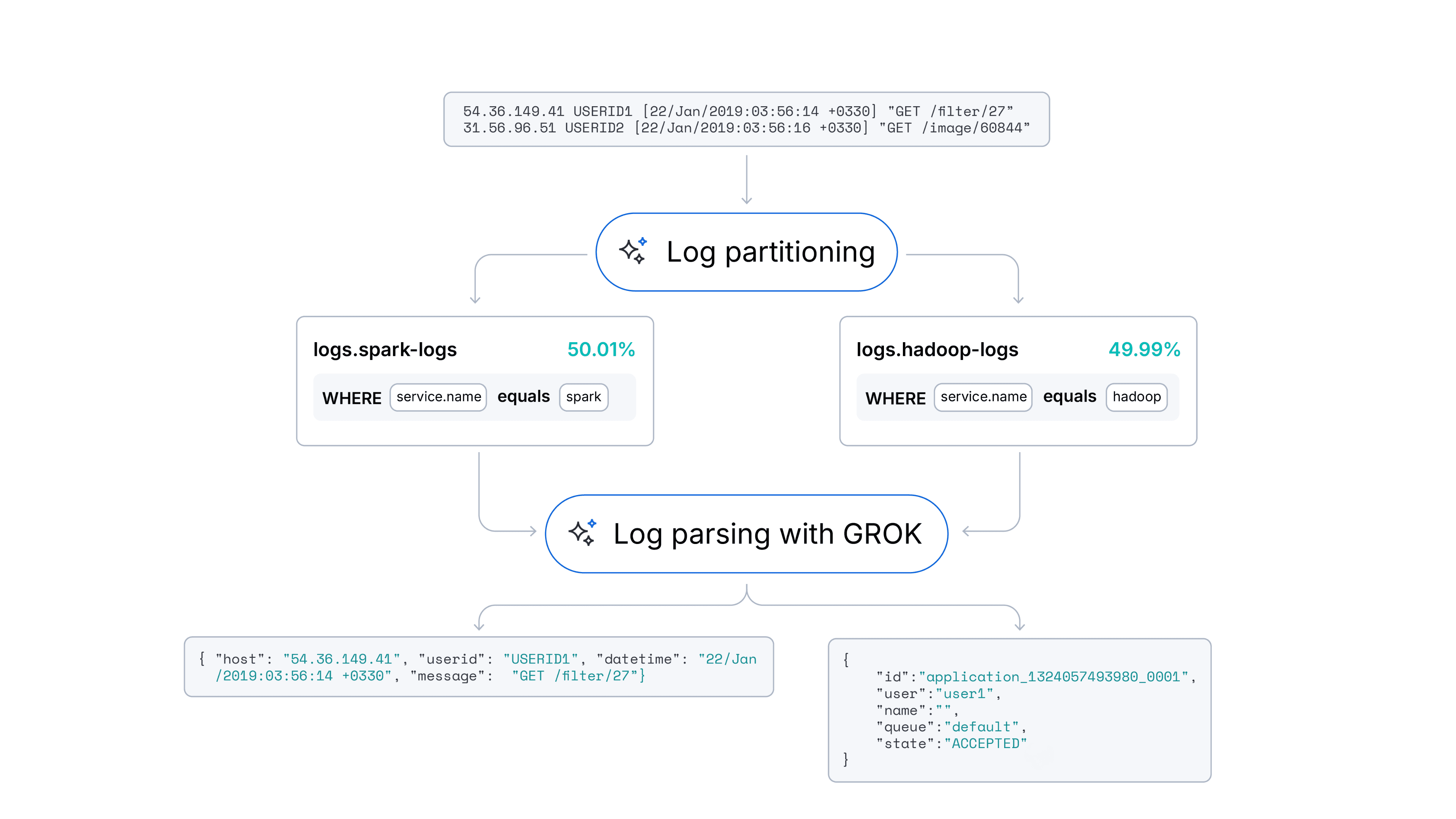
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.
