Elastic data tiering strategy: Optimizing for a resilient and efficient implementation


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
At Elastic, most of our successful customer implementations begin with a single use case aimed at addressing specific business requirements. Elastic is often initially adopted because developers appreciate the features it offers. However, because of its flexibility and customizability, customers tend to expand their adoption to address various needs, such as logging and application performance monitoring, SIEM and security operations, and even more complex search use cases utilizing the data already available in Elastic.
In today's IT environment, merely storing data (logs, traces, metrics, and documents) is insufficient. Organizations need a solution that enables their teams to access and utilize this data quickly and effectively. Efficiency is key in data management, as every bit of stored data incurs costs for hardware, licensing, maintenance, and management.
In this blog, we’ll break down how organizations with large amounts of data can optimize how it is stored across different tiers to gain cost savings and derive more value from their data.
The challenge: Efficient and scalable data management
Organizations love Elastic for its speed, scalability, customizability, and functionality. Because of this, they often find new use cases for Elastic. This becomes a challenge when large amounts of data are ingested without considering how the data is stored, managed, and used, which can lead to bottlenecks in data management. As data grows, their current setups struggle to handle new needs, reaching the limits of their hardware and licenses.
If your organization is experiencing these issues, the solution is more manageable than you might expect.
The solution: A business-driven data strategy
The way to overcome this challenge is by defining a data strategy that aligns with your business objectives. Instead of collecting and retaining data based on arbitrary requirements, ask yourself the following questions:
What data needs to be collected to drive a business objective?
How often is this data used?
Is there an expiry date after which this data is no longer valuable?
Are there compliance requirements for this data?
Based on the answers to the questions above, organizations can create a business-driven data strategy to optimize the way that data is being stored and utilized, maximizing their existing investment in Elastic.
Case study
To showcase the benefits of adopting this strategy, let’s explore a case study of a customer who has undergone this process.
This customer typically processes 5TB of data per day and handles an average of 250,000 events per second. However, at times the volume increases to 7TB per day and 350,000 events per second. The Elastic implementation for this customer was focused on ingesting a high volume of security data and making it available to the security operations center (SOC) team to search for information on cyber incidents and fraud investigations.
This implementation was so successful that the customer added new use cases that required longer data retention and faster search capabilities from a wider range of data sources. They targeted the following business outcomes:
Log optimization: By optimizing their data tiers, organizations can enhance their log management practices, ensuring that they retain the right logs for the right amount of time, improving operational efficiency, and compliance adherence.
Improved license utilization: Efficient storage tiering means better license utilization, allowing organizations to make the most out of their existing resources and potentially avoid unnecessary licensing costs.
Enhanced business efficiency: The ability to find insights from logs more efficiently can lead to improved business efficiency, enabling faster decision-making and more informed strategic planning.
Onboarding new use cases: With optimized data tiers, organizations can easily onboard new use cases, expanding their data analytics capabilities without significant infrastructure investments.
Clear data strategy: Optimized data tiering contributes to a clear data strategy, ensuring that data is reliable, easily accessible, and governed effectively, laying the foundation for data-driven decision-making.
Data tiering
Data tiering is a complex and nuanced topic and it deserves its own blog to unpack. However, for the purposes of defining a data strategy, the different data tiers can be simplified into three main uses: ingest, search, and store.
Ingest (hot tier): Ingest data as quickly as possible with minimal latency.
Search (hot and warm tier): Search data quickly and crunch large data sets.
- Store (cold and frozen tier): Store data for as long as required and perform low-frequency ad-hoc searches.
