Prometheus-Monitoring in großen Deployments mit dem Elastic Stack
Tools. Was wären wir Engineers ohne sie, die tollen Tools, die unseren Teams dabei helfen, produktiv zu arbeiten, Probleme schneller zu lösen und immer besser zu werden?! Aber es werden immer mehr, sie erfordern zusätzlichen Wartungsaufwand – und sie führen zu Silos. Jedes Team hat seine eigenen Aufgaben und ist ständig auf der Suche nach Tools, mit denen sich die ganz speziellen Anforderungen dieses Teams am besten lösen lassen. Diese Autonomie bei der Wahl der Mittel führt dazu, dass die Teams für sich genommen immer effizienter werden. Auf der anderen Seite geht dadurch der Blick auf die anderen Teile der Organisation verloren. Wenn man dies mit der schieren Zahl von Teams multipliziert, wird einem schnell klar, dass hier isolierte Cluster entstehen, die das ganze Gegenteil einer ganzheitlichen Sicht auf das Geschäft darstellen.
Prometheus ist ein gutes Beispiel für so ein Tool. Es hat sich schnell zu dem Tool für Monitoring- und Alerting-Zwecke im Zusammenhang mit Container-Systemen entwickelt. Seine Hauptstärke ist das effiziente Überwachen und Speichern serverseitiger Metriken. Das Tool ist uneingeschränkt Open Source und hat eine lebhafte Community um sich geschart, die seine Reichweite in Form von Exportern auf viele Drittanbietersysteme ausgedehnt hat. Wie die meisten Spezial-Tools ist Prometheus so konstruiert, dass es besonders einfach und benutzerfreundlich ist. Diese Einfachheit erfordert Kompromisse, was sich besonders bei großen Deployments und bei der teamübergreifenden Zusammenarbeit bemerkbar macht. In diesem Blogpost beschäftigen wir uns mit einigen dieser Kompromisse und sehen uns an, wie Elastic Stack dazu beitragen kann, deren Auswirkungen möglichst gering zu halten.
Langfristige Datenaufbewahrung
Prometheus speichert Daten lokal in der Instanz. Dass Rechen- und Datenspeicher auf einem Knoten residieren, mag die Bedienung erleichtern, wirkt sich aber auch negativ auf die Skalierbarkeit und die Sicherstellung einer hohen Verfügbarkeit aus. Das bedeutet, dass Prometheus nicht wirklich für die langfristige Speicherung von Metriken optimiert ist. Je nach Größe Ihrer Umgebung kann die optimale Aufbewahrungsdauer für Zeitreihen in Prometheus bei gerade einmal ein paar Tagen oder sogar nur Stunden liegen.
Wenn es darum geht, Prometheus-Daten für eine erweiterte Analyse (z. B. zur Ermittlung der Saisonalität von Zeitreihen) skalierbar und langfristig aufzubewahren, muss Prometheus um eine Lösung für die Langzeitspeicherung von Daten ergänzt werden. Die Auswahl an Lösungen dafür ist groß; infrage kommen u. a. andere spezialisierte TSDBs oder für Zeitreihen optimierte Datenbanken im Spaltenformat. Alle diese Lösungen, so effizient sie auch für ihren Einsatzzweck sein mögen, haben einen Nachteil: Sie sind ausschließlich auf einen Datentyp spezialisiert – Metriken. Metriken sind zwar für das Verständnis des Systemverhaltens von immenser Bedeutung, aber es gibt auch noch andere Komponenten, die die Observability von Systemen ausmachen.
Wenn Nutzer Observability-Überlegungen anstellen, versuchen sie, Metriken mit anderen Typen operationaler Daten, wie Logdaten und Traces, zu kombinieren. In unserem Blogpost zur Observability im Elastic Stack verweisen wir auf die steigende Zahl von Anwendungsfällen, in denen Nutzer, die den Elastic Stack ursprünglich für ihre Logdaten eingesetzt haben, inzwischen auch Metriken, Traces und Uptime-Daten in Elasticsearch ingestieren. Das ist auch nicht weiter verwunderlich, denn Elasticsearch behandelt jeden einzelnen Datentyp einfach wie einen weiteren Index und erlaubt es Ihnen, alle Ihre operationalen Daten so zu aggregieren, korrelieren, analysieren und visualisieren, wie Sie es wünschen. Durch Features wie Daten-Rollups in Elastic können historische Zeitreihendaten zu einem Bruchteil der Speicherkosten von Rohdaten gespeichert werden.
