Kubernetes-Observability-Tutorial: Monitoring der Anwendungsperformance mit Elastic APM
Dies ist der letzte Teil unserer Tutorial-Reihe zur Observability in Kubernetes, in der es um die Überwachung aller Aspekte der in Kubernetes laufenden Anwendungen geht. Sie besteht aus den folgenden drei Teilen:
- Ingestieren und Analysieren von Logdaten
- Erfassen von Performance- und Zustandsmetriken
- Monitoring der Anwendungsperformance mit Elastic APM
Wir sehen uns an, wie Sie mit Elastic Observability und Elastic APM die Performance Ihrer Anwendungen überwachen können.
| Bevor es losgeht: Das folgende Tutorial setzt das Vorhandensein einer bestimmten Kubernetes-Umgebung voraus. Lesen Sie dazu unseren ergänzenden Blogpost, in dem wir die Schritte zur Einrichtung einer Einzelknoten-Minikube-Umgebung mit einer Demo-Anwendung beschreiben. Diese Umgebung benötigen Sie, um die weiteren Aktivitäten nachvollziehen zu können. |
Monitoring der Anwendungsperformance
Beim Monitoring der Anwendungsperformance, kurz auch APM (Application Performance Monitoring) genannt, werden zwei aus Kundensicht besonders wichtige Dienstgüteindikatoren betrachtet: die Reaktionszeit auf Anforderungen („Latenz“) und nutzerseitige Fehlermeldungen. Durch die effektive Überwachung dieser beiden Indikatoren lässt sich ermitteln, welche Komponente (und welcher Codeblock in ihr) für Probleme, wie Leistungseinbußen oder erhöhtes Fehlermeldungsaufkommen, verantwortlich ist. Mit APM steht ein hervorragendes Tool für die Erstbewertung zur Verfügung, das bei der Ermittlung des genauen Problems helfen kann und so zur Reduzierung der mittleren Reaktionszeit (Mean Time To Respond – MTTR) beiträgt.
Verteiltes Tracing mit Elastic APM
Elastic APM unterstützt das verteilte Tracing, das die Messung einer End-to-End-Reaktionslatenz für die verschiedenen verteilten Anwendungskomponenten ermöglicht, die an der Beantwortung einer Nutzeranfrage oder ‑anforderung beteiligt sind. Die App zeigt die Gesamtdauer der Trace an und listet die Latenzen der einzelnen Komponenten auf, die am verteilten Tracing beteiligt sind. Sehen wir uns die App APM in Kibana und die Traces und Transaktionen einmal genauer an. Hinweis: Bevor es losgeht, sollten Sie zunächst ein wenig in der Anwendung Petclinic herumklicken, um Nutzer-Traffic zu erzeugen.
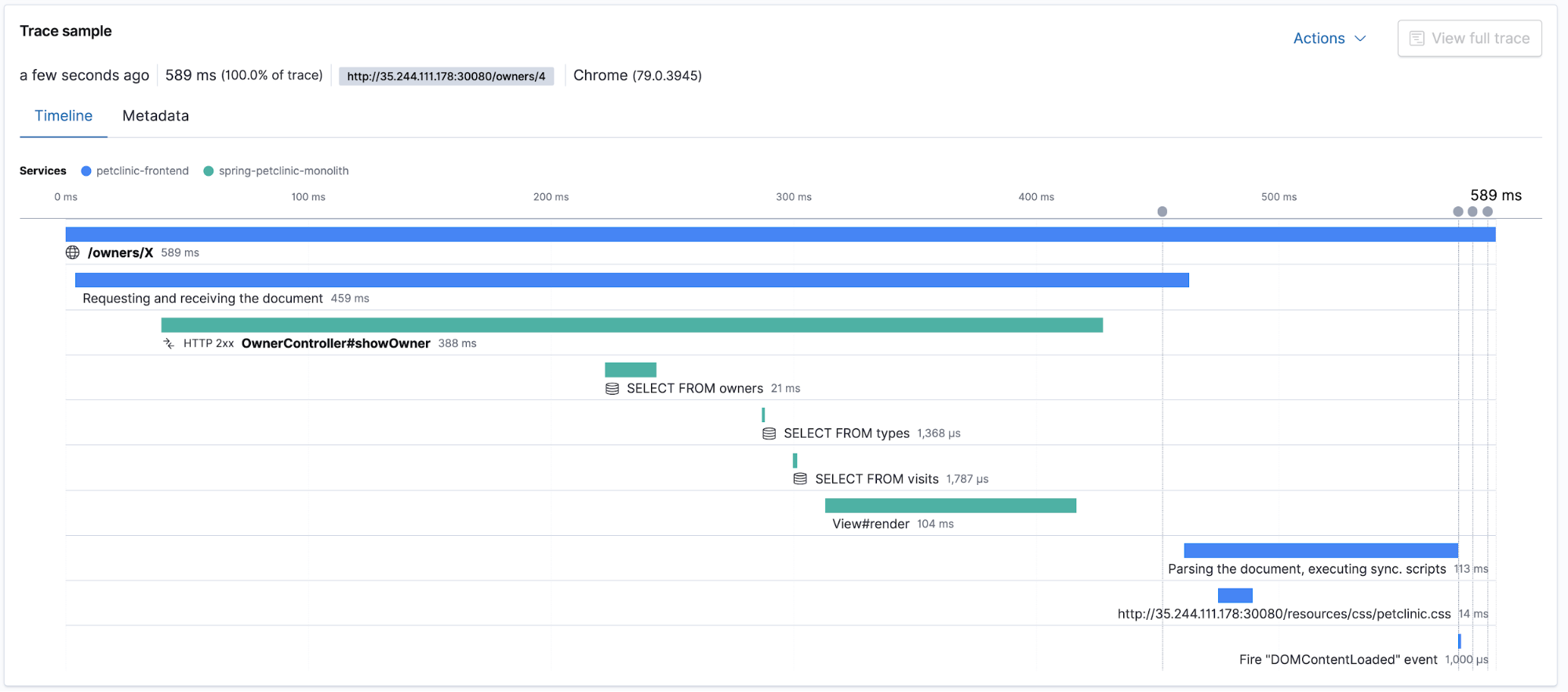
Traces im Kontext mit Logdaten und Metriken
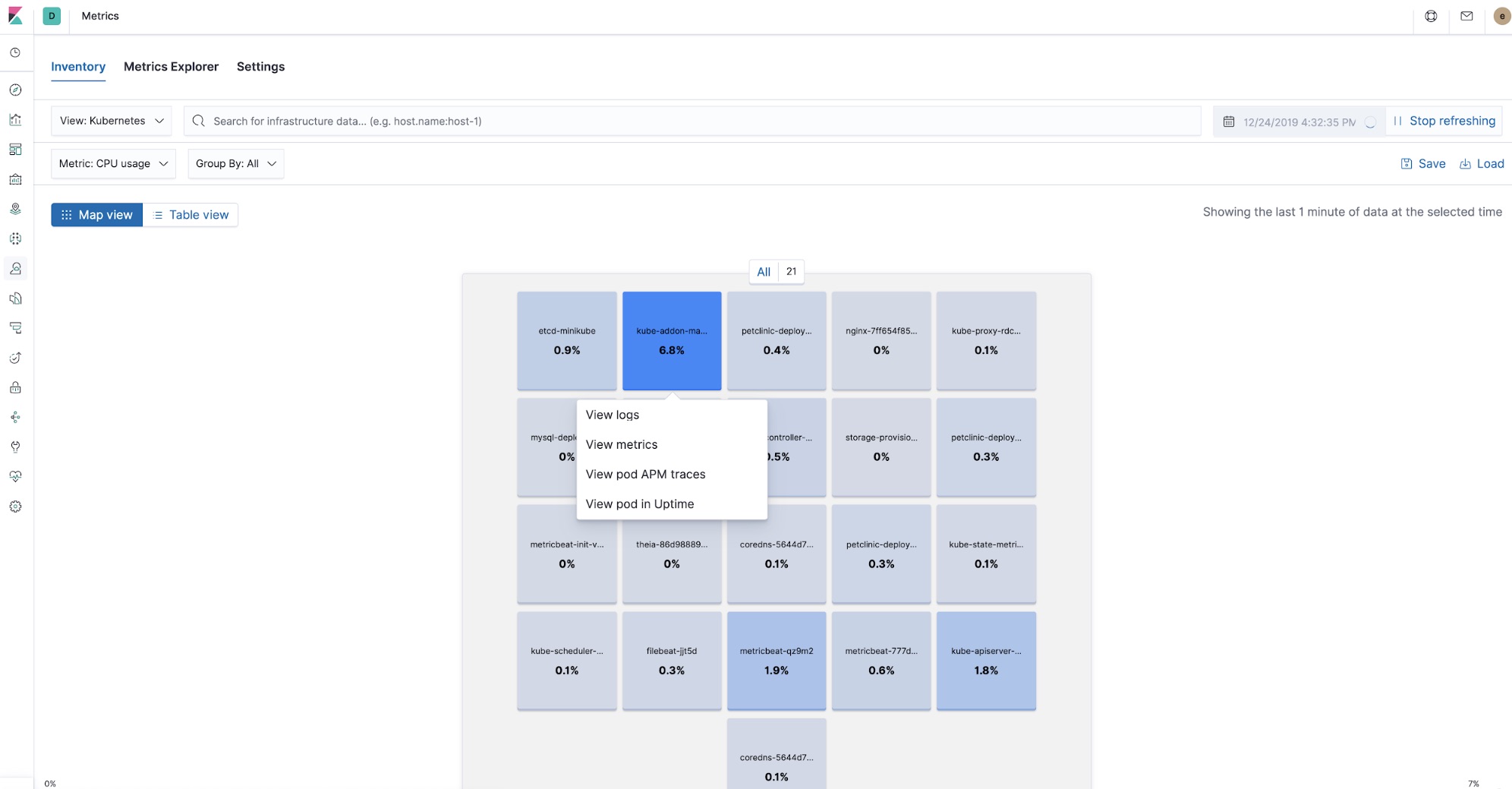