Data growth and retention
Understanding the range of data retention requirements is crucial for compliance and efficient data management. Different regulations necessitate varying retention periods:
SOX retention requirements: 7 Years
HIPAA data retention requirements: 6 Years
PCI DDS data retention requirements: 1 Year
Basel II data retention requirements: 3–7 Years
GDPR employee records:
Wages: 3 Years
Tax records: 6 Years
Name, address: 3 Years
- Fair Labor Standards Act: 2–3 Years
Previous vs. new architecture
Previous architecture
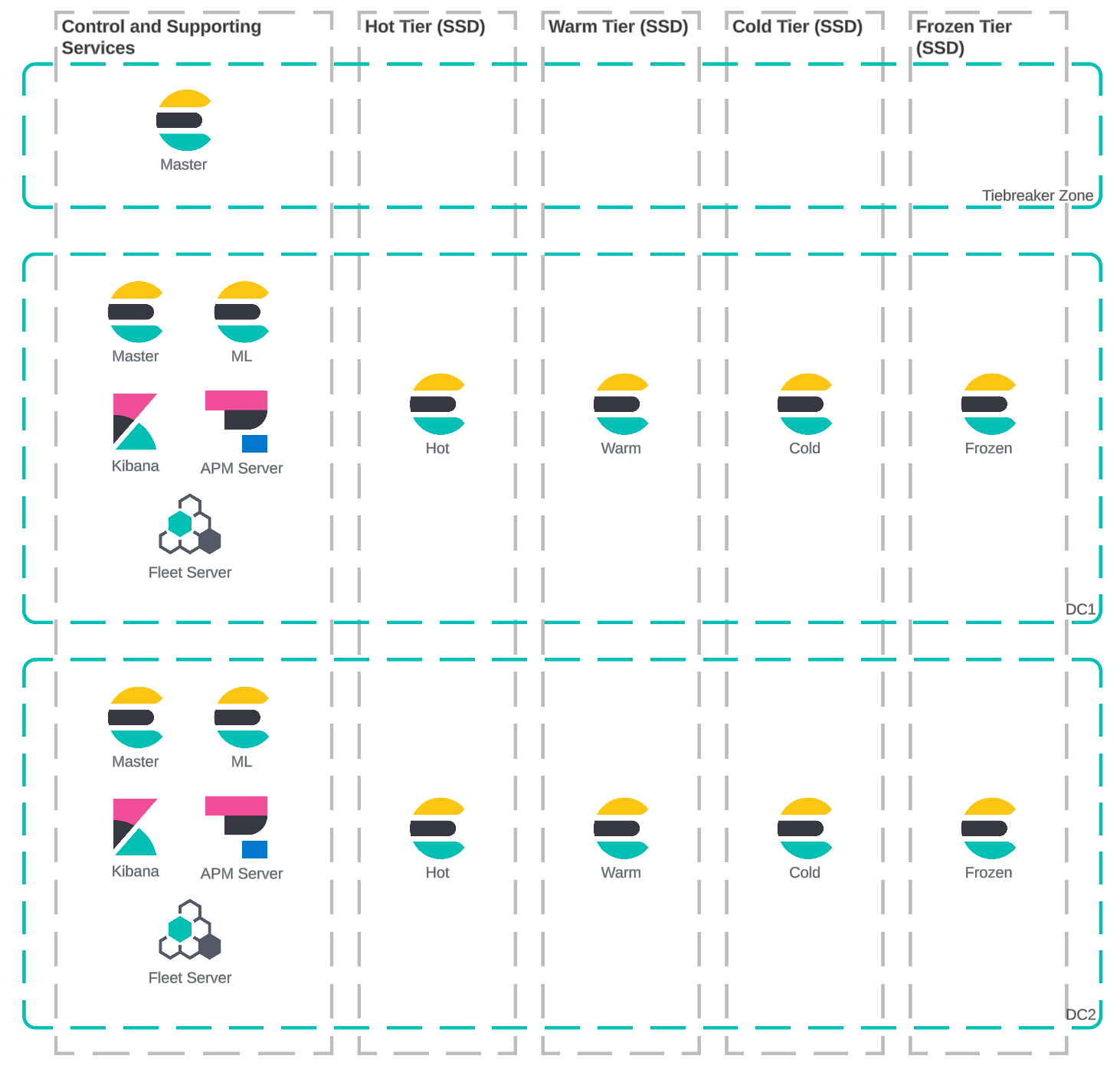
The previous architecture had two data centers with a four-tier storage implementation catering to various data handling needs. This implementation required more hardware, licenses, and overhead in operational management.
