NLP bereitstellen: Beispiel für eine Standpunktanalyse


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Im Rahmen unserer mehrteiligen Blogreihe zur Verarbeitung natürlicher Sprache (NLP) zeigen wir am Beispiel eines NLP-Modells für die Standpunktanalyse, wie Sie ermitteln können, ob Kommentarfelder (im Textformat) positive oder negative Einträge enthalten. Wir zeigen an einem öffentlich verfügbaren Modell, wie Sie das Modell in Elasticsearch bereitstellen und in einer Ingestionspipeline verwenden können, um Kundenbewertungen als positiv oder negativ zu klassifizieren.
Die Standpunktanalyse ist eine Art von Binärklassifizierung, bei der jedem Feld einer von zwei Werten zugewiesen wird. Für die Zuweisung wird normalerweise ein Wahrscheinlichkeitswert zwischen 0 und 1 ausgegeben, wobei Werte näher an 1 ein höheres Vertrauen in die Zuweisung darstellen. Diese Art von NLP-Analyse ist hilfreich für viele Arten von Datensätzen, wie etwa Produktbewertungen oder Kundenfeedback.
Die Kundenbewertungen, die wir klassifizieren werden, stammen aus einem öffentlichen Datensatz aus der Yelp Dataset Challenge 2015. Dieser von der Yelp-Bewertungsseite zusammengestellte Datensatz eignet sich hervorragend, um unsere Standpunktanalyse zu testen. In diesem Beispiel überprüfen wir einen Teil des Yelp-Bewertungsdatensatzes mit einem öffentlichen NLP-Modell für Standpunktanalysen und verwenden das Modell, um die Kommentare als positiv oder negativ zu markieren. Dabei möchten wir herausfinden, welcher Prozentanteil der Bewertungen positiv bzw. negativ ist.
Modell für Standpunktanalysen in Elasticsearch bereitstellen
docker run -it --rm elastic/eland \
eland_import_hub_model \
--url $ELASTICSEARCH_URL \
--hub-model-id distilbert-base-uncased-finetuned-sst-2-english \
--task-type text_classification \
--start
Dieses Mal setzen wir --task-type auf text_classification und übergeben die Option --start an das Eland-Skript, damit das Modell automatisch bereitgestellt wird und wir es nicht erst in der „Model Management“-Bedienoberfläche manuell starten müssen.
Probieren Sie anschließend die folgenden Beispiele in der Kibana-Konsole aus:
POST _ml/trained_models/distilbert-base-uncased-finetuned-sst-2-english/deployment/_infer
{
"docs": [
{
"text_field": "The movie was awesome!"
}
]
}
Das Ergebnis sollte ungefähr so aussehen:
{
"predicted_value" : "POSITIVE",
"prediction_probability" : 0.9998643924765398
}
Sie können auch das dieses Beispiel ausprobieren:
POST _ml/trained_models/distilbert-base-uncased-finetuned-sst-2-english/deployment/_infer
{
"docs": [
{
"text_field": "The cat was sick on the bed"
}
]
}
Produziert eine stark negative Antwort für die Katze und die Person, die die Leintücher reinigt.
{
"predicted_value" : "NEGATIVE",
"prediction_probability" : 0.9992468477843378
}
Yelp-Bewertungen analysieren
Wie bereits erwähnt verwenden wir eine Teilmenge der Yelp-Bewertungen, die auf Hugging Face verfügbar sind und die manuell mit einem bestimmten Standpunkt markiert wurden. Auf diese Weise können wir die Ergebnisse mit dem markierten Index vergleichen. Mit dem Kibana-Dateiupload können wir einen Teil des Datensatzes hochladen, um ihn mit dem Inferenz-Prozessor zu verarbeiten.
In der Kibana-Konsole können wir jetzt eine Ingestionspipeline (genau wie im vorherigen Blogeintrag) erstellen, dieses Mal für die Standpunktanalyse, und ihr den Namen sentiment geben. Die Bewertungen befinden sich im Feld review. Wie zuvor definieren wir eine field_map, um das Feld review zu dem vom Modell erwarteten Feld zuzuordnen. Wir verwenden denselben Handler für on_failure wie in der NER-Pipeline:
PUT _ingest/pipeline/sentiment
{
"processors": [
{
"inference": {
"model_id": "distilbert-base-uncased-finetuned-sst-2-english",
"field_map": {
"review": "text_field"
}
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
Die Bewertungsdokumente werden im Elasticsearch-Index yelp-reviews gespeichert. Mit der reindex-API können wir die Bewertungsdaten durch die Pipeline für die Standpunktanalyse leiten. Da die erneute Indexierung einige Zeit in Anspruch nehmen wird, weil alle Dokumente verarbeitet und entsprechende Inferenzen gezogen werden müssen, lassen wir den Prozess im Hintergrund laufen, indem wir die API mit dem Flag wait_for_completion=false aufrufen. Überprüfen Sie den Prozess mit der Aufgabenverwaltungs-API.