December 31, 2025
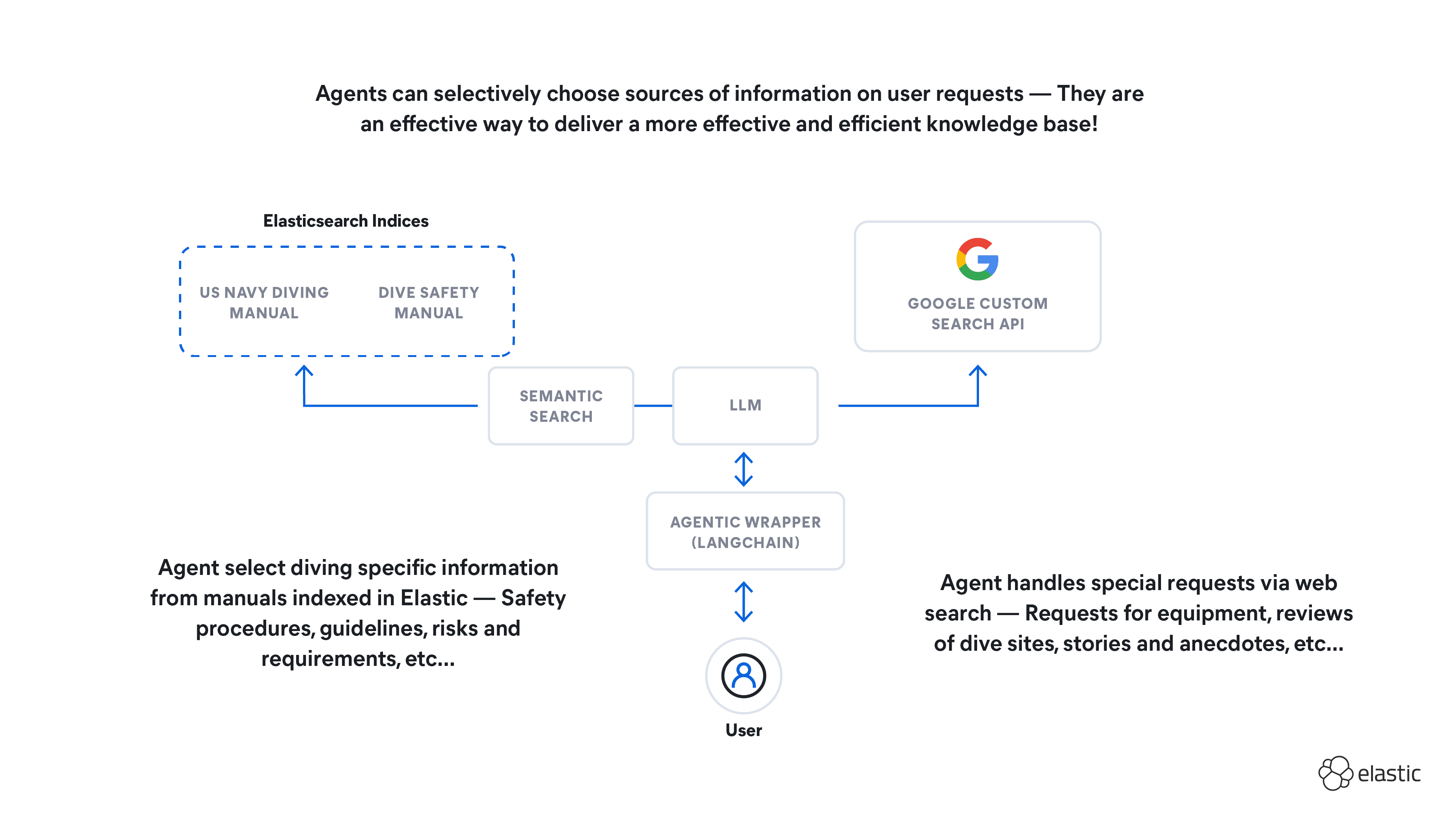
How to build an agent knowledge base with LangChain and Elasticsearch
Learn how to build an agent knowledge base and test its ability to query sources of information based on context, use WebSearch for out-of-scope queries, and refine recommendations based on user intention.