Bereitstellen von NLP: Texteinbettungen und Vektorsuche


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Im Rahmen unserer Blogpostreihe zur Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) zeigen wir anhand eines beispielhaft ausgewählten Texteinbettungsmodells, wie Sie aus Textinhalten Vektoren generieren können, und wir demonstrieren die Vektorähnlichkeitssuche auf der Basis der so generierten Vektoren. Wir stellen ein öffentlich verfügbares Modell auf Elasticsearch bereit und nutzen es in einer Ingestionspipeline, um aus Textdokumenten Einbettungen zu generieren. Anschließend demonstrieren wir, wie Sie diese Einbettungen in der Vektorähnlichkeitssuche nutzen können, um Dokumente zu finden, die eine semantische Ähnlichkeit mit der Suchabfrage aufweisen.
Die Vektorähnlichkeitssuche, häufig auch „semantische Suche“ genannt, erbringt zusätzliche Ergebnisse, die über die der herkömmlichen keywordbasierten Suche hinausgehen – mit ihrer Hilfe lassen sich semantisch ähnliche Dokumente finden, die nicht unbedingt dieselben Keywords enthalten müssen. Die Vektorähnlichkeitssuche arbeitet mit Dichtevektoren und nutzt für die Suche nach ähnlichen Vektoren einen „K-Nearest-Neighbour“-Algorithmus. Zu diesem Zweck müssen die in Textform vorliegenden Inhalte anhand eines Texteinbettungsmodells in einen numerischen Vektor umgewandelt werden.
Zur Demonstration verwenden wir ein öffentliches Dataset aus der MS MARCO-„Passage Ranking“-Aufgabe. Es besteht aus echten Fragen aus der Microsoft-Suchmaschine Bing und aus von Menschen generierten Antworten auf diese Fragen. Dieses Dataset ist aus zwei Gründen eine perfekte Ressource für das Testen der Vektorähnlichkeitssuche: Zum einen ist die Beantwortung von Fragen einer der gängigsten Anwendungsfälle für die Vektorsuche und zum anderen nutzen die Top-Paper im MS MARCO-Leaderboard in der einen oder anderen Form die Vektorsuche.
In unserem Beispiel werden wir mit einer Teilmenge dieses Datasets arbeiten, anhand eines Modells Texteinbettungen produzieren und diese Einbettungen dann als Grundlage für eine Vektorsuche verwenden. Wir hoffen, außerdem auch eine schnelle Prüfung der Qualität der Ergebnisse der Vektorsuche vornehmen zu können.
1. Bereitstellen eines Texteinbettungsmodells
Der erste Schritt besteht darin, ein Texteinbettungsmodell zu installieren. Als Modell verwenden wir msmarco-MiniLM-L-12-v3 von Hugging Face. Dabei handelt es sich um ein SentenceTransformer-Modell, das einzelne Sätze oder ganze Absätze auf einen 384-dimensionalen Dichtevektor abbildet. Dieses Modell ist für die semantische Suche optimiert und wurde spezifisch anhand des MS MARCO-„Passage“-Datasets trainiert, sodass es für unsere Aufgabe bestens geeignet ist. Neben diesem Modell unterstützt Elasticsearch auch eine Reihe anderer Modelle für die Texteinbettung. Die vollständige Liste finden Sie hier.
Wir installieren das Modell mit dem Eland-Docker-Image, das wir im NER-Beispiel erstellt haben. Durch Ausführung des folgenden Skripts wird das Modell in unseren lokalen Cluster importiert und bereitgestellt:
eland_import_hub_model \
--url https://<user>:<password>@localhost:9200/ \
--hub-model-id sentence-transformers/msmarco-MiniLM-L-12-v3 \
--task-type text_embedding \
--startDieses Mal setzen wir --task-type auf text_embedding und übergeben an das Eland-Skript die Option --start, damit das Modell automatisch bereitgestellt wird. So müssen wir es nicht erst in der „Model Management“-Bedienoberfläche manuell starten. Um schneller Schlussfolgerungen ziehen zu können, kann die Zahl der Inferenz-Threads über den Parameter inference_threads erhöht werden.
Ob das Modell erfolgreich bereitgestellt wurde, lässt sich in Kibana Console mit dem folgenden Beispiel prüfen:
POST /_ml/trained_models/sentence-transformers__msmarco-minilm-l-12-v3/deployment/_infer
{
"docs": {
"text_field": "how is the weather in jamaica"
}
}Als Ergebnis sollte der prognostizierte Dichtevektor zurückgegeben werden:
{
"predicted_value" : [
0.3345310091972351,
-0.305600643157959,
0.2592800557613373,
…
]
}2. Laden der Ausgangsdaten
Wie bereits in der Einleitung erwähnt, verwenden wir das MS MARCO-„Passage Ranking“-Dataset. Das Dataset ist mit seinen mehr als 8 Millionen Passagen ziemlich groß. Für unser Beispiel greifen wir daher auf die Teilmenge dieses Datasets zurück, die auch in der Testphase des 2019 TREC Deep Learning Track verwendet worden ist. Das für die Re-Ranking-Aufgabe verwendete Dataset msmarco-passagetest2019-top1000.tsv enthält 200 Suchabfragen und für jede Abfrage eine Liste relevanter Passagen, die von einem einfachen IR-System extrahiert wurden. Aus diesem Dataset haben wir alle eindeutigen Passagen mit ihren IDs extrahiert und sie in einer separaten .tsv-Datei gespeichert. Diese enthält insgesamt 182.469 Passagen. Diese Datei nutzen wir als unser Dataset.
Zum Hochladen des Datasets verwenden wir die Datei-Upload-Funktion von Kibana. Sie erlaubt die Nutzung benutzerdefinierter Namen für Felder: Das Feld für die Passagen-IDs nennen wir id und als Feldtyp legen wir long fest. Das Feld für den Inhalt der Passagen nennen wir text und als Feldtyp legen wir text fest. Der Indexname lautet collection. Nach dem Upload sehen wir einen Index mit dem Namen collection, der 182.469 Dokumente enthält.
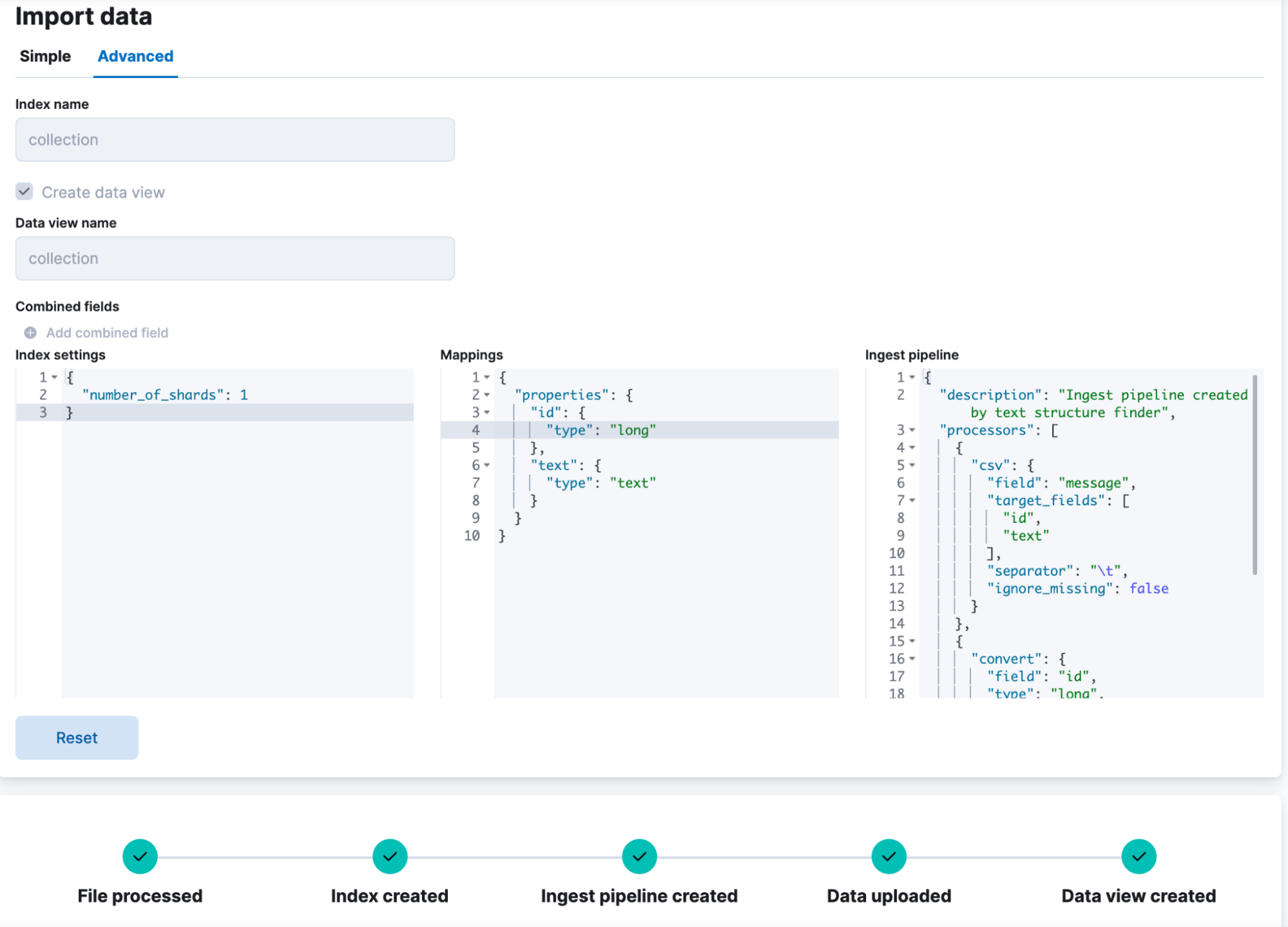
3. Erstellen einer Pipeline
Wir möchten die Ausgangsdaten mit einem Inferenzprozessor verarbeiten, der für jede Passage eine Einbettung hinzufügt. Zu diesem Zweck erstellen wir eine Texteinbettungs-Ingestionspipeline, mit deren Hilfe wir unsere Ausgangsdaten noch einmal indexieren.
