Búsqueda con AI que prioriza la privacidad mediante LangChain y Elasticsearch


 Share on Twitter
Share on TwitterComparte en Twitter

 Share on LinkedIn
Share on LinkedInComparte en LinkedIn

 Share on Facebook
Share on FacebookComparte en Facebook

 Share by Email
Share by EmailComparte por correo electrónico

 Print this page
Print this pageImprime
Dediqué los últimos fines de semana al fascinante mundo de la "ingeniería rápida" y a aprender cómo las bases de datos de vectores, como Elasticsearch®, pueden supercargar modelos de lenguaje grandes (LLM), como ChatGPT, actuando como memoria a largo plazo y un almacén de conocimiento semántico. Sin embargo, algo que me preocupa (al igual que a muchos otros arquitectos de datos experimentados) es que muchos de los tutoriales y las demostraciones disponibles dependen completamente de enviar tus datos privados a grandes empresas web y empresas de AI basadas en el cloud.
Los datos privados son de varios tipos y están protegidos por distintas razones. Las empresas nuevas y autónomas saben que sus datos privados son, a veces, su ventaja competitiva. Los datos internos y datos de clientes con frecuencia contienen información de identificación personal, que tiene consecuencias tanto legales como en el mundo real si no se la protege. En los dominios de observabilidad y seguridad, la falta de precaución en el uso de servicios de terceros puede ser la fuente de filtraciones de datos. Incluso hemos escuchado acusaciones de vulneraciones de ciberseguridad vinculadas al uso de herramientas de chat de AI.
Ningún diseño está libre de riesgos o es completamente privado, incluso al trabajar con empresas como Elastic que se han comprometido seriamente con la privacidad y la seguridad o hacer despliegues en una verdadera brecha de aire. Sin embargo, he trabajado con suficientes casos de uso de datos confidenciales para saber que permitir la búsqueda de AI con un enfoque que priorice la privacidad realmente aporta valor. Me encantó el recorrido excelente de mi colega Jeff Vestal sobre el uso de herramientas de OpenAI con Elasticsearch, pero este artículo tendrá un enfoque diferente.
Tengo dos objetivos para el enfoque de este proyecto:
- Privado: cuando digo privado, lo digo en serio. Si bien usaré Elasticsearch hospedado en el cloud, si el caso de uso lo requiere, quiero que funcione de manera totalmente hermética. Demostremos que podemos hacer que la búsqueda de AI funcione sin enviar nuestro conocimiento privado a terceros.
- Divertido: de paso, divirtámonos un poco mientras lo hacemos. Usaremos un raspado de Wookieepedia, una wiki de Star Wars de la comunidad que es popular para ejercicios de ciencia de datos, y hagamos un asistente para trivia de AI privado. Cuando comencé a escribir este blog, se aproximaba el 4 de mayo, y si bien ya pasó esa fecha ahora que está publicado, soy fanático todo el año.
La forma más fácil de seguir los pasos y probarlo tú mismo es activar una instancia de Elasticsearch en Elastic Cloud y ejecutar en la notebook de Python proporcionada, lo que implementará el proyecto a pequeña escala. Si deseas ejecutar el raspado completo de Wookieepedia, los 180 000 párrafos sobre Star Wars y crear una búsqueda de conocimiento sobre Star Wars completa, puedes seguir el código de este repositorio de GitHub.
