The strata of data: Accessing the gold in human information


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
I married into a family of geologists and rock and gem enthusiasts, and that bit of serendipity has added immensely to my life. Whenever we go on family hike excursions, I learn so much more about the landscape than I could have ever hoped to from my own educational path, and as a bonus my home gets adorned with tastefully and expertly chosen specimens from around the world. While I can’t possibly compare myself in that realm of knowledge, I still find the concepts fascinating, beautiful, and strangely relatable to my own vocation in the world of data and search.
Take the geological concepts of strata (the plural of stratum), which are the layers of dirt and rocks that get laid down and modified by geological activity over millennia. The variances in those layers are described by the fundamental concepts of original horizontality, superposition, cross-cutting relationships, and intrusion. When you look at a vast landscape like the Grand Canyon, what you’re able to see is the result of interactions between glacially slow accumulations that have been impacted by sometimes sudden and powerful events, and every inch of it gets steadily weathered by the slow march of time.

That’s beautiful (and maybe even interesting), but how the heck does geology relate to data? Perhaps even more pointedly, why would you even want to? Well as the saying goes, a picture is worth more than a thousand words, and a mental image of the way data resides in our environment should help us better understand how best to store, manage, and leverage it for its intended purposes.
There are essentially three distinct layers of data (especially noticeable at the scales of “big data”) that together form what can be described as the “strata of data.” Each of these layers can be likened to a different geological stratum, where instead of the different makeup and densities of rock and sediment, we have new incoming data continuously sprinkled over the top of previously deposited data. Those layers eventually get compacted into new forms, the oldest of which we consider frozen and not directly accessible. That accessibility, the usability of the data, is really what delineates the boundaries between the strata, as there are different data operations available at each layer. In many respects it’s those operational limitations that define the relative value that we’re able to derive from the data stored at each layer. This visual of layer upon layer applies to data of all types, including events, metrics, structured, unstructured, and semi-structured.
Starting from bedrock
Just for fun, let’s create some formal-sounding Latin names for each of the layers in the “strata of data” to refer to and describe them with:
Machine Data — Lapillus Machina: A combination of the Latin words for “machine” and “little stones” or pebbles. The name of this layer denotes lots of individual data elements that aren’t yet connected to anything else; at this layer each individual data record is most efficiently processed through binary decision trees by machines (hence Machina).