Anschließend erstellen wir in Kibana Console eine Ingestionspipeline (wie schon im vorherigen Blogpost), dieses Mal aber für Texteinbettungen. Sie erhält den Namen text-embeddings. Die Passagen befinden sich in einem Feld mit der Bezeichnung text. Wie zuvor definieren wir mit field_map eine Feldzuordnung, um gemäß den Erwartungen des Modells dem Feld text_field Text zuzuordnen. Außerdem wird für den Handler on_failure festgelegt, dass er Fehler in einen anderen Index indexiert:
PUT _ingest/pipeline/text-embeddings
{
"description": "Text embedding pipeline",
"processors": [
{
"inference": {
"model_id": "sentence-transformers__msmarco-minilm-l-12-v3",
"target_field": "text_embedding",
"field_map": {
"text": "text_field"
}
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}4. Neuindexieren der Daten
Wir wollen die Dokumente aus dem Index collection in den neuen Index collection-with-embeddings indexieren. Dazu schicken wir die Dokumente durch die Pipeline text-embeddings, damit Dokumente im Index collection-with-embeddings ein zusätzliches Feld für die Passageneinbettungen erhalten. Bevor wir das tun können, müssen wir aber ein Mapping für unseren Zielindex erstellen und definieren, insbesondere für das Feld text_embedding.predicted_value, in dem der Ingestionsprozessor die Einbettungen speichern wird. Wenn wir das nicht tun, werden die Einbettungen in die regulären float-Felder indexiert und stehen dort nicht für die Vektorähnlichkeitssuche zur Verfügung. Das von uns verwendete Modell erzeugt Einbettungen als 384-dimensionale Dichtevektoren. Daher legen wir als Feldtyp für das indexierte Feld dense_vector fest und setzen die Zahl der Dimensionen auf 384:
PUT collection-with-embeddings
{
"mappings": {
"properties": {
"text_embedding.predicted_value": {
"type": "dense_vector",
"dims": 384,
"index": true,
"similarity": "cosine"
},
"text": {
"type": "text"
}
}
}
}
Jetzt steht dem Neuindexieren nichts mehr im Wege. Da dieser Prozess einige Zeit in Anspruch nehmen wird, weil alle Dokumente verarbeitet und entsprechende Inferenzen gezogen werden müssen, lassen wir den Prozess im Hintergrund laufen, indem wir die API mit dem Flag wait_for_completion=false aufrufen.
