Como acessar modelos de machine learning no Elastic


 Share on Twitter
Share on TwitterCompartilhar no Twitter

 Share on LinkedIn
Share on LinkedInCompartilhar no LinkedIn

 Share on Facebook
Share on FacebookCompartilhar no Facebook

 Share by Email
Share by EmailCompartilhar por e-mail

 Print this page
Print this pageImprimir
A Elastic oferece suporte para os modelos de machine learning de que você precisa
A Elastic® possibilita que você aplique o machine learning (ML) apropriado para seu caso de uso e nível de expertise em ML. Você tem várias opções:
- Utilizar os modelos que vêm integrados. Além de modelos voltados para ameaças à segurança específicas e tipos de problemas do sistema na nossa solução de observabilidade e segurança, você pode usar nosso modelo proprietário Elastic Learned Sparse Encoder pronto para uso, bem como uma identificação de idioma, útil se você estiver trabalhando com dados de texto que não estejam em inglês.
- Acessar modelos PyTorch de terceiros de qualquer lugar, incluindo o hub de modelos HuggingFace.
- Carregar um modelo que você treinou — principalmente transformadores de PLN neste ponto.
O uso de modelos integrados oferece valor imediato, sem exigir nenhum conhecimento de ML de sua parte, mas você tem a flexibilidade de experimentar modelos diferentes e determinar o que funciona melhor nos seus dados.
Nós projetamos nosso gerenciamento de modelos para ser escalável em vários nós de um cluster, além de garantir um bom desempenho de inferência para cargas de trabalho de alta taxa de transferência e de baixa latência. Isso ocorre em parte capacitando os pipelines de ingestão para executar a inferência e usando nós dedicados para a inferência de modelo computacionalmente exigente — durante a fase de ingestão, bem como na análise e na busca de dados.
Continue lendo para saber mais sobre a biblioteca do Eland que permite carregar modelos no Elastic e como isso funciona para os vários tipos de machine learning que você pode usar no Elasticsearch® — desde os mais recentes modelos transformadores e de processamento de linguagem natural (PLN) até os modelos de árvore aprimorados para regressão.
Você pode carregar modelos de ML no Elastic com o Eland
Nossa biblioteca do Eland fornece uma interface fácil para carregar modelos de ML no Elasticsearch, desde que tenham sido treinados usando o PyTorch. Usando a biblioteca nativa libtorch e esperando modelos que foram exportados ou salvos como uma representação TorchScript, o Elasticsearch evita a execução de um interpretador Python enquanto executa a inferência de modelos.
Ao se integrar a um dos formatos mais populares para a construção de modelos de PLN no PyTorch, o Elasticsearch pode fornecer uma plataforma que funciona com uma grande variedade de tarefas e casos de uso de PLN. Veremos mais sobre isso na seção sobre transformadores a seguir.
Você tem três opções para usar o Eland para carregar um modelo: linha de comando, Docker e de dentro do seu próprio código Python. O Docker é menos complexo porque não requer uma instalação local do Eland e de todas as suas dependências. Depois que você tem acesso ao Eland, a amostra de código abaixo mostra como carregar um modelo de REN DistilBERT, como exemplo:

Mais abaixo, examinaremos cada um dos argumentos de eland_import_hub_model. E você pode emitir o mesmo comando de um container do Docker.
Após o upload, a interface do usuário ML Model Management do Kibana permite que você gerencie os modelos em um cluster do Elasticsearch, incluindo aumentar as alocações para elevar a taxa de transferência e parar/retomar modelos enquanto (re)configura seu sistema.
Quais modelos são compatíveis?
A Elastic oferece suporte para uma variedade de modelos transformadores, bem como para as bibliotecas de aprendizado supervisionado mais populares:
- Modelos de PLN e embedding. Todos os transformadores que estão em conformidade com a interface do modelo BERT padrão e usam o algoritmo de tokenização WordPiece. Veja uma lista completa de arquiteturas de modelo compatíveis.
- Aprendizagem supervisionada. Modelos treinados das bibliotecas scikit-learn, XGBoost e LightGBM para serem serializados e usados como um modelo de inferência no Elasticsearch. Nossa documentação fornece um exemplo para treinar uma classificação XGBoost em dados no Elastic. Você também pode exportar e importar modelos supervisionados treinados no Elastic com nossa analítica de estruturas de dados.
- IA generativa. Você pode usar a API fornecida para o LLM para passar consultas — potencialmente enriquecidas com contexto recuperado do Elastic — e processar os resultados retornados. Para mais instruções, consulte este post do blog , que se vincula a um repositório do GitHub com código de exemplo para comunicação por meio da API do ChatGPT.
Abaixo, fornecemos mais informações sobre o tipo de modelo que você provavelmente usará no contexto de aplicações de busca: transformadores de PLN.
Como aplicar transformadores e PLN no Elastic com facilidade
Vamos mostrar as etapas para carregar e usar um modelo de PLN, por exemplo, um modelo de REN popular da Hugging Face, examinando os argumentos identificados no snippet de código abaixo.

