The big ideas behind retrieval augmented generation


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by email

 Print this page
Print this pagePrint
It’s 10:00 p.m. on a Sunday when my 9th grader bursts into my room in tears. She says she doesn’t understand anything about algebra and is doomed to fail. I jump into supermom mode only to discover I don’t remember anything about high school math. So, I do what any supermom does in 2024 and head to ChatGPT for help. These generative AI chatbots are amazing. I quickly get a detailed explanation of how to solve all her problems. “But Mom,” she whines, “that’s not how we do it!” If only I could get ChatGPT to keep its answers in line with the class’s particular way of doing things . . .
Fortunately, semantic search and retrieval augmented generation (RAG) make that possible. In this blog post, I’ll show how you can train an LLM chatbot on your own data to make it practical for your use cases and scalable across your organization. This isn’t a tutorial, though you can find many of those on Elastic’s Search Labs. Instead, we’ll focus on the big ideas and the value they can bring to your business. And we’ll answer the question of how we can make generative AI even better than it already is.
Large language models
Large language models (LLMs) and the chatbots built on them have changed the world over the past couple of years and for good reason. They do a remarkable job of understanding and responding to user input by meeting the users where they are. No longer are we forced to figure out the perfect search terms; we can ask for what we want as if speaking to a fellow human who can provide examples and expert-level knowledge in language we can easily understand. But they’re not perfect.
Challenges of LLMs
LLMs are trained on generic public data that’s often dated by the time the chatbot can use it. They work as well as they do because there is a tremendous wealth of such data available today, but what about the data they don’t have access to? My daughter’s insistence that we do her homework according to the precise method they’ve taught in school may seem like a trivial example (though, not for her!). Yet, parallel scenarios are playing out for users who want to turn this new technology into a product they can sell but who need the LLM to be able to talk about their private content.
Additionally, LLMs are prone to hallucinating if they don’t have the answer to a question in their training set. They will often confidently tell users completely untrue information to provide something instead of a disappointing "I don’t know." There are things these models shouldn’t know, though. We don’t want them to have access to our proprietary information, and we certainly don’t want them to make up answers to questions that can only be answered using that proprietary information.
So, are LLM-powered chatbots destined to stay amusing distractions forever and of no actual use in production and at scale? Of course not! Let’s discuss how we can get the best of both worlds: lovely natural language answers grounded in information from private data sources.
Semantic search
The first step to achieving our goal of improving generative AI with information it doesn’t have access to is to identify what information is needed. How good does that search need to be, though? Assume that you have a data set that includes all of the answers to the questions you want to ask your chatbot. Let’s consider a few possibilities and some case studies for each.
BloombergGPT: Training an LLM from scratch
This option would be ideal in a perfect world, but the realities of training an LLM make this approach impractical for most companies. LLM training requires truly massive amounts of high-quality data on the order of hundreds of billions of tokens1 as well as well-trained data scientists working on expensive computing resources.
One company that was able to achieve this is Bloomberg with BloombergGPT, an LLM that is designed to work well with finance-specific content.2 To do this, Bloomberg used its 40 years’ worth of financial data, news, and documents and then added a large volume of data from financial filings and generic information from the internet. Bloomberg’s data scientists used 700 billion tokens and 1.3 million hours of graphics processing unit (GPU) time. Most companies simply don’t have these kinds of resources to play with. So, even if your company has all the data to answer questions correctly, it’s likely far from enough information to train an LLM from scratch.
Med-PaLM: Fine-tuning an existing LLM
This second option requires much less computing power and time than training a model from scratch, but this approach still has significant costs. Google took this approach with Med-PaLM, an LLM for the medical domain.3 What it accomplished is impressive, but we can’t all be Google. The work required a large team of data scientists as well as an LLM Google was allowed to fine-tune in the first place. Not all LLM vendors allow fine-tuning, such as OpenAI with GPT-4.