POST _reindex?wait_for_completion=false
{
"source": {
"index": "collection"
},
"dest": {
"index": "collection-with-embeddings",
"pipeline": "text-embeddings"
}
}
Zurückgegeben wird eine Aufgaben-ID („task_id“). Zur Überwachung des Aufgabenfortschritts können wir Folgendes eingeben:
GET _tasks/<task_id>Oder wir überwachen den Fortschritt, indem wir in der Modellstatistik-API oder in der Modellstatistik-UI den Anstieg des Inference count-Wertes beobachten.

Die neu indexierten Dokumente enthalten jetzt die Inferenzergebnisse – Vektoreinbettungen. Ein solches Dokument kann zum Beispiel wie folgt aussehen:
{
"id": "G7PPtn8BjSkJO8zzChzT",
"text": "This is the definition of RNA along with examples of types of RNA molecules. This is the definition of RNA along with examples of types of RNA molecules. RNA Definition",
"text_embedding":
{
"predicted_value":
[
0.057356324046850204,
0.1602816879749298,
-0.18122544884681702,
0.022277727723121643,
....
],
"model_id": "sentence-transformers__msmarco-minilm-l-12-v3"
}
}
5. Vektorähnlichkeitssuche
Derzeit bieten wir keine Unterstützung für die implizite Generierung von Einbettungen aus Suchbegriffen während einer Suchanfrage. Daher haben wir unsere semantische Suche als zweistufigen Prozess aufgesetzt:
- Erzeugung einer Texteinbettung aus einer Textabfrage: Hierfür nutzen wir die _infer-API unseres Modells.
- Nutzung der Vektorsuche zum Finden von Dokumenten mit semantischer Ähnlichkeit mit dem Abfragetext: In Elasticsearch 8.0 haben wir einen neuen _knn_search-Endpoint eingeführt, mit dem anhand indexierter dense_vector-Felder eine effiziente approximative „Nearest-Neighbour“-Suche durchgeführt werden kann. Wir nutzen die _knn_search-API, um die ähnlichsten Dokumente zu finden.
Wird zum Beispiel nach „how is the weather in jamaica“ gesucht, führen wir zunächst die „run _infer“-API aus, um deren Einbettung als Dichtevektor abzurufen:
POST /_ml/trained_models/sentence-transformers__msmarco-minilm-l-12-v3/deployment/_infer
{
"docs": {
"text_field": "how is the weather in jamaica"
}
}Anschließend nutzen wir den zurückgegebenen Dichtevektor für die folgende _knn_search-Operation:
GET collection-with-embeddings/_knn_search
{
"knn": {
"field": "text_embedding.predicted_value",
"query_vector": [
0.3345310091972351,
-0.305600643157959,
0.2592800557613373,
…
],
"k": 10,
"num_candidates": 100
},
"_source": [
"id",
"text"
]
}Als Ergebnis erhalten wir die zehn Dokumente, die der Abfrage am nächsten kommen, sortiert nach dem Grad ihrer Ähnlichkeit:
"hits" : [
{
"_index" : "collection-with-embeddings",
"_id" : "47TPtn8BjSkJO8zzKq_o",
"_score" : 0.94591534,
"_source" : {
"id" : 434125,
"text" : "The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably cooler than the days, and the mountain areas are cooler than the lower land throughout the year. Continue Reading."
}
},
{
"_index" : "collection-with-embeddings",
"_id" : "3LTPtn8BjSkJO8zzKJO1",
"_score" : 0.94536424,
"_source" : {
"id" : 4498474,
"text" : "The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably cooler than the days, and the mountain areas are cooler than the lower land throughout the year"
}
},
{
"_index" : "collection-with-embeddings",
"_id" : "KrXPtn8BjSkJO8zzPbDW",
"_score" : 0.9432083,
"_source" : {
"id" : 190804,
"text" : "Quick Answer. The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably cooler than the days, and the mountain areas are cooler than the lower land throughout the year. Continue Reading"
}
},
...6. Schnelle Prüfung
Da wir nur eine Teilmenge des MS MARCO-Datasets verwendet haben, können wir keine vollständige Auswertung durchführen. Aber wir können anhand einiger Abfragen eine einfache Prüfung vornehmen, um ein Gefühl dafür zu bekommen, dass wir nicht irgendwelche zufälligen Ergebnisse, sondern tatsächlich relevante Ergebnisse erhalten. Wir verwenden dazu die drei letzten Abfragen aus den TREC-„2019 Deep Learning Track“-Judgements für die „Passage Ranking“-Aufgabe, senden diese an unsere Vektorähnlichkeitssuche, nehmen die ersten zehn Ergebnisse und sehen uns in den TREC-Judgements an, wie relevant unsere Ergebnisse sind. Für die „Passage Ranking“-Aufgabe werden die Passagen anhand der folgenden Vier-Punkte-Skala beurteilt: 0 = irrelevant, 1 = Zusammenhang vorhanden (die Passage bezieht sich auf das Thema, beantwortet aber die Frage nicht), 2 = sehr relevant und 3 = absolut relevant.