The customer retained all logs for 90 days, regardless of how the data was used.
7 days hot
2 days warm
10 days cold
Remaining days in frozen
The customer had the same hardware in both the hot and warm tiers. The warm tier was used purely for force merging indices for searchable snapshots. The warm and cold tiers were very underutilized in both CPU and storage. The frozen tier was narrow, resulting in slow historical searches.
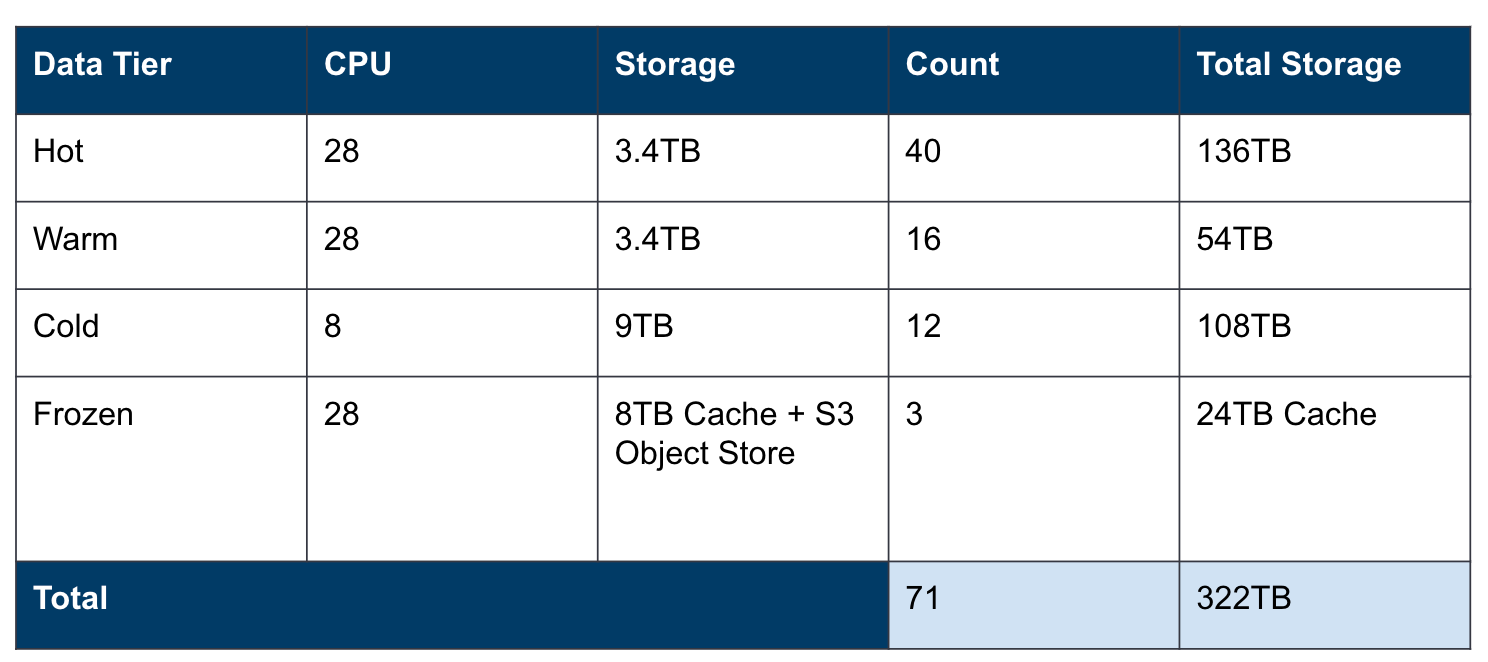
New architecture
After reviewing how the data was utilized, the following findings were discovered:
Most of the high volume data was only searched in the first 24 hours after ingestion.