Una vez que termines, debería verse así:
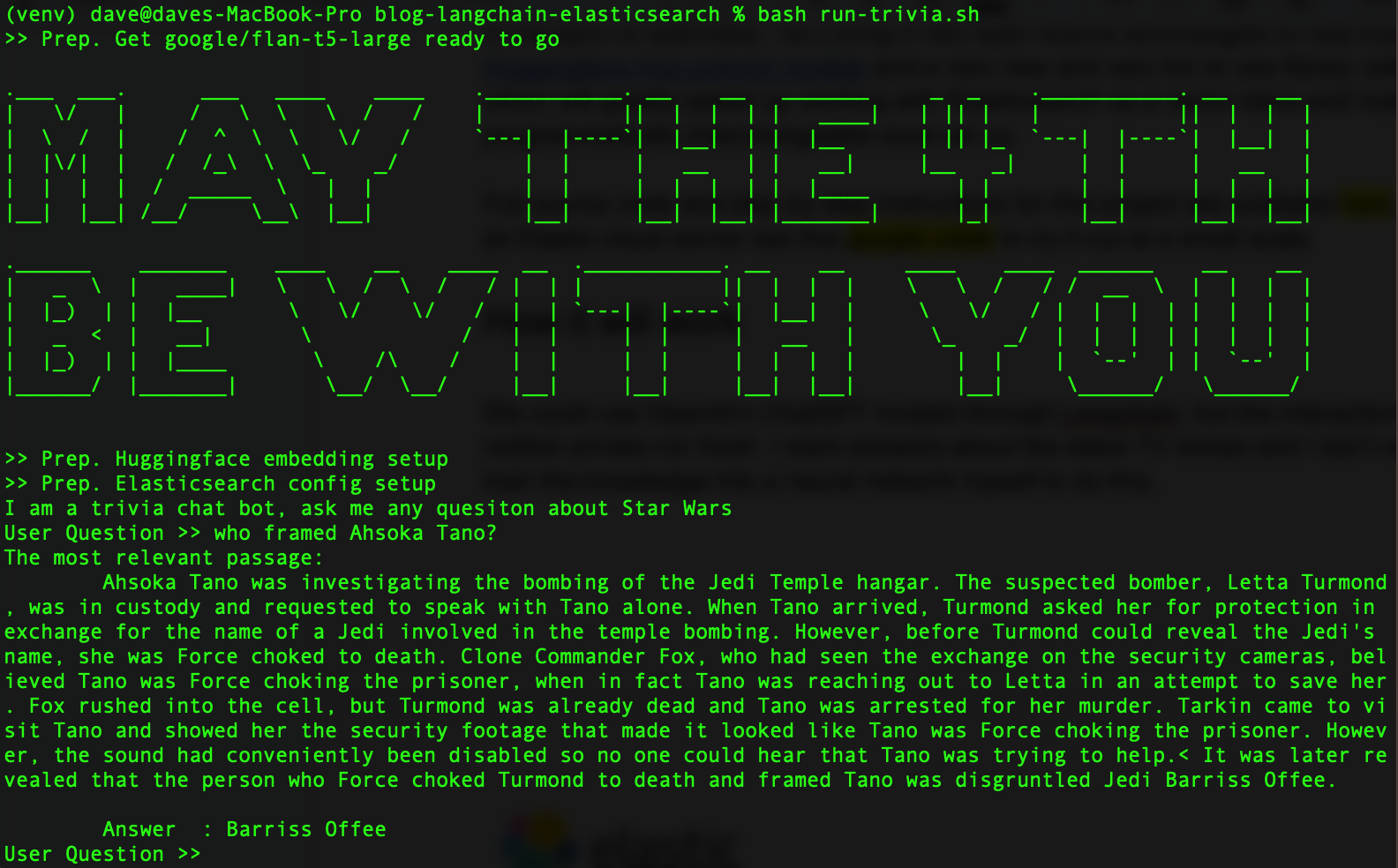
En aras de la apertura, incluyamos dos tecnologías open source para ayudar a Elasticsearch: la biblioteca de transformadores de Hugging Face y la nueva y divertida biblioteca de Python, llamada LangChain, que acelerarán el trabajo con Elasticsearch como una base de datos de vectores. Además, LangChain hará que nuestros LLM sean intercambiables programáticamente una vez que estén configurados, así podremos experimentar con varios modelos.
Cómo funcionará
¿Qué es LangChain? LangChain es un marco de trabajo de Python y JavaScript para desarrollar aplicaciones impulsadas por modelos de lenguaje grandes. LangChain funcionará con API de OpenAI, pero también se destaca en abstraer las diferencias entre las bases de datos y las herramientas de AI.