Wenn es um das Bereitstellen einer Anwendung in Kubernetes geht, bieten verteiltes Tracing und APM nach wie vor den Vorteil einer schnellen Erstbewertung von Problemen, während gleichzeitig auch die anderen Teile des Observability-Puzzles – Logdaten und Metriken – erfasst und über Querverweise verknüpft werden können. Die Tatsache, dass Sie jedes dieser Teile zur Hand haben, versetzt Sie in die Lage, die Ursachen von Latenzspitzen zu finden und zu beseitigen. APM hilft Ihnen dabei, die Untersuchung auf eine konkrete Komponente einzugrenzen und eine Verknüpfung zu CPU- und Arbeitsspeicher-Nutzungsmetriken sowie Fehlerlogdaten eines bestimmten Kubernetes-Pods herzustellen, ohne Kibana dazu verlassen zu müssen.
Dank der Prozessoren in Beats und der von den APM-Agents erfassten Metadaten werden Querverweise auf alle Observability-Daten in Kibana hergestellt. So können Sie sich an einem zentralen Ort die APM-Traces ansehen, die Metriken der an der Verarbeitung der jeweiligen Trace beteiligten Pods betrachten und die Logdaten prüfen, die die Komponenten bei der Verarbeitung der Trace aufgezeichnet haben.
Bereitstellung von Elastic APM-Agents
Bei der Bereitstellung der Anwendungskomponenten werden gleichzeitig auch die zugehörigen APM-Agents bereitgestellt. In Kubernetes werden die Anwendungskomponenten zum Teil des Codes, der in den Pods ausgeführt wird. In diesem Tutorial kommen zwei Agents zum Einsatz: der APM-RUM-JavaScript-Agent („RUM“ steht für „Real User Monitoring“) und der APM-Java-Agent.
Elastic APM-Java-Agent
Das folgende Code-Snippet zeigt den Initialisierungsteil des APM-Java-Agents im Petclinic-Pod-Deployment-Deskriptor in $HOME/k8s-o11y-workshop/petclinic/petclinic.yml:
env:
- name: ELASTIC_APM_SERVER_URLS
valueFrom:
secretKeyRef:
name: apm-secret
key: apm-url
- name: ELASTIC_APM_SECRET_TOKEN
valueFrom:
secretKeyRef:
name: apm-secret
key: apm-token
- name: ELASTIC_APM_SERVICE_NAME
value: spring-petclinic-monolith
- name: ELASTIC_APM_APPLICATION_PACKAGES
value: org.springframework.samplesDer APM-Agent wird in der Datei pom.xml der Anwendung Petclinic ($HOME/k8s-o11y-workshop/docker/petclinic/pom.xml) als Abhängigkeit bereitgestellt:
<!-- Liste der Elastic APM-Abhängigkeiten -->
<dependency>
<groupId>co.elastic.apm</groupId>
<artifactId>apm-agent-attach</artifactId>
<version>${elastic-apm.version}</version>
</dependency>
<dependency>
<groupId>co.elastic.apm</groupId>
<artifactId>apm-agent-api</artifactId>
<version>${elastic-apm.version}</version>
</dependency>
<dependency>
<groupId>co.elastic.apm</groupId>
<artifactId>elastic-apm-agent</artifactId>
<version>${elastic-apm.version}</version>
</dependency>
<!-- Ende der Liste der Elastic APM-Abhängigkeiten -->
Bei dieser Art der Bereitstellung wird der Java-Agent als Maven-Abhängigkeit definiert. Es gibt auch andere Möglichkeiten, APM-Agents bereitzustellen, wie z. B. Java-Agent-Anhänge zur Laufzeit. Nähere Informationen dazu finden Sie in der Dokumentation zum Elastic APM-Java-Agent.