After 24 hours, the main usage of the data was for security investigations, which required ad-hoc searching.
Some select indices needed to be retained longer for reporting.
Due to new compliance requirements, data needed to be retained for up to a year.
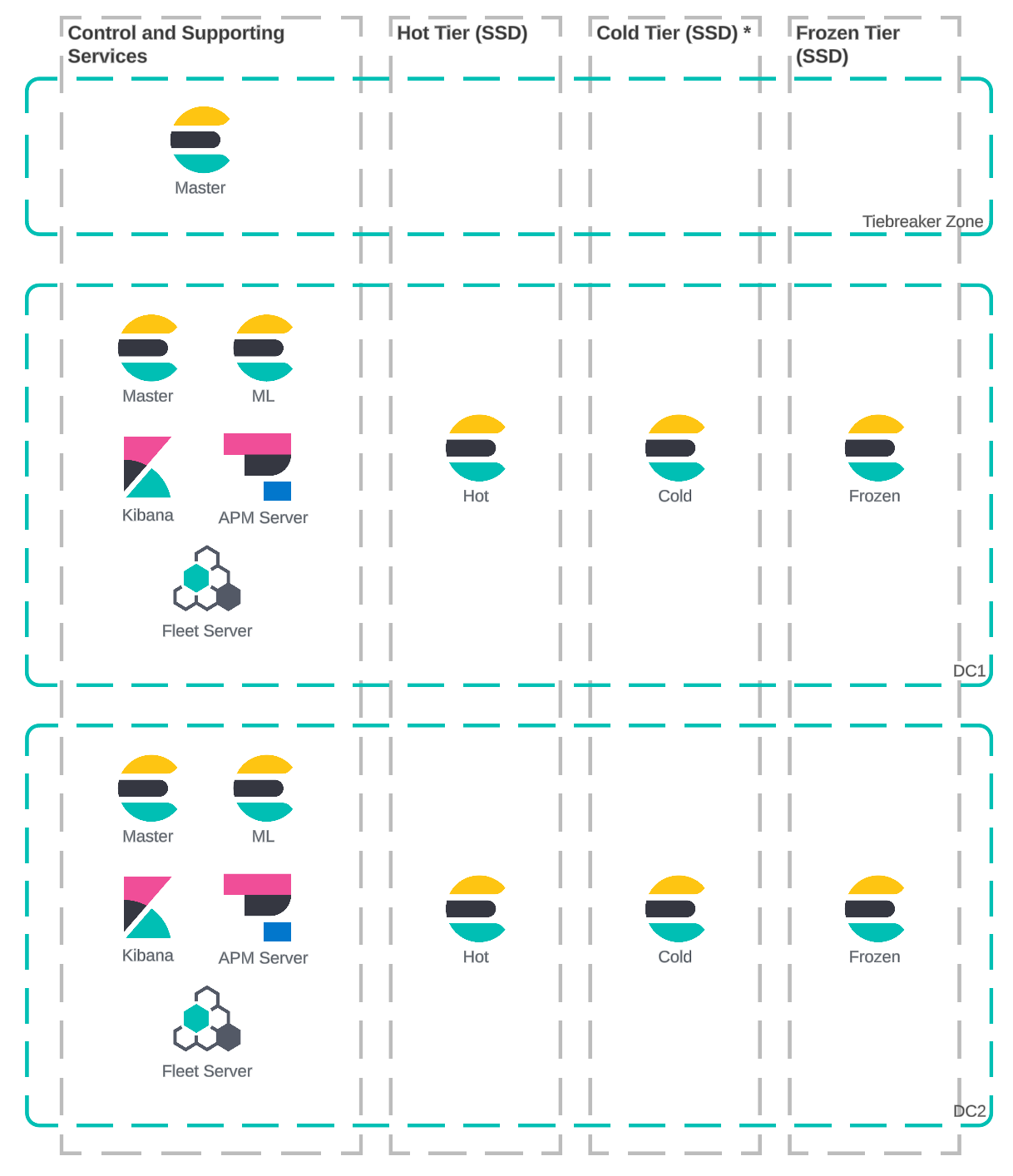
Migrate to hot/cold/frozen architecture
Hot tier nodes had sufficient capacity to perform force merging activities, allowing the warm tier to be removed.
