Elasticsearch 8.16: Production-ready hybrid conversational search and an innovative quantization for vector data that outperforms Product Quantization (PQ)


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Elasticsearch 8.16 introduces BBQ (Better Binary Quantization) — an innovative approach to compressing vectorized data that outperforms traditional methods, such as Product Quantization (PQ). Elastic is the first vector database vendor to implement this approach and enable this capability to be used in real-world search workloads and reduce the necessary computing resources while maintaining low query latency and high ranking quality.
This release also brings the general availability of Reciprocal Rank Fusion (RRF), Retrievers and the open Inference API, and a comprehensive suite of tools to streamline workflows to build hybrid search and retrieval augmented generation (RAG)-based applications.
Elasticsearch 8.16 is available now on Elastic Cloud — the only hosted Elasticsearch offering to include all of the new features in this latest release. These capabilities are also available in fully managed Serverless Elasticsearch projects on Elastic Cloud.You can also download the Elastic Stack and our cloud orchestration products — Elastic Cloud Enterprise and Elastic Cloud for Kubernetes — for a self-managed experience.
To get started with Elasticsearch for local development run, check out our start-local script to get a local deployment in minutes on your laptop.
curl -fsSL https://elastic.co/start-local | sh
What else is new in Elastic 8.16? Check out the 8.16 announcement post to learn more >>
Elastic does BBQ
Meet Better Binary Quantization (BBQ), a cutting-edge optimization for vector data that achieves up to 32x compression benefits on vector data without compromising on accuracy. Elastic is proud to be the first to provide this capability to users of our distributed and scalable Elasticsearch vector database for the reduction and scale of workloads that depend on large data sets.
This is first available to Elastic customers only but will rapidly be contributed to the Lucene community to elevate the potential capabilities of all vector stores.
BBQ preserves high ranking quality while achieving nearly the same speed and storage efficiency of scalar quantization. Its high compression levels enable organizations to effectively manage large data sets and scale their vector storage and search operations affordably. Additionally, BBQ reduces memory usage by over 95% while retaining excellent recall even as data sets expand. It can also be easily combined with other quantization methods in Elasticsearch for maximum benefits.
Hybrid conversational search, more tools without the complexity
Hybrid search is a pivotal technique in managing relevance for search experiences. By combining the precision of lexical keyword search with the contextual understanding of semantic search, ecommerce catalog search can retain precision while gaining semantic understanding. Additionally, RAG and conversational search experiences can reduce hallucinations with the context provided to the LLM.
While there are several methods to achieve hybrid search, including weighting of scores, the easiest approach to normalizing scores between retrieval approaches has been RRF. Elastic first integrated RRF as a technical preview in 8.8 and increasingly simplified usage with the subsequent introduction of the composable retrievers abstraction into the query DSL. The combination of these capabilities made building hybrid search as easy as one query call to /_search.
The following is pseudo code that combines three types of retrievers — one for a match query, one for vector (kNN) query, and another for a simple semantic query (using the inference service specified in the inference API). These three retriever results are quickly normalized with RRF. Plus, one more retriever for easy semantic_reranking for second stage retrieval and increased relevance. The full stack of relevance capabilities can be that simple for your production workloads!
"retriever": {
"text_similarity_reranker": {
// ... semantic reranking parameters
"retriever": {
"rrf": {
"retrievers": [{
"standard": {
"query"."semantic": {
"field": "a-semantic_text-field",
"query": "why are retrievers fun?"
}}},{
"knn": {
// ... knn parameters
// ... query_vector_builder parameters
"model_text": "why are retrievers fun?"
}}}},{
"standard": {
"query"."match": {
"some-field": "why are retrievers fun?"
}}}}]}}}}Now, both of these key capabilities — retrievers and Reciprocal Rank Fusion (RRF) — are generally available for Enterprise licensed customers, enhancing composability and performance for confident production deployments. 8.16 supports multilevel nesting with all features available at each level, paving the way for Learning to Rank (LTR) and rules-based retrievers.
Tired of irrelevant search results? Easily exclude specific results using exclude Query Rules, ensuring your users get more accurate and focused search outcomes.
Elastic’s open inference API — also now generally available — enables you to create endpoints and use machine learning models from popular inference providers. These endpoints can be used in semantic_text for easy retrieval with retrievers for semantic queries, kNN queries, and semantic reranking. Our catalog of integrated inference providers include Anthropic, Mistral, Cohere, and more! In 8.16, we now provide support for Watsonx.ai Slate embedding models and Alibaba Cloud AI embedding models, reranking capabilities, and completion support for the Qwen LLMs family.
Additionally, semantic_text now supports new adjustable chunking options, giving users the flexibility to modify our native chunking strategy for vectorized data from word chunking to sentence and to adjust chunking window size.
Customers can also use completion task types in the inference API in their ingest pipelines for enriched document processing and storage of summarization. This pairs especially well with our catalog of Elastic integrations, such as the Elastic Open Web Crawler and connectors.
Empowered developer experience
Great search experiences are built by developers. Kibana has been updated to include affordances that make Kibana a better experience to iterate on all the potential combinations of machine learning and tuning. The ability to quickly do this in code and in Kibana can accelerate changes that positively impact click-to-conversion rates or refine the summarization of key insights to an organization.
Starting first with a customizable navigation option, developers have direct access to the tools that matter.