- Especifique o identificador do Elastic Cloud. Como alternativa, use --url.
- Forneça detalhes de autenticação para acessar seu cluster. Consulte os métodos de autenticação disponíveis.
- Especifique o identificador para o modelo no hub de modelos da Hugging Face.
- Especifique o tipo de tarefa de PLN. Os valores aceitos são fill_mask, ner, text_classification, text_embedding e zero_shot_classification.
Depois de carregar o modelo, você precisa implantá-lo. Isso é feito na tela Model Management (Gerenciamento de modelo) da guia Machine Learning no Kibana. Em seguida, você normalmente testa o modelo para verificar se ele está funcionando corretamente.
Agora está tudo pronto para você usar o modelo implantado para inferência. Por exemplo, para extrair entidades nomeadas, você chama o endpoint _infer no modelo de REN carregado:
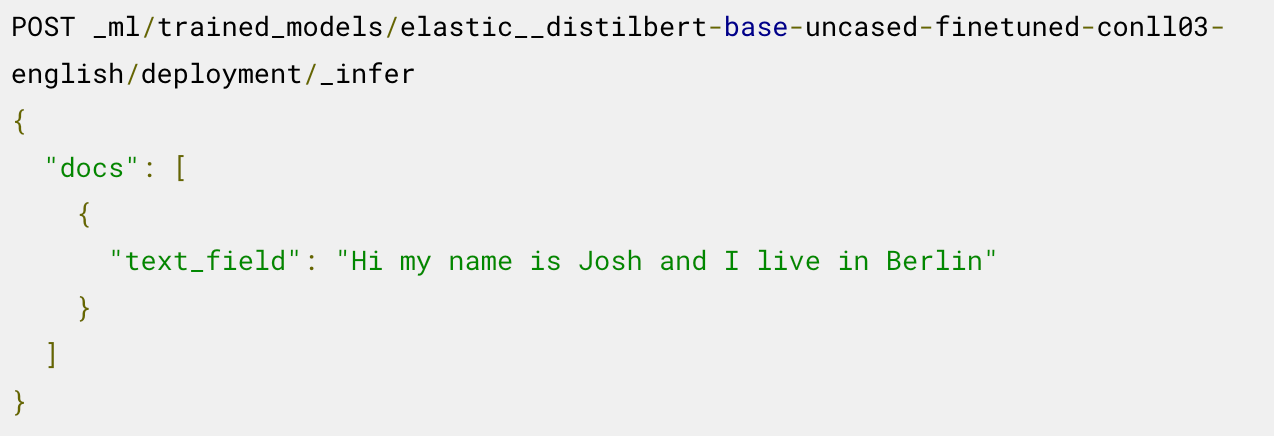
O modelo identifica duas entidades: a pessoa “Josh” e o local “Berlin”.

Para ver etapas adicionais, como o uso desse modelo em um pipeline de inferência e o ajuste da implantação, leia o post do blog que descreve este exemplo.
Quer ver como aplicar a busca semântica — por exemplo, como criar embeddings de texto e depois aplicar a busca vetorial para encontrar documentos relacionados? Este post do blog traz uma descrição passo a passo, incluindo a validação do desempenho do modelo.
Não sabe qual tipo de tarefa usar para qual modelo? Esta tabela deve ajudar você a começar.
Modelo da Hugging Face | task-type |
|---|---|
ner | |
text_embedding | |
text_classification | |
zero_shot_classification | |
| Resposta a perguntas | question_answering |
A Elastic também oferece suporte para comparar a similaridade entre dois textos como task-type text_similarity. Isso é útil para classificar o texto do documento ao compará-lo com outra entrada de texto fornecida e, às vezes, é chamado de codificação cruzada.
Confira mais detalhes nestes recursos
- Suporte para transformadores PyTorch, incluindo considerações de design para Eland
- Etapas para carregar transformadores no Elastic e usá-los em inferência (em inglês)
- Post que descreve como consultar seus dados proprietários usando o ChatGPT (em inglês)
- Como adaptar um transformador pré-treinado para uma tarefa de classificação de texto e carregar o modelo customizado no Elastic (em inglês)
- Identificação de idioma integrada de texto que não está em inglês antes de passar para modelos compatíveis apenas com inglês
Elastic, Elasticsearch e marcas associadas são marcas comerciais, logotipos ou marcas registradas da Elasticsearch N.V. nos Estados Unidos e em outros países. Todos os outros nomes de empresas e produtos são marcas comerciais, logotipos ou marcas registradas de seus respectivos proprietários.
O lançamento e o tempo de amadurecimento de todos os recursos ou funcionalidades descritos neste post permanecem a exclusivo critério da Elastic. Os recursos ou funcionalidades não disponíveis atualmente poderão não ser entregues dentro do prazo previsto ou nem chegar a ser entregues.
Compartilhar
- Share on Twitter
Compartilhar no Twitter
- Share on LinkedIn
Compartilhar no LinkedIn
- Share on Facebook
Compartilhar no Facebook
- Share by Email
Compartilhar por e-mail
- Print this page
Imprimir

