Stretching the Elastic Stack to Fit the (Very Large and Complicated) Human Genome
The Human Genome Project was supposed to cure all the diseases. At least, that's what the general public thought back in 2001 when the results of the project were first shared. But scientists suspected all along that uncovering the root of all human disease would be a bit more complicated — and they were right. The data could be collected, but making use of it was going to take years of grueling and tedious work.
Daniel Myung and Bhasker Bokuri are two scientific computing experts at Merck Pharmaceuticals who presented at Elastic{ON} on March 9, 2017 about how their innovative approach to managing genomic data with the Elastic Stack opens new vantages for geneticists. Using the Elastic Stack, scientists can see their data in new ways that uncover safer, more effective treatments for diseases like cancer, Alzheimer’s, and diabetes.
“The pharmaceutical industry still has a pretty low batting average,” said Myung. “There’s all this work and all this effort. It’s pretty expensive and there’s still this low hit rate of [a product idea] actually being safe and effective.” They want to use genetic data to better predict in the discovery phase how a drug will affect the body long before expensive trials. The goal is to speed the production of effective treatments and make drugs cheaper for all.
They want to use genetic data to better predict in the discovery phase how a drug will affect the body long before expensive trials.
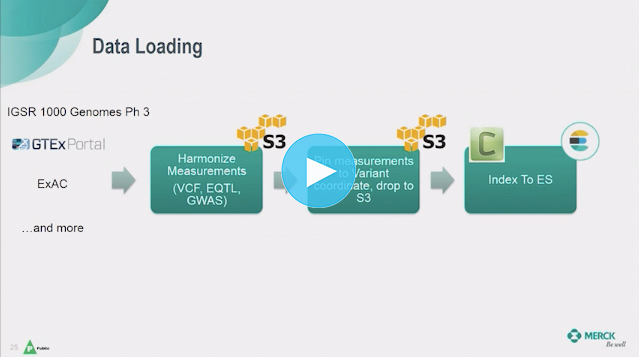
As sequencing costs have fallen from tens of millions of dollars to around $1,000 to sequence a whole genome, thousands of studies have been pouring in from academia, public sources, and consortium efforts among multiple pharmaceutical companies. The consortium efforts are the source of most of the de-identified, aggregate data in Merck's database. The problem Myung and Bokuri face is that the data is unwieldy. There is so much of it, it’s in multiple formats from diverse sources, and the methods that have produced this 13 years-and-counting’s worth of data change every few years. Previous methods of handling this data, as Myung and Bokuri described, were tedious, manual, and required a significant amount of expert integration. It could take two days to add a single field.
Myung and Bokuri have used Elastic products to make a pipeline that ingests and harmonizes the diverse data into a rapidly searchable database and creates a universal coordinate system for genetic variants. The size and the weird shape of their data fit well into Elastic.
The size and the weird shape of their data fit well into Elastic.
They approach it like a weather map, but instead of using location, temperature, humidity, pressure, and wind speed data to make weather predictions, they use genetic variant locations, epigenetic effects, phenotype expression, GWAS, and eQTL data to help researchers predict the efficacy of a drug. It’s not perfect, just like weather forecasts aren’t perfect, but it presents search results in hours that used to take weeks. And it helps researchers find better places to aim their questions and hopefully raise that pharmaceutical batting average.
Interestingly, this method works in retrospect. Myung displayed a graph from the genetic database of the gene targeted by the successful cholesterol drug Lipitor — a known pharmaceutical home run.The graph displayed some interesting effects. If geneticists had run a search on this gene using the new Elastic database, they would have seen these effects and recommended this gene as a target for new medications.
The database is promising, but it’s not done yet. “This is a start,” said Myung. “We’ve put something in a database and you can search things now.” Myung and Bokuri are still looking for ways to support the geneticists who make those data-driven decisions. In the future they hope to apply machine learning or statistics to the data.
If you’re interested in their approach to working with complex and important data, dive in and check out their Elastic{ON} presentation and slide deck.