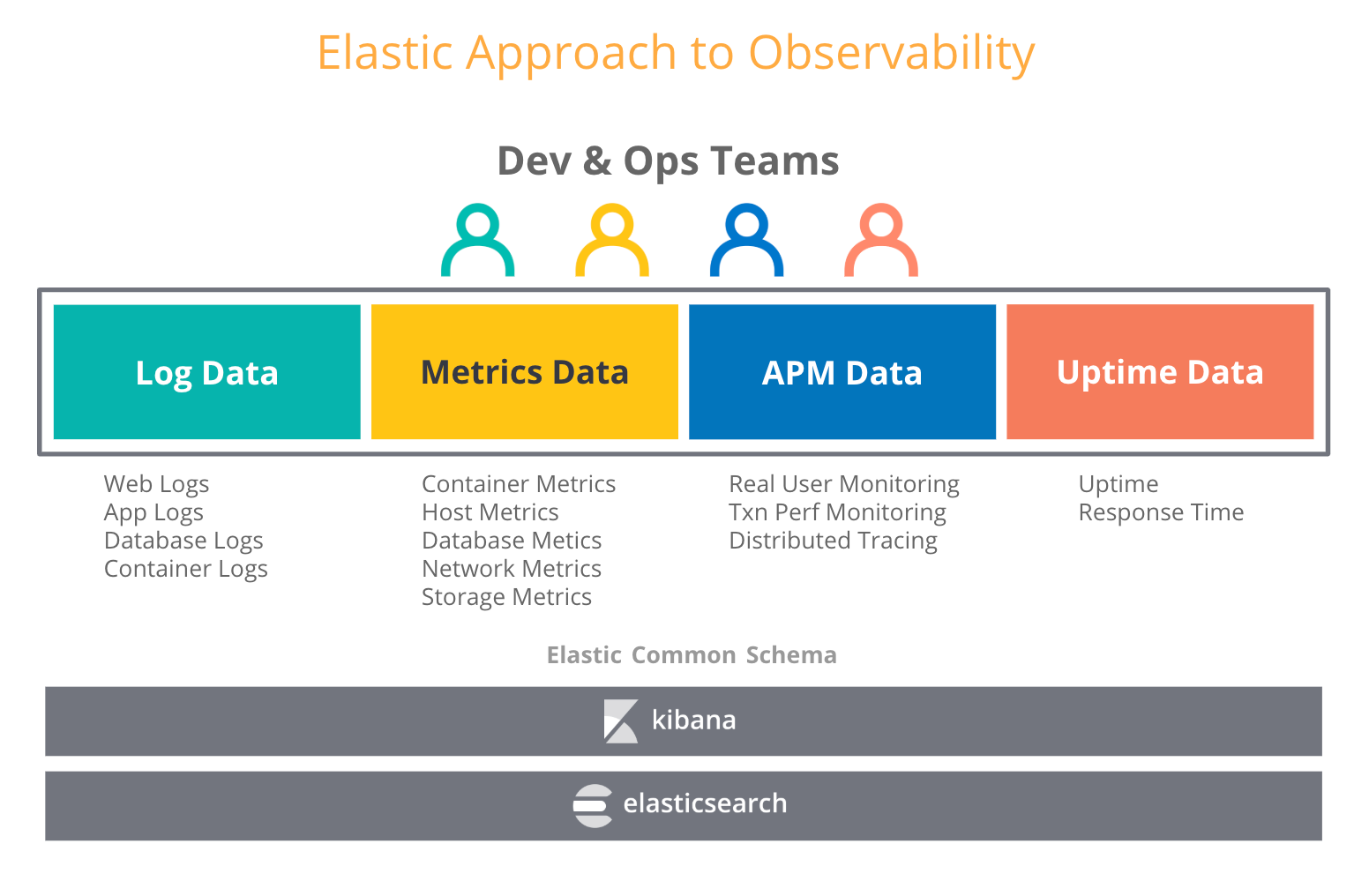
Was bedeutet das nun für die Auswahl einer langfristigen Speichermöglichkeit für Prometheus? Um längere Aufbewahrungsdauern für Ihre Prometheus-Metriken zu erzielen, können Sie einen dedizierten Metrikenspeicher wählen, schaffen dadurch aber potenziell einen weiteren Silo. Oder Sie können mit dem Elastic Stack das Beste aus beiden Welten zusammenbringen, indem Sie an der Peripherie Prometheus einsetzen, während Sie Ihre Metriken zusammen mit Ihren anderen operationalen Daten in einem skalierbaren, zentralisierten Elasticsearch-Deployment aufbewahren – so lange Sie wollen. So erhalten Sie langfristige Aufbewahrung und mehr Observability.
Zentralisierte globale Ansicht für Prometheus-Daten
In einem Produktions-Setup müssen Sie sich wahrscheinlich um mehrere Kubernetes-Cluster kümmern. Auf jedem Cluster laufen eine oder mehrere Prometheus-Instanzen, die Einblick in den Zustand von Knoten, Pods, Diensten und Endpunkten haben. Fehlt da etwas?
Jede Prometheus-Instanz kann eine Teilmenge der Ressourcen in Ihrer Umgebung abdecken. Wenn Sie eine Frage haben, zu deren Beantwortung Metriken von mehreren Clustern abgefragt werden müssen, lässt sich das in Prometheus nur über Umwege erreichen.

Die Nutzung von Elastic als zentralisiertem Speicher kann dabei helfen, Daten aus Hunderten von Prometheus-Instanzen zu konsolidieren und so eine globale Ansicht der Daten aus allen Ressourcen zu erhalten. Das Prometheus-Modul für Metricbeat kann automatisch Metriken aus Prometheus-Instanzen holen und Gateways, Exporter und so ziemlich jeden anderen Dienst pushen, der das Expositionsformat von Prometheus unterstützt. Und dazu müssen Sie in Ihrer Produktionsumgebung rein gar nichts tun – Plug-&-Play at its best.
Dimensionen mit hoher Kardinalität
Weshalb ist „hohe Kardinalität“ so wichtig? Hohe Kardinalität ermöglicht es Ihnen, Ihre Metriken mithilfe von Tags oder Labels mit arbiträrem Kontext zu versehen. In den meisten Fällen empfiehlt es sich, diese Metadaten zu erhalten, da sie beim Debugging Ihrer Dienste unschätzbare Dienste erweisen können. All diese Trace-IDs, Anforderungs-IDs, Container-IDs, Versionsnummern usw. verraten Ihnen stets mehr darüber, was in Ihren Systemen vor sich geht.

Die Stärke reiner TSDBs sind Dimensionen mit geringer Kardinalität. Die angeblich höhere Speichereffizienz spezialisierter TSDBs im Vergleich zu Elasticsearch lässt sich im Wesentlichen bei Dimensionen mit geringer Kardinalität realisieren. Nicht umsonst wird in der Prometheus-Dokumentation ausdrücklich von Daten mit hoher Kardinalität abgeraten:
ACHTUNG: Zur Erinnerung: Jede eindeutige Kombination aus Schlüssel/Wert-Label-Paaren stellt eine neue Zeitreihe dar, wodurch sich die Menge der gespeicherten Daten drastisch erhöhen kann. Verwenden Sie Label nicht zum Speichern von Dimensionen mit hoher Kardinalität (viele unterschiedliche Label-Werte), wie Benutzer-IDs, E‑Mail-Adressen oder anderen unbegrenzten Gruppen von Werten.
Ist das ein guter Ratschlag? In verteilten Umgebungen ist das Debugging eine hochkomplexe Angelegenheit. Bei den Monolithen der Vergangenheit reichte es, beim Debugging einfach den Anwendungscode Schritt für Schritt durchzugehen. So ließ sich problemlos mit ein paar Dashboards herausfinden, welches Monolithenmodul für das Problem verantwortlich war. Diese Zeiten sind vorbei. Die Infrastruktur-Software befindet sich mitten in einem Paradigmenwechsel. Container, Orchestrierer, Microservices, Service-Meshes, serverlose Systeme und Lambdas sind allesamt äußerst vielversprechende Technologien, die das Entwickeln und Bedienen von Software von Grund auf ändern. Das macht Software immer verteilter und das Debugging dieser Software wird zu einer detektivischen Suche nach der Stelle im Systemcode, die das Problem verursacht.
Für Elastic ist hohe Kardinalität kein Problem. Elastic ist so konzipiert, dass nichts Nutzer daran hindern soll, ihren Daten relevanten Kontext hinzuzufügen. Dank seiner Indexierungsfunktionen können Elasticsearch-Nutzer ihre Metriken flexibel mit allen Metadaten versehen, die bei der Suche nach Problemfaktoren helfen können, um schnellstmöglich die Ursache des Problems zu finden.
Jederzeit und überall sicher
Das Mindeste, was von einem guten Tool erwartet wird, ist, dass es unseren Umgebungen keine Sicherheitsrisiken beschert. Zwei der wichtigsten Bausteine für Sicherheit in verteilten Umgebungen sind die Verschlüsselung der Kommunikation und die Zugriffssteuerung.