Por su cuenta, ChatGPT no es malo en la trivia de Star Wars. Sin embargo, su conjunto de datos de entrenamiento ya tiene varios años, y buscamos respuestas sobre los programas de TV y eventos más recientes del universo de Star Wars. Además, recuerda que estamos haciendo de cuenta que estos datos son muy confidenciales como para compartirlos en un LLM grande en el cloud. Podríamos hacer ajustes en un modelo de lenguaje grande nosotros mismos con datos más recientes, pero hay una forma mucho más sencilla de hacerlo que además nos permitirá usar siempre los datos más actuales disponibles.
Hoy, usemos un LLM más pequeño y fácil de hospedar por nuestra cuenta. Obtuve buenos resultados con el modelo flan-t5-large de Google, que compensa la falta de entrenamiento con una buena capacidad para parsear respuestas del contexto insertado. Usaremos la búsqueda semántica para recuperar nuestro conocimiento privado y luego insertar ese contexto con una pregunta en nuestro LLM privado.
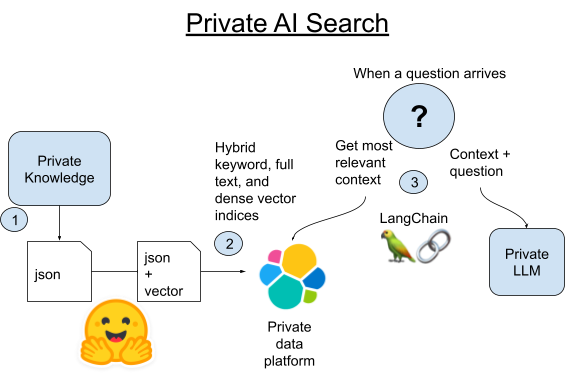
1. Raspa todos los artículos del canon de Wookieepedia poniendo los datos en archivos Pickle de Python preparados.
2A. Carga cada párrafo de esos artículos en Elasticsearch mediante la biblioteca Vectorstore integrada de LangChain.
2B. O bien, podemos comparar LangChain con la nueva forma de hospedar transformadores de pytorch en Elasticsearch en sí. Desplegaremos el modelo de incrustación de texto en Elasticsearch para aprovechar el procesamiento distribuido y acelerar el proceso.
3. Cuando ingresa una pregunta, encontraremos el párrafo más similar semánticamente a la pregunta mediante la búsqueda de vectores de Elasticsearch. Luego tomaremos ese párrafo y lo agregaremos a la línea de comando de un LLM pequeño local a modo de contexto para la pregunta y luego dejaremos que la magia de la AI generativa obtenga una respuesta breve para nuestra pregunta de trivia.
Configuración del entorno de Python y Elasticsearch
Asegúrate de tener Python 3.9 o similar en tu equipo. Uso la versión 3.9 para una compatibilidad de bibliotecas más sencilla con aceleración de GPU, pero no será necesario para este proyecto. Cualquier versión 3.X reciente de Python funcionará.
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install beautifulsoup4 eland elasticsearch huggingface-hub langchain tqdm torch requests sentence_transformersSi descargaste el código de muestra, puedes ver en el código las versiones exactas que usé con el siguiente comando pip install.
pip install -r requirements.txtPuedes configurar un cluster de Elasticsearch con estas instrucciones. La versión de prueba en el cloud gratuita es la forma más sencilla para comenzar.
Crea un archivo .env en la carpeta y carga tus detalles de conexión para Elasticsearch.
export ES_SERVER="YOURDESSERVERNAME.es.us-central1.gcp.cloud.es.io"
export ES_USERNAME="YOUR READ WRITE AND INDEX CREATING USER"
export ES_PASSWORD="YOUR PASSWORD"Paso 1. Raspar los datos
El repositorio de código tiene un pequeño set de datos en Dataset/starwars_small_sample_data.pickle. Puedes omitir este paso si no tienes problema en trabajar a escala pequeña.
