Centralized Pipeline Management in Logstash
With the release of 6.0.0-beta1, we launched the centralized pipeline management feature for Logstash. In this post, I'll take you through how you can use this feature to ease the operation of your Logstash instances. I’ll also explain how it all works under the hood, what future enhancements this enables, and lastly, provide our short term and long term roadmap.
Introduction
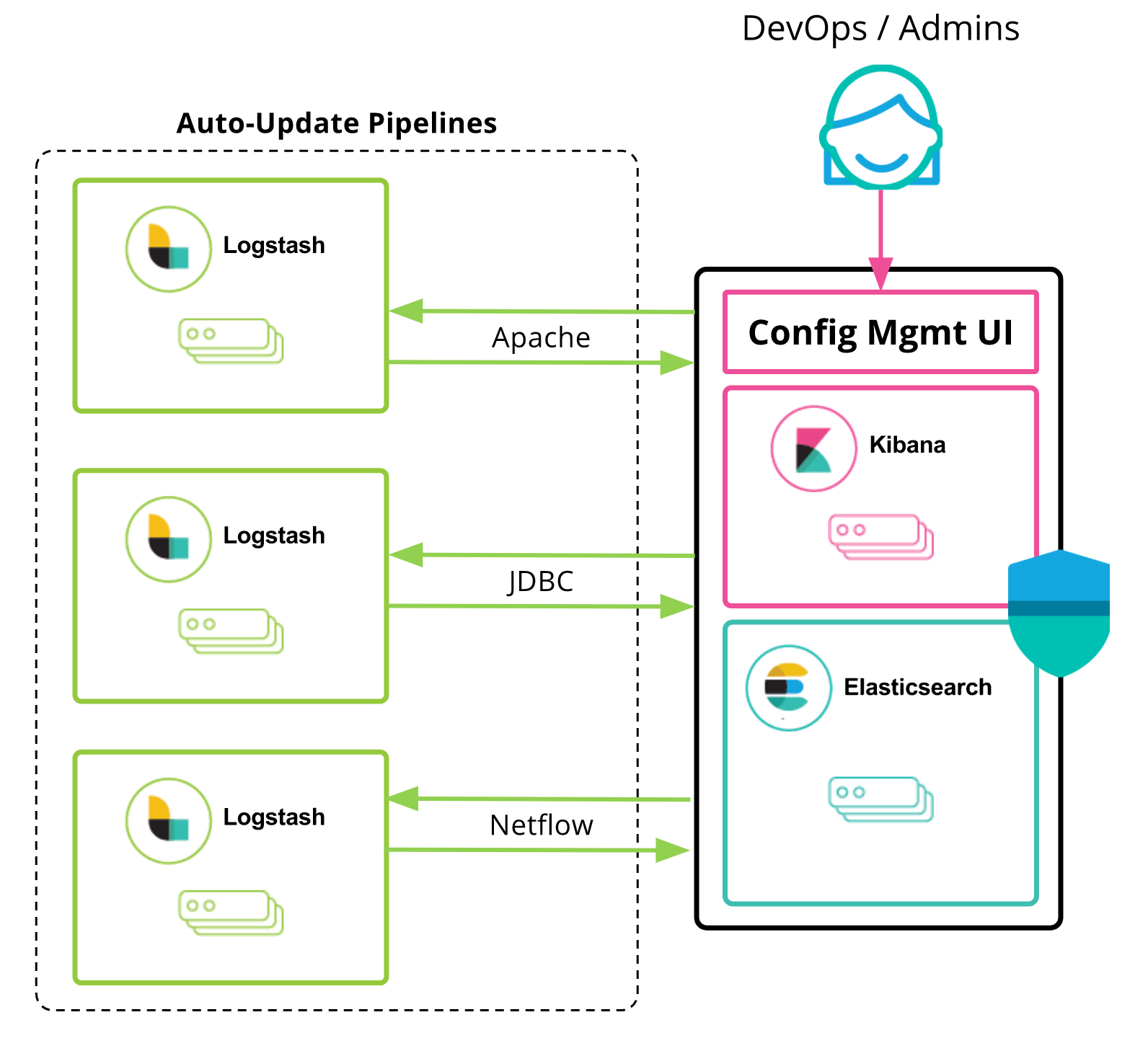
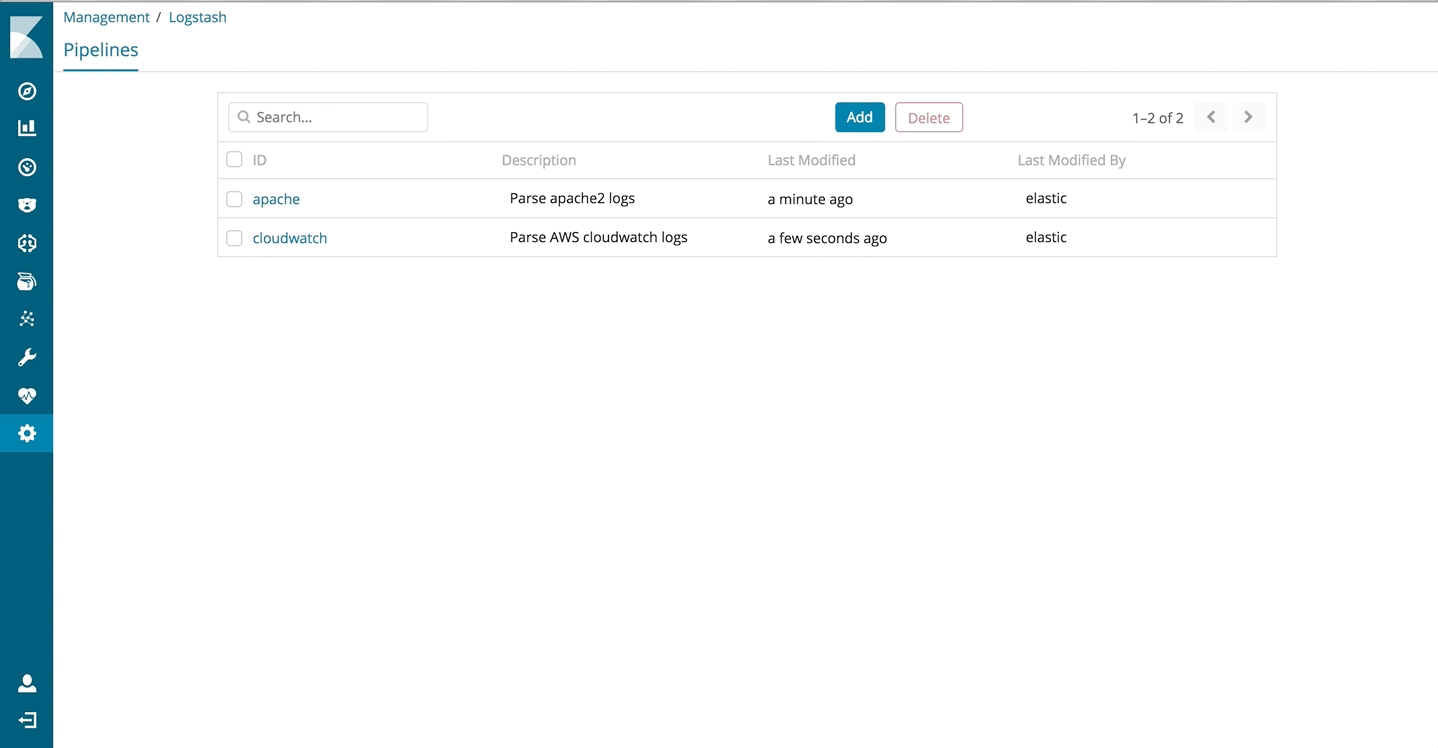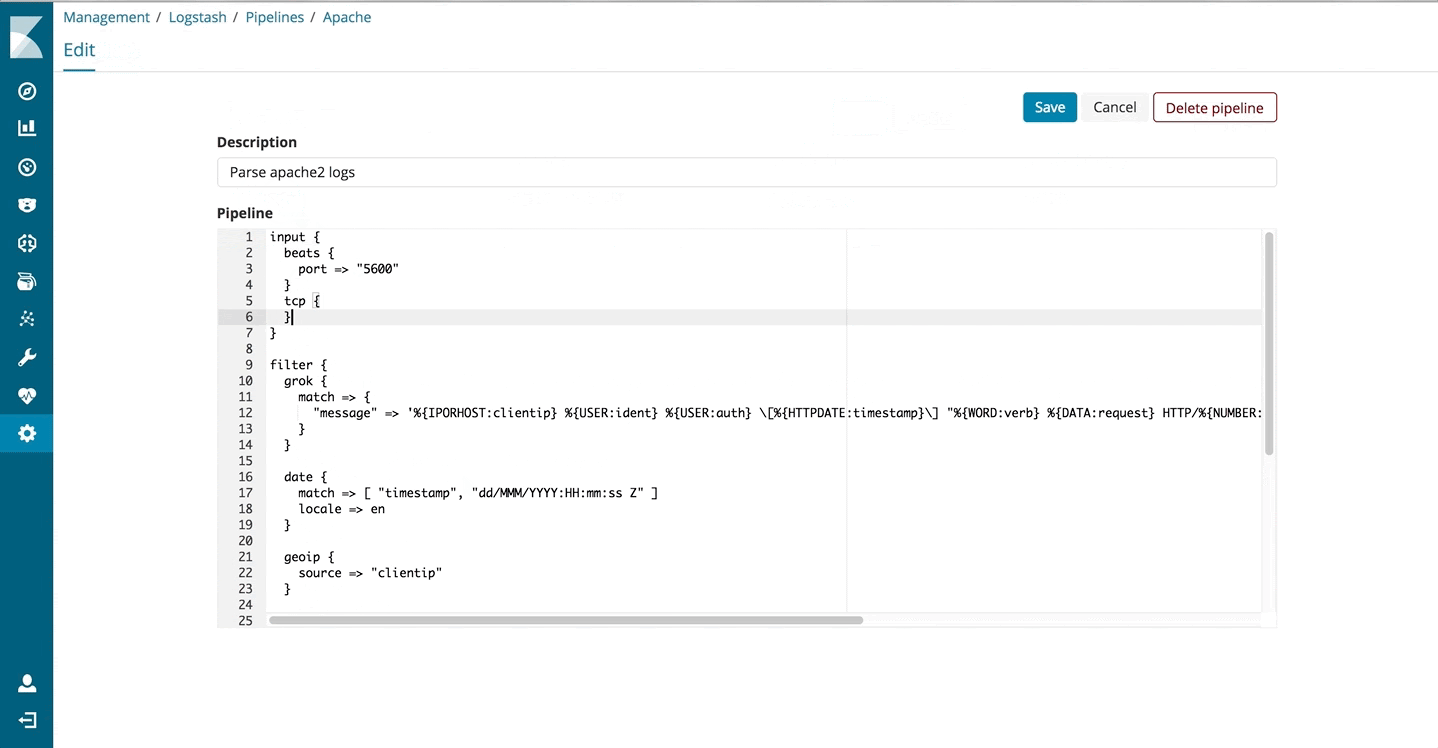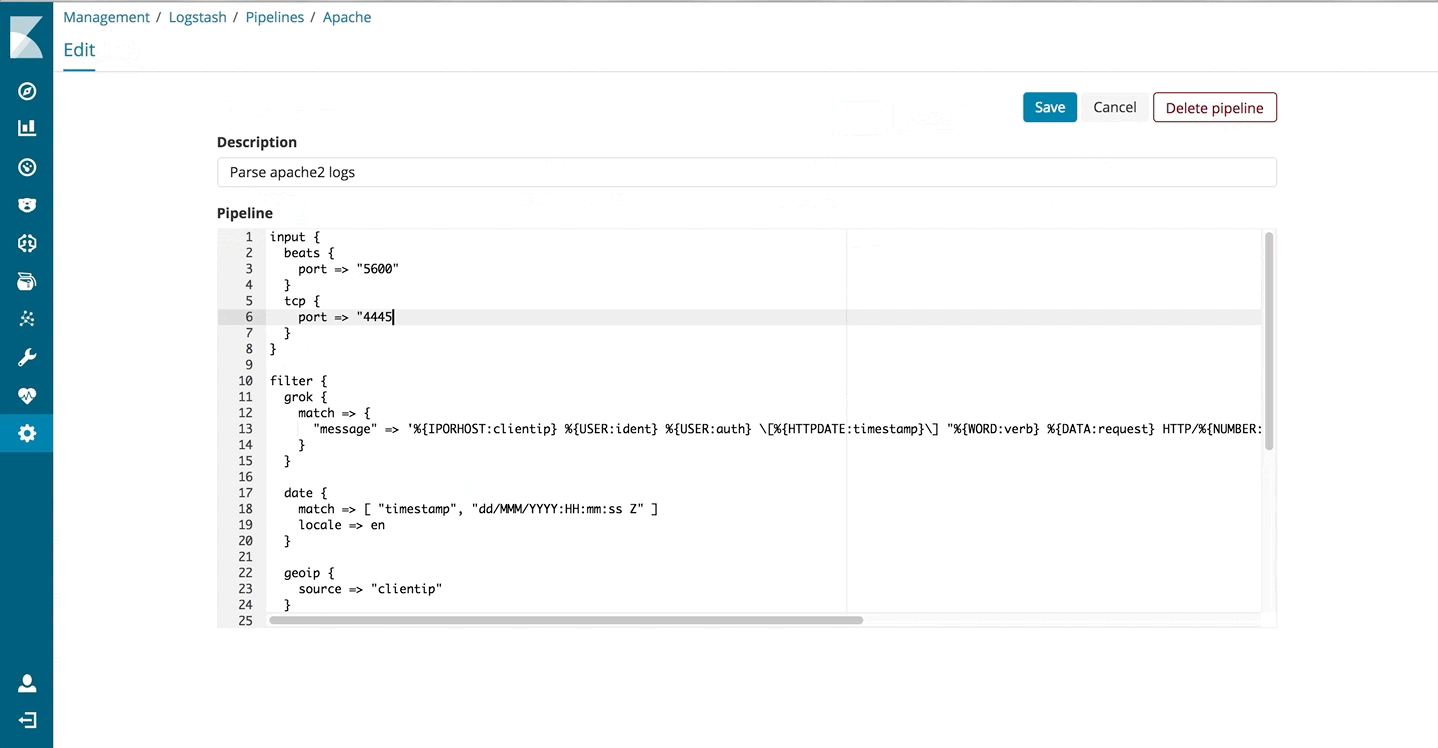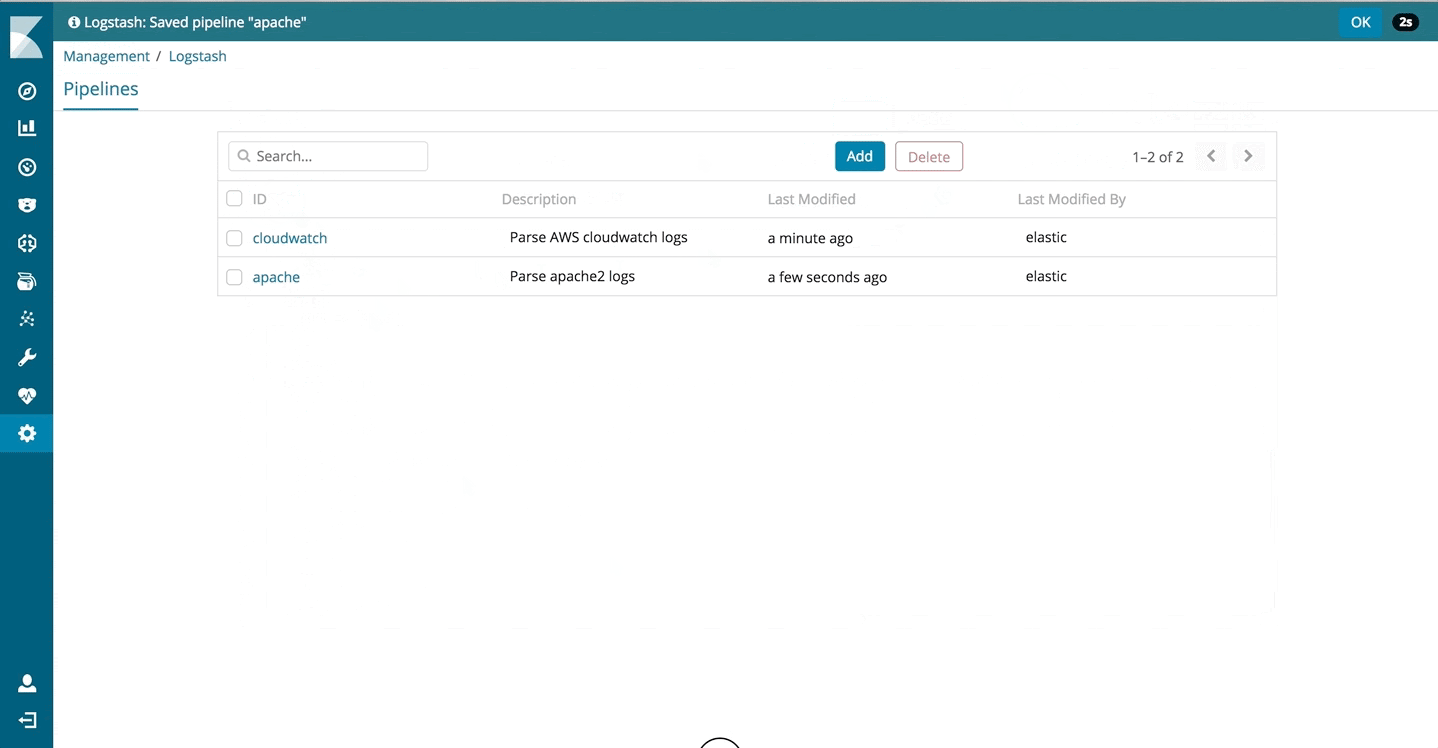
Simply put, this feature provides management and automated orchestration for your Logstash deployments. You start with the new Logstash management UI provided in Kibana to create, edit, or delete pipelines. A simple text editor is available to interact with your Logstash pipelines using the existing configuration DSL. These pipelines get stored in the Elasticsearch cluster which is configured for that Kibana instance. Once this is set up from the UI, Logstash instances can then subscribe to these pipelines managed by the Elasticsearch cluster. In essence, Elasticsearch now becomes a middleware and a state store that Logstash instances can rally around.