Elastic APM-RUM-Agent
Der RUM-Agent wird als Teil der Browseranwendung des Nutzers ausgeführt und stellt alle vom Browser erfassten nutzerseitigen Metriken zur Verfügung. In diesem Tutorial wird er zu diesem Zweck, aber auch als Ausgangspunkt für verteilte Traces genutzt. Das folgende Code-Snippet zeigt, wo der APM-Agent im nutzerseitigen JavaScript-Code instanziiert wird ($HOME/k8s-o11y-workshop/docker/petclinic/src/main/resources/templates/fragments/layout.html):
<script th:inline="javascript">
...
var serverUrl = [[${apmServer}]];
elasticApm.init({
serviceName: 'petclinic-frontend',
serverUrl: serverUrl,
distributedTracingOrigins: [],
pageLoadTransactionName: pageName,
active: true,
pageLoadTraceId: [[${transaction.traceId}]],
pageLoadSpanId: [[${transaction.ensureParentId()}]],
pageLoadSampled: [[${transaction.sampled}]],
distributedTracing: true,
})
...
</script>
Petclinic ist eine serverseitig gerenderte Anwendung und Thymeleaf ist ein bei Spring Boot verwendetes Framework für das Vorlagen-Rendering, das im Java-Code des Controllers einige der Werte bereitstellt, die an das Frontend gesendet werden. Das folgende Beispiel zeigt, wie der Wert für das Modellattribut transaction in $HOME/k8s-o11y-workshop/docker/petclinic/src/main/java/org/springframework/samples/petclinic/owner/OwnerController.java bereitgestellt wird:
@ModelAttribute("transaction")
public Transaction transaction() {
return ElasticApm.currentTransaction();
}
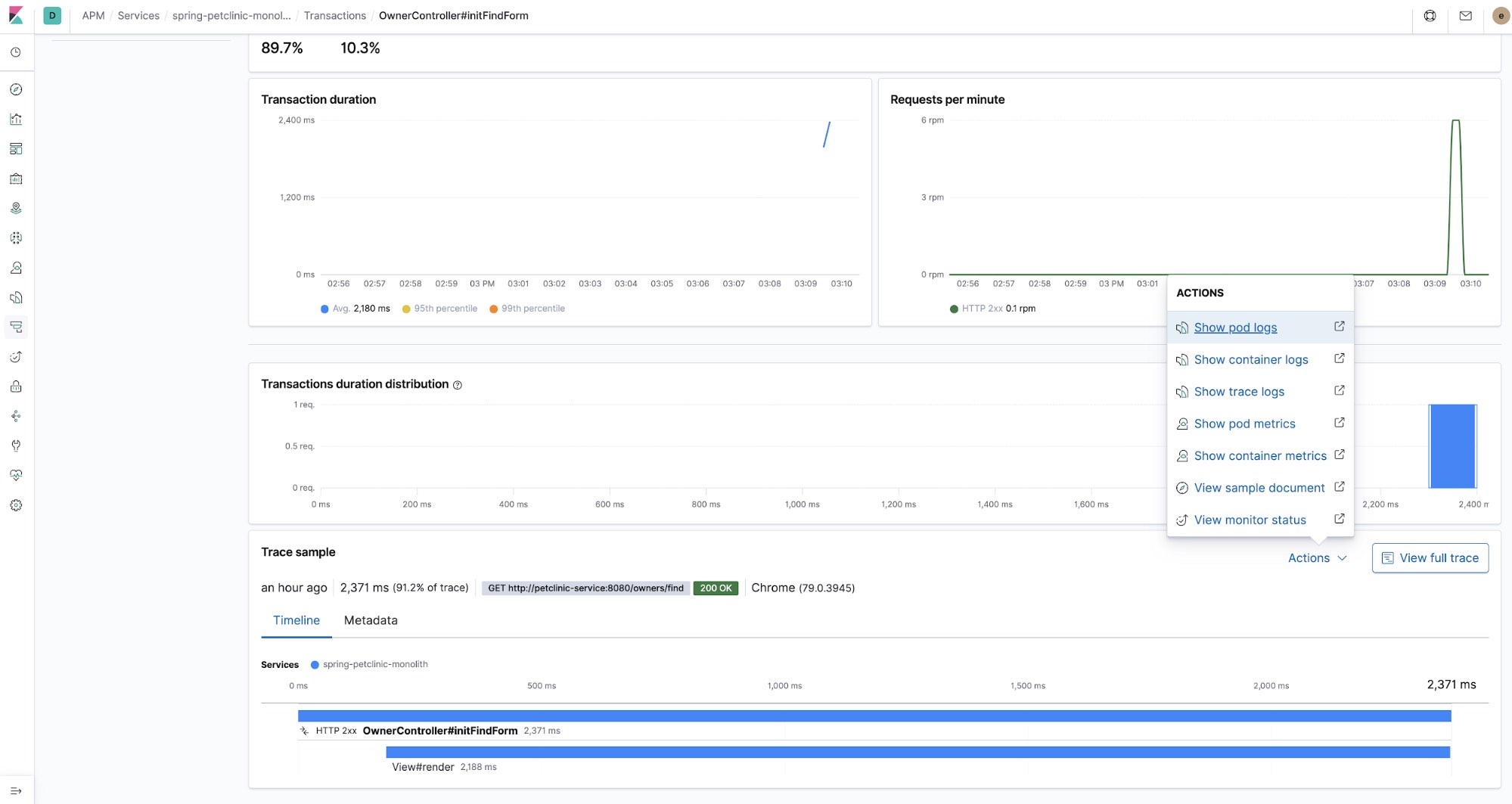
Monitoring-Fehler
APM-Agents erfassen auch unverarbeitete Ausnahmen. Klicken Sie einmal auf das Menü „ERROR“ und sehen Sie sich dann in der App APM in Kibana die Details zu den aufgetretenen Ausnahmen an.