Bitte beachten Sie, dass es sich bei unserer Prüfung nicht um eine exakte Auswertung handelt – sie dient lediglich zu Demonstrationszwecken. Da wir nur Passagen indexiert haben, von denen bekannt ist, dass sie mit den Abfragen in Zusammenhang stehen, ist dies eine viel einfachere Aufgabe als die ursprüngliche Aufgabe, Passagen zu finden. Wir planen jedoch, das MS MARCO-Dataset zu einem späteren Zeitpunkt einer exakten Auswertung zu unterziehen.
Die an unsere Vektorsuche gesendete Abfrage 1124210 „tracheids are part of _____“ erbringt die folgenden Ergebnisse:
ID der Passage | Relevanzeinstufung | Passage |
|---|---|---|
2258591 | 2 – sehr relevant | Tracheid of oak shows pits along the walls. It is longer than a vessel element and has no perforation plates. Tracheids are elongated cells in the xylem of vascular plants that serve in the transport of water and mineral salts.Tracheids are one of two types of tracheary elements, vessel elements being the other. Tracheids, unlike vessel elements, do not have perforation plates.racheids provide most of the structural support in softwoods, where they are the major cell type. Because tracheids have a much higher surface to volume ratio compared to vessel elements, they serve to hold water against gravity (by adhesion) when transpiration is not occurring. |
2258592 | 3 – absolut relevant | Tracheid. a dead lignified plant cell that functions in water conduction. Tracheids are found in the xylem of all higher plants except certain angiosperms, such as cereals and sedges, in which the water-conducting function is performed by vessels, or tracheae.Tracheids are usually polygonal in cross section; their walls have annular, spiral, or scalene thickenings or rimmed pores.racheids are found in the xylem of all higher plants except certain angiosperms, such as cereals and sedges, in which the water-conducting function is performed by vessels, or tracheae. Tracheids are usually polygonal in cross section; their walls have annular, spiral, or scalene thickenings or rimmed pores. |
2258596 | 2 – sehr relevant | Woody angiosperms have also vessels. The mature tracheids form a column of superposed, cylindrical dead cells whose end walls have been perforated, resulting in a continuous tube called vessel (trachea). Tracheids are found in all vascular plants and are the only conducting elements in gymnosperms and ferns. Tracheids have Pits on their end walls. Pits are not nearly as efficient for water translocation as Perforation Plates found in vessel elements. Woody angiosperms have also vessels. The mature tracheids form a column of superposed, cylindrical dead cells whose end walls have been perforated, resulting in a continuous tube called vessel (trachea). Tracheids are found in all vascular plants and are the only conducting elements in gymnosperms and ferns |
2258595 | 2 – sehr relevant | Summary: Vessels have perforations at the end plates while tracheids do not have end plates. Tracheids are derived from single individual cells while vessels are derived from a pile of cells. Tracheids are present in all vascular plants whereas vessels are confined to angiosperms. Tracheids are thin whereas vessel elements are wide. Tracheids have a much higher surface-to-volume ratio as compared to vessel elements. Vessels are broader than tracheids with which they are associated. Morphology of the perforation plate is different from that in tracheids. Tracheids are thin whereas vessel elements are wide. Tracheids have a much higher surface-to-volume ratio as compared to vessel elements. Vessels are broader than tracheids with which they are associated. Morphology of the perforation plate is different from that in tracheids. |
131190 | 3 – absolut relevant | Xylem tracheids are pointed, elongated xylem cells, the simplest of which have continuous primary cell walls and lignified secondary wall thickenings in the form of rings, hoops, or reticulate networks. |
7443586 | 2 – sehr relevant | 1 The xylem tracheary elements consist of cells known as tracheids and vessel members, both of which are typically narrow, hollow, and elongated. Tracheids are less specialized than the vessel members and are the only type of water-conducting cells in most gymnosperms and seedless vascular plants. |
