Como implantar o PLN: embeddings de texto e busca vetorial


 Share on Twitter
Share on TwitterCompartilhar no Twitter

 Share on LinkedIn
Share on LinkedInCompartilhar no LinkedIn

 Share on Facebook
Share on FacebookCompartilhar no Facebook

 Share by Email
Share by EmailCompartilhar por e-mail

 Print this page
Print this pageImprimir
Como parte de nossa série de posts do blog sobre processamento de linguagem natural (PLN), apresentaremos um exemplo de uso de um modelo de embedding de texto para gerar representações vetoriais de conteúdos textuais e a demonstração de uma busca por similaridade vetorial nos vetores gerados. Implantaremos um modelo disponível publicamente no Elasticsearch e o usaremos em um pipeline de ingestão para gerar embeddings partindo de documentos textuais. Em seguida, mostraremos como usar esses embeddings na busca por similaridade vetorial para encontrar documentos semanticamente semelhantes para uma determinada consulta.
A busca por similaridade vetorial ou busca semântica, como é comumente chamada, vai além da busca tradicional baseada em palavras-chave e permite que os usuários encontrem documentos semanticamente semelhantes que podem não ter palavras-chave comuns, fornecendo assim uma gama mais ampla de resultados. A busca por similaridade vetorial opera em vetores densos e usa a busca de k vizinhos mais próximos para encontrar vetores semelhantes. Para isso, os conteúdos na forma textual precisam primeiro ser convertidos para suas representações numéricas vetoriais usando um modelo de embedding de texto.
Usaremos um conjunto de dados público da Tarefa de Classificação de Passagem do MS MARCO para demonstração. Ele consiste em perguntas reais do mecanismo de busca do Microsoft Bing e respostas geradas por humanos para elas. Esse conjunto de dados é um recurso perfeito para testar a busca por similaridade vetorial, primeiro porque a resposta a perguntas é um dos casos de uso mais comuns para a busca vetorial e, em segundo lugar, porque os principais artigos da tabela de classificação do MS MARCO usam a busca vetorial de alguma forma.
Em nosso exemplo, trabalharemos com uma amostra desse conjunto de dados, usaremos um modelo para produzir embeddings de texto e, em seguida, executaremos a busca vetorial nele. Esperamos também fazer uma rápida verificação da qualidade dos resultados produzidos da busca vetorial.
1. Implantar um modelo de embedding de texto
A primeira etapa é instalar um modelo de embedding de texto. Para nosso modelo, usamos msmarco-MiniLM-L-12-v3 da Hugging Face. Esse é um modelo transformador de frase que pega uma frase ou um parágrafo e o mapeia para um vetor denso de 384 dimensões. Esse modelo é otimizado para busca semântica e foi treinado especificamente no conjunto de dados de passagem do MS MARCO, tornando-o adequado para nossa tarefa. Além desse modelo, o Elasticsearch oferece suporte para vários outros modelos para embedding de texto. A lista completa pode ser encontrada aqui.
Instalamos o modelo com o agente docker do Eland que criamos no exemplo de NER. A execução de um script abaixo importa nosso modelo para nosso cluster local e o implanta:
eland_import_hub_model \
--url https://<user>:<password>@localhost:9200/ \
--hub-model-id sentence-transformers/msmarco-MiniLM-L-12-v3 \
--task-type text_embedding \
--startDesta vez, --task-type é definido como text_embedding, e a opção --start é passada para o script do Eland para que o modelo seja implantado automaticamente sem que seja necessário iniciá-lo na UI de Gerenciamento de Modelos. Para acelerar as inferências, você pode aumentar o número de threads de inferência com o parâmetro inference_threads.