El código de raspado está adaptado del excelente blog de ciencia de datos de Dennis Bakhuis y su proyecto; échales un vistazo. Solo extrae el primer párrafo de cada artículo, y yo cambié el código para extraer todo. Quizá él haya tenido que mantener un cierto tamaño de datos que entrara en la memoria principal, pero nosotros no tenemos ese problema porque tenemos Elasticsearch, que permitiría que esto escale en el rango de los petabytes.
También podrías conectar sin problema tu propia fuente de datos privados. LangChain tiene algunas bibliotecas de utilidades excelentes para dividir los datos de texto en fragmentos más breves.
El raspado no es el foco de este artículo, así que echa un vistazo al cuaderno de Python si deseas ejecutarlo por tu cuenta en una menor escala o descarga el código fuente y ejecútalo así:
source .env
python3 step-1A-scrape-urls.py
python3 step-1B-scrape-content.py
Una vez que hayas terminado, deberías poder examinar los archivos Pickle guardados así para asegurarte de que haya funcionado.
from pathlib import Path
import pickle
bookFilePath = "starwars_*_data*.pickle"
files = sorted(Path('./Dataset').glob(bookFilePath))
for fn in files:
with open(fn,'rb') as f:
part = pickle.load(f)
for key, value in part.items():
title = value['title'].strip()
print(title)Si omitiste el raspado web, cambia bookFilePath a "starwars_small_sample_data.pickle" para usar la muestra que incluí en el repositorio de GitHub.
Paso 2A. Cargar incrustaciones en Elasticsearch
El código completo muestra cómo hice esto con solo LangChain. La parte clave del código es hacer un bucle por los archivos Pickle guardados, como en el ejemplo anterior, extraer una lista de cadenas que sean párrafos y luego entregarlas a la función from_texts() de Vectorstore de LangChain.
from langchain.vectorstores import ElasticVectorSearch
from langchain.embeddings import HuggingFaceEmbeddings
from pathlib import Path
import pickle
import os
from tqdm import tqdm
model_name = "sentence-transformers/all-mpnet-base-v2"
hf = HuggingFaceEmbeddings(model_name=model_name)
index_name = "book_wookieepedia_mpnet"
endpoint = os.getenv('ES_SERVER', 'ERROR')
username = os.getenv('ES_USERNAME', 'ERROR')
password = os.getenv('ES_PASSWORD', 'ERROR')
url = f"https://{username}:{password}@{endpoint}:443"
db = ElasticVectorSearch(embedding=hf, elasticsearch_url=url, index_name=index_name)
batchtext = []
bookFilePath = "starwars_*_data*.pickle"
files = sorted(Path('./Dataset').glob(bookFilePath))
for fn in files:
with open(fn,'rb') as f:
part = pickle.load(f)
for ix, (key, value) in tqdm(enumerate(part.items()), total=len(part)):
paragraphs = value['paragraph']
for p in paragraphs:
batchtext.append(p)
db.from_texts(batchtext,
embedding=hf,
elasticsearch_url=url,
index_name=index_name)
Paso 2B. Ahorrar tiempo y dinero con modelos entrenados hospedados
Descubrí que, en mi Intel Macbook anterior, crear incrustaciones requeriría varias horas de procesamiento. Y estoy siendo bueno; parecía que llevaría varios días. Creo que puedo hacerlo más rápido y por menos dinero usando los nodos de machine learning (ML) escalables de forma dinámica del servicio hospedado de Elastic. Los clusters de prueba gratuitos no te permitirán escalar ese nivel, por lo que este paso puede tener más sentido para unos que para otros.
El resultado final: este enfoque demoró 40 minutos en nodos que cuestan USD 5/h para ejecutarse en Elastic Cloud, lo que es mucho más rápido que lo que puedo hacer de forma local y a un costo equiparable al de procesar las incrustaciones con los cargos de token actuales de OpenAI. Hacer esto de forma eficiente es un tema más amplio, pero me impresiona lo rápido que pude poner en marcha un pipeline de inferencia paralelo en Elastic Cloud sin tener que aprender nuevas habilidades o entregar mis datos a una API no privada.