181177 | 2 – sehr relevant | In most plants, pitted tracheids function as the primary transport cells. The other type of tracheary element, besides the tracheid, is the vessel element. Vessel elements are joined by perforations into vessels. In vessels, water travels by bulk flow, as in a pipe, rather than by diffusion through cell membranes. |
2947055 | 0 – irrelevant | Cholesterol belongs to the groups of lipids called _______.holesterol belongs to the groups of lipids called _______. |
6541866 | 2 – sehr relevant | In most plants, pitted tracheids function as the primary transport cells. The other type of tracheary element, besides the tracheid, is the vessel element. Vessel elements are joined by perforations into vessels. In vessels, water travels by bulk flow, as in a pipe, rather than by diffusion through cell membranes. In most plants, pitted tracheids function as the primary transport cells. The other type of tracheary element, besides the tracheid, is the vessel element. Vessel elements are joined by perforations into vessels. In vessels, water travels by bulk flow, as in a pipe, rather than by diffusion through cell membranes. |
Die Abfrage 1129237 „hydrogen is a liquid below what temperature“ erbringt die folgenden Ergebnisse:
ID der Passage | Relevanzeinstufung | Passage |
|---|---|---|
8588222 | 0 – irrelevant | Answer to: Hydrogen is a liquid below what temperature? By signing up, you'll get thousands of step-by-step solutions to your homework questions.... for Teachers for Schools for Companies |
128984 | 3 – absolut relevant | Hydrogen gas has the molecular formula H 2. At room temperature and under standard pressure conditions, hydrogen is a gas that is tasteless, odorless and colorless. Hydrogen can exist as a liquid under high pressure and an extremely low temperature of 20.28 kelvin (−252.87°C, −423.17 °F). Hydrogen is often stored in this way as liquid hydrogen takes up less space than hydrogen in its normal gas form. Liquid hydrogen is also used as a rocket fuel. |
8588219 | 3 – absolut relevant | User: Hydrogen is a liquid below what temperature? a. 100 degrees C c. -183 degrees C b. -253 degrees C d. 0 degrees C Weegy: Hydrogen is a liquid below 253 degrees C. User: What is the boiling point of oxygen? a. 100 degrees C c. -57 degrees C b. 8 degrees C d. -183 degrees C Weegy: The boiling point of oxygen is -183 degrees C. |
3905057 | 3 – absolut relevant | Hydrogen is a colorless, odorless, tasteless gas. Its density is the lowest of any chemical element, 0.08999 grams per liter. By comparison, a liter of air weighs 1.29 grams, 14 times as much as a liter of hydrogen. Hydrogen changes from a gas to a liquid at a temperature of -252.77°C (-422.99°F) and from a liquid to a solid at a temperature of -259.2°C (-434.6°F). It is slightly soluble in water, alcohol, and a few other common liquids. |
4254811 | 3 – absolut relevant | At STP (standard temperature and pressure) hydrogen is a gas. It cools to a liquid at -423 °F, which is only about 37 degrees above absolute zero. Eleven degrees cooler, at … -434 °F, it starts to solidify. |
2697752 | 2 – sehr relevant | Hydrogen's state of matter is gas at standard conditions of temperature and pressure. Hydrogen condenses into a liquid or freezes solid at extremely cold... Hydrogen's state of matter is gas at standard conditions of temperature and pressure. Hydrogen condenses into a liquid or freezes solid at extremely cold temperatures. Hydrogen's state of matter can change when the temperature changes, becoming a liquid at temperatures between minus 423.18 and minus 434.49 degrees Fahrenheit. It becomes a solid at temperatures below minus 434.49 F.Due to its high flammability, hydrogen gas is commonly used in combustion reactions, such as in rocket and automobile fuels. |
6080460 | 3 – absolut relevant | Hydrogen can exist as a liquid under high pressure and an extremely low temperature of 20.28 kelvin (−252.87°C, −423.17 °F). Hydrogen is often stored in this way as liquid hydrogen takes up less space than hydrogen in its normal gas form. Liquid hydrogen is also used as a rocket fuel. Hydrogen is found in large amounts in giant gas planets and stars, it plays a key role in powering stars through fusion reactions. Hydrogen is one of two important elements found in water (H 2 O). Each molecule of water is made up of two hydrogen atoms bonded to one oxygen atom. |