Aktuell bieten der Prometheus-Server, Alertmanager und die offiziellen Exporter keine TLS-Verschlüsselung der HTTP-Endpunkte. Für eine sichere Bereitstellung dieser Komponenten müssen Sie einen Reverse Proxy wie nginx nutzen und die TLS-Verschlüsselung auf Proxy-Ebene anwenden. Auch die rollenbasierte Steuerung des Zugriffs (Role-Based Access Control – RBAC) auf Metriken sollte nicht dem Prometheus-Server überlassen, sondern extern verwaltet werden. Wird Prometheus aber in einem Kubernetes-Cluster ausgeführt, sind TLS und RBAC kein Problem mehr, denn beide Technologien werden dort unterstützt. In allen anderen Fällen (z. B. bei Hunderten von Prometheus-Servern in geografisch verteilten oder hybriden Deployments) ist die Bewältigung dieser Sicherheitsprobleme mit Drittanbieter-Tools alles andere als einfach.
Wir bei Elastic nehmen solche Risiken sehr ernst und machen Security zu einem integralen Bestandteil unseres Stacks. Unsere Standarddistribution stellt grundlegende Security-Optionen kostenlos bereit, und Elasticsearch bietet mehrere Möglichkeiten, den Zugriff auf Ihre Daten in einem Cluster abzusichern sowie den Datenverkehr zwischen Cluster und Daten-Shippern zu verschlüsseln. Zusätzlich zu RBAC unterstützt Elasticsearch die detaillierte attributbasierte Zugriffssteuerung (Attribute-Based Access Control – ABAC), mit der Sie den Zugriff auf Dokumente in Suchabfragen und Aggregationen einschränken können. Mit den SSL-Konfigurationseinstellungen in Metricbeat können Sie dafür sorgen, dass Ihre operationalen Daten sicher unterwegs sind, egal, wie groß und verteilt Ihre Umgebungen sein mögen.
Streamen von Prometheus-Metriken an Elasticsearch
Mit Metricbeat können Sie jetzt schon mit dem Streamen von Metriken von Prometheus an Elasticsearch beginnen. Über das Prometheus-Modul lassen sich Metriken auf verschiedene Art und Weise von Prometheus-Servern, Exportern oder Push-Gateways sammeln:
- Wenn Sie schon einen Prometheus-Server zu laufen haben und diese Metriken direkt abfragen möchten, können Sie als Erstes eine Verbindung zum Prometheus-Server herstellen und entweder den Endpunkt
/metricsoder die Prometheus Federation API nutzen, um bereits erfasste Metriken abzurufen.
- Haben Sie keinen Prometheus-Server oder stört es Sie nicht weiter, für das parallele Sammeln von Daten von Ihren Exportern und Push-Gateways mehrere Tools einsetzen zu müssen, können Sie sich direkt mit ihnen verbinden.

Lassen Sie Metricbeat so nah wie möglich bei Ihrem Prometheus-Server laufen. In unserem Blogpost zu Prometheus und Open Standards werden verschiedene Konfigurationen beschrieben, aus denen Sie sich eine geeignete aussuchen können.