Podemos testar se a implantação do modelo foi bem-sucedida usando este exemplo no console do Kibana:
POST /_ml/trained_models/sentence-transformers__msmarco-minilm-l-12-v3/deployment/_infer
{
"docs": {
"text_field": "how is the weather in jamaica"
}
}Deveremos ver o vetor denso previsto como o resultado:
{
"predicted_value" : [
0.3345310091972351,
-0.305600643157959,
0.2592800557613373,
…
]
}2. Carregar os dados iniciais
Conforme mencionado na introdução, usamos o conjunto de dados de Classificação de Passagem do MS MARCO. O conjunto de dados é bastante grande, composto por mais de 8 milhões de passagens. Para nosso exemplo, usamos um subconjunto dele que foi usado na fase de teste do 2019 TREC Deep Learning Track. O conjunto de dados msmarco-passagetest2019-top1000.tsv usado para a tarefa de reclassificação contém 200 consultas e, para cada consulta, uma lista de passagens de texto relevantes extraídas por um sistema de IR simples. Desse conjunto de dados, extraímos todas as passagens exclusivas com seus ids e as colocamos em um arquivo tsv separado, totalizando 182.469 passagens. Usamos esse arquivo como nosso conjunto de dados.
Usamos o recurso de upload de arquivo do Kibana para carregar esse conjunto de dados. O upload de arquivo do Kibana nos permite fornecer nomes customizados para os campos. Vamos chamá-los de id com tipo long para os ids das passagens e text com tipo text para o conteúdo das passagens. O nome do índice é collection. Após o upload, podemos ver um índice chamado collection com 182.469 documentos.
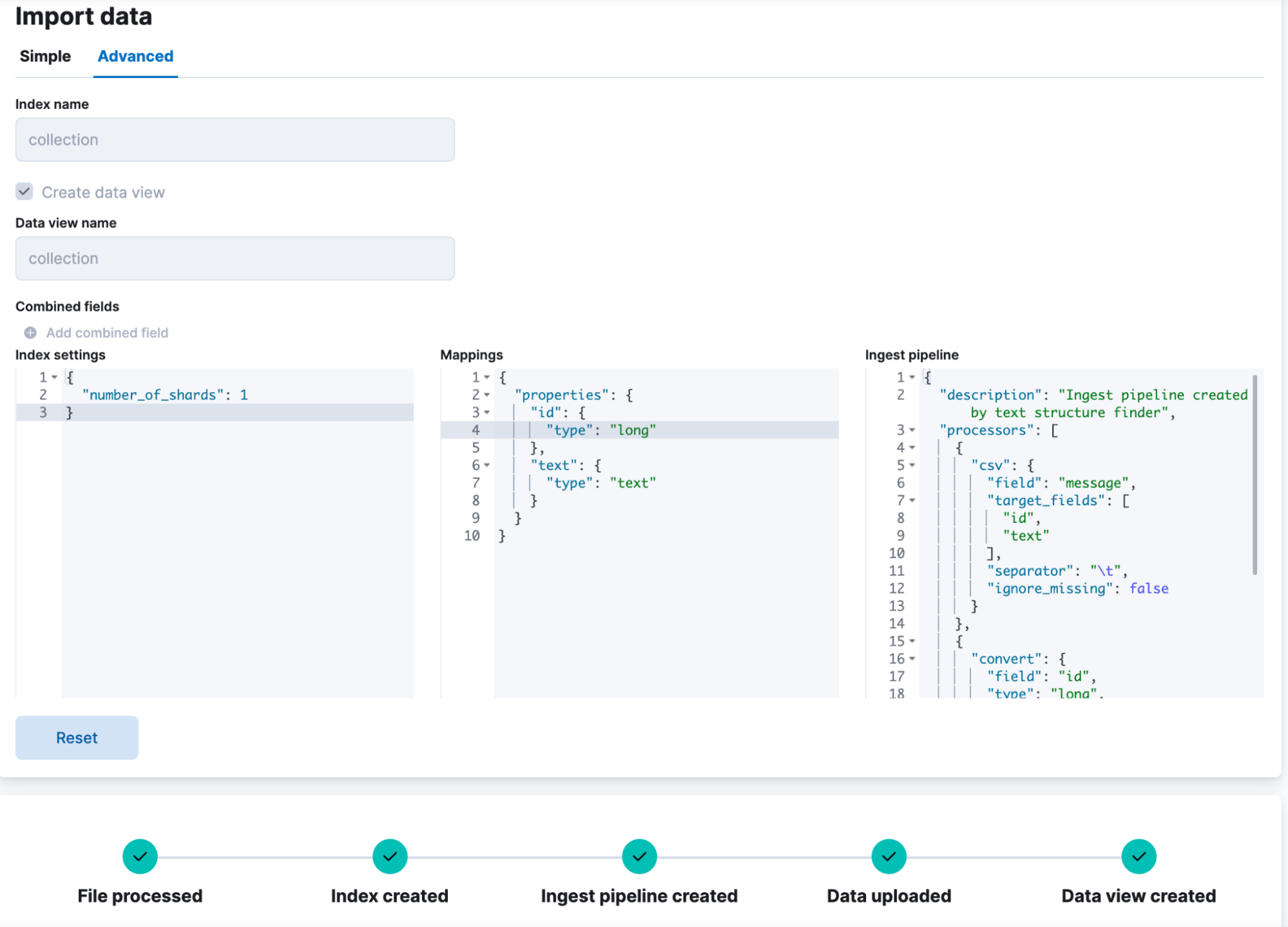
3. Criar o pipeline
Queremos processar os dados iniciais com um processador de inferência que adicionará um embedding para cada passagem. Para isso, criamos um pipeline de ingestão de embedding de texto e, em seguida, reindexamos nossos dados iniciais com esse pipeline.
No console do Kibana, criamos um pipeline de ingestão (como fizemos no post do blog anterior), desta vez para embeddings de texto, e o chamamos de text-embeddings. As passagens estão em um campo chamado text. Como fizemos antes, definiremos um field_map para mapear o texto para o campo text_field que o modelo espera. Da mesma forma, o manipulador on_failure é definido para indexar falhas em um índice diferente:
PUT _ingest/pipeline/text-embeddings
{
"description": "Text embedding pipeline",
"processors": [