128989 | 3 – absolut relevant | Confidence votes 11.4K. At STP (standard temperature and pressure) hydrogen is a gas. It cools to a liquid at -423 °F, which is only about 37 degrees above absolute zero. Eleven degrees cooler, at -434 °F, it starts to solidify. |
1959030 | 0 – irrelevant | While below 4 °C the breakage of hydrogen bonds due to heating allows water molecules to pack closer despite the increase in the thermal motion (which tends to expand a liquid), above 4 °C water expands as the temperature increases. Water near the boiling point is about 4% less dense than water at 4 °C (39 °F) |
3905800 | 0 – irrelevant | Hydrogen is the lightest of the elements with an atomic weight of 1.0. Liquid hydrogen has a density of 0.07 grams per cubic centimeter, whereas water has a density of 1.0 g/cc and gasoline about 0.75 g/cc. These facts give hydrogen both advantages and disadvantages. |
Die Abfrage 1133167 „how is the weather in jamaica“ erbringt die folgenden Ergebnisse:
ID der Passage | Relevanzeinstufung | Passage |
|---|---|---|
434125 | 3 – absolut relevant | The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably cooler than the days, and the mountain areas are cooler than the lower land throughout the year. |
4498474 | 3 – absolut relevant | The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably cooler than the days, and the mountain areas are cooler than the lower land throughout the year. |
190804 | 3 – absolut relevant | Quick Answer. The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably cooler than the days, and the mountain areas are cooler than the lower land throughout the year. Continue Reading. |
1824479 | 3 – absolut relevant | A: The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably cooler than the days, and the mountain areas are cooler than the lower land throughout the year. |
1824480 | 3 – absolut relevant | Quick Answer. The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably cooler than the days, and the mountain areas are cooler than the lower land throughout the year. |
1824488 | 2 – sehr relevant | Learn About the Weather of Jamaica The weather patterns you'll encounter in Jamaica can vary dramatically around the island Regardless of when you visit, the tropical climate and warm temperatures of Jamaica essentially guarantee beautiful weather during your vacation. Average temperatures in Jamaica range between 80 degrees Fahrenheit and 90 degrees Fahrenheit, with July and August being the hottest months and February the coolest. |
4922619 | 2 – sehr relevant | Weather. Jamaica averages about 80 degrees year-round, so climate is less a factor in booking travel than other destinations. The days are warm and the nights are cool. Rain usually falls for short periods in the late afternoon, with sunshine the rest of the day. |
190806 | 2 – sehr relevant | It is always important to know what the weather in Jamaica will be like before you plan and take your vacation. For the most part, the average temperature in Jamaica is between 80 °F and 90 °F (27 °FCelsius-29 °Celsius). Luckily, the weather in Jamaica is always vacation friendly. You will hardly experience long periods of rain fall, and you will become accustomed to weeks upon weeks of sunny weather. |
2613296 | 2 – sehr relevant | Average temperatures in Jamaica range between 80 degrees Fahrenheit and 90 degrees Fahrenheit, with July and August being the hottest months and February the coolest. Temperatures in Jamaica generally vary approximately 10 degrees from summer to winter |
1824486 | 2 – sehr relevant | The climate in Jamaica is tropical and humid with warm to hot temperatures all year round. The average temperature in Jamaica is between 80 and 90 degrees Fahrenheit. Jamaican nights are considerably... |
Wir stellen fest: Bei allen drei Abfragen hat Elasticsearch zumeist relevante Ergebnisse zurückgegeben und die Top-Ergebnisse waren bei allen Abfragen zumeist entweder sehr oder absolut relevant.
Jetzt ausprobieren
NLP ist ein leistungsstarkes Feature im Elastic Stack und die Roadmap für die weitere Entwicklung ist spannend. Entdecken Sie neue Features und bleiben Sie bei den neuesten Entwicklungen auf dem Laufenden – mit einem eigenen Cluster in Elastic Cloud. Wenn Sie selbst mit den Beispielen in diesem Blogpost experimentieren möchten, probieren Sie Elastic Cloud 14 Tage kostenlos aus.
Mehr zu NLP finden Sie in den folgenden Blogposts:
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken