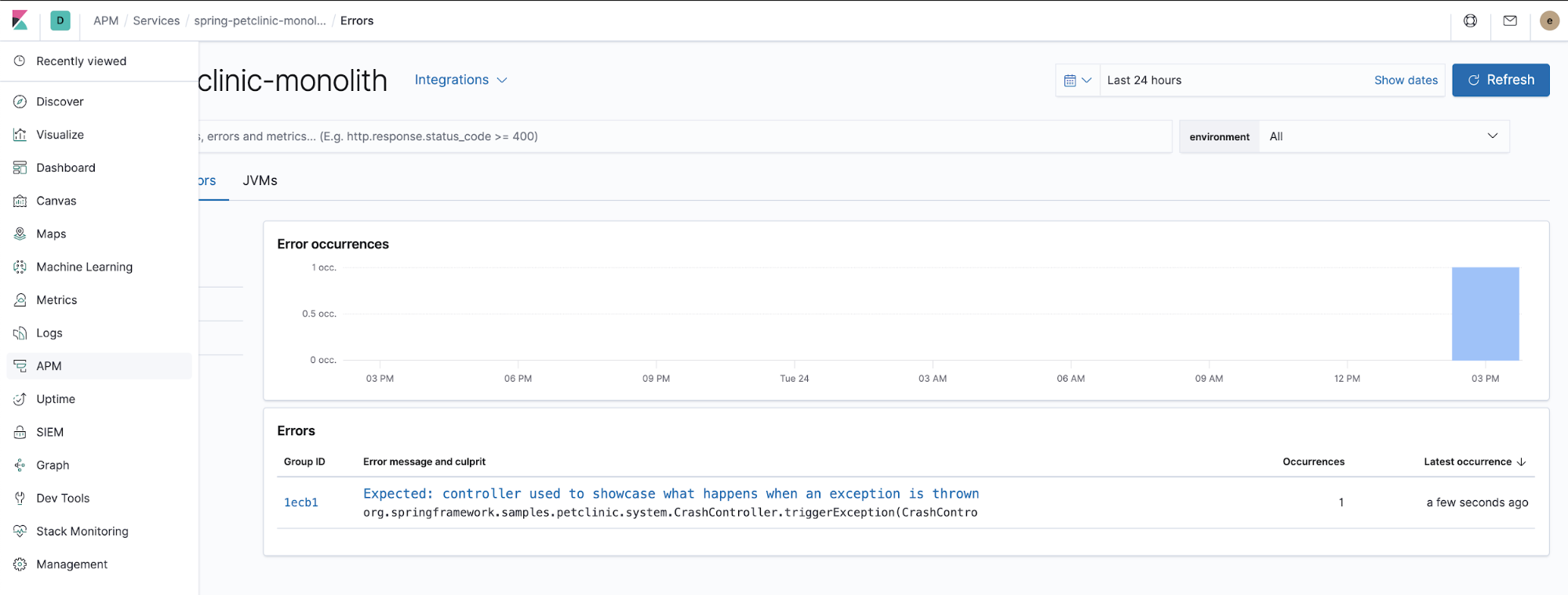
Der Java-Code, der dafür verantwortlich ist, wie der APM-Agent von der Anwendung ausgegebene unverarbeitete Ausnahmen erfasst, sieht wie folgt aus (aus $HOME/k8s-o11y-workshop/docker/petclinic/src/main/java/org/springframework/samples/petclinic/system/CrashController.java):
@GetMapping("/oups")
public String triggerException() {
throw new RuntimeException("Expected: controller used to showcase what "
+ "happens when an exception is thrown");
}
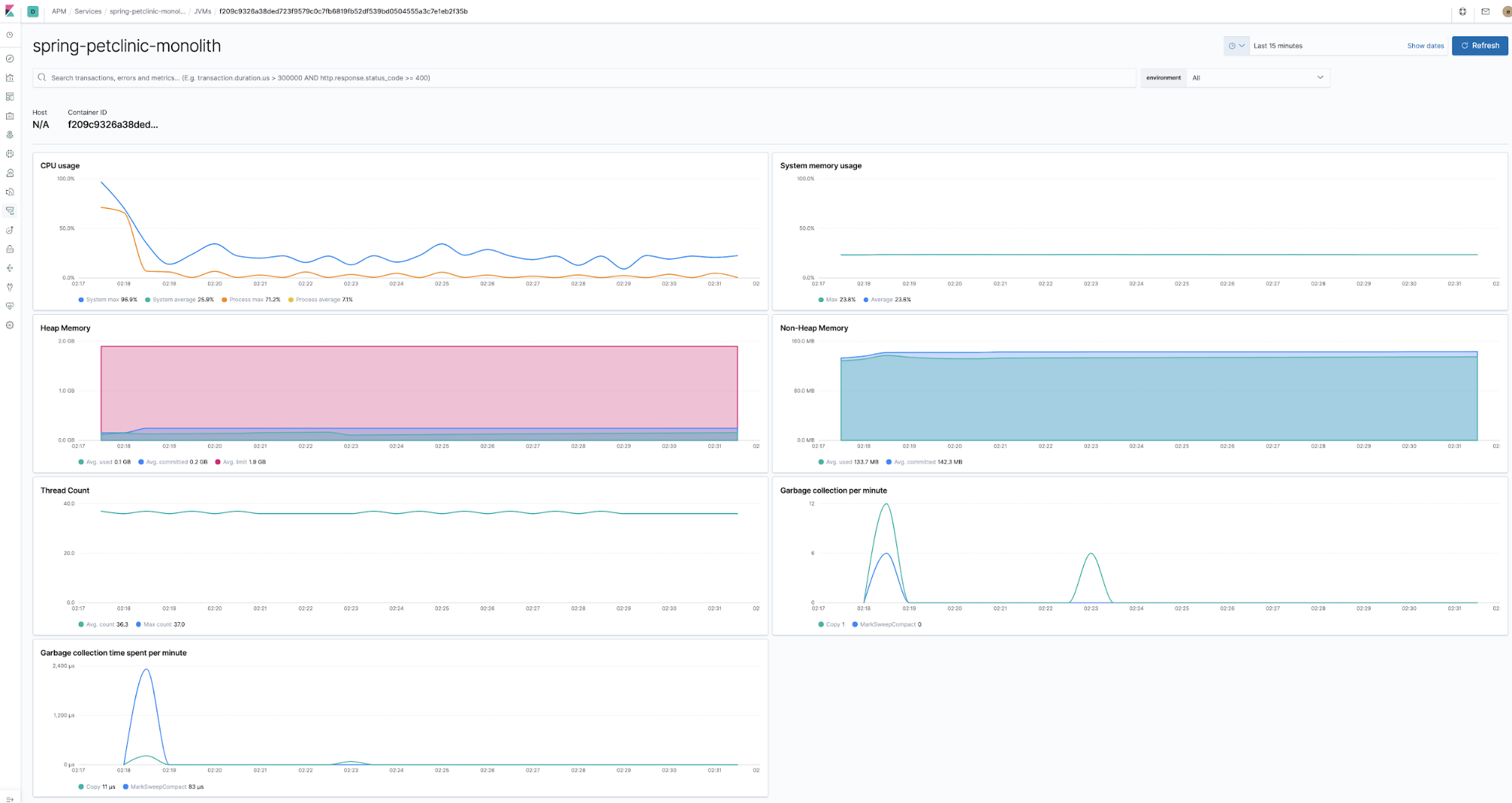
Überwachung von Laufzeitmetriken
Zusammen mit den Anwendungskomponenten werden zur Laufzeit Agents bereitgestellt, die Laufzeitmetriken erfassen, wie zum Beispiel der Java-Agent. Dieser Agent erfasst die Metriken nach entsprechender Aktivierung „out of the box“ ohne jeden zusätzlichen Programmier- oder Konfigurationsaufwand.