{
"inference": {
"model_id": "sentence-transformers__msmarco-minilm-l-12-v3",
"target_field": "text_embedding",
"field_map": {
"text": "text_field"
}
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}4. Reindexar dados
Queremos reindexar documentos do índice collection no novo índice collection-with-embeddings enviando documentos por meio do pipeline text-embeddings, para que os documentos no índice collection-with-embeddings tenham um campo adicional para os embeddings das passagens. Porém, antes de fazermos isso, precisamos criar e definir um mapeamento para nosso índice de destino, em particular para o campo text_embedding.predicted_value onde o processador de ingestão armazenará os embeddings. Se não fizermos isso, os embeddings serão indexados em campos float regulares e não poderão ser usados para busca por similaridade vetorial. O modelo que usamos produz embeddings como vetores de 384 dimensões, portanto, usamos o tipo de campo indexado dense_vector com 384 dimensões, como se segue:
PUT collection-with-embeddings
{
"mappings": {
"properties": {
"text_embedding.predicted_value": {
"type": "dense_vector",
"dims": 384,
"index": true,
"similarity": "cosine"
},
"text": {
"type": "text"
}
}
}
}
Finalmente, está tudo pronto para a reindexação. Como ela levará algum tempo para processar todos os documentos e inferir sobre eles, fazemos a reindexação em segundo plano invocando a API com o sinalizador wait_for_completion=false.
POST _reindex?wait_for_completion=false
{
"source": {
"index": "collection"
},
"dest": {
"index": "collection-with-embeddings",
"pipeline": "text-embeddings"
}
}
Isso retorna um id de tarefa. Podemos monitorar o progresso da tarefa com:
GET _tasks/<task_id>Como alternativa, acompanhe o progresso observando o aumento da contagem de inferência na API de estatísticas do modelo ou na UI de estatísticas do modelo.

Os documentos reindexados agora contêm os resultados da inferência — embeddings vetoriais. Como exemplo, um dos documentos fica mais ou menos assim:
{
"id": "G7PPtn8BjSkJO8zzChzT",
"text": "This is the definition of RNA along with examples of types of RNA molecules. This is the definition of RNA along with examples of types of RNA molecules. RNA Definition",
"text_embedding":
{
"predicted_value":
[
0.057356324046850204,
0.1602816879749298,
-0.18122544884681702,
0.022277727723121643,
....