Motivation behind this feature
The size of Logstash production deployments varies in range from users running a few instances to large deployments of 30-40 instances to process terabytes of data. Often times, groups of Logstash instances will be running the same configuration. Over time, these configurations can get complex as they tend to handle multiple data sources. When we surveyed Logstash users a couple of years ago, we gathered some key insights into how folks manage Logstash. From that survey, 50% of the respondents managed Logstash manually. The rest used config management tools such as Puppet and Chef. We speculate this is related to the size of the deployments — the same survey showed that most popular deployment size was in the 1-10 instances range. There is a learning curve involved with these configuration management tools which perhaps didn't justify it be used for these small deployments. This inspired us to provide an easy to use pipeline management functionality out of the box, all using the Elastic Stack components.
Multi-tenancy and self-service
This feature was designed to make Logstash pipelines self-servicing. Combined with the new multiple pipelines feature introduced in Logstash 6.0.0 alpha2, you can now isolate data flows using separate pipelines. Perhaps, each tenant or a logging data-flow can run as a separate pipeline.
If you are running a logging service in your company using the Elastic Stack, you can on board new data sources easily with the UI. Want a new TCP input for your Netflow data? Just add the TCP block in the config UI and hit save. The Logstash instances will pick ‘em up. Adding a new grok pattern for this data source? Easy. The possibilities are endless here.
Security considerations
Security, and specifically access control, should be an important consideration when using this feature. The centralized management UI is a powerful control panel to manage your Logstash instances. Like any other management feature, please make sure you protect access to administrators and trusted users only. This centralized pipeline management feature integrates seamlessly with the built-in security features provided with the Elastic Gold license, or the Standard license when you're using our Elastic Cloud service. It’s secured out of the box with a logstash_admin role which is the only role that has access to this management UI. We strongly recommend that as an Elastic Stack administrator, you use this role to lock down access only to trusted users. Other best practices we recommend for this feature are:
- Avoid storing passwords or other credentials as plain text in the config when using this feature. We encourage you to use the environment variable expansion feature in Logstash. This way, you can safely use variables for credentials within the pipeline management UI while defining any secrets using environment variables on the Logstash machines. Logstash will resolve this variable at runtime therefore providing a level of indirection.
- Enable TLS when communicating with Elasticsearch. See details here.
- Disable plugins that are not actively used in your configuration by uninstalling them. When there is a need to use a plugin in your config you can easily add them using the plugin manager.
- The Ruby filter is a powerful way to extend Logstash’s functionality to process data. On the flip side, the Ruby filter doesn’t provide any sandboxing capabilities, so please understand the risks involved before using this filter. This guideline isn’t specific to the pipeline management feature, but its risks are further exposed in this context.
- Configure document level security to restrict access to individual pipelines. Under the hood, each pipeline is stored as a regular document in an Elasticsearch index. The ID of the document is the name of the pipeline. Please follow the docs for document level security feature to configure it for this use case.
Roadmap
This feature in its current form is just the tip of the iceberg, but it establishes an important foundation for future enhancements. Short term, our focus will be to add security related features like auditing. You can then track which specific user made a change to the pipeline, when they made it, and what the change was. Another short term focus is to integrate with our monitoring UI so we can provide user feedback when pipeline reloads go awry.
Longer term, we are working on providing syntax highlighting, autocomplete, and snippets support for the config editor. Version based rollback, you ask? On it. Oh, and did I mention we’re already thinking about a drag-n-drop UI to create pipelines? I can go on and on about all the exciting stuff that's brewing in our heads, but I’ll stop here. :)
We would like to hear from you! Please let us know how you like this feature or if you have ideas for enhancements. You could also win plenty of swag when you provide feedback via our Pioneer Program. What are you waiting for?! Get ‘stashin!