Überwachung des Zustands der Prometheus-Server
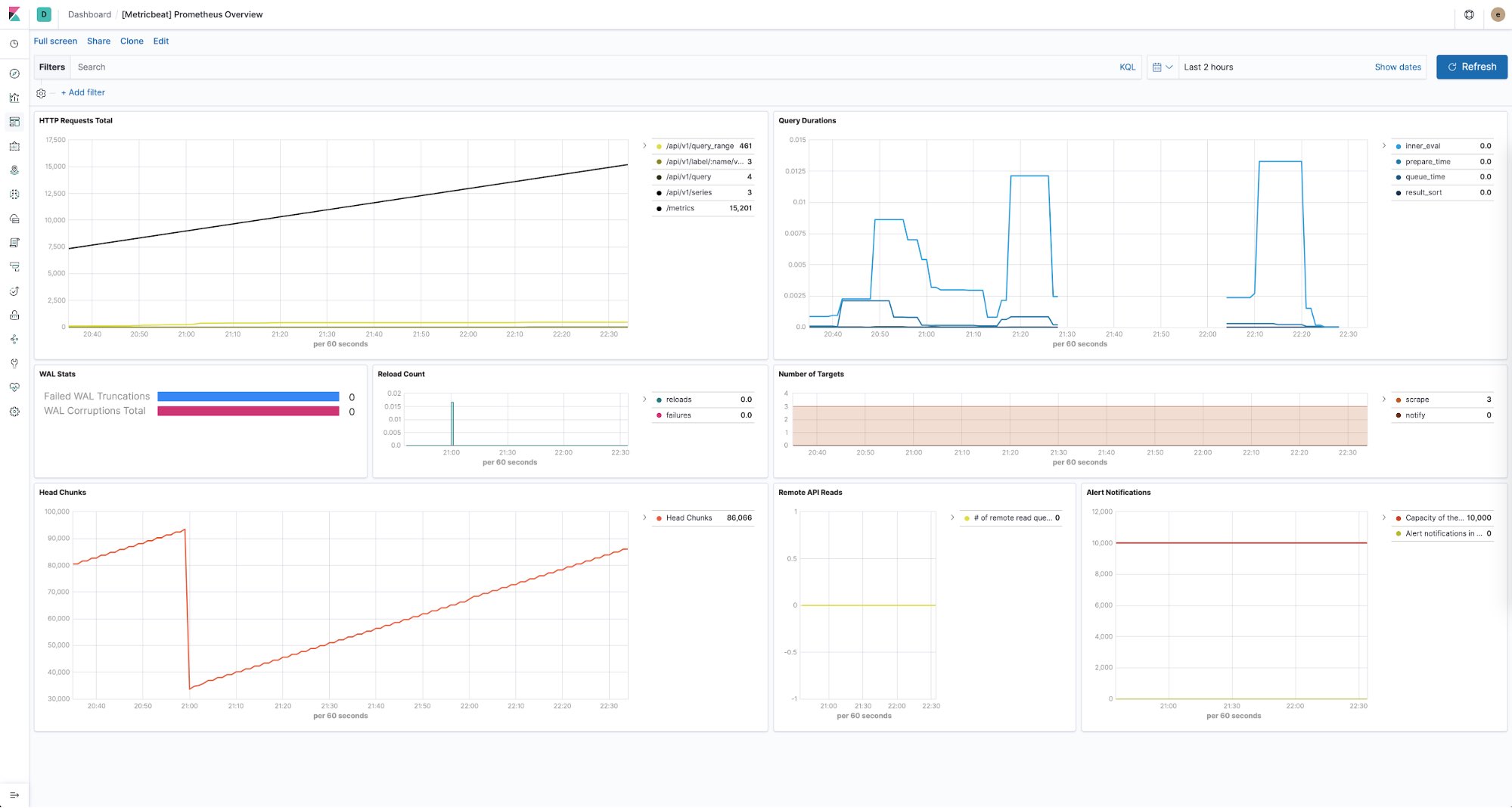
Der Elastic Stack bietet auch die Möglichkeit, den Zustand aller Ihrer Prometheus-Instanzen im Blick zu behalten. Sie können Metricbeat nutzen, um Performance-Metriken von den einzelnen Prometheus-Servern in Ihren Umgebungen zu sammeln und sie zu speichern. Vordefinierte Dashboards, die ohne weitere Konfiguration sofort einsatzbereit sind, geben Aufschluss über die Zahl der HTTP-Anforderungen pro Endpunkt, die Abfragedauer, die Zahl der gefundenen Ziele und vieles andere mehr.
An alles gedacht
Was am Ende für Sie, Ihr Team und das gesamte Unternehmen zählt, ist der Erfolg. Alle Tools sollten als Hilfsmittel betrachtet werden, dieses Ziel zu erreichen, und jedes Team sollte die Möglichkeit haben, frei zu entscheiden, welche Tools ihm dabei helfen, das vorhandene Potenzial voll auszuschöpfen. Und wenn es darum geht, operationale Silos abzubauen, sind wir überzeugt, dass der Elastic Stack Ihnen dabei helfen kann, die ultimative Observability-Plattform aufzubauen – eine Plattform, über die jeder im Unternehmen sicher auf operationale Daten zugreifen, mit ihnen interagieren und so zum Erfolg des gesamten Unternehmens beitragen kann.
Wenn Sie mehr darüber erfahren möchten, wie wir mit Zeitreihendaten arbeiten, besuchen Sie unsere Elastic Metrics-Webseite. Probieren Sie das Streamen Ihrer Metriken nach Elasticsearch Service aus – einfacher und schneller wird es nicht. Falls Sie Fragen haben, empfehlen wir Ihnen wie immer unsere Diskussionsforen.