Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
When working with PDFs in a retrieval-augmented generation (RAG) pipeline, a key challenge is efficiently extracting and processing tables. Traditional methods often convert tables into highly normalized formats such as CSV or JSON, which fail to capture the contextual richness needed for effective search and retrieval. These representations break the data down into rows and columns, losing the broader relationships between elements. To address this, I developed a approach that leverages a large language model (LLM) to transform tables into readable text while retaining the context, enhancing the usability of the data in RAG workflows.
This article explains the reasoning behind this approach, the high-level benefits, and the key parts of the notebook.
Why this table PDF parsing approach?
Standard table parsing techniques often fail in RAG because they produce highly normalized outputs. While CSV and JSON formats are useful for specific data analytics, they break down in scenarios where more context is needed. Retrieval-augmented generation models thrive on rich, content-heavy data, and having only single rows or minimal data points hinders effective search.
Instead of sticking with the traditional approach of exporting table data in structured formats, I opted to extract the tables, parse them using Azure OpenAI, and reformat the tables into human-readable text. This approach allows for better contextual embedding and enhances searchability without losing the richness of the data.
Parsing challenges in PDF tables
In real-world applications, extracting structured information from PDFs often involves complex tables like the one below from Bank of America's SEC FORM 10-Q.
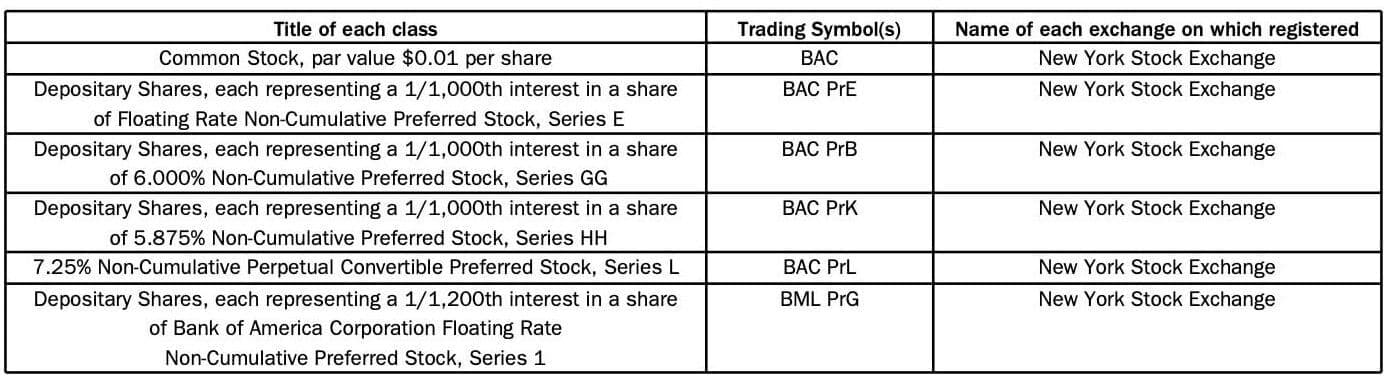
This table contains critical financial data, such as stock symbols, descriptions, and exchanges. However, parsing such tables presents multiple challenges:
Complexity of table structure
The table includes merged cells, multi-line text, and varying formats for data types like numbers and text. This adds complexity to the parsing process as tools often struggle to identify the correct relationships between the data elements.
Loss of context
When tables are converted to formats such as CSV or JSON, much of the relational context between the table's rows and columns is lost. For example, the relationship between the title of each class and its corresponding trading symbol may not be preserved, impacting the integrity of the extracted data.
Handling special characters and formats
Stock symbols and series names, such as "BAC PrE" and "BAC PrL," may contain abbreviations or special characters that get misinterpreted by traditional parsing tools, leading to inaccurate data extraction.
Addressing the challenges of parsing PDF tables in RAG
Using a large language model (LLM) approach, the tables can be transformed into readable text that retains the context of the relationships between rows and columns. This ensures that critical financial information is not lost during parsing and is fully searchable for retrieval-augmented generation (RAG) workflows.
For example, applying this method to the table above outputs the following text:
The benefits
- Improved searchability: Embedding text instead of highly structured table data ensures that RAG models can capture the relationships and broader context of the content, making it easier to retrieve accurate results.
- Preservation of context: By converting tables into human-readable descriptions, we preserve the intent and structure of the original data, which is essential for RAG workflows where the document's meaning is crucial.
- Handling unstructured data: This method handles the natural unstructured nature of PDFs better than simple table extraction, making it more versatile in real-world applications.
- Readable output: Rather than dealing with abstract, normalized data, the final output is in a format that is easier for both humans and machines to interpret.