POST _reindex?wait_for_completion=false
{
"source": {
"index": "yelp-reviews"
},
"dest": {
"index": "yelp-reviews-with-sentiment",
"pipeline": "sentiment"
}
}
Dabei wird eine Aufgaben-ID zurückgegeben. Wir überwachen den Fortschritt der Aufgabe wie folgt:
The above returns a task id. We can monitor progress of the task with:
Alternativ können wir zusehen, wie der Wert von Inference Count (Inferenzanzahl) in der Benutzeroberfläche für Modellstatistiken steigt.

Die neu indexierten Dokumente enthalten jetzt die Inferenzergebnisse. Eines der analysierten Dokumente sieht beispielsweise so aus:
{
"review": "The food is good. Unfortunately the service is very hit or miss. The main issue seems to be with the kitchen, the waiters and waitresses are often very apologetic for the long waits and it's pretty obvious that some of them avoid the tables after taking the initial order to avoid hearing complaints.",
"ml": {
"inference": {
"predicted_value": "NEGATIVE",
"prediction_probability": 0.9985209630712552,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
}
},
"timestamp": "2022-02-02T15:10:38.195345345Z"
}
Der zugewiesene Wert ist NEGATIV, was angesichts des mangelhaften Service verständlich ist.
Visualisieren, wie viele Bewertungen negativ sind
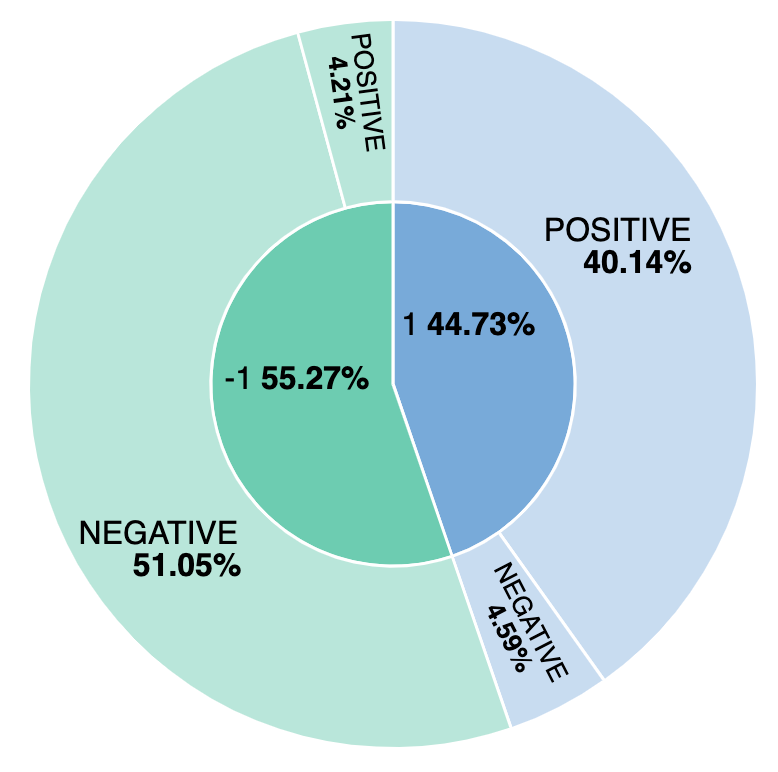
Welcher Prozentanteil der Bewertungen ist negativ? Und wie schneidet unser Modell im Vergleich zur manuellen Standpunktmarkierung ab? Um das herauszufinden, erstellen wir eine einfache Visualisierung, die positive und negative Bewertungen von Modell und manueller Markierung gegenüberstellt. Wir erstellen die Visualisierung anhand von ml.inference.predicted_value field und stellen fest, dass etwa 44 % der Bewertungen als positiv eingestuft wurden und dass das Modell für die Standpunktanalyse 4,59 % davon falsch markiert hat.
Selbst ausprobieren
Weiterführende Informationen zu NLP:
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken