Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
In the realm of Retrieval-Augmented Generation (RAG), one persistent challenge is finding the optimal amount of data to feed into a Large Language Model (LLM). Too little data results in insufficient or inaccurate responses, while too much data leads to vague answers. This delicate balance inspired me to develop a notebook focusing on intelligent chunking and leveraging Elasticsearch vector database.
This blog builds on that notebook and explores fetch surrounding chunking, an emerging pattern in RAG that uses intelligent chunking and Elasticsearch vector database to optimize LLM responses. The approach balances data input to enhance the accuracy and relevance of LLM-generated answers through semantic hybrid search.
The motivation: A refined approach to RAG data chunking
The primary motivation behind building this notebook was to demonstrate a refined approach to RAG by addressing the challenge of data chunking. Traditional methods often fall short in dynamically adjusting the data size fed to LLMs, either overwhelming the model with too much context or starving it with too little. This notebook aims to strike the right balance, providing just enough information for the LLM to generate precise and contextually relevant responses. However, it must be noted that there is no one-size-fits-all solution.
This method works especially well with books and similar texts where content flows within longer sections or chapters. However, it may require adaptation for texts structured into shorter, distinct sections, such as research papers or articles, where each segment might cover a different topic. In such cases, additional strategies may be necessary to effectively chunk and retrieve related content.
The methodology: Intelligent RAG data chunking
Fetch surrounding chunks
The core idea is to partition the source text into manageable chunks, ensuring each chunk contains just the right amount of information. For this demonstration, I used text from "Harry Potter and the Sorcerer's Stone." The text was partitioned into chapters, and each chapter was further divided into smaller chunks. These chunks, along with their dense and sparse (ELSER) vector representations, were indexed in the Elasticsearch vector database.
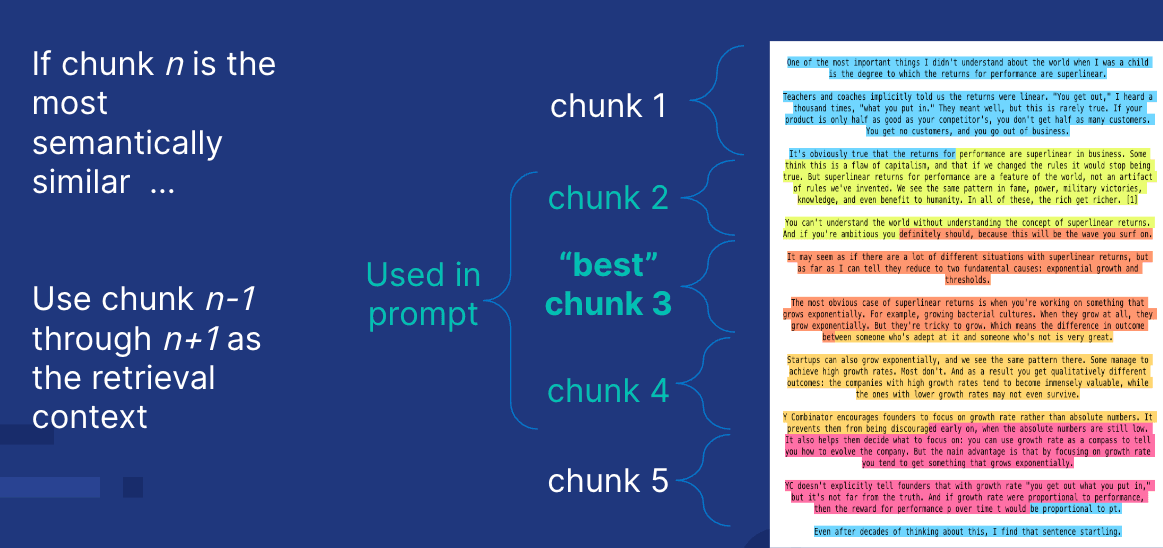
Assigning numbers to chunks
Each chunk within a chapter was assigned a sequential integer, allowing us to identify its position. When a matching chunk is found, the chapter number and chunk number are used to retrieve surrounding chunks, providing additional context for the LLM.
Vector database in Elasticsearch
These chunks and their vector representations were ingested into an Elasticsearch Cloud instance. Elasticsearch's robust vector search capabilities make it ideal for hosting these chunks, allowing for efficient retrieval of the most relevant chunks based on the semantic content or text match of a user's query.
AI search
To retrieve the relevant chunks, I employed a hybrid search strategy using dense vector comparisons, sparse vector comparisons, and text search in parallel. This multi-faceted approach ensures that the search results are both semantically rich and contextually accurate. A query is issued to find the matched chunk, which returns the chunk number and chapter. Surrounding chunks for that chapter are then fetched based on the matched chunk.