Data is generated everywhere in the organization: it’s constantly flowing in from the edge, networks, and from a multitude of applications, sensors, and devices all in different formats and often through different protocols and interfaces. The collected data usually gets laid down into the data landscape in a raw state, frequently using a message queueing technology that ensures data is reliably received and made available for delivery to downstream consumers.
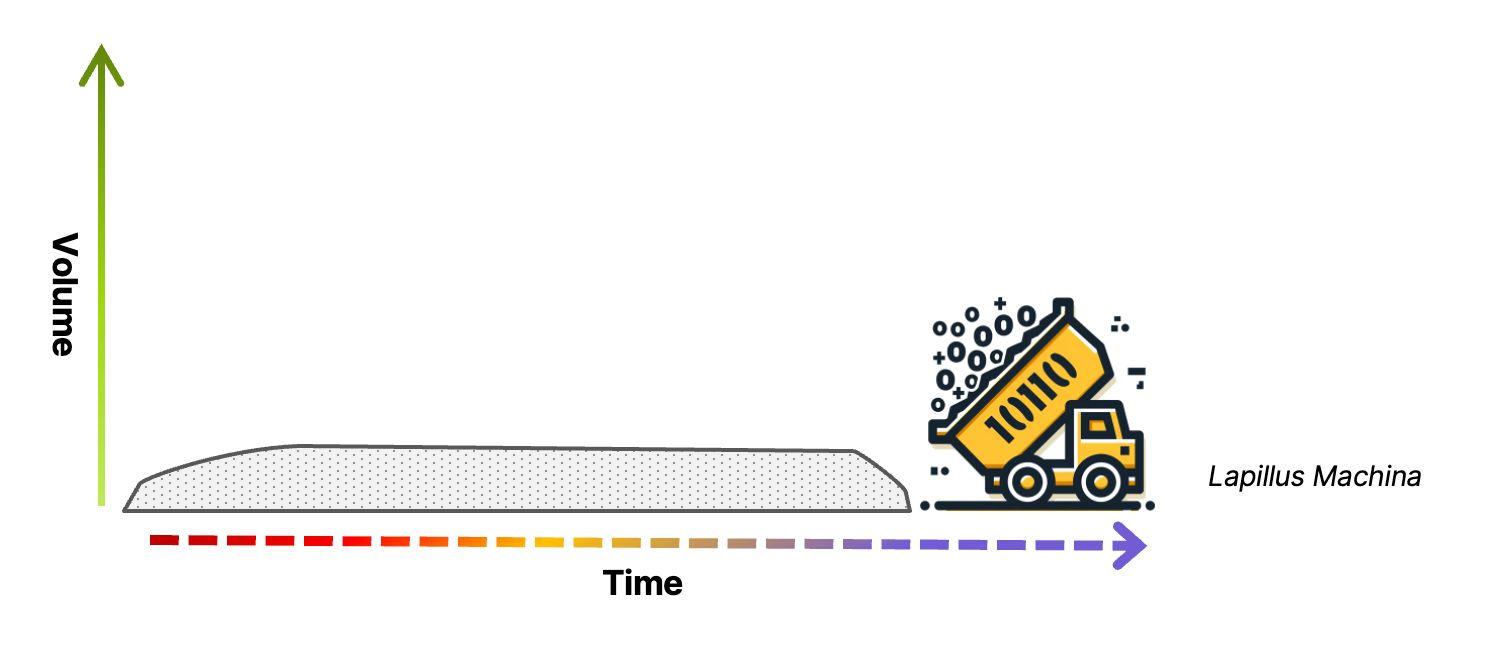
Message queues can serve several very important purposes in the architecture: in addition to receiving and delivering data, they can help to smooth the flow of data to the consumer applications by throttling the throughput across peaks and valleys, and they can perform some low-level operations like enrichments, manipulations, and routing to other workflows based on metadata values. What they can’t do is connect information found in the collected individual data records in any associated way.
In its raw state, data is not fully usable in the sense that it’s unable to be correlated with other data or actively retrieved by anything other than the metadata. This layer is associated with Machine Data because machines are especially suited to this type of activity, where operations are limited to an individual record. The operational limitations at this layer are partially due to the fact that only the metadata is available to analyze, but also the human-level understanding (based on a searchable memory) that can correlate multiple data points together and infer meaning is not possible.
Human Data — Terra Humanus: The Latin combination of “Earth” and “human.” At this layer, the data has been ingested into a platform that can query, analyze, and correlate multiple data elements together; this is the layer that humans specifically can use to make sense of, interact with, and make use of unified data.
As the raw data is consumed by downstream applications, it gets transformed into a new state, that of Terra Humanus. I’ve termed this layer the Human Data layer because this is where we are able to interact with the data in meaningful ways. We humans largely find meaning by creating and matching patterns within disparate data, and to do that we need a memory to call upon, a place to search within to find those matches. This layer is where data is extracted and analyzed together for a myriad of uses — data really does want to be free, and it should be made available to any and all use cases it might be relevant to.
My intuition says there are probably far more data platforms in the world than there are different types of geological materials. That’s actually a bad thing in that ingesting the same data into different platforms can actually isolate the information inside a single use case (and limit the ways to access it, limit the analysis capabilities, etc.) and make it harder for data to be reused; in other words, it creates the dreaded data silos. So rather than a single, smooth, easily navigated Human Data layer, one might imagine this as a layer of large loose rocks that aren’t connected to each other at all. It’s so bad we’ll have to rename it Terra Disfunctio.