],
"model_id": "sentence-transformers__msmarco-minilm-l-12-v3"
}
}
5. Busca por semelhança vetorial
Atualmente, não oferecemos suporte para a geração implícita de embeddings de termos de consulta durante uma solicitação de busca; assim, nossa busca semântica é organizada como um processo de duas etapas:
- Obter um embedding de texto de uma consulta textual. Para isso, usamos a API _infer do nosso modelo.
- Usar a busca vetorial para encontrar documentos semanticamente semelhantes ao texto da consulta. No Elasticsearch v8.0, introduzimos um novo endpoint _knn_search que permite uma busca eficiente de vizinhos mais próximos aproximados em campos dense_vector indexados. Usamos a API _knn_search para encontrar os documentos mais próximos.
Por exemplo, faça uma consulta textual “how is the weather in jamaica”; primeiro, executamos a API _infer para obter seu embedding como um vetor denso:
POST /_ml/trained_models/sentence-transformers__msmarco-minilm-l-12-v3/deployment/_infer
{
"docs": {
"text_field": "how is the weather in jamaica"
}
}Depois disso, conectamos o vetor denso resultante a _knn_search da seguinte forma:
GET collection-with-embeddings/_knn_search
{
"knn": {
"field": "text_embedding.predicted_value",
"query_vector": [
0.3345310091972351,
-0.305600643157959,
0.2592800557613373,
…
],
"k": 10,
"num_candidates": 100
},
"_source": [
"id",
"text"
]
}Como resultado, obtemos os 10 primeiros documentos mais próximos da consulta, classificados por sua proximidade com a consulta:
"hits" : [
{
"_index" : "collection-with-embeddings",
"_id" : "47TPtn8BjSkJO8zzKq_o",
"_score" : 0.94591534,
"_source" : {
"id" : 434125,
"text" : "The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably cooler than the days, and the mountain areas are cooler than the lower land throughout the year. Continue Reading."
}
},
{
"_index" : "collection-with-embeddings",
"_id" : "3LTPtn8BjSkJO8zzKJO1",
"_score" : 0.94536424,
"_source" : {
"id" : 4498474,
"text" : "The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably cooler than the days, and the mountain areas are cooler than the lower land throughout the year"
}
},
{
"_index" : "collection-with-embeddings",
"_id" : "KrXPtn8BjSkJO8zzPbDW",
"_score" : 0.9432083,
"_source" : {
"id" : 190804,
"text" : "Quick Answer. The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably cooler than the days, and the mountain areas are cooler than the lower land throughout the year. Continue Reading"
}
},
...6. Verificação rápida
Como usamos apenas um subconjunto do conjunto de dados do MS MARCO, não podemos fazer uma avaliação completa. O que podemos fazer em vez disso é uma simples verificação em algumas consultas apenas para ter uma sensação de que realmente estamos obtendo resultados relevantes, e não alguns resultados aleatórios. Dos julgamentos do TREC 2019 Deep Learning Track para a Tarefa de Classificação de Passagem, pegamos as três últimas consultas, as enviamos para nossa busca por similaridade vetorial, obtemos os 10 primeiros resultados e consultamos os julgamentos do TREC para ver a relevância dos resultados que recebemos. Para a Tarefa de Classificação de Passagem, as passagens são julgadas em uma escala de quatro pontos: Irrelevante (0), Relacionada (a passagem tem a ver com o tópico, mas não responde à pergunta) (1), Altamente Relevante (2) e Perfeitamente Relevante (3).
Observe que nossa verificação não é uma avaliação rigorosa; ela é usada apenas para nossa demonstração rápida. Como indexamos apenas as passagens que sabemos que estão relacionadas às consultas, é uma tarefa muito mais fácil do que a tarefa de recuperação de passagem original. No futuro, pretendemos fazer uma avaliação rigorosa do conjunto de dados do MS MARCO.