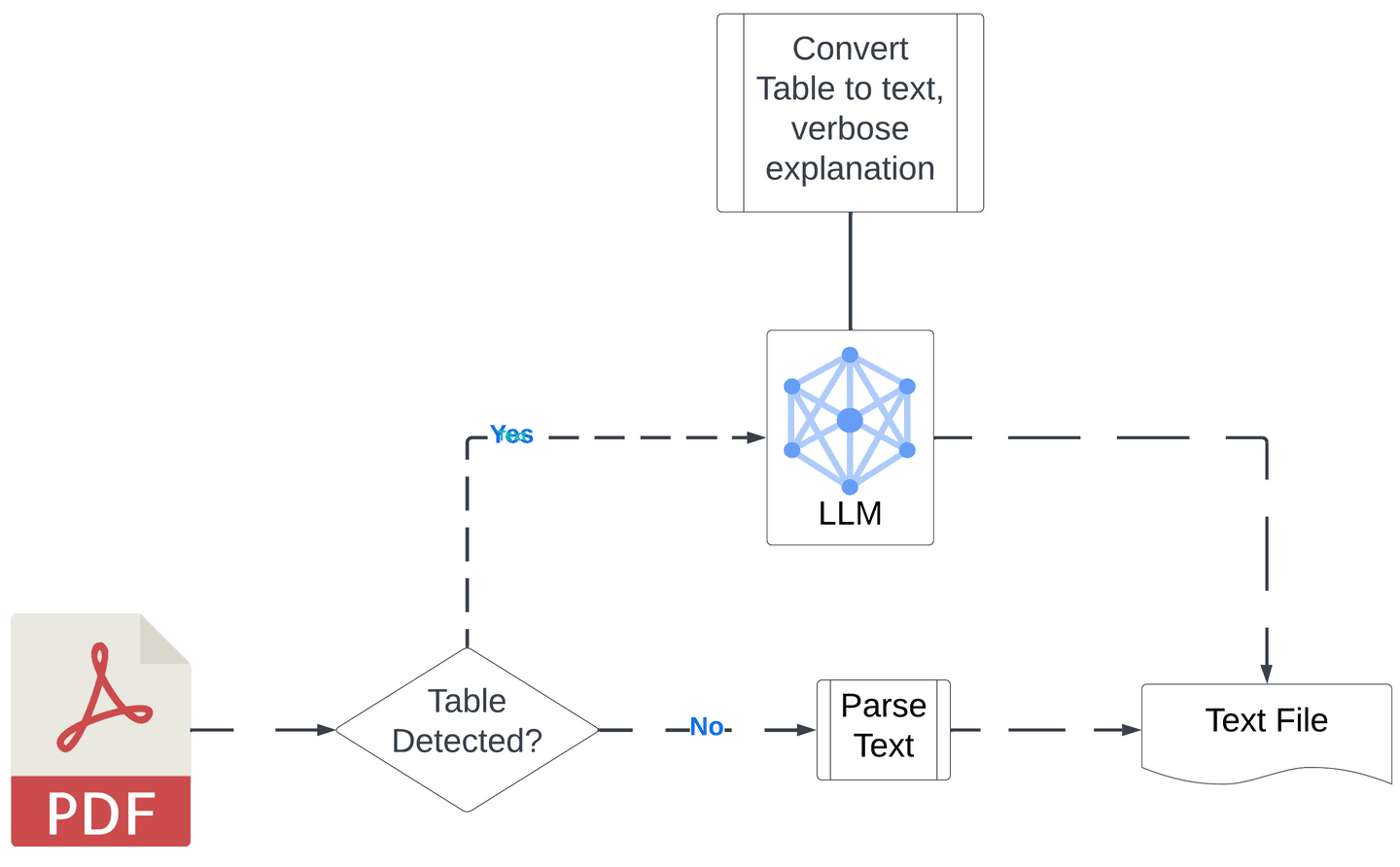
Key code explanation
1. Extracting text and tables from PDFs
The first step in the process uses the pdfplumber library to extract both text and tables from each page of the PDF.
Here, pdfplumber is utilized to extract both plain text and tables from each page of the PDF. It provides a flexible way to handle PDFs and their internal structure.
2. Cleaning and sending tables to Azure OpenAI
After extracting the tables, the script sends a cleaned version of the table data to Azure OpenAI for transformation into readable text. This allows the LLM to create a natural language summary of the table.
The tables are cleaned to handle missing or None values and are then passed to Azure OpenAI, which generates a textual description of the table's contents. This helps retain the table's context in the final output.
3. Writing the final output
Once the text has been generated from the tables and the non-table text has been extracted, everything is written into a single output file. This ensures that both text and table data are available for downstream tasks like search and retrieval.
By embedding the table summaries alongside the rest of the text, we provide a comprehensive output that is ready for use in RAG applications, ensuring all information from the PDF is preserved in a human-readable format.