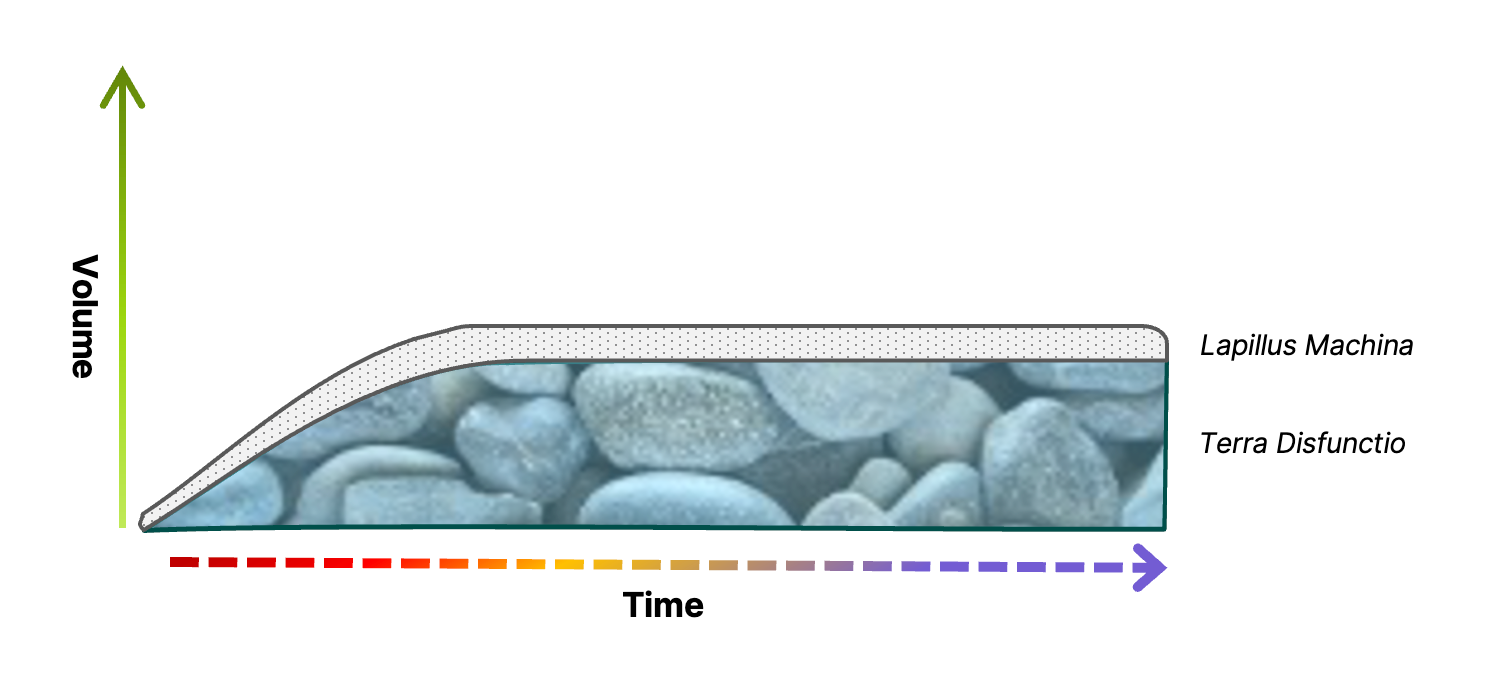
There are lots of reasons for this state of affairs taking hold, including some that until fairly recently were unassailable technological and cost limitations. The underlying (and often unmet) requirement for all data flowing into the Terra Humana layer is to be able to query, correlate, and understand all of it together — we collect data in order to make use of it. As anyone who’s ever wielded a shovel will confirm, digging in smooth, uniform material (be it dirt, or sand, or data) is much faster and easier than trying to pick your way through disconnected rocks and stones. I think this point by itself strongly makes the case for integrating all systems and use cases at the data layer, but before we get to that let’s complete the “strata of data” picture.