Para este paso, descargaremos la generación de incrustaciones al cluster de Elasticsearch en sí, que puede hospedar el modelo de incrustación e incrustar los párrafos de texto de manera distribuida. Para hacer esto, tendremos que cargar los datos y usar pipelines de ingesta para que la forma final coincida con el mapeo de índice que usa LangChain. Ejecuta el siguiente comando REST en Dev Tools (Herramientas de desarrollo) en Kibana:
PUT /book_wookieepedia_mpnet
{
"settings": {
"number_of_shards": 4
},
"mappings": {
"properties": {
"metadata": {
"type": "object"
},
"text": {
"type": "text"
},
"vector": {
"type": "dense_vector",
"dims": 768
}
}
}
}
A continuación, cargaremos el modelo de incrustación en Elasticsearch mediante la biblioteca de Python eland.
source .env
python3 step-3A-upload-model.pyLuego vayamos a la consola de Elastic Cloud y escalemos nuestro nivel de ML a 64 vCPU totales (8 veces el poder de mi computadora portátil actual).
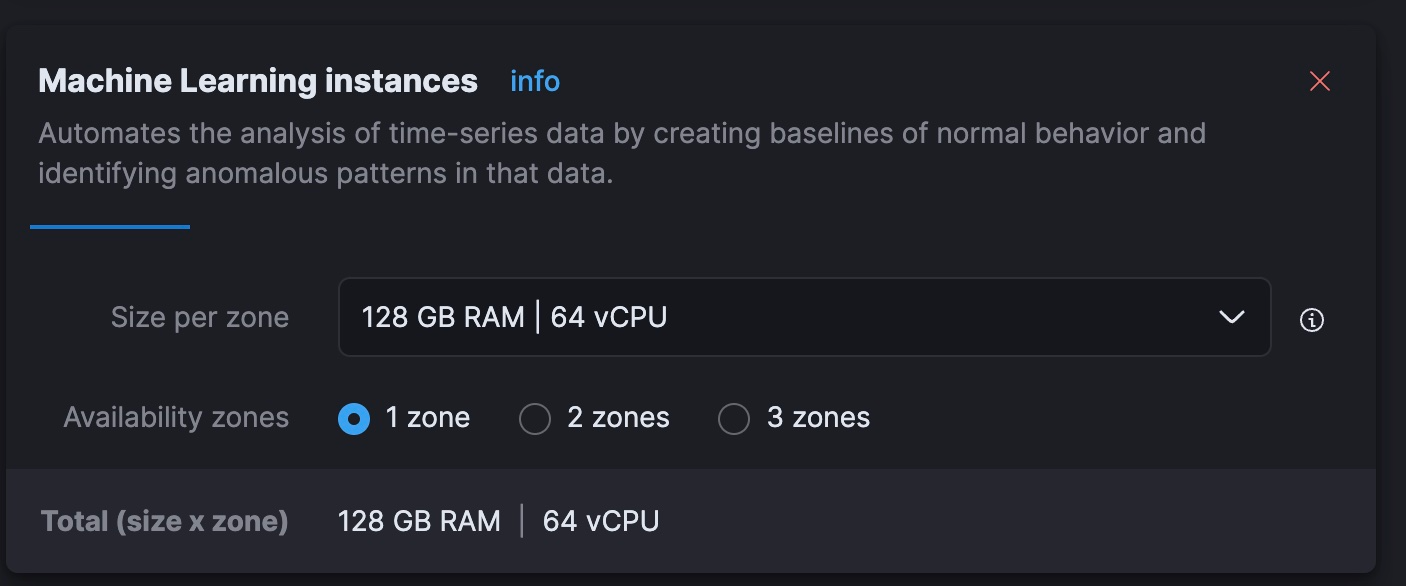
Ahora, en Kibana, desplegaremos el modelo de ML entrenado. A escala, las pruebas de rendimiento han demostrado que los usuarios deberían comenzar con 1 thread por asignación de modelo y aumentar la cantidad de asignaciones para aumentar el rendimiento. La documentación y orientación se puede encontrar aquí. Experimenté y, para este set más pequeño, obtuve los mejores resultados con 32 instancias en 2 threads cada una. Para configurar esto, ve a Stack Management (Gestión de la pila) > Machine Learning. Usa la característica Synchronize saved objects (Sincronizar objetos guardados) para que Kibana vea el modelo que enviamos a Elasticsearch con el código de Python. Luego despliega el modelo en el menú que se abre al hacer clic en él.