Elastic Support Assistant: Retrieval augmented generation
Fortunately, another approach works within the parameters established by existing LLM providers, taking advantage of the enormous effort already put into LLM development. This technique, RAG, uses prompt engineering to allow existing LLMs to work with additional content without modifying the LLM simply by including the necessary information in the prompt. A good example of this approach in action is the Elastic Support Assistant, a chatbot that can answer questions about Elastic products using Elastic’s support knowledge library. By employing RAG with this knowledge base, the support assistant will always be able to use the latest information about Elastic products, even if the underlying LLM hasn’t been trained on newly added features.
To make this approach practical and scalable, we must carefully identify what this extra content should be. LLM vendors typically charge by the token, so every word sent to them counts. The tables below show some of those costs for several popular LLMs.
| Assumptions | |
Requests per day | 86,400 |
| Low Prompt Tokens | 1,000 |
| High Prompt Tokens | 2,000 |
| Low Response Tokens | 250 |
| High Response Tokens | 500 |
| Cost per day | ||
| Low Price | High Price | |
| GPT-4 | $3,888.00 | $7,776.00 |
| GPT-3.5 | $129.60 | $259.20 |
| Claude-v2.1 | $1,209.60 | $2,419.20 |
| Claude Instant | $120.96 | $241.92 |
So, as tempting as it might be to just send the LLM everything in your data set, this simply isn’t a practical approach to prompt engineering. Instead, we want to come up with the tightest possible prompt to help the LLM answer correctly. We’ll discuss the pieces that go into constructing a prompt later, but first, we need to figure out how to find the additional content we want to include. How do we identify what the LLM will need to give the correct answer?
Vectors
Text search has long been dependent on keyword-focused algorithms. Keyword search is a syntactic approach to information retrieval. In linguistics, syntax refers to how words and phrases are arranged together. It doesn’t matter what the words mean. Consider the following sentences:
Jack and Jill went up a hill.
A hill is what Jack and Jill went up.
Jack and Jill went up a dune.
These sentences all mean the same thing, but only the first two are matches using keyword search on the word hill. Keyword search is a well-understood problem and works exceptionally well to a point. A search algorithm using keywords will never return sentence (3) given the search term hill. Getting sentences (1) and (2) may be all that is required for the use case, but if we want sentence (3) as well, we need to move beyond syntax to semantics.
Semantics refers to the meanings of words and phrases in linguistics. Computers find this much more challenging to “get” as it requires a depth of understanding that is difficult to program. Average English speakers probably know that hills and dunes are similar concepts, but how do we teach this to computers? Well, one thing that computers are really good at is math. If we can turn the problem of semantic search into a math problem, computers will be great at it! So, that’s what we’ll do.
Turning semantic search into a math problem
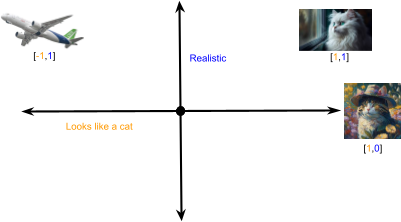
Let’s begin with a simple example. We want to describe the meaning of a concept in a numeric way. Imagine we are describing the concept of a cat. For our example, we’ll use images to represent concepts. We could have a scale from –1 to 1 that says how much a given image looks like a cat. In Figure 1, we represent this on a number line, which you can think of as the x-axis of a coordinate system. The picture on the far right is assigned the value [1] since it looks very much like a cat. The airplane on the left definitely does not look like a cat, so it gets the value [–1]. The image at point [0] has some cat-like features but not enough to score higher on the looks-like-a-cat scale.

We now have a one-dimensional model that we can use to describe any concept. The only thing we can say about concepts in this model is whether they look like cats, which makes this model hardly useful. If we want to add more ways to describe concepts, we must add more dimensions.
Let’s add a new dimension to the model that we can use to say how realistic an image is. We’ll represent this with a y-axis in our coordinate plane (see Figure 2). Combining these two scales gives us a two-dimensional model as shown in Figure 3. Note that two values now represent concepts; the first number tells us how much the image looks like a cat, and the second number tells us how realistic the image is.