Archived Data — Gelida Lacus: Latin for “frozen lake.” Almost self-explanatory, data in this layer is normally kept in a frozen, inaccessible state that requires restoring to a “warmer” state (a Terra Humanus) in order to be queried or interacted with. The frozen data archive has been largely replaced with the “data lake” (Datum Lacus) — more on that later.
As mentioned, there was a time not all that long ago when the cost factor to keep data alive and accessible for interactive querying was insurmountable. So began the rise of the frozen data archives (Gelida Lacus), which are platforms meant for long-term data storage but aren’t capable of fast, flexible retrieval, much less interactive querying. In addition to the traditional kinds of archived data required for compliance, investigations, or records management, those cost concerns mentioned earlier have forced the typical big data organization to store a large percentage of its Human Data in these frozen lakes as well.
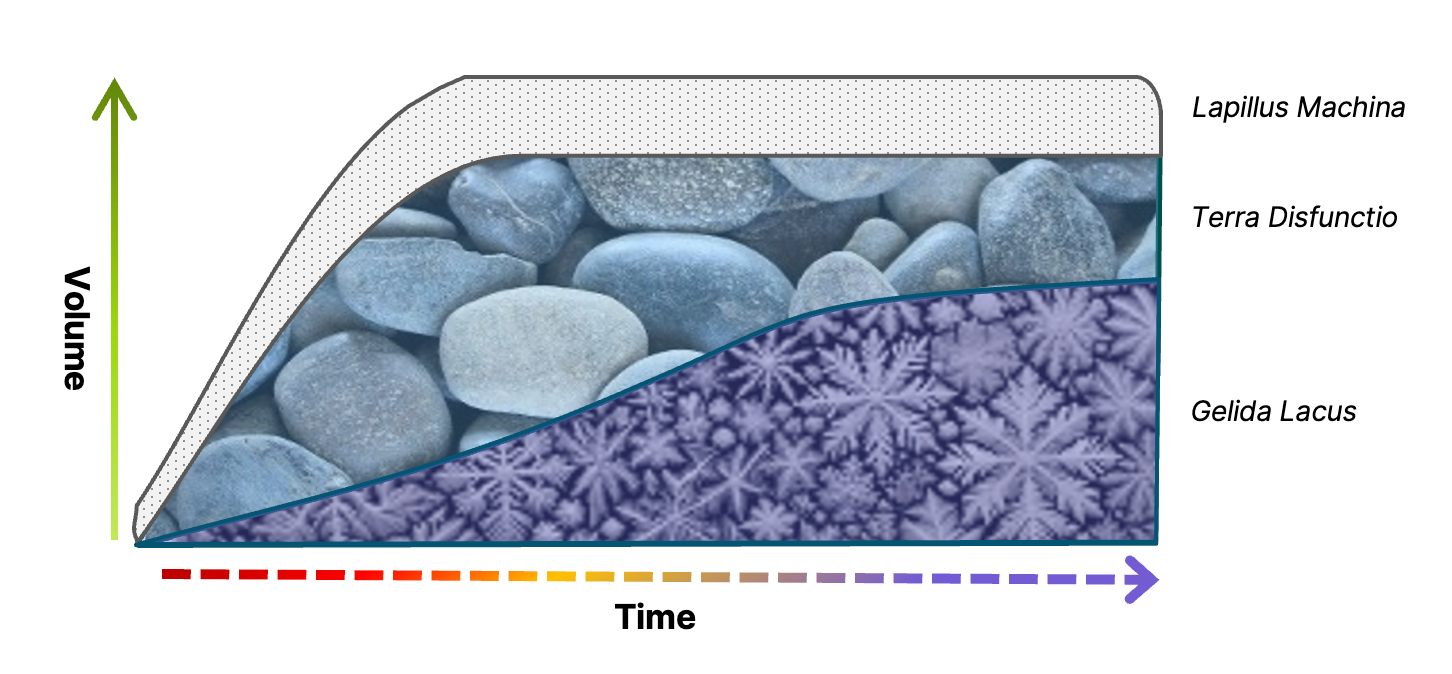
Data archives can usually only retrieve the data within them via metadata (hmm, kind of like Lapillus Machina), and the platforms that do allow finding by the contents within the records are very limited in the query mechanisms they provide — often the background search mechanism amounts to a very slow keyword-based table scan of every. single. record.