A consulta nº 1124210 “tracheids are part of _____” enviada à nossa busca vetorial retorna os seguintes resultados:
Id da passagem | Classificação de relevância | Passagem |
|---|---|---|
2258591 | 2 - altamente relevante | Tracheid of oak shows pits along the walls. It is longer than a vessel element and has no perforation plates. Tracheids are elongated cells in the xylem of vascular plants that serve in the transport of water and mineral salts.Tracheids are one of two types of tracheary elements, vessel elements being the other. Tracheids, unlike vessel elements, do not have perforation plates.racheids provide most of the structural support in softwoods, where they are the major cell type. Because tracheids have a much higher surface to volume ratio compared to vessel elements, they serve to hold water against gravity (by adhesion) when transpiration is not occurring. |
2258592 | 3 - perfeitamente relevante | Tracheid. a dead lignified plant cell that functions in water conduction. Tracheids are found in the xylem of all higher plants except certain angiosperms, such as cereals and sedges, in which the water-conducting function is performed by vessels, or tracheae.Tracheids are usually polygonal in cross section; their walls have annular, spiral, or scalene thickenings or rimmed pores.racheids are found in the xylem of all higher plants except certain angiosperms, such as cereals and sedges, in which the water-conducting function is performed by vessels, or tracheae. Tracheids are usually polygonal in cross section; their walls have annular, spiral, or scalene thickenings or rimmed pores. |
2258596 | 2 - altamente relevante | Woody angiosperms have also vessels. The mature tracheids form a column of superposed, cylindrical dead cells whose end walls have been perforated, resulting in a continuous tube called vessel (trachea). Tracheids are found in all vascular plants and are the only conducting elements in gymnosperms and ferns. Tracheids have Pits on their end walls. Pits are not nearly as efficient for water translocation as Perforation Plates found in vessel elements. Woody angiosperms have also vessels. The mature tracheids form a column of superposed, cylindrical dead cells whose end walls have been perforated, resulting in a continuous tube called vessel (trachea). Tracheids are found in all vascular plants and are the only conducting elements in gymnosperms and ferns |
2258595 | 2 - altamente relevante | Summary: Vessels have perforations at the end plates while tracheids do not have end plates. Tracheids are derived from single individual cells while vessels are derived from a pile of cells. Tracheids are present in all vascular plants whereas vessels are confined to angiosperms. Tracheids are thin whereas vessel elements are wide. Tracheids have a much higher surface-to-volume ratio as compared to vessel elements. Vessels are broader than tracheids with which they are associated. Morphology of the perforation plate is different from that in tracheids. Tracheids are thin whereas vessel elements are wide. Tracheids have a much higher surface-to-volume ratio as compared to vessel elements. Vessels are broader than tracheids with which they are associated. Morphology of the perforation plate is different from that in tracheids. |
131190 | 3 - perfeitamente relevante | Xylem tracheids are pointed, elongated xylem cells, the simplest of which have continuous primary cell walls and lignified secondary wall thickenings in the form of rings, hoops, or reticulate networks. |
7443586 | 2 - altamente relevante | 1 The xylem tracheary elements consist of cells known as tracheids and vessel members, both of which are typically narrow, hollow, and elongated. Tracheids are less specialized than the vessel members and are the only type of water-conducting cells in most gymnosperms and seedless vascular plants. |
181177 | 2 - altamente relevante | In most plants, pitted tracheids function as the primary transport cells. The other type of tracheary element, besides the tracheid, is the vessel element. Vessel elements are joined by perforations into vessels. In vessels, water travels by bulk flow, as in a pipe, rather than by diffusion through cell membranes. |
2947055 | 0 - irrelevante | Cholesterol belongs to the groups of lipids called _______.holesterol belongs to the groups of lipids called _______. |
