Image recognition and search at Adobe with Elasticsearch and Sensei
This post is a recap of a community talk given at a recent Elastic{ON} Tour event. Interested in seeing more talks like this? Check out the conference archive or find out when the Elastic{ON} Tour is coming to a city near you.
Software giant Adobe is known the world around for its Photoshop, Illustrator, and Acrobat products, which are rolled into cloud service suites — Creative Cloud, Document Cloud, and Experience Cloud — of other similar software offerings. A number of their products — especially those where image search is critical, such as Adobe Stock — feature slick search capabilities that use Elasticsearch behind the scenes.
"Elasticsearch resilience and stability is very high... [and it has] the right balance of open source with a tight review process."
The Adobe+Elasticsearch search landscape
All told, Adobe’s self-managed Elastic Stack deployment comprises 18 production clusters hosting over 10 billion documents, with a live ingestion rate of about 6,000 documents per second. To better support search in Adobe Lightroom, for example, they made the switch from Amazon’s Elasticsearch Service to their own self-managed clusters, moving over nearly 3.5B documents. Much of Adobe’s content is non-textual — images, videos, Photoshop files, and the like — but also includes standard enterprise document types, especially PDFs. The Elastic Stack, along with custom-built Elasticsearch plugins, helps drive the following content search experiences:
- Search based on computer vision and metadata
- Deep textual and hybrid content search
- Video and richer format search
- Enterprise search
- Discovery and recommendations
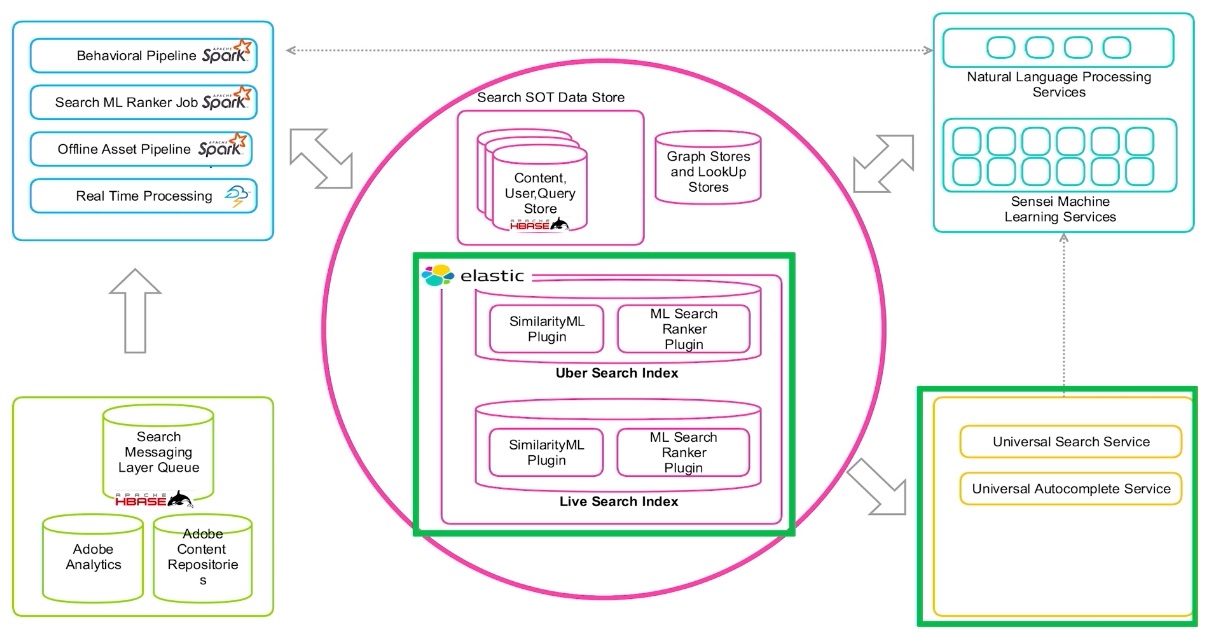
Machine learning with Adobe Sensei and Elasticsearch
Adobe Sensei artificial intelligence and machine learning technology does the heavy lifting for training the image search models. To work alongside Sensei, Adobe created several Elasticsearch plugins — a similarity plugin and another for search ranking — to help drive image recognition capability and create an effective tool for users to find similar images. Together, they provide users with real-time search features such as face detection, object detection, face clustering, auto tagging, and named entity recognition.