This list of values is called a vector embedding. You can think of this like the address for the concept within the model. A two-dimensional model like the one we’ve developed here has addresses that are similar to latitude and longitude points. If we add a third dimension like the color of the image, we’ll get a third value in the vector embedding. This would be like adding elevation to latitude and longitude.
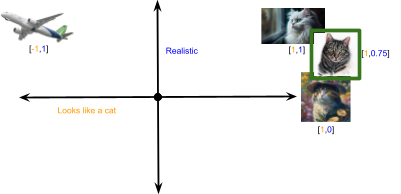
Nearest neighbors
Since concepts are located in the model based on specific features, concepts that are near each other in the model are likely similar in some way. These nearest neighbors are what we return when we’re doing semantic search. To find similar concepts, we first locate the concept we’re looking for in the model. Then we see what other concepts are nearby. Very close concepts are better matches for the search term, while more distant neighbors are not as good. Figure 4 shows a simple example of this using our two-dimensional vector space or model.

The number of dimensions in the model dictates the level of detail in which you can describe a concept. More dimensions result in a finer-grained description of the concept, but they also result in much more complex nearest neighbor searches. OpenAI currently offers several embedding models with the latest being text-embedding-3-small and text-embedding-3-large. The latter of these has a whopping 3,072 dimensions while the small version has a more manageable 1,536.
It’s quite difficult to picture a vector space with this many dimensions; in fact, many humans struggle with anything higher than three dimensions. Instead, you may find it helpful to think of each number in the embedding as part of the concept’s address. If the model has 1,536 dimensions, there will be 1,536 parts of every concept’s address that describe the concept’s location in the multidimensional vector space. This also means there are 1,536 ways to describe the concept.
Nearest neighbor search can still work on these large embeddings, but the math gets much trickier — trickier than we’ll go into in this blog. Suffice it to say, adding more ways to describe concepts can be very valuable, but there’s a tradeoff between such high specificity and the practicality of actually using the model. Striking the right balance is necessary if we are to perform semantic search in production and at scale.
So far, we’ve used images to represent concepts. There are embedding models for images that work in much the same way we’ve shown here, though with many more dimensions, but we’re going to turn our attention now to text. It’s one thing to describe a concept like cat using vectors, but what if we want to search for something more detailed, such as a mischievous cat about to pounce? Even in that short phrase, there’s a lot going on, and in the real world, you will probably be dealing with even larger passages. Now, we’ll discuss how to apply semantic search to prose.
Applying semantic search to prose
In the old days, when you were trying to answer a question using the enormous amounts of data on the internet, you would carefully consider your keyword selection and hope that one of the returned links contained the answer you needed. As search engines have improved, they’ve started to include a preview of where they think the answer is on the page, so you sometimes don’t even need to click on the link. It’s still a bit of a scavenger hunt to get a complete answer, so it is very compelling to have generative AI chatbots bring all the pieces together for you.
To accomplish this, we first need to find the pieces. Essentially, we are doing what we needed to do in the old days and then having the chatbot figure out the complete answer from those “links.” In the previous section, we introduced semantic search as an alternative to syntactic search to improve the relevance of what we send to the chatbot. It should be clear now why searching for meaning can provide better results than finding exact matches.
What is the meaning of the content on the other end of a hyperlink, though? You’ve probably experienced following a link and then getting lost on the page trying to figure out why that link was returned in the first place. There are likely hundreds, if not thousands, of tokens on the page. We already discussed why it isn’t practical to send all of the tokens to the chatbot. It can be costly to send so much data, and there are also technical limitations on how much data you can send at a time. So, it doesn’t make sense to find the “links” and send everything on the page to the LLM. We need to break the content into meaningful pieces before we perform semantic search.