Ahora volvamos a usar Dev Tools (Herramientas de desarrollo) para crear un nuevo índice y pipeline de ingesta que procese el párrafo de texto en un documento, ponga el resultado en un campo de vector denso llamado "vector" y copie el párrafo en el campo "text" esperado.
PUT /book_wookieepedia_mpnet
{
"settings": {
"number_of_shards": 4
},
"mappings": {
"properties": {
"metadata": {
"type": "object"
},
"text": {
"type": "text"
},
"vector": {
"type": "dense_vector",
"dims": 768
}
}
}
}
PUT _ingest/pipeline/sw-embeddings
{
"description": "Text embedding pipeline",
"processors": [
{
"inference": {
"model_id": "sentence-transformers__all-mpnet-base-v2",
"target_field": "text_embedding",
"field_map": {
"text": "text_field"
}
}
},
{
"set":{
"field": "vector",
"copy_from": "text_embedding.predicted_value"
}
},
{
"remove": {
"field": "text_embedding"
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
Prueba el pipeline para asegurarte de que funcione.
POST _ingest/pipeline/sw-embeddings/_simulate
{
"docs": [
{
"_source": {
"text": "Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.",
"metadata": {
"a": "b"
}
}
}
]
}
Ahora estamos listos para cargar en batches los datos usando la biblioteca de Python normal para Elasticsearch, fijando como objetivo nuestro pipeline de ingesta para crear correctamente la incrustación de vectores y transformar los datos a fin de que coincidan con las expectativas de LangChain.
source .env
python3 step-3B-batch-hosted-vectorize.py¡Felicitaciones! Los datos tienen aproximadamente 13 millones de tokens, en términos de OpenAI, por lo que generar estos vectores en un servicio en el cloud de OpenAI o equivalente costaría aproximadamente USD 5.40. Con Elastic Cloud, les tomó 40 minutos a las máquinas que cuestan USD 5/h.
Con los datos cargados, recuerda escalar tu ML de Cloud de nuevo a cero o algo más razonable mediante la consola del cloud.
Paso 3. Ganar en la trivia de Star Wars
A continuación, juguemos con el LLM y LangChain. Creé el archivo de biblioteca lib_llm.py para tener este código.
from langchain import PromptTemplate, HuggingFaceHub, LLMChain
from langchain.llms import HuggingFacePipeline
from transformers import AutoTokenizer, pipeline, AutoModelForSeq2SeqLM
from langchain.vectorstores import ElasticVectorSearch
from langchain.embeddings import HuggingFaceEmbeddings
import os
cache_dir = "./cache"
def getFlanLarge():
model_id = 'google/flan-t5-large'
print(f">> Prep. Get {model_id} ready to go")
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(model_id, cache_dir=cache_dir)
pipe = pipeline(
"text2text-generation",
model=model,
tokenizer=tokenizer,
max_length=100
)
llm = HuggingFacePipeline(pipeline=pipe)
return llm
local_llm = getFlanLarge()
def make_the_llm():
template_informed = """
I am a helpful AI that answers questions.
When I don't know the answer I say I don't know.
I know context: {context}
when asked: {question}
my response using only information in the context is: """
prompt_informed = PromptTemplate(
template=template_informed,
input_variables=["context", "question"])
return LLMChain(prompt=prompt_informed, llm=local_llm)
## continued below
template_informed es la parte esencial, pero también fácil de comprender, de esto. Todo lo que hacemos es dar formato a una plantilla de línea de comando, que tomará nuestros dos parámetros: el contexto y la pregunta del usuario.