6541866 | 2 - altamente relevante | In most plants, pitted tracheids function as the primary transport cells. The other type of tracheary element, besides the tracheid, is the vessel element. Vessel elements are joined by perforations into vessels. In vessels, water travels by bulk flow, as in a pipe, rather than by diffusion through cell membranes. In most plants, pitted tracheids function as the primary transport cells. The other type of tracheary element, besides the tracheid, is the vessel element. Vessel elements are joined by perforations into vessels. In vessels, water travels by bulk flow, as in a pipe, rather than by diffusion through cell membranes. |
A consulta nº 1129237 “hydrogen is a liquid below what temperature” retorna os seguintes resultados:
Id da passagem | Classificação de relevância | Passagem |
|---|---|---|
8588222 | 0 - irrelevante | Answer to: Hydrogen is a liquid below what temperature? By signing up, you'll get thousands of step-by-step solutions to your homework questions.... for Teachers for Schools for Companies |
128984 | 3 - perfeitamente relevante | Hydrogen gas has the molecular formula H 2. At room temperature and under standard pressure conditions, hydrogen is a gas that is tasteless, odorless and colorless. Hydrogen can exist as a liquid under high pressure and an extremely low temperature of 20.28 kelvin (−252.87°C, −423.17 °F). Hydrogen is often stored in this way as liquid hydrogen takes up less space than hydrogen in its normal gas form. Liquid hydrogen is also used as a rocket fuel. |
8588219 | 3 - perfeitamente relevante | User: Hydrogen is a liquid below what temperature? a. 100 degrees C c. -183 degrees C b. -253 degrees C d. 0 degrees C Weegy: Hydrogen is a liquid below 253 degrees C. User: What is the boiling point of oxygen? a. 100 degrees C c. -57 degrees C b. 8 degrees C d. -183 degrees C Weegy: The boiling point of oxygen is -183 degrees C. |
3905057 | 3 - perfeitamente relevante | Hydrogen is a colorless, odorless, tasteless gas. Its density is the lowest of any chemical element, 0.08999 grams per liter. By comparison, a liter of air weighs 1.29 grams, 14 times as much as a liter of hydrogen. Hydrogen changes from a gas to a liquid at a temperature of -252.77°C (-422.99°F) and from a liquid to a solid at a temperature of -259.2°C (-434.6°F). It is slightly soluble in water, alcohol, and a few other common liquids. |
4254811 | 3 - perfeitamente relevante | At STP (standard temperature and pressure) hydrogen is a gas. It cools to a liquid at -423 °F, which is only about 37 degrees above absolute zero. Eleven degrees cooler, at … -434 °F, it starts to solidify. |
2697752 | 2 - altamente relevante | Hydrogen's state of matter is gas at standard conditions of temperature and pressure. Hydrogen condenses into a liquid or freezes solid at extremely cold... Hydrogen's state of matter is gas at standard conditions of temperature and pressure. Hydrogen condenses into a liquid or freezes solid at extremely cold temperatures. Hydrogen's state of matter can change when the temperature changes, becoming a liquid at temperatures between minus 423.18 and minus 434.49 degrees Fahrenheit. It becomes a solid at temperatures below minus 434.49 F.Due to its high flammability, hydrogen gas is commonly used in combustion reactions, such as in rocket and automobile fuels. |
6080460 | 3 - perfeitamente relevante | Hydrogen can exist as a liquid under high pressure and an extremely low temperature of 20.28 kelvin (−252.87°C, −423.17 °F). Hydrogen is often stored in this way as liquid hydrogen takes up less space than hydrogen in its normal gas form. Liquid hydrogen is also used as a rocket fuel. Hydrogen is found in large amounts in giant gas planets and stars, it plays a key role in powering stars through fusion reactions. Hydrogen is one of two important elements found in water (H 2 O). Each molecule of water is made up of two hydrogen atoms bonded to one oxygen atom. |
128989 | 3 - perfeitamente relevante | Confidence votes 11.4K. At STP (standard temperature and pressure) hydrogen is a gas. It cools to a liquid at -423 °F, which is only about 37 degrees above absolute zero. Eleven degrees cooler, at -434 °F, it starts to solidify. |