Most of the data can transition from the hot tier straight to the frozen tier after 36 hours.
Data that requires local storage for reporting use cases can be kept in the cold tier.
The hot tier can also be reduced because there is less data that needs to be retained.
Expanding the frozen tier increases the amount of cache available for searches, improving search performance. In addition, it allows data to be kept for a year instead of just 90 days.
Storage optimization
Better storage density: the cold tier can leverage a searchable snapshot as a replica. The frozen tier stores all data in the snapshot repository and only caches query results in its local cache.
Less data replication requires fewer nodes, reducing the hardware and license utilization.
All tiers utilize the same storage requirements, allowing hardware to be consolidated and reused easily.
The changes freed up 20–30 nodes and licenses, which were reused to build additional use cases.
The new architecture aims to consolidate hardware profiles for logging and security workloads, potentially introducing a third zone for increased resilience. It also focuses on storage optimization, including better storage density and reduced data replication, resulting in fewer nodes required and optimized license utilization. This architecture allows for the consolidation of hardware profiles.
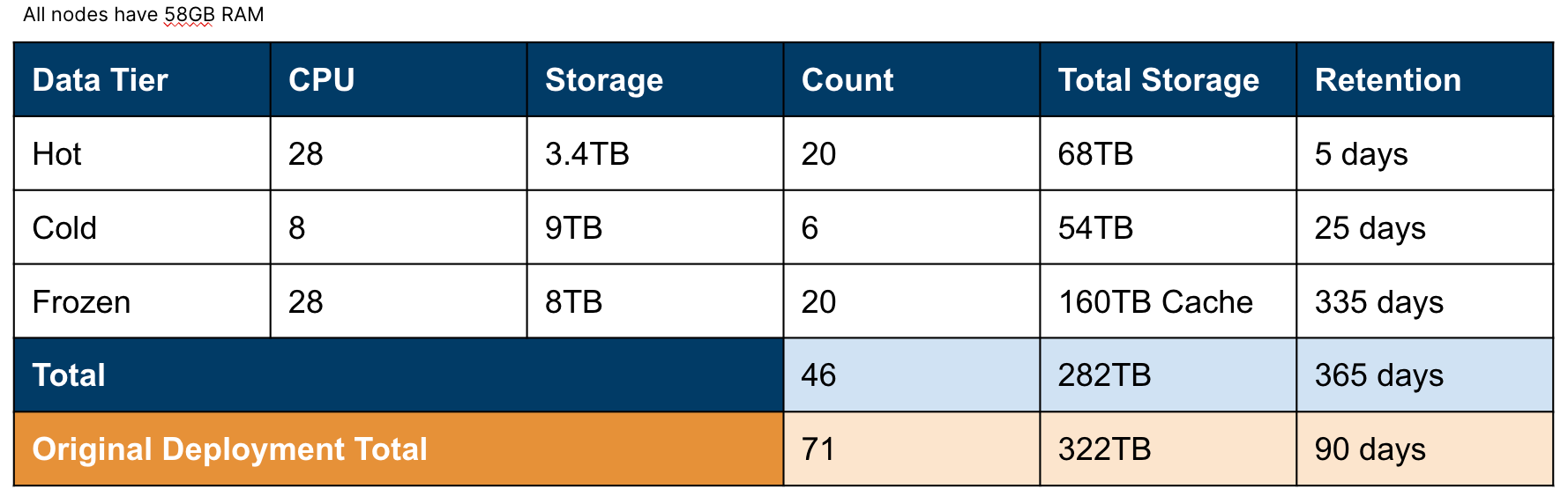
Re-architecture benefits
Improved data retention strategy: A more efficient storage tiering strategy can lead to better data retention, which can be particularly important for security and compliance purposes.