The search functionality in Adobe Stock is a great example of their machine-trained image search technology. Its digital content library contains over 130 million image assets and showcases the power and convenience of being able to easily search, sift through, and sort images. It can also seamlessly filter based on image similarity search: finding other images resembling a chosen or uploaded image based on a variety of attributes, such as color, content, and composition, and indexed by price, tag, type, and so on.
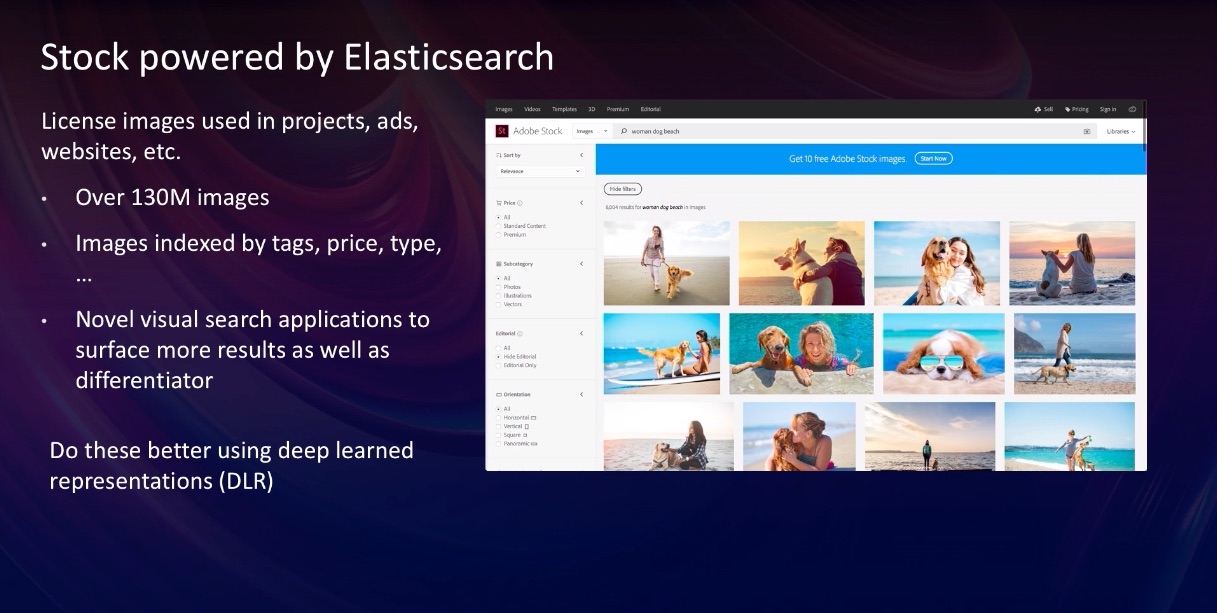
Deeply trained machine learning models toil along with Elasticsearch as the data store in the background to make Adobe Stock search possible. They use convolutional neural networks to train deep learned representations, or embeddings, to map the similarity of a property to Euclidean distance (i.e., to begin to develop groupings of similar images and attributes). A slew of additional machine learning wizardry takes place, and the overall machine intelligence built into Stock results in a gorgeous and highly useful image search experience for users.
For a deeper dive
If you're interested in much more detail, watch Baldo Faieta, Adobe Senior Computer Scientist, delve into the specifics of how Adobe AI and ML combine with Elasticsearch to help train and build image recognition, comparison, and search capabilities in the full Adobe presentation from Elastic{ON} Santa Clara.

If you’d like to put the Elastic Stack through the paces yourself, spin up a free 14-day trial of the Elasticsearch Service.