Con este código principal final que continúa de lo anterior, se ve de la siguiente forma:
## continued from above
topic = "Star Wars"
index_name = "book_wookieepedia_mpnet"
# Create the HuggingFace Transformer like before
model_name = "sentence-transformers/all-mpnet-base-v2"
hf = HuggingFaceEmbeddings(model_name=model_name)
## Elasticsearch as a vector db, just like before
endpoint = os.getenv('ES_SERVER', 'ERROR')
username = os.getenv('ES_USERNAME', 'ERROR')
password = os.getenv('ES_PASSWORD', 'ERROR')
url = f"https://{username}:{password}@{endpoint}:443"
db = ElasticVectorSearch(embedding=hf, elasticsearch_url=url, index_name=index_name)
## set up the conversational LLM
llm_chain_informed= make_the_llm()
def ask_a_question(question):
## get the relevant chunk from Elasticsearch for a question
similar_docs = db.similarity_search(question)
print(f'The most relevant passage: \n\t{similar_docs[0].page_content}')
informed_context= similar_docs[0].page_content
informed_response = llm_chain_informed.run(
context=informed_context,
question=question)
return informed_response
# The conversational loop
print(f'I am a trivia chat bot, ask me any question about {topic}')
while True:
command = input("User Question >> ")
response= ask_a_question(command)
print(f"\tAnswer : {response}")
Conclusión
Luego de lidiar un poco con los datos, ahora usamos AI sin exponer los datos a un LLM hospedado de terceros. El mundo de la AI cambia rápido, pero preservar la seguridad y el control de los datos privados es algo que todos deberíamos tomar en serio debido a las consecuencias normativas, financieras y humanas de las filtraciones de datos. Es poco probable que eso cambie. Trabajamos con clientes que usan la búsqueda para investigar el fraude, defender su nación y mejorar los resultados en comunidades de pacientes vulnerables. La privacidad es importante. Para conocer más sobre cómo Elastic se usa en estas áreas, echa un vistazo a lo siguiente:
¿Te encanta LangChain tanto como a mí? Como un sabio Jedi dijo una vez: "Eso está bien. Has dado tu primer paso hacia un mundo sin límites". A partir de aquí, se puede ir en muchas direcciones. LangChain elimina la complejidad de trabajar con la ingeniería rápida de la AI. Sé que Elasticsearch tiene muchos otros roles aquí, como memoria a largo plazo para la AI generativa, así que me entusiasma mucho ver qué surge a partir de este espacio que cambia tan rápidamente.
En este blog, es posible que hayamos usado herramientas de AI generativa de terceros, que son propiedad de sus respectivos propietarios y operadas por estos. Elastic no tiene ningún control sobre las herramientas de terceros, y no somos responsables de su contenido, funcionamiento o uso, ni de ninguna pérdida o daño que pueda resultar del uso de dichas herramientas. Ten cautela al usar herramientas de AI con información personal o confidencial. Cualquier dato que envíes puede ser utilizado para el entrenamiento de AI u otros fines. No hay garantías de que la información que proporciones se mantenga segura o confidencial. Deberías familiarizarte con las prácticas de privacidad y los términos de uso de cualquier herramienta de AI generativa previo a su uso.
Elastic, Elasticsearch y las marcas asociadas son marcas comerciales, logotipos o marcas comerciales registradas de Elasticsearch N.V. en los Estados Unidos y otros países. Todos los demás nombres de empresas y productos son marcas comerciales, logotipos o marcas comerciales registradas de sus respectivos propietarios.
Comparte
- Share on Twitter
Comparte en Twitter
- Share on LinkedIn
Comparte en LinkedIn
- Share on Facebook
Comparte en Facebook
- Share by Email
Comparte por correo electrónico
- Print this page
Imprime