Playground has been enhanced with session persistence and the ability to support follow-up questions. Using Playground against a PDF or a Word document upload is even easier, making experimentation with files faster and more efficient. Paired with the ability to export dev console requests to Python and Javascript, iteration and incorporation into your preferred development environment is merely a copy command away.
Tap into our open source innovations with 8.16, featuring the Elastic Open Web Crawler — now in beta — managed via CLI for efficient website data ingestion and storing vector data in Elasticsearch’s top-tier vector database. Additionally, get started in minutes with the new start-local feature, allowing you to spin up Elasticsearch and Kibana locally in just one step for quick trials and evaluations.
Elastic AI Assistant for Search
Improve how you use Elasticsearch and Kibana with a built-in Elastic AI Assistant for Search. Not only can you benefit from the capabilities of Elastic to build your own RAG-based conversational agent or application, you can also benefit from one provided out of the box for accelerated onboarding and get help within the Elastic deployment.
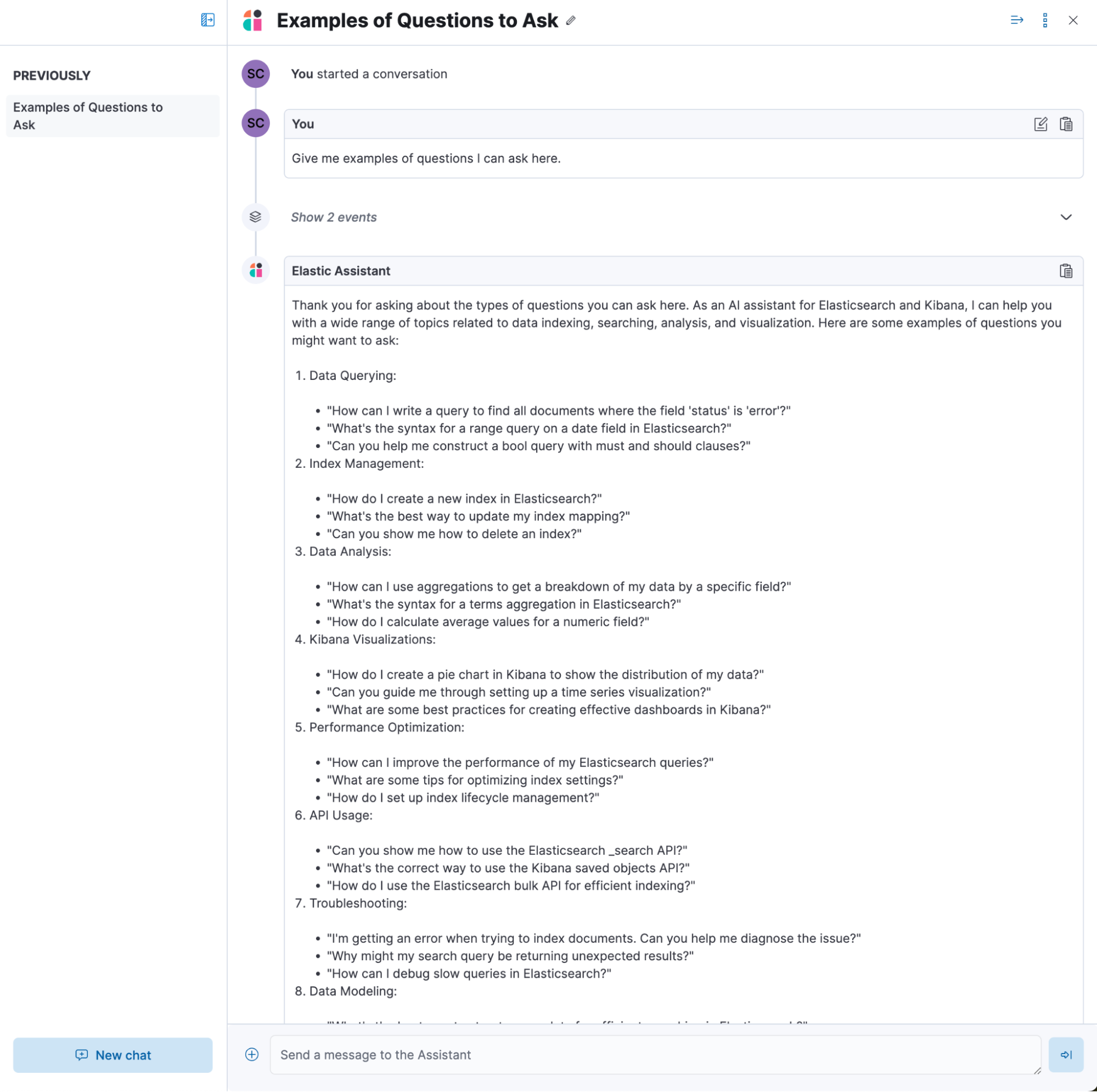
All Elastic AI Assistants benefit from custom knowledge — bring and import your knowledge base or use existing indices to use a customized AI-driven help center that onboards your team to the power of Elastic quickly. Web crawlers and connectors can be used to enhance and sync with third-party sources of data that house your knowledge and personalize your Elastic AI Assistant experience.
Try it out
Read about these capabilities and more in the release notes.
Existing Elastic Cloud customers can access many of these features directly from the Elastic Cloud console. Not taking advantage of Elastic on cloud? Start a free trial.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print