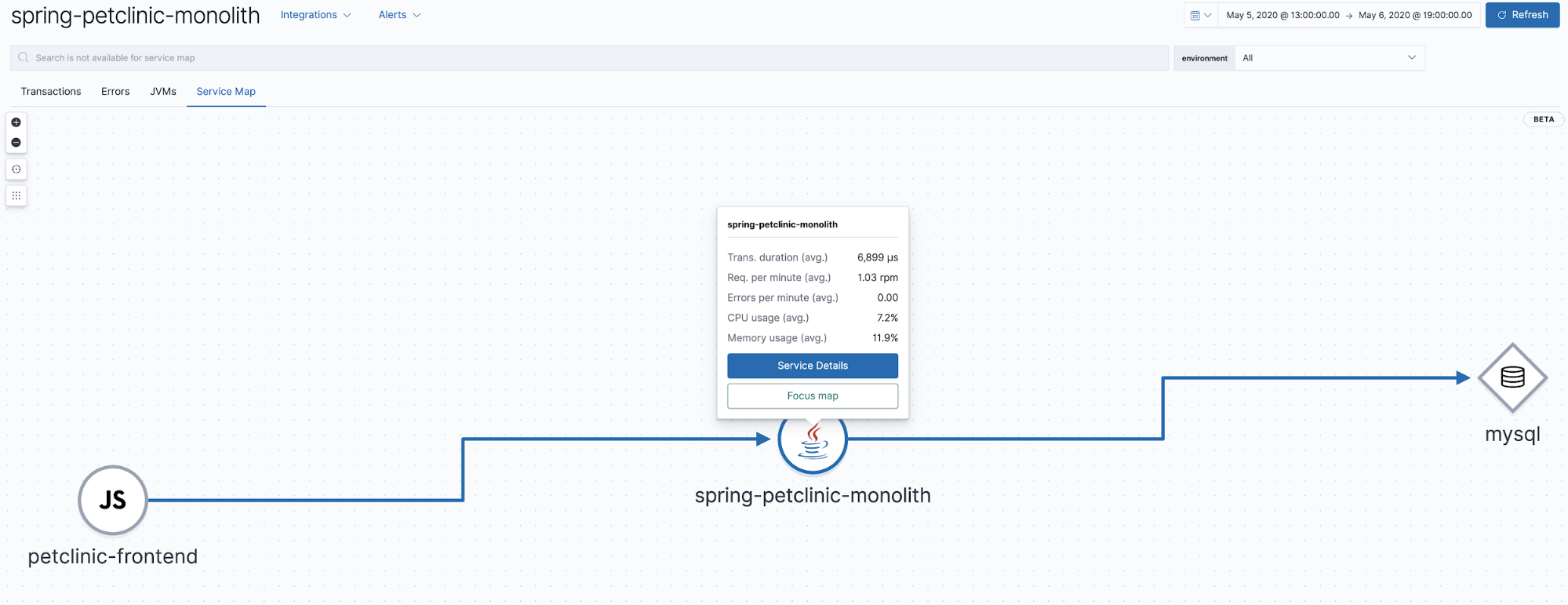
Service Maps
In Elastic APM 7.7 wurde mit der Betaversion von Service Maps eine Möglichkeit eingeführt, Beziehungen in APM-Traces grafisch darzustellen. Diese Ansicht zeigt, welche Komponenten an den in der App APM angezeigten Traces beteiligt sind. Unsere Anwendung ist sehr einfach: Sie besteht lediglich aus einem Browser-Client mit Java und einem MySQL-Backend. Die Service Map, die auf diese Weise entsteht, ist dementsprechend ebenfalls recht einfach gehalten.
Erfassen von JMX-Metriken mit einem Elastic APM-Agent
Der Java-Agent kann so konfiguriert werden, dass er von der Anwendung bereitgestellte JMX-Metriken erfasst. Die Petclinic-Komponente in diesem Tutorial ist in
$HOME/k8s-o11y-workshop/petclinic/petclinic.yml so konfiguriert, dass sie die folgenden Metriken erfasst:
- name: ELASTIC_APM_CAPTURE_JMX_METRICS
value: >-
object_name[java.lang:type=GarbageCollector,name=*]
attribute[CollectionCount:metric_name=collection_count]
attribute[CollectionTime:metric_name=collection_time],
object_name[java.lang:type=Memory] attribute[HeapMemoryUsage:metric_name=heap]
Visualisieren benutzerdefinierter Metriken mit Lens
In der App APM werden nicht alle Metriken dargestellt. So sind zum Beispiel die gerade erwähnten JMX-Metriken sehr anwendungsspezifisch und können daher nicht in der App visualisiert werden. Manchmal müssen Metriken auch in andere Visualisierungen einbezogen oder anders visualisiert werden, um wirklich nützlich zu sein. Zur nativen Visualisierung dieser Metriken können Kibana-Visualisierungen und ‑Dashboards verwendet werden, aber es gibt auch noch eine neue und durchaus spannende Möglichkeit, das noch schneller hinzubekommen.
Vor nicht allzu langer Zeit wurde Kibana um Lens erweitert. Lens ist ein intuitiveres Visualisierungstool speziell für Datenanalysten. Das folgende Beispiel zeigt, wie Lens verwendet werden kann, um eine vom Agent erfasste benutzerdefinierte JMX-Metrik zu visualisieren.
Beispiel zur Verwendung von Lens
Damit das Ganze etwas interessanter wird, möchten wir im Folgenden einen „scale-out“-Befehl ausführen, um die Zahl der Pods der Petclinic-Komponente zu erhöhen und so pro laufender JVM mehr als eine Zeile zu erhalten.
