Nutzung von Machine-Learning-Modellen in Elastic


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Elastic unterstützt die für Sie idealen Machine-Learning-Modelle
Mit Elastic® nutzen Sie die je nach Anwendungsfall und Vorerfahrung mit Machine Learning (ML) für Sie optimalen Modelle. Sie haben mehrere Optionen:
- Nutzen Sie die integrierten Modelle. Neben unseren Modellen für spezifische Sicherheitsbedrohungen und Arten von Systemproblemen in unserer Observability- und Security-Lösung können Sie auch unser hauseigenes Elastic Learned Sparse Encoder-Modell ohne Anpassungen nutzen sowie Spracherkennung verwenden. Das ist nützlich, wenn Ihre Textdaten nicht in englischer Sprache vorliegen.
- Sie können PyTorch-Modelle von Drittanbietern von überall abrufen, einschließlich des HuggingFace Model Hub.
- Laden Sie ein Modell, das Sie selbst trainiert haben – derzeit vornehmlich NLP-Transformatoren.
Mit den integrierten Modellen können Sie gleich ohne Vorwissen bei ML loslegen, genießen aber dennoch die Flexibilität, unterschiedliche Modelle ausprobieren und ermitteln zu können, welches mit Ihren Daten optimale Leistungen erzielt
Unsere Modellverwaltung ist auf Skalierbarkeit über mehrere Knoten in einem Cluster ausgelegt, wobei gleichzeitig eine gute Inferenzleistung für Workloads mit hohem Durchsatz ebenso wie solchem mit geringer Latenz gewährleistet bleibt. Das wird zum Teil durch die Nutzung von Ingestionspipelines für die Inferenz und von dedizierten Knoten für die rechenintensive Modellinferenz sowohl während der Ingestionsphase als auch bei Datenanalyse und Suche ermöglicht.
Erfahren Sie hier mehr über die Eland-Bibliothek, mit der Sie Modelle in Elastic laden können, und über die Möglichkeiten, die Sie damit hinsichtlich der unterschiedlichen Arten von Machine Learning haben, die Sie mit Elasticsearch® nutzen können: von den aktuellen Transformations- und NLP-Modellen (Natural Language Processing, Verarbeitung natürlicher Sprache) bis hin zu Boosted-Tree-Modellen für die Regression.
Mit Eland ML-Modelle in Elastic laden
Unsere Eland-Bibliothek bietet eine benutzerfreundliche Oberfläche zum Laden von mit PyTorch trainierten ML-Modellen in Elasticsearch. Unter Verwendung der nativen Bibliothek libtorch und der Erwartung von Modellen, die als TorchScript-Repräsentation exportiert oder gespeichert wurden, werden mit Elasticsearch Python-Interpreter bei der Modellinferenz überflüssig.
Durch die Integration mit einem der gängigsten Formate für das Erstellen von NLP-Modellen in PyTorch kann Elasticsearch eine Plattform bereitstellen, die mit einer Vielzahl von NLP-Aufgaben und ‑Anwendungsfällen funktioniert. Im nachfolgenden Abschnitt zu Transformern gehen wir darauf näher ein.
Sie können Eland auf drei Arten zum Hochladen eines Modells verwenden: via Befehlszeile, Docker und über Ihren eigenen Python-Code. Docker ist weniger komplex, weil dafür keine lokale Installation von Eland und all seinen Abhängigkeiten erforderlich ist. Nachdem Sie auf Eland zugreifen können, können Sie mit folgendem Beispielcode ein DistilBERT NER-Modell hochladen:

Weiter unten sehen wir uns die einzelnen Argumente von eland_import_hub_model an. Sie können denselben Befehl auch über einen Docker-Container ausführen.
Nach dem Upload können Sie über die ML Model Management-Benutzeroberfläche von Kibana die Modelle auf einem Elasticsearch Cluster verwalten. Dazu gehören die Erhöhung von Zuweisungen für höheren Durchsatz und das Anhalten/Fortsetzen von Modellen während der (Neu-)Konfiguration Ihres Systems.
Welche Modelle werden unterstützt?
Elastic unterstützt verschiedenste Transformationsmodelle sowie die beliebtesten Bibliotheken für Supervised Learning:
- NLP und Einbettungsmodelle: Alle Transformationsmodelle, die der standardmäßigen BERT-Modellschnittstelle entsprechen und den WordPiece-Tokenisierungsalgorithmus verwenden. Hier finden Sie eine vollständige Liste aller unterstützen Modellarchitekturen.
- Supervised Learning: Trainierte Modelle von scikit-learn, XGBoost und LightGBM Bibliotheken zur Serialisierung und Nutzung als Inferenzmodell in Elasticsearch. In unserer Dokumentation finden Sie ein Beispiel für das Training eines XGBoost classify anhand von Daten in Elastic. Sie können mit unseren Datenframe-Analytics auch in Elastic trainierte überwachte Modelle exportieren und importieren.
- Generative KI: Sie können die für das LLM bereitgestellte API verwenden, um Abfragen einzugeben – diese können auch um Kontext aus Elastic erweitert sein – und die ausgegebenen Ergebnisse zu verarbeiten. Weitere Anweisungen erhalten Sie in diesem Blogpost, der einen Link zu einem GitHub-Repository mit Beispielcode für die Kommunikation über die API von ChatGPT enthält.
Nachstehend finden Sie weitere Einzelheiten zu der Art Modell, die Sie im Kontext von Suchanwendungen am wahrscheinlichsten verwenden: NLP-Transformer.
Anwendung von Transformern und NLP in Elastic – einfach gemacht!
Hier erfahren Sie die Schritte, mit denen Sie ein NLP-Modell laden und verwenden können, beispielsweise ein beliebtes NER-Modell von Hugging Face. Dazu verwenden wir die Argumente im Code-Ausschnitt unten.