Simplified platform management: Consolidating hardware profiles and reducing the number of nodes required can simplify platform management, reducing operational overhead.
Reduced hardware footprint: Optimization of compute resources and storage density can lead to a reduced hardware footprint, saving space and energy.
Enhanced ROI: By optimizing their storage tiers, the organization can achieve a better return on investment, making the most out of its existing infrastructure.
The pros of the new architecture include simpler management, better utilization of licenses and hardware, longer data retention, and smaller deployment, leading to faster upgrades and increased infrastructure resilience. However, potential cons may include slower search performance for certain use cases requiring fast storage with high IOPS due to more data being stored in frozen tiers.
Implementing the strategy
A tiered data strategy allows organizations to optimize performance for recent data while efficiently storing large volumes of data. By leveraging shard allocation awareness, organizations can define the characteristics of each tier and schedule the migration of indices according to the data strategy. This ensures that data is stored on the most appropriate hardware tier at any given time, balancing performance and cost considerations.
Example storage tiers and memory ratios
Memory to storage ratio is a crucial consideration when planning Elastic growth. Below are the four storage tiers available to Elastic customers:
Hot tier: Optimized for ingestion and search performance, typically using high-speed SSDs with a memory to storage ratio of around 1:30
Warm tier: Optimized for storage capacity, utilizing SSD or HDDs with a memory to storage ratio of approximately 1:160
Cold tier: Optimized for storage capacity using a searchable snapshot as a replica (Although the storage ratio is the same as the warm tier, the removal of a local replica halves the storage requirements.)
Frozen tier: Optimized for archival purposes, employing cheap snapshot storage with local disk cache to provide a memory-to-storage ratio exceeding 1:1,000
High-level cost analysis of different storage configurations
In our analysis, we assessed the total cost of ownership (TCO) for various storage configurations to optimize another customer's Elastic implementation. Below is a detailed breakdown of these configurations and their associated costs:
Self-managed ES cluster
1TB daily ingestion
Total retention 365 days
| Configuration | Retention days | Nodes | Hardware cost | Snapshot storage cost | Total cost (TCO) |
| Hot-warm | 7 hot, 358 warm | 4 hot, 60 warm | $44,954 | $7,665 | $52,619 |
| Hot-warm-cold | 7 hot, 90 warm, 268 cold | 4 hot, 15 warm, 23 cold | $28,231 | $7,665 | $36,795 |
| Hot-warm-frozen | 7 hot, 90 warm, 268 frozen | 4 hot, 15 warm, 3 frozen | $17,051 | $7,665 | $22,204 |
| Hot-frozen | 7 hot, 358 frozen | 4 hot, 4 frozen | $6,198 | $7,665 | $12,066 |
Considerations for capacity planning
When planning the capacity for each tier, it's crucial to size them independently based on their specific requirements. This involves understanding the storage and performance needs of each tier and ensuring that they are adequately provisioned. Additionally, organizations must consider the overall capacity requirements and how the different tiers will interact to ensure a balanced and efficient storage strategy.
Final thoughts
Optimizing storage tiering is not just about saving costs; it's about enabling organizations to evolve and adapt to new challenges and opportunities.
By approaching platform optimization challenges using the data strategy principles, organizations can facilitate new use cases, improve data reliability, and enhance their overall data strategy. Check out our documentation to learn how your organization can build a resilient and efficient implementation of Elastic using data tiering.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print