$ kubectl scale --replicas=3 deployment petclinic-deployment # Prüfen, ob scale-out gemacht hat, was es sollte $ kubectl get pods
Daraufhin sollte Folgendes zu sehen sein:
NAME READY STATUS RESTARTS AGE mysql-deployment-7ffc9c5897-grnft 1/1 Running 0 37m nginx-7ff654f859-xjqgn 1/1 Running 0 28m petclinic-deployment-86b666567c-5m9xb 1/1 Running 0 9s petclinic-deployment-86b666567c-76pv7 1/1 Running 0 9s petclinic-deployment-86b666567c-gncsw 1/1 Running 0 30m theia-86d9888954-867kk 1/1 Running 0 43m
Und jetzt kommt Lens dazu:
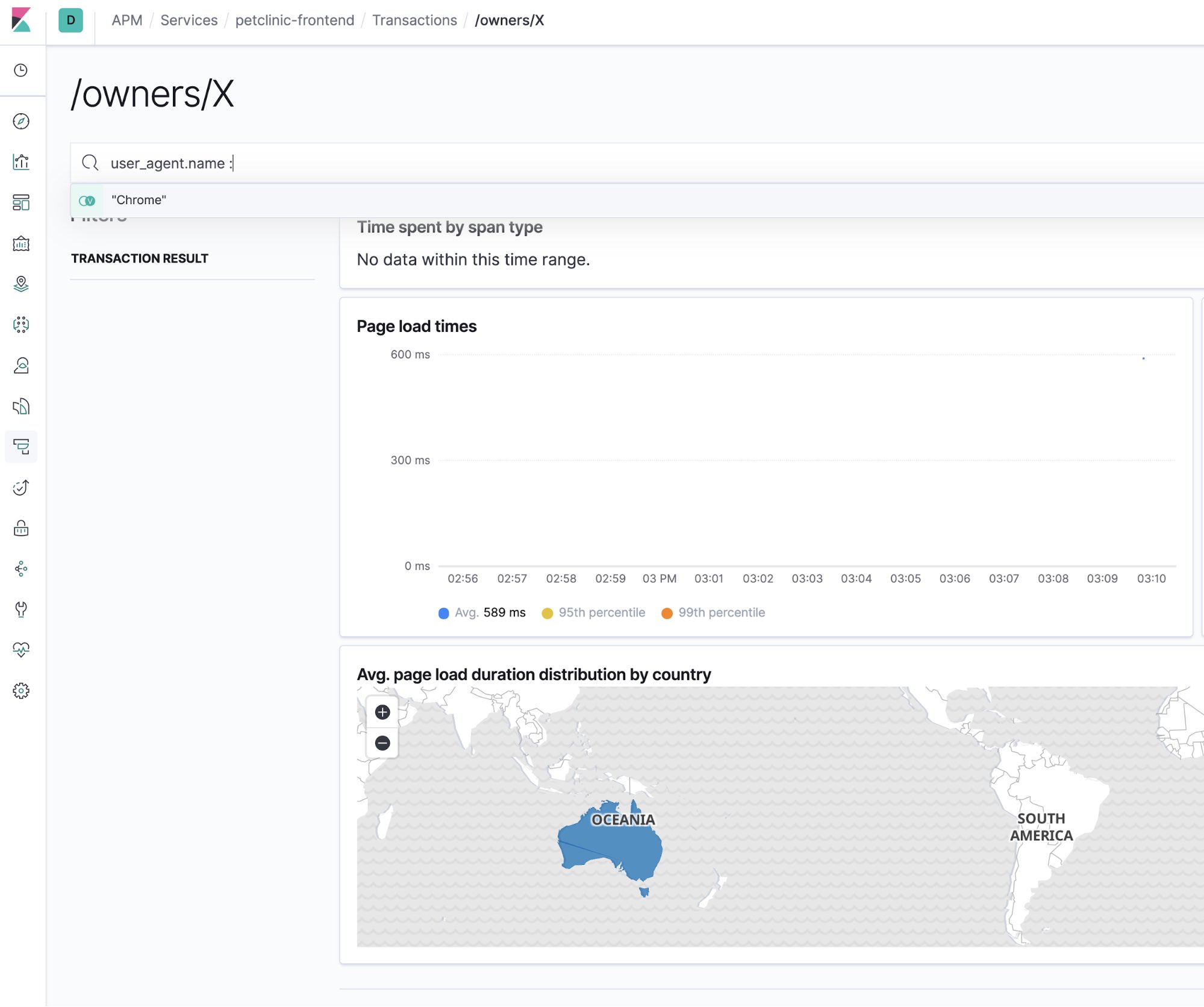
Suchleiste zum … Suchen
Natürlich gibt es in Elastic APM eine Suchleiste. Und die ist hervorragend dafür geeignet, die sprichwörtliche Nadel im Heuhaufen zu suchen, um das Ausmaß des zu beseitigenden Problems einzugrenzen. Die folgende Abbildung zeigt, wie die APM-Benutzeroberfläche auf einen konkreten Browsertyp eingegrenzt werden kann:
Korrelieren von APM-Traces und Logdaten
Ein weiterer Beleg dafür, dass ein Ganzes mehr als die Summe seiner Einzelteile sein kann, ist das Korrelieren von APM-Traces mit den Logdaten, die vom getraceten Code produziert wurden. APM-Traces können über das Feld trace.id<Code> mit Logdaten verknüpft werden. Mit ein paar einfachen Konfigurationen lässt sich dafür sorgen, dass das einfach so und ohne großen Aufwand passiert. Sehen wir uns als Erstes ein Beispiel für so eine Korrelation an.