1959030 | 0 - irrelevante | While below 4 °C the breakage of hydrogen bonds due to heating allows water molecules to pack closer despite the increase in the thermal motion (which tends to expand a liquid), above 4 °C water expands as the temperature increases. Water near the boiling point is about 4% less dense than water at 4 °C (39 °F) |
3905800 | 0 - irrelevante | Hydrogen is the lightest of the elements with an atomic weight of 1.0. Liquid hydrogen has a density of 0.07 grams per cubic centimeter, whereas water has a density of 1.0 g/cc and gasoline about 0.75 g/cc. These facts give hydrogen both advantages and disadvantages. |
A consulta nº 1133167 “how is the weather in jamaica” retorna os seguintes resultados:
Id da passagem | Classificação de relevância | Passagem |
|---|---|---|
434125 | 3 - perfeitamente relevante | The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably cooler than the days, and the mountain areas are cooler than the lower land throughout the year. |
4498474 | 3 - perfeitamente relevante | The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably cooler than the days, and the mountain areas are cooler than the lower land throughout the year. |
190804 | 3 - perfeitamente relevante | Quick Answer. The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably cooler than the days, and the mountain areas are cooler than the lower land throughout the year. Continue Reading. |
1824479 | 3 - perfeitamente relevante | A: The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably cooler than the days, and the mountain areas are cooler than the lower land throughout the year. |
1824480 | 3 - perfeitamente relevante | Quick Answer. The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably cooler than the days, and the mountain areas are cooler than the lower land throughout the year. |
1824488 | 2 - altamente relevante | Learn About the Weather of Jamaica The weather patterns you'll encounter in Jamaica can vary dramatically around the island Regardless of when you visit, the tropical climate and warm temperatures of Jamaica essentially guarantee beautiful weather during your vacation. Average temperatures in Jamaica range between 80 degrees Fahrenheit and 90 degrees Fahrenheit, with July and August being the hottest months and February the coolest. |
4922619 | 2 - altamente relevante | Weather. Jamaica averages about 80 degrees year-round, so climate is less a factor in booking travel than other destinations. The days are warm and the nights are cool. Rain usually falls for short periods in the late afternoon, with sunshine the rest of the day. |
190806 | 2 - altamente relevante | It is always important to know what the weather in Jamaica will be like before you plan and take your vacation. For the most part, the average temperature in Jamaica is between 80 °F and 90 °F (27 °FCelsius-29 °Celsius). Luckily, the weather in Jamaica is always vacation friendly. You will hardly experience long periods of rain fall, and you will become accustomed to weeks upon weeks of sunny weather. |
2613296 | 2 - altamente relevante | Average temperatures in Jamaica range between 80 degrees Fahrenheit and 90 degrees Fahrenheit, with July and August being the hottest months and February the coolest. Temperatures in Jamaica generally vary approximately 10 degrees from summer to winter |
1824486 | 2 - altamente relevante | The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably... |
Como podemos ver para todas as três consultas, o Elasticsearch retornou resultados relevantes na maior parte, e os principais resultados de todas as consultas foram em sua maioria altamente ou perfeitamente relevantes.
Experimentando
O PNL é um recurso poderoso no Elastic Stack, com um roadmap empolgante. Descubra novos recursos e acompanhe os desenvolvimentos mais recentes criando seu cluster no Elastic Cloud. Inscreva-se para fazer uma avaliação gratuita de 14 dias hoje mesmo e teste os exemplos deste post.
Se quiser ler mais sobre PNL:
- How to deploy NLP named entity recognition NER (Como implantar o reconhecimento de entidade nomeada (NER) do PLN)
- How to deploy NLP sentiment analysis (Como implantar a análise de sentimentos do PNL)
- How to deploy natural language processing: Getting started (Como implantar o processamento de linguagem natural: para começar)
Compartilhar
- Share on Twitter
Compartilhar no Twitter
- Share on LinkedIn
Compartilhar no LinkedIn
- Share on Facebook
Compartilhar no Facebook
- Share by Email
Compartilhar por e-mail
- Print this page
Imprimir

