Testing the new Elasticsearch cold tier of searchable snapshots at scale
The cold tier of searchable snapshots, previously beta in Elasticsearch 7.10, is now generally available in Elasticsearch 7.11. This new data tier reduces your cluster storage by up to 50% over the warm tier while maintaining the same level of reliability and redundancy as your hot and warm tiers.
In this blog, we’ll take a look at the scenarios we’ve explored to make sure that the cold tier works flawlessly at scale, underlining the importance we place on quality and reliability of our solutions.
Cold tier refresher
The cold tier reduces your cluster costs by keeping only the primary shards on local storage, doing away with the need for replica shards and instead relying on snapshots (kept in object stores like AWS S3, Google Storage, or Microsoft Azure Storage) to provide the necessary resiliency. The local storage essentially acts like a cached version of the snapshot's data in the repository.
In the case of a cold node or local storage becomes unhealthy, searchable snapshots will automatically recover and rebalance the shards onto other nodes.
In the case of full-cluster or rolling restarts (or node reboots), local storage is persistent and data available locally will not be re-downloaded from snapshots, minimizing the time needed to get back to a green cluster as well as avoiding unnecessary network costs.
To ensure all of this works as expected at scale, we focused our validation efforts on three scenarios, all using:
- Five Elasticsearch nodes (16G heap)
- Six 2TB magnetic disks in RAID-0 configuration
- A 5TB snapshot of logging data, spread across 10 indices with five shards each, force merged down to one segment (force-merging optimizes the index for read access and reduces the number of files that need to be restored in case of a failure event)
Scenario 1: Full cluster restart
The first scenario we validated were full-cluster restarts. To verify this we went through the following steps:
- Mount the 5TB searchable snapshot and wait for the local cache to be fully prewarmed (Phase 0).
- Execute a full-cluster restart according to the full-cluster restart guidelines.
- After re-enabling allocation, measure how long it takes for the cluster to:
- Become green.
- Finish all background downloading to prewarm the caches.
- Ensure there is no additional shard rebalancing after step 3.
Thanks to the persistence layer that was newly introduced in Elasticsearch 7.11, after starting all nodes and re-enabling allocation, the cluster became green immediately and no background downloading took place.
Below we can see the cumulative network traffic during mounting (Phase 0) and after a full cluster restart and re-enabling allocation (Phase 1, no additional network traffic):

Scenario 2: Rolling restart
The second scenario we validated was the common case of rolling cluster restarts.
The experiment was similar to the full-cluster restart:
- Mount the 5TB searchable snapshot and wait for the local cache to be fully prewarmed.
- Execute the rolling restart procedure for the first node by disabling shard allocation prior to stopping each node.
- Start the node and after re-enabling shard allocation, measure the time it would take to get to green. We expected this to be fast due to the persistent cache. We also made sure no unnecessary background downloads were taking place after each restart.
- Repeat steps 2 and 3 for all the other nodes in the cluster.
This experiment was also a success and thanks to the persistent cache, introduced in Elasticsearch 7.11, getting to green was practically instantaneous and no additional background downloads from the snapshot took place.
Scenario 3: Node crash
Finally, we wanted to ensure correct behavior when one node crashes. We ran the following experiment:
- Mount the 5TB searchable snapshot and wait for the local cache to be fully prewarmed (Phase 0).
- From the five nodes, kill one Elasticsearch node (node-1, using SIGKILL) and wait until the cluster becomes green again (Phase 1).
- Ensure background downloads are related to receiving data from shards hosted by the killed node.
- After getting to green no additional rebalancing should be taking place.
- Start the failed node again (Phase 2):
- Only peer recovery should be taking place (since all data exists on the remaining four nodes) to rebalance shards.
- Cluster should get to green.
Again, this experiment was successful. After node-1 got killed, the remaining nodes automatically restored the shards (from searchable snapshots) hosted by the missing node.
No additional rebalancing happened after the cluster became green, as can be seen in the chart below visualizing the network traffic per node:
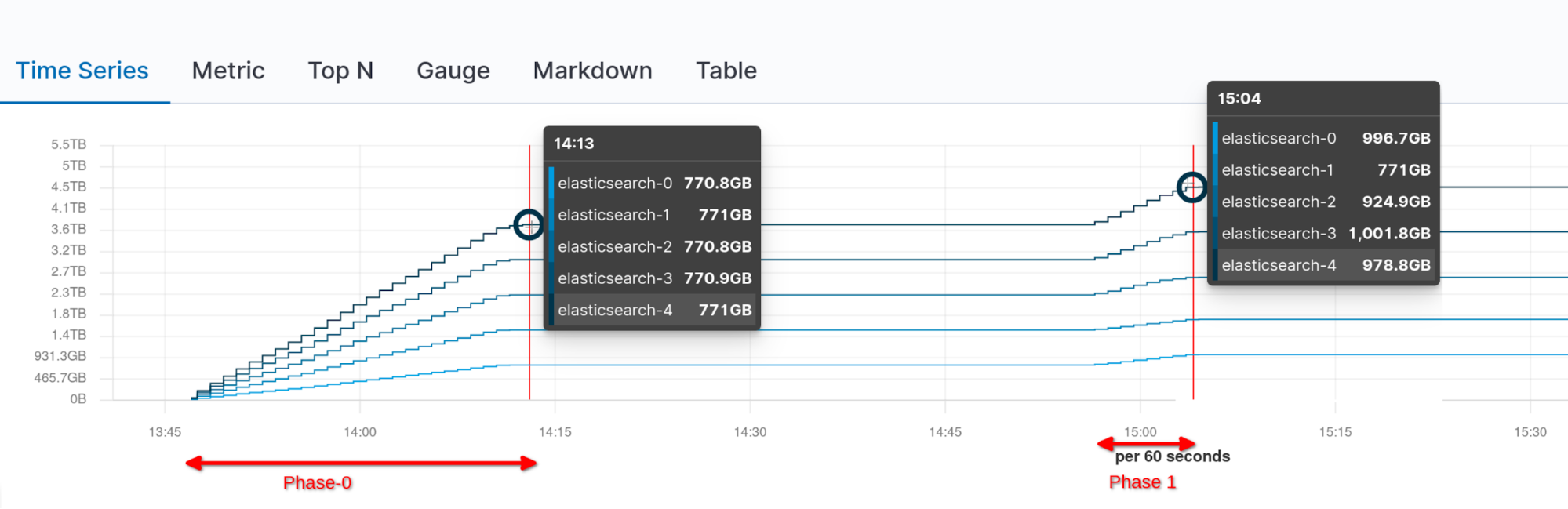
After bringing back the missing node, peer recovery kicked in and node-1 ended up hosting again the necessary amount of shards to have an evenly distributed cluster.

Get started today
We hope this journey of feature validation was as interesting to you as it was exciting to us!
To get started with searchable snapshots and begin storing data in the cold tier, spin up a cluster on Elastic Cloud or install the latest version of the Elastic Stack. Already have Elasticsearch running? Just upgrade your clusters to 7.11 and give it a try. If you want to know more you can read the data tiers and searchable snapshots documentation.