Hier ist eine Trace:
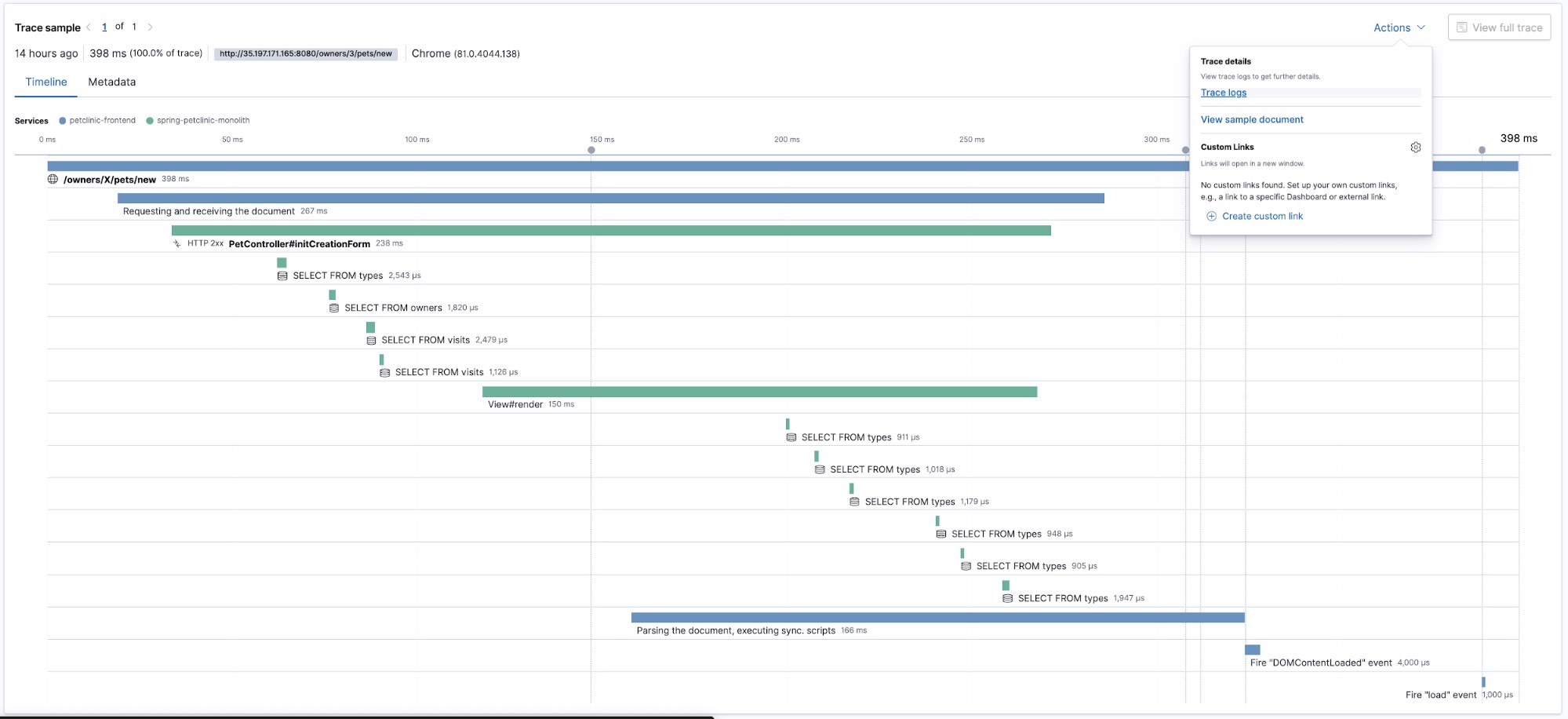
Diese Trace zeigt uns in der Zeitleistenansicht, wie unterschiedliche Teile des Codes ausgeführt wurden. Sehen wir uns nun an, welche Logdaten von dem Code erzeugt wurden, den wir gerade getracet haben. Dazu wählen wir im Menü „Actions“ Trace logs aus. Auf diese Weise gelangen wir zur Logs-Benutzeroberfläche, wo bereits die Zeit angezeigt wird, zu der die Trace-Daten erfasst wurden. Anhand der Trace-ID (trace.id) wird nach den Logdaten gefiltert, die mit derselben Trace-ID annotiert wurden:
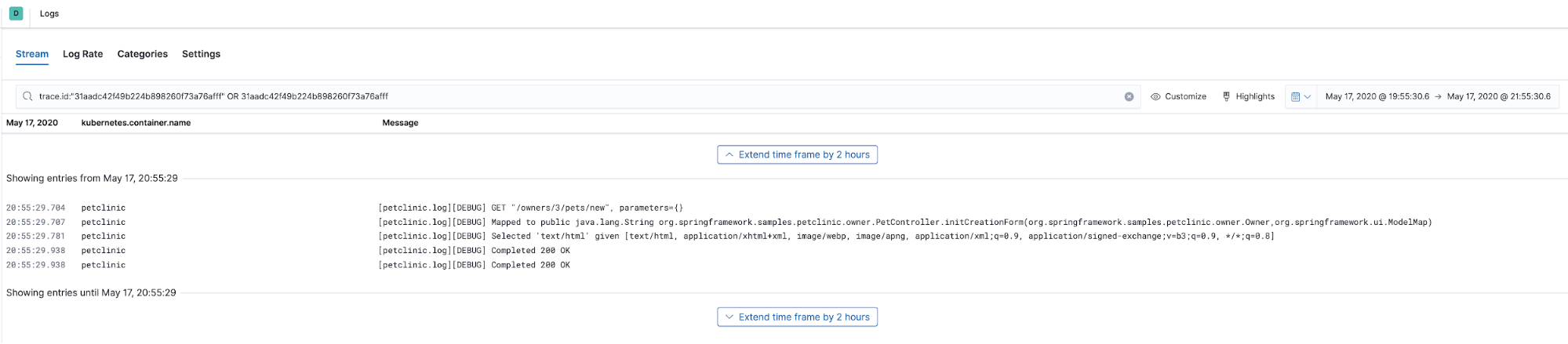
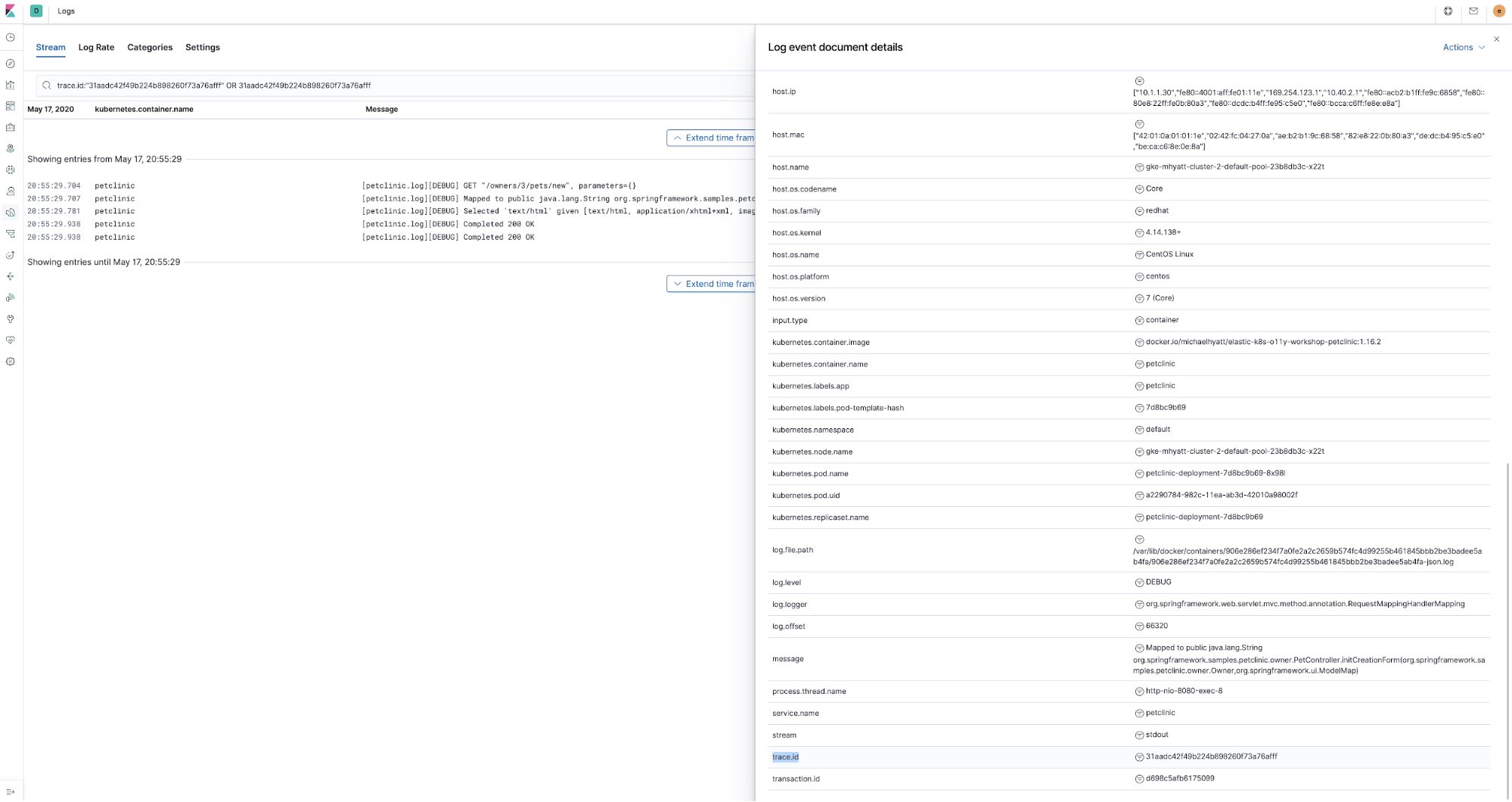
Klar, trace.id ist Bestandteil der APM-Traces, aber wie haben wir es geschafft, Logdaten damit anzureichern? Erstens arbeiten wir ja mit dem Elastic APM-Java-Agent, sodass wir die dort verfügbare Funktion zur Logdatenkorrelation nutzen können. Sie sorgt dafür, dass die Felder trace.id und transaction.id in der MDC-Kontext-Map des Java-Logging-Frameworks (bei Spring Boot „logback“) mit Werten versehen werden. Dazu muss lediglich in der Petclinic-ConfigMap (petclinic/petclinic.yml) die folgende Umgebungsvariable festgelegt werden:
- name: ELASTIC_APM_ENABLE_LOG_CORRELATION
value: "true"Anschließend wird das Logging für die Anwendung Petclinic mit ECS-Logging konfiguriert, sodass die an den Elastic Stack gesendeten Logdaten gemäß dem Elastic Common Schema mit zusätzlichen Feldern angereichert werden, wie log.level, transaction.id usw. Zu diesem Zweck haben wir in der Petclinic-Datei pom.xml die folgende Abhängigkeit festgelegt:
<dependency>
<groupId>co.elastic.logging</groupId>
<artifactId>logback-ecs-encoder</artifactId>
<version>${ecs-logging-java.version}</version>
</dependency>
Außerdem gibt es die Datei docker/petclinic/src/main/resources/logback-spring.xml, für die das ECS-Logging so konfiguriert wurde, dass die Logdaten als JSON an stdout ausgegeben werden:
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="co.elastic.logging.logback.EcsEncoder">
<serviceName>petclinic</serviceName>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="console"/>
</root>
Und schließlich sei noch auf die Annotation in der Petclinic-ConfigMap (petclinic/petclinic.yml) verwiesen, die Filebeat mithilfe von Beats-Autodiscovery anweist, die JSON-Ausgabe von Petclinic zu parsen:
container:
annotations:
...
co.elastic.logs/type: "log"
co.elastic.logs/json.keys_under_root: "true"
co.elastic.logs/json.overwrite_keys: "true"