Chunking
This process of breaking the content up is called chunking, and it is necessary for reasons beyond the limitations of what you can send to the LLM. Consider the example of the mischievous cat about to pounce again. A vector embedding is a numerical representation of a concept, but there are at least four distinct concepts in this phrase. We don’t really care about the distinct concepts, though. We care about them taken all together, so what we really want is a single embedding for the entire phrase.
This is something today’s embedding models can do, though the details of how they do this are beyond the scope of this post. In simple terms, the embeddings for mischievous, pounce, about, and to influence the numerical representation for cat, allowing us to perform semantic search over complex concepts like the example. Yet, consider how it would work to assign a single embedding to an entire paragraph about our mischievous cat. What about a short story or even an entire novel?
You naturally lose some of the detail as you include more concepts in the vector embedding. That is, semantic precision goes down as you include more content. For example, a novel can be about many things, not just a single concept. On the other hand, you’re pretty much guaranteed to find the “answer” to your question if you send the entire novel to the LLM. We know we can’t realistically do that, but there is another reason why we can’t vectorize an entire novel. Just as LLMs limit how much data they can receive at a time, most embedding models limit how many tokens can be included in the embedding. After that token limit is reached, the rest of the content is simply dropped. So, even if we try to get a single embedding for a novel, we’ll probably only capture the meaning of the first paragraph or so and then ignore the rest.
So, the task of chunking the data is trickier than it might first appear. As shown in Figure 5, the size of the chunks critically influences our ability to uncover accurate answers. Fine grained or small chunks have high semantic precision since the vector representation for the chunk is less diluted by multiple concepts. However, small chunks are less likely to contain the complete “answer” we’re looking for. Imagine if every link Google returns only points to a few words. You’ll almost certainly need to click through multiple links to get all of the information you need. On the other hand, coarse grained or big chunks likely have complete answers, but it’s harder to identify them as good matches since the numerical representation is influenced by so many concepts.
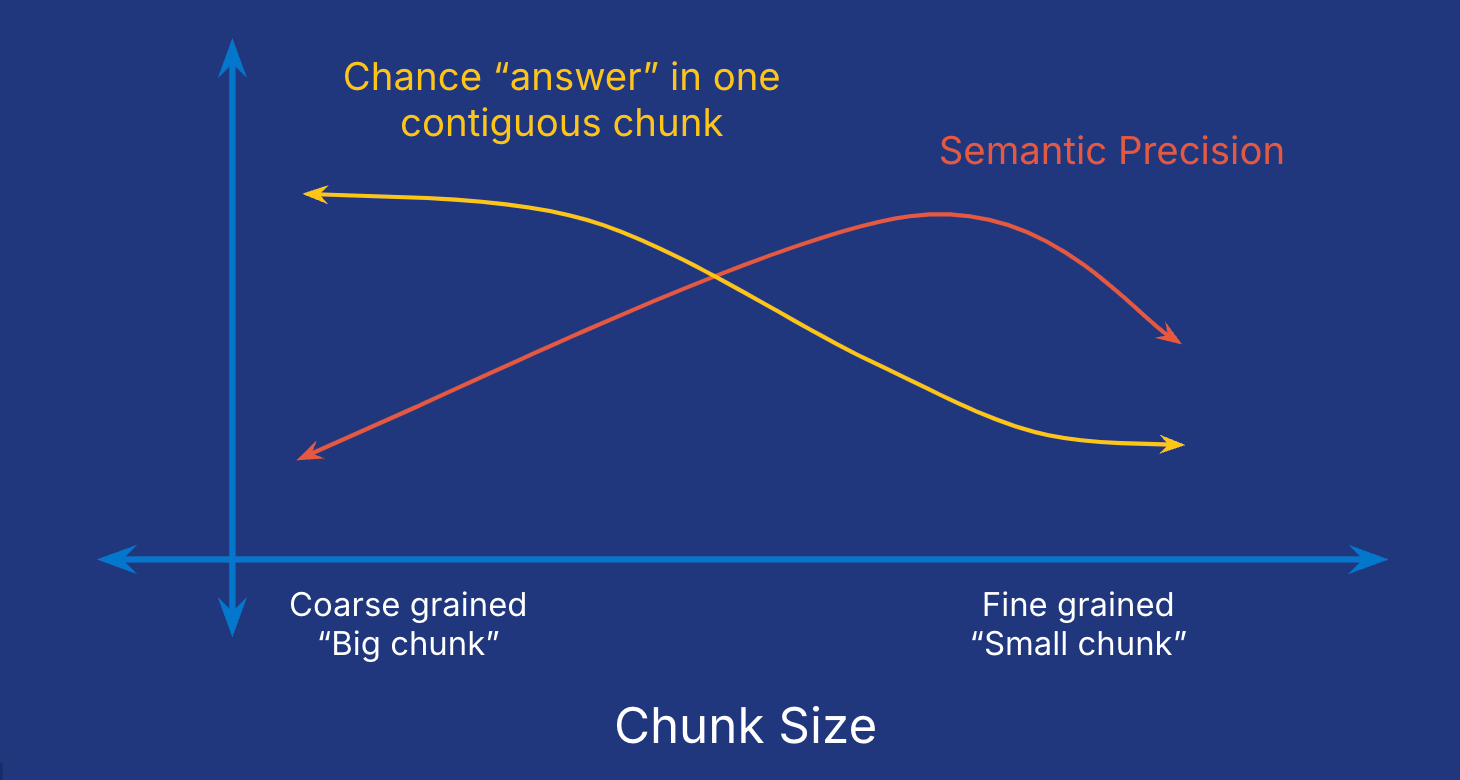
There are a number of different strategies for chunking that try to mitigate these concerns. Finding the right balance between chunk size and semantic precision often takes some trial and error, and the best strategy often varies from use case to use case. Let’s consider a few of the most common approaches.
Token-based chunking
The first option is the most straightforward. We simply base chunks on the number of tokens they contain. While the number of tokens in a paragraph can vary wildly, a reasonable average is 150 words. If we have chunks that are each 150 tokens long, we might strike the right balance, but you can probably imagine how easily this strategy can fail. As soon as you have a paragraph that is not exactly 150 tokens, you’ll likely have chunks spanning paragraph boundaries and paragraphs that require multiple chunks. This will have a cascading effect, as shown in Figure 6. Imagine reading a book in this way and stopping to grab a cup of coffee after each chunk. It would be next to impossible to follow along. If you are reading a book in this fragmented way, you likely have to go back and reread some of the text so that you don’t get lost. Strategies 2 and 3 work on this principle.

Token overlap
With token overlap, each chunk overlaps with the chunks next to it (see Figure 7). For example, we might have an overlap of 50 tokens so that every chunk is 200 tokens. Token overlap increases the chance that a chunk will contain a complete idea, topic transition, or context clue. However, there is necessarily some redundancy with this approach. This might be fine, but resource management is important when we consider running a RAG application at scale.

Surrounding chunks
The final strategy we’ll discuss here is to retrieve surrounding chunks. The basic idea is similar to familiarizing yourself with the context of what you’re reading by reviewing the preceding and succeeding content. We begin with the same token-based chunks we had with strategy 1. We then apply semantic search to find the “best” chunk (i.e., the nearest neighbor to what we’re searching for). At this point, we’re ready to send information to the LLM, but rather than sending only the most relevant chunk, we also send the chunks directly before and after the most relevant hit. This hopefully ensures that we send complete ideas to the LLM so that the chatbot has everything it needs to answer our question.

Retrieval augmented generation
So far, we’ve focused on the retrieval part of retrieval augmented generation. We know that we will use an LLM for the generation part, which leaves us with the question of how what we retrieve will augment what the chatbot generates. To understand this, we first need to consider how we interact with LLMs in general. We use prompts to converse with LLM-powered chatbots. Put simply, a prompt is just what we say to the chatbot, and with sites like ChatGPT, it really is as simple as typing in something and waiting for a response. Behind the scenes, though, there’s a bit more going on — prompts are actually composed of several parts.
Prompt engineering
System prompt
First, there is always a system prompt that defines how we want the chatbot to behave in general. With ChatGPT, this system prompt isn’t shown, but when we create our own RAG application, we need to define it in order to get the chatbot to do what we want. Since we will be retrieving data to augment the chatbot’s knowledge, we need to make sure that the generation uses that data. Moreover, if we want to restrict the application to using the retrieved data to prevent hallucinations, this should also be specified in the system prompt. For example, the following system prompt would ensure the behavior we’re looking for:
You are a helpful AI assistant who answers questions using the following supplied context. If you can’t answer the question using this context, say, “I don’t know.”
Supplied context
The next part of the prompt is the supplied context. This is where we include data we retrieved using search. For example, if we run semantic search and find the three nearest neighboring chunks for the search term, we can provide those three chunks in the supplied context. Alternatively, we might only send the closest nearest neighbor along with the preceding and succeeding chunks. It’s up to us what we include in this section, and it can take some trial and error to figure out what works best in our application.
User input
The final piece of the prompt is the user input. When we use a chatbot like ChatGPT, we are restricted to use only this part of the prompt. For our RAG application, however, this section serves a dual purpose. As usual, this is where we ask the chatbot to do something specific, such as explain how to answer a particular algebra problem, but this is also where we supply the search terms we’ll use to provide context to the prompt. With all of these pieces in place, we’re ready to see our RAG application in action.
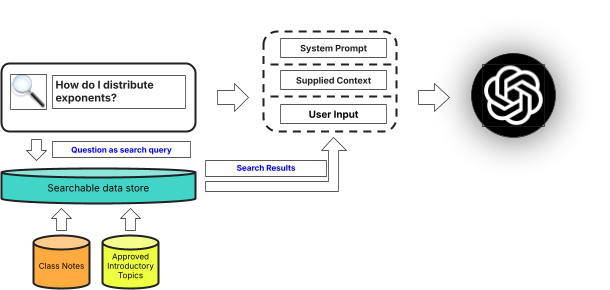
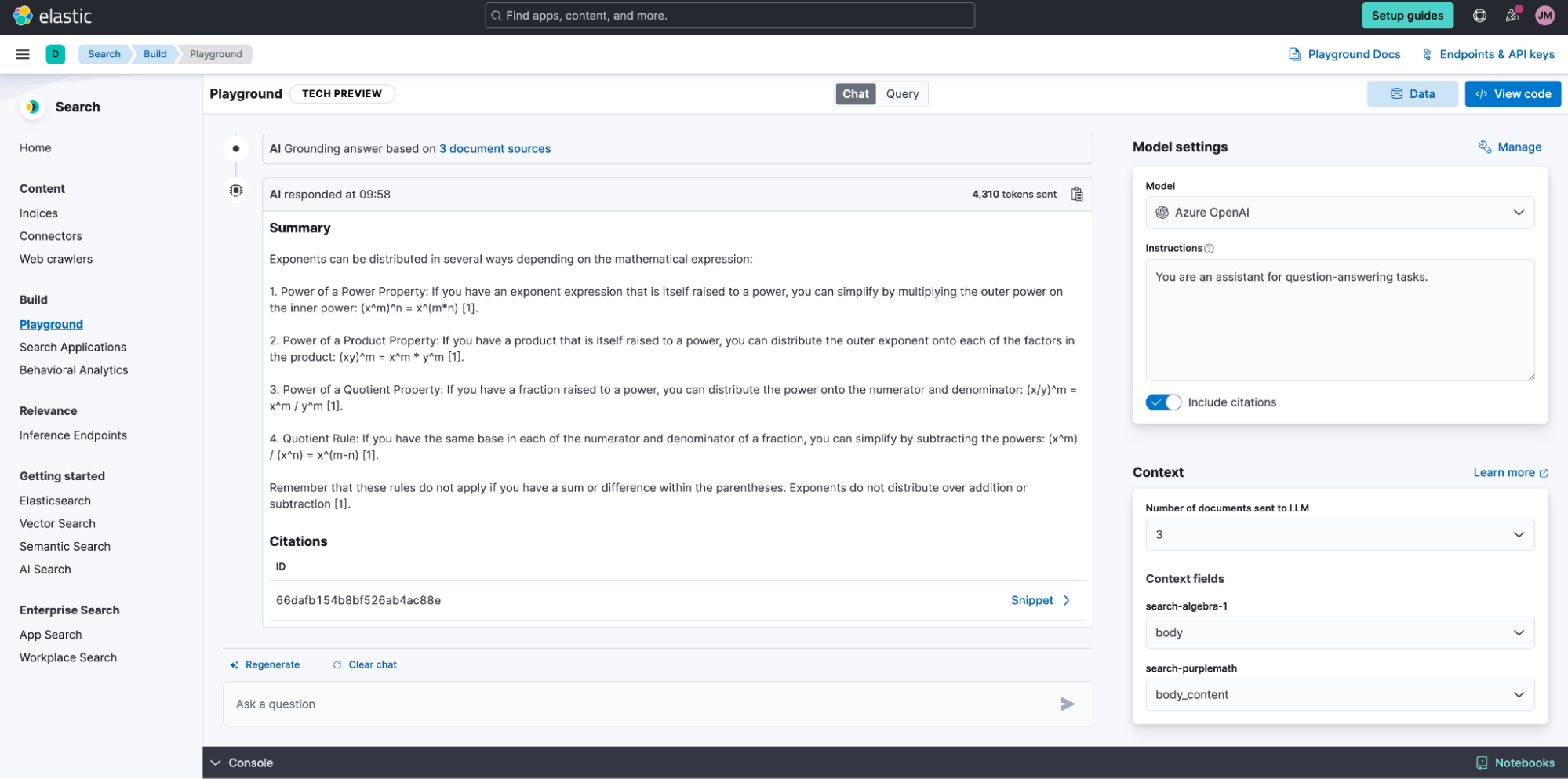