As time has gone by, low-cost resilient and highly available object stores (S3, blob stores, etc.) have gradually taken the place of shared drives and SANs as the cold storage. With object stores came new technologies designed to span those large data stores and overcome some of the searchability shortcomings of the past. Most of these new technologies have chosen relational databases as the query model and interface (though I know there are differences, I’m including columnar stores and dataframes in this description). These so-called “data lake” technologies (Datum Lacus) are more than an evolution of the frozen archives; they are a huge step forward and can be extremely powerful for specific use cases (especially those involving large-scale number crunching), but for the purposes of Human Data you simply can’t do everything you need to be able to do with SQL. In the larger view, having some portion of the data that you need for human analytics in a data lake presents us with yet another data silo that has to be merged with Terra Disfunctio in order to get the full picture.
The relative value of data over time
Now that we have a view of the different states of data across the strata, we can explore some of the forces at work within the layers. Two factors that can have a large influence on how relevant a given bit of data is perceived are the age of the data and the data’s provenance or relative importance of the data to our daily operations.
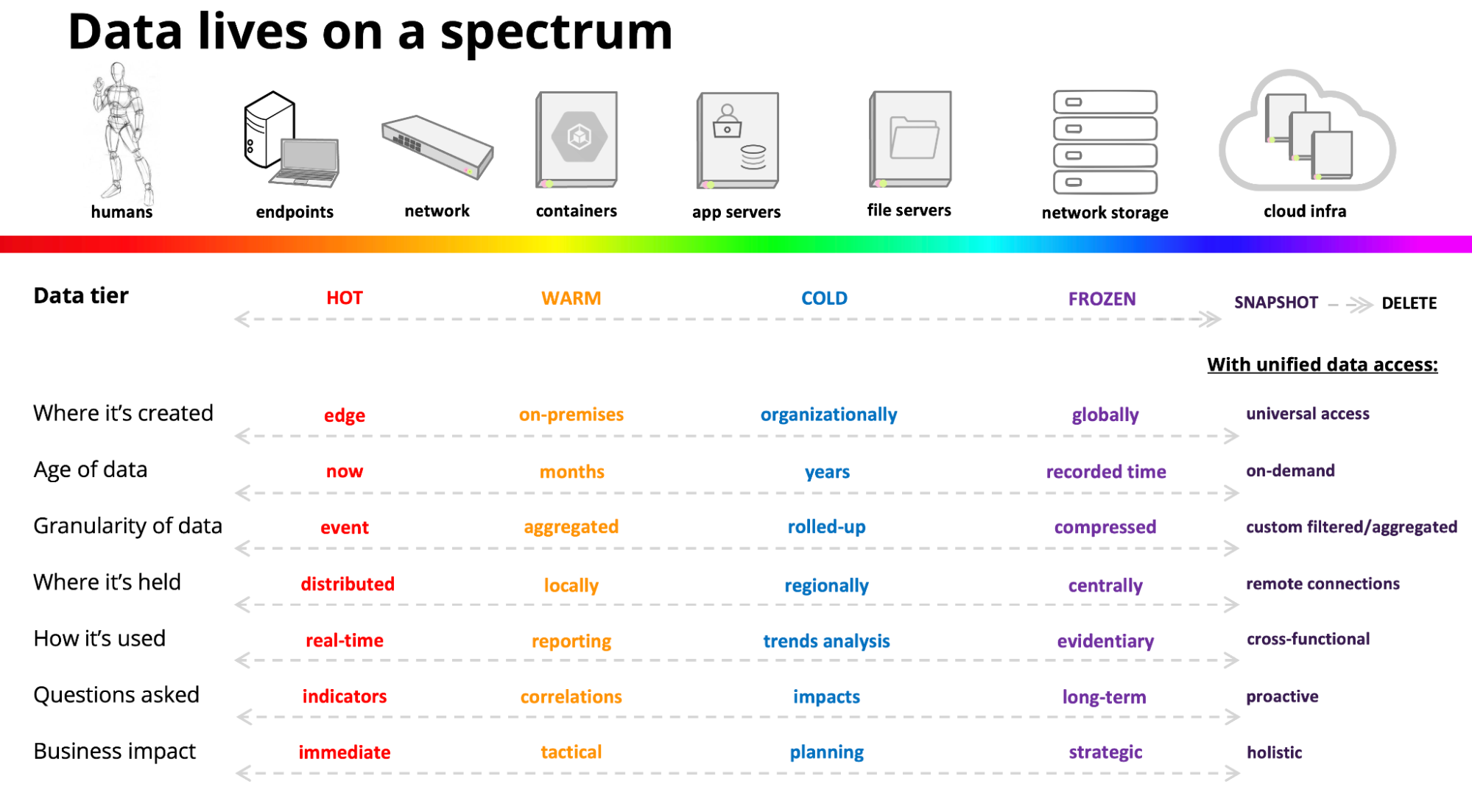
As data ages, its relative value and purpose changes from being useful in near real-time detection and alerting to grouped reporting and trends analysis, and finally it’s used for things like long-tail investigations and maybe large-scale modeling or planning activities. Sometimes data ends up staying around simply to satisfy compliance and records management requirements.