Conclusion
By using an LLM to transform tables into readable text and embedding that text back into the original content, this approach significantly enhances the usability of PDF tables in retrieval-augmented generation workflows. It preserves context, improves searchability, and ensures that no valuable information is lost in the normalization process. This method offers a more comprehensive solution for those working with PDF-based data in RAG applications.
Related Content

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.
January 20, 2026
Context engineering vs. prompt engineering
Learn how context engineering and prompt engineering differ and why mastering both is essential for building production AI agents and RAG systems.
January 2, 2026
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.
December 31, 2025
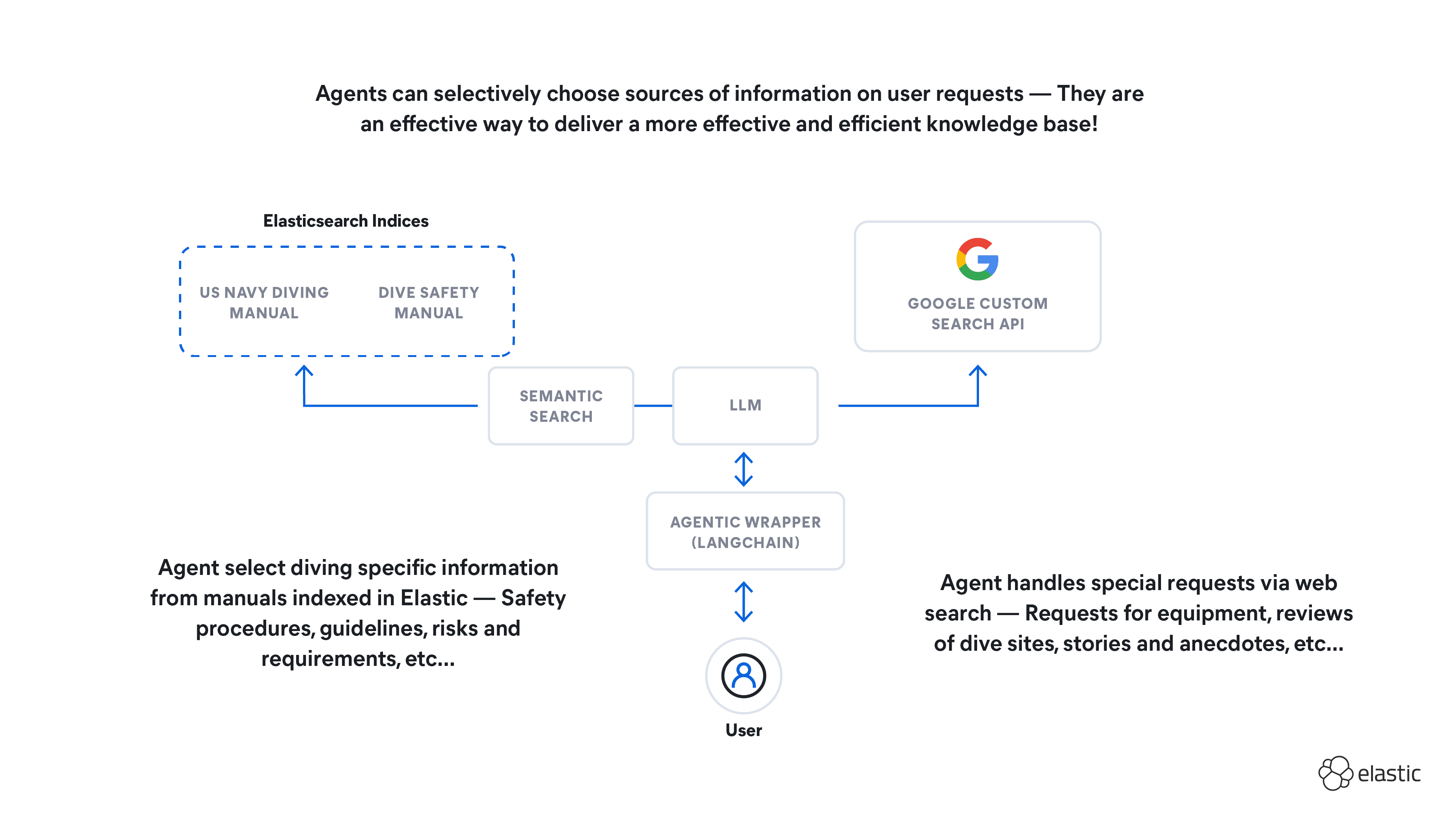
How to build an agent knowledge base with LangChain and Elasticsearch
Learn how to build an agent knowledge base and test its ability to query sources of information based on context, use WebSearch for out-of-scope queries, and refine recommendations based on user intention.

December 29, 2025
Creating reliable agents with structured outputs in Elasticsearch
Explore what structured outputs are and how to leverage them in Elasticsearch to ground agents in the most relevant context for data contracts.