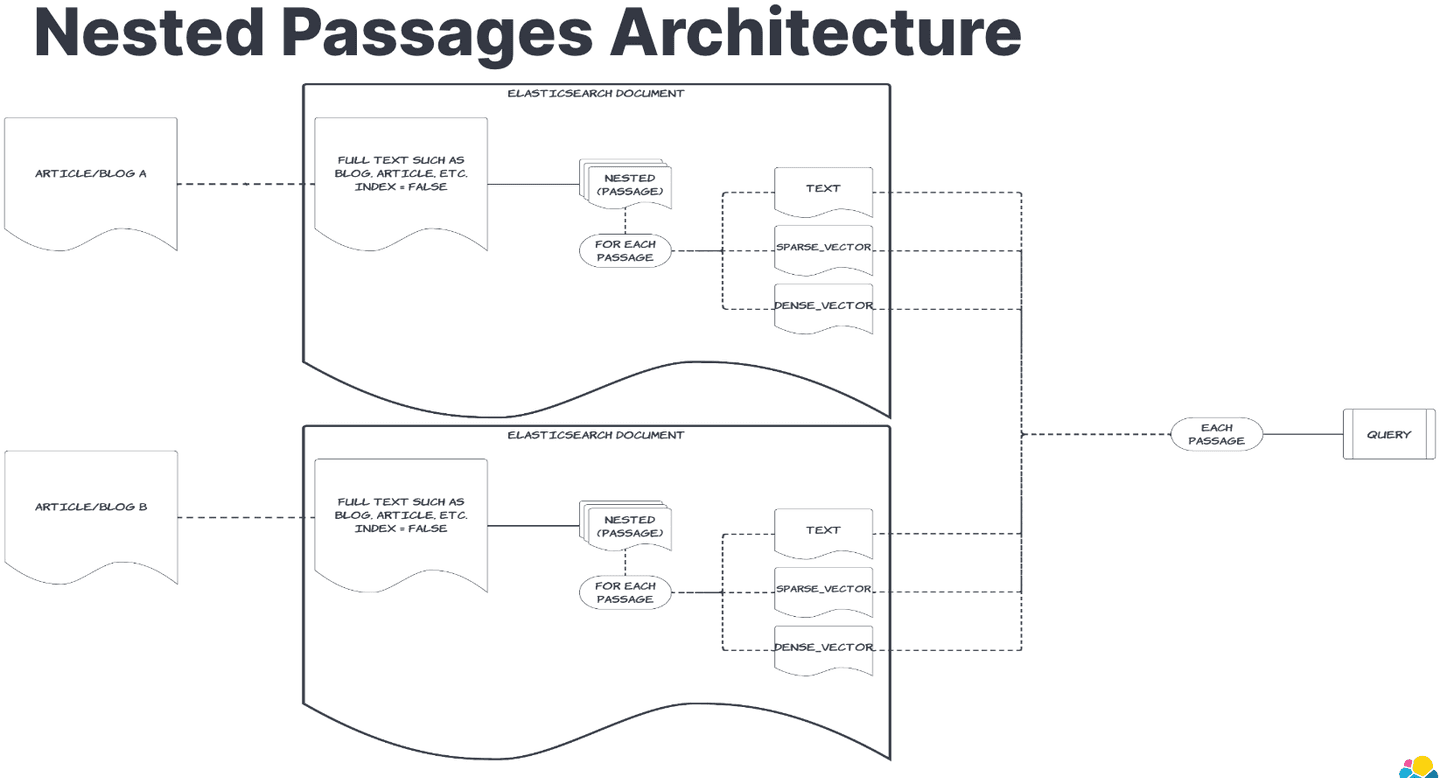
The RAG pattern
When a query is made, the search flow performs the following steps:
- Query analysis: The user's query is translated into dense and sparse vectors to retrieve the most relevant chunks from the Elasticsearch index.
- Chunk retrieval: Using the AI search strategy, the system retrieves the top relevant chunks.
- Contextual expansion: Adjacent chunks (n-1 and n+1) are also retrieved to provide a more comprehensive context. If the chunk is the last in the chapter, it fetches n-1 and n-2; if it's the first, it fetches n+1 and n+2.
- LLM response: These intelligently selected chunks are then fed into the LLM, ensuring it receives the optimal amount of information to generate a precise and contextually relevant response.
Why intelligent RAG data chunking matters
This approach addresses a critical aspect of RAG by optimizing the input data fed to LLMs. By leveraging intelligent chunking and hybrid semantic search, this method enhances the accuracy and relevance of the responses generated by LLMs. It showcases a pattern that can be widely applied in various applications within the RAG space, from customer support to content generation and beyond.
Conclusion
This notebook underscores the importance of intelligent data chunking in the RAG framework and demonstrates how Elasticsearch vector database can be leveraged to achieve optimal results. By ensuring the LLM receives just the right amount of information, this methodology paves the way for more accurate and contextually rich responses, enhancing the overall effectiveness of RAG systems.
Related Content

January 28, 2026
Apache Lucene 2025 wrap-up
2025 was a stellar year for Apache Lucene; here are our highlights.

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.
January 20, 2026
Context engineering vs. prompt engineering
Learn how context engineering and prompt engineering differ and why mastering both is essential for building production AI agents and RAG systems.
January 2, 2026
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.
December 31, 2025
How to build an agent knowledge base with LangChain and Elasticsearch
Learn how to build an agent knowledge base and test its ability to query sources of information based on context, use WebSearch for out-of-scope queries, and refine recommendations based on user intention.