Provenance is frequently assigned during data collection (at the Lapillus Machina layer) or at ingest (into Terra Humanus) when the source is validated or identified as authoritative and given a higher relative weight in results.
In practice, we would want to control the effects of these influencers dynamically to suit the circumstance, but due to the fractured state of Human Data, most organizations are only able to statically apply these factors. This lack of coherence across the Terra Humanus layer ends up shaping what we are able to accomplish with our data; it constrains how data gets managed through the layers, what operations can be performed, and ultimately how accurate our decisions can be with limited access to vital information. We’re left working within a data ecosystem that relies more on the legacy technical workarounds we’ve developed to overcome big data problems than it does on the nature of the data and how we really want to use it to solve problems.

Finding the buried gold
It’s true that no one platform can do all things, but the first and often most important step in any human data operation is to find all relevant data, to start with a complete data picture. Instead of tightly coupling the data storage, retrieval, and query operations to each individual use case and application, we can power all of those decisions with a purpose-built data access layer — a unified search platform.
Elastic's Search AI Platform has the unique ability to provide a single data layer that spans the entire data landscape, with data query, aggregation, and analysis capabilities that far surpass other approaches. The platform includes several query mechanisms (including lexical, semantic/vector, and hybrid search modalities), advanced integrated machine learning, and easy integrations to ingest data from all popular data sources and formats, and then to power applications and services with a complete view of the data.