Damit diese Korrelation funktioniert, müssen wir dafür sorgen, dass sowohl der Java-Agent als auch das Logging-Framework Trace-Korrelationen aufzeichnen. So können wir diese beiden Teile des Observability-Puzzles zusammenbringen.
Fazit
Logdaten, Metriken und APM-Traces … geschafft! In dieser Tutorial-Reihe haben wir uns angesehen, wie wir unter Verwendung von Filebeat, Metricbeat und APM eine Anwendung instrumentieren können, die es uns erlaubt, ihre Logdaten, Metriken und APM-Traces mit dem Elastic Stack zu erfassen. Außerdem haben wir gezeigt, wie es gelingen kann, Kubernetes-Logdaten und ‑Metriken mit denselben Komponenten zu erfassen. Das Elastic-Ökosystem bietet darüber hinaus zusätzliche Komponenten, mit denen Sie weitere Details hinzufügen können, um ein noch umfassenderes Bild Ihrer Kubernetes-Umgebung zu erhalten:
- Heartbeat eignet sich hervorragend, um die Uptime und Reaktionsfähigkeit Ihrer Anwendung und der gesamten Kubernetes-Umgebung zu messen. Es kann außerhalb Ihres Clusters in der Nähe Ihrer Nutzer bereitgestellt werden. Heartbeat verschafft Ihnen eine Idee davon, wie Ihre Nutzer Ihre Anwendung sehen, wie die Netzwerk- und Reaktionslatenzen auf Nutzerseite aussehen und wie viele Fehlermeldungen die Nutzer erhalten.
- Packetbeat ermöglicht Einblicke in den internen Netzwerkverkehr des Kubernetes-Clusters, die TLS-Zertifikat-Handshakes, die DNS-Lookups usw.
- Ich habe ein Beispiel-Deployment von Jupyter Notebook bereitgestellt und ein Beispiel-Notebook-Dokument hinzugefügt, das zeigt, wie Sie auf die in Elasticsearch gespeicherten Observability-Rohdaten zugreifen können, um mit ihnen richtig ernsthafte Datenanalysen anzustellen:
k8s-o11y-workshop/jupyter/scripts/example.ipynb
Ich lade Sie ein, sich am Github-Repo zu beteiligen oder ein Github-Issue zu erstellen, wenn es irgendwelche Probleme gibt.
Für einen schnellen Einstieg in die Überwachung Ihrer Systeme und Infrastruktur haben Sie zwei Möglichkeiten: Entweder Sie melden sich an, um den Elasticsearch Service auf Elastic Cloud kostenlos auszuprobieren, oder Sie laden den Elastic Stack herunter und hosten ihn lokal. Nachdem alles eingerichtet ist, können Sie mit Elastic Uptime die Verfügbarkeit Ihrer Hosts überwachen und mit Elastic APM die Anwendungen instrumentieren, die auf Ihren Hosts ausgeführt werden. Auf diese Weise sorgen Sie für komplette Observability in Ihrem System, vollständig in Ihren neuen Metriken-Cluster integriert. Wenn Sie auf Probleme stoßen oder Fragen haben, wird Ihnen in unseren Discuss-Foren sicher schnell weitergeholfen.