Figure 9 shows how this would work for our original problem. How can we get a chatbot to answer questions about algebra using only information provided in class? We first identify what information is permissible and ingest it into a searchable data store, such as Elasticsearch. For example, my daughter’s teacher provided class notes in PDF form as well as a link to an approved site for introductory topics. As we ingest the data, we need to prepare it for semantic search. Fortunately, Elasticsearch makes this extremely easy to do by providing a field type that performs chunking for us and figures out the embeddings for each chunk. We have this easy button for semantic search, and there is also an AI playground where we can see our RAG application work as we develop it. Using the Playground, we can see if our application meets my daughter’s standards (see Figure 10).
Build your own application with Elasticsearch
We’ve seen why retrieval augmented generation is necessary to make LLM-powered chatbots practical and scalable. It simply doesn’t make sense to rely solely on the public data LLMs are trained on, but we also need to be cognizant of how and what we share with them. Semantic search can retrieve highly relevant data based on its meaning rather than keywords alone.
Elasticsearch makes it easy to set up semantic search and then see it in action with its AI Playground feature. Once everything looks good in Playground, you can download the code for your chatbot so that you can insert it into your own application. Elastic’s Search Labs provides detailed tutorials on how to do this using the tools described here.
You don’t need to be an expert data scientist to use semantic search or generative AI. RAG makes it easy to get the most out of this technology. Now, you know what’s going on behind the scenes that makes it work so well.
Ready to dive deeper? Read this ebook next: An executive's guide to operationalizing generative AI.
1 A token is a meaningful piece of data. What a token officially is depends on the tokenizer being used, but for our purposes, you can think of a token as being a word.
2 https://www.bloomberg.com/company/press/bloomberggpt-50-billion-parameter-llm-tuned-finance
3 https://sites.research.google/med-palm
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by email
- Print this page
Print