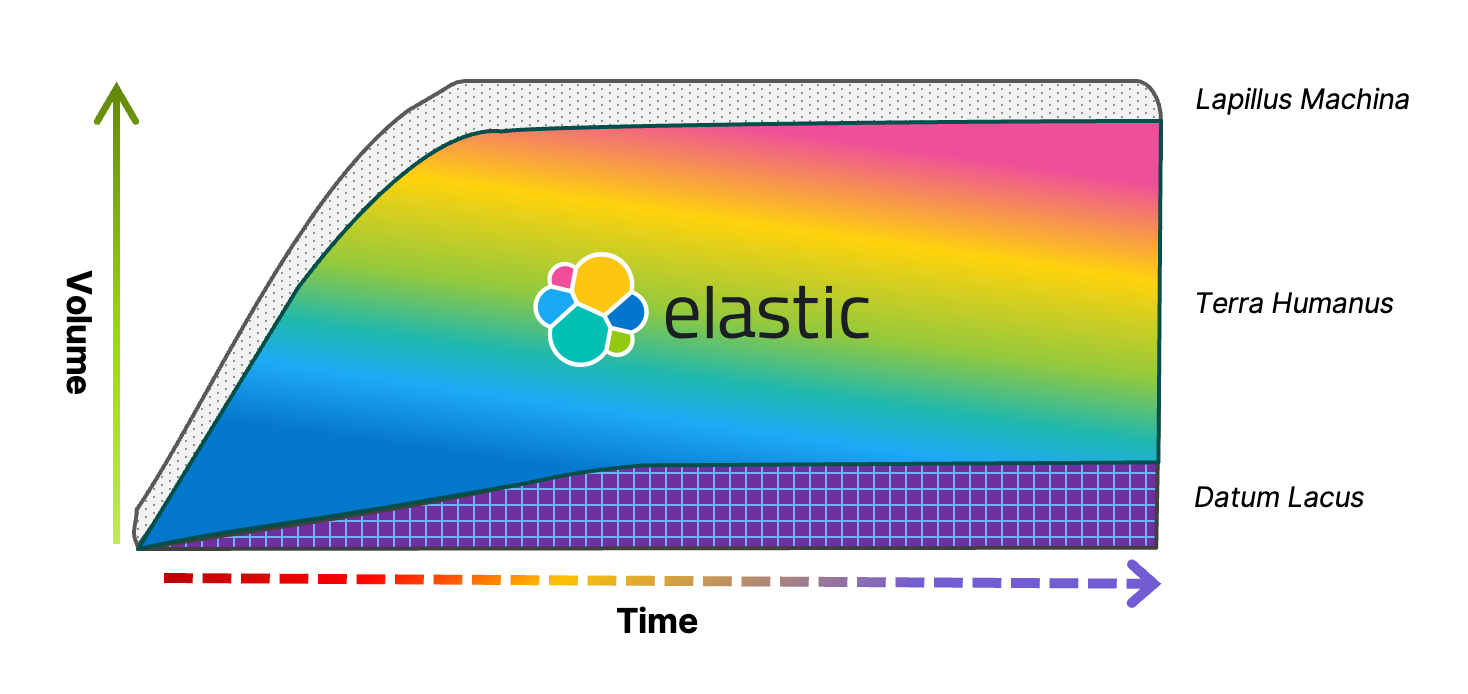
Unlike the disjointed situation we had with Terra Disfunctio, a unified Terra Humanus brings with it the ability to make informed business decisions and solves many problems at once. With a single Human Data layer, you get:
Simplified data query and retrieval on all types of data, with multiple modes of search (including lexical, semantic, and hybrid) and ranking capabilities that can power:
A wealth of solutions including security, observability, search — really any use case that needs fast access to all relevant data
A single layer to apply security and governance on all data
A search platform allows administrators to quickly identify the data of value, especially useful in systems that need to identify risk and/or protect data based on the content (like Zero Trust), not just the metadata .
Fully indexed search can overcome the need for systems like data catalogs, and it can also perform faster, more dynamic categorization and classification, reducing reliance on inflexible tagging schemes.
Keeping data searchable throughout its life span means more accurate and manageable records management; one major advantage is knowing what’s safe to delete.
A unified API layer to power integrations and data operations on all applications and services
Reduces unexpected query load on the underlying data sources/repositories
Removes many-to-many integrations between disparate data sources by providing a one-to-many ingestion integration
Future-proofs the addition of new capabilities or changing architectures by integrating via common APIs at the data layer
Provides a search-based data access and analysis layer to run large-scale analytic workloads that previously were only possible (though with a much more limited search capability) at the Datum Lacus layer
As we’ve seen, data flows through various states during its lifetime and the state it currently resides in largely determines the value that data is able to deliver to our operations. With Elastic as the single data layer powering Human Data operations, we’re able to leverage Terra Humanus to the fullest. We can fluidly traverse data from all formats and sources across time and dynamically influence our results based on the factors of the use case we’re pursuing. We can interactively use all of our data together as a single launchpad for our business operations, and that unified data picture lets us get to the real reasons (whatever they might be) that we’re keeping all that data in the first place.

Learn more about getting the most value from your data:
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print