- Geben Sie die Elastic Cloud-Kennung an. Verwenden Sie alternativ --url.
- Geben Sie die Authentifizierungsdaten für den Zugriff auf Ihren Cluster an. Sie können verfügbare Authentifizierungsmethoden nachschlagen.
- Geben Sie die Kennung für das Modell im Hugging Face Model Hub an.
- Geben Sie die Art der NLP-Aufgabe an. Unterstützte Werte sind fill_mask, ner, text_classification, text_embedding und zero_shot_classification.
Nachdem Sie das Modell geladen haben, müssen Sie es als Nächstes bereitstellen. Dazu nutzen Sie den Bildschirm Model Management des Reiters Machine Learning in Kibana. Dann folgt üblicherweise ein Test des Modells, um sicherzustellen, dass es wie vorgesehen funktioniert.
Nun können Sie das bereitgestellte Modell für die Inferenz verwenden. Um zum Beispiel benannte Entitäten zu extrahieren, rufen Sie den Endpoint _infer auf dem geladenen NER-Modell auf:
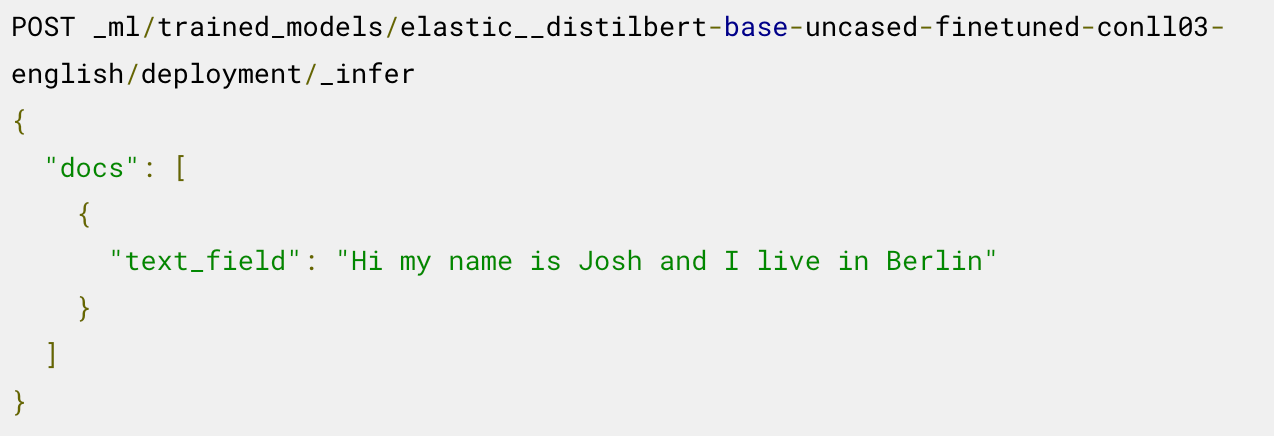
Das Modell hat zwei Entitäten identifiziert: die Person „Josh“ und den Ort „Berlin“.

Für weitere Schritte wie die Verwendung dieses Modells in einer Inferenzpipeline und die Feinabstimmung der Bereitstellung lesen Sie den Blogpost, der dieses Beispiel beschreibt.
Möchten Sie erfahren, wie Sie eine semantische Suche anwenden – wie Sie beispielsweise Einbettungen für Text erstellen und über eine Vektorsuche ähnliche Dokumente finden? Dieser Blogpost führt Sie Schritt für Schritt durch das Verfahren und beschreibt auch die Validierung der Modellleistung.
Sie sind sich nicht sicher, welche Aufgabe für welches Modell geeignet ist? Diese Tabelle bietet einen guten Startpunkt.
Hugging Face Modell | task-type |
|---|---|
Erkennung benannter Entitäten (Named Entity Recognition, NER) | ner |
text_embedding | |
text_classification | |
zero_shot_classification | |
| Beantwortung von Fragen | question_answering |
Elastic unterstützt zudem Vergleiche der Ähnlichkeit von zwei Texten mit dem Aufgabentyp text_similarity. Dies ist nützlich für die Bewertung des Texts eines Dokuments beim Vergleich mit einer anderen bereitgestellten Texteingabe und wird manchmal als Cross-Encoding bezeichnet.
Mehr Details finden Sie in diesen Ressourcen
- Unterstützung für PyTorch-Transformer einschließlich Designaspekte für Eland
- Schritte zum Laden von Transformern in Elastic und für die Verwendung bei der Inferenz
- Blogpost mit Beschreibung der Abfrage Ihrer proprietären Daten mit ChatGPT
- Anpassen eines vorab trainierten Transformers auf eine Textklassifizierungsaufgabe und Laden des benutzerdefinierten Modells in Elastic
- Integrierte Spracherkennung, mit der Sie nicht englischsprachigen Text erkennen, bevor Sie ihn in Modelle eingeben, die nur Englisch unterstützen
Elastic, Elasticsearch und zugehörige Marken, Waren- und Dienstleistungszeichen sind Marken oder eingetragene Marken von Elastic N.V. in den USA und anderen Ländern. Alle weiteren Marken- oder Warenzeichen sind eingetragene Marken oder eingetragene Warenzeichen der jeweiligen Eigentümer.
Die Entscheidung über die Veröffentlichung der in diesem Blogpost beschriebenen Leistungsmerkmale und Funktionen oder deren Zeitpunkt liegt allein bei Elastic. Es ist möglich, dass nicht bereits verfügbare Leistungsmerkmale oder Funktionen nicht rechtzeitig oder überhaupt nicht veröffentlicht werden.
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken

