The evolving role of SREs: Balancing reliability, cost, and innovation
A look at the expanding roles of SREs and the new skills needed: cost management and AI


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by email

 Print this page
Print this pagePrint
Imagine the CTO walks into your team meeting and drops a bombshell: "We need to cut our cloud costs by 30% this quarter." As the lead SRE, this might cause a strong reaction — isn’t your job about ensuring reliability? When did you become responsible for the company's cloud bill?
If you've had a similar experience, you're not alone. The role of site reliability engineers (SREs) is evolving fast. A recent survey of observability practitioners sheds light on this transformation, revealing both challenges and opportunities for those of us in the SRE trenches.
Most SREs love their jobs
A whopping 94% of SREs surveyed said they would recommend the role to a colleague. That's a ringing endorsement if I've ever heard one.
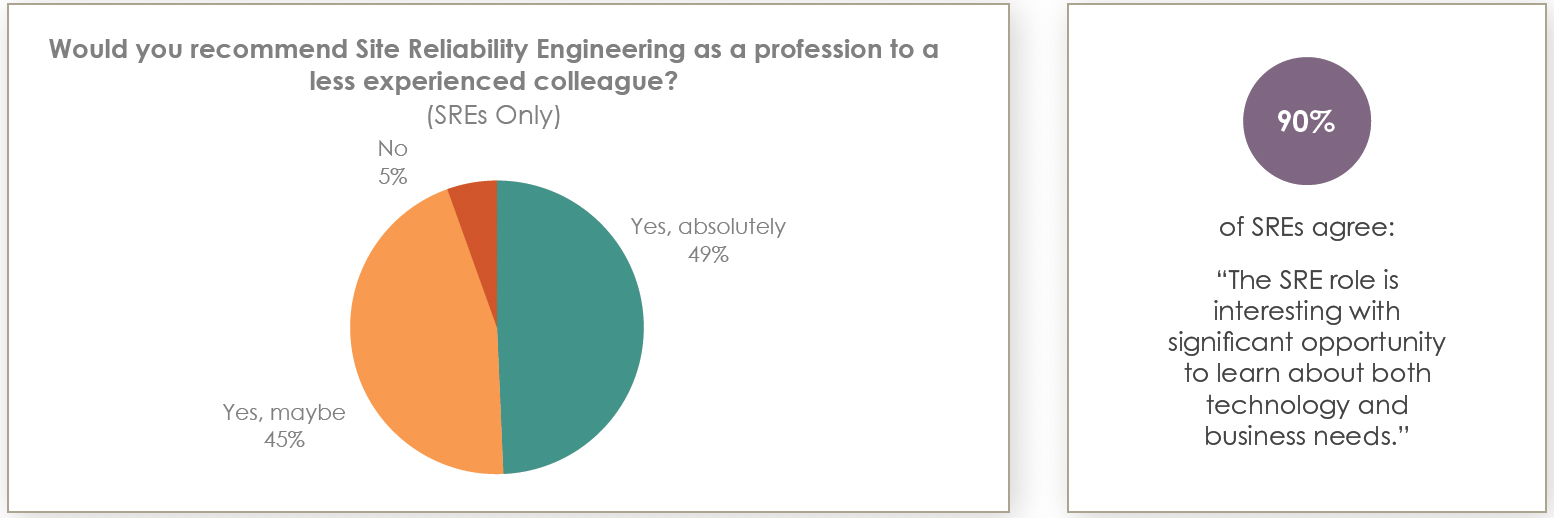
But why do SREs love it so much? The survey offers some clues:
90% of SREs agree that the job is interesting and offers opportunities to learn about both business and technology.
The role requires a diverse skill set, keeping things challenging and engaging.
SREs often have a bird's-eye view of the entire system, allowing for strategic thinking and impactful improvements.
SREs learn about business and technology
The foundation of this high job satisfaction appears to stem from the unique blend of challenges and opportunities that define the SRE role. While many technical positions might focus on specific aspects of technology or business operations, SREs get to experience both worlds simultaneously. Most SREs report finding their work intellectually stimulating, specifically citing the dynamic interplay between business and technology as a key driver of their job satisfaction.
SREs are challenged by their diverse skill set
What makes the SRE role particularly engaging is its demand for a diverse skill set. These professionals might spend one day optimizing cloud infrastructure; the next day collaborating with product teams to improve service level objectives (SLOs); and another day designing automated incident response systems. The emergence of generative AI (GenAI) has also opened up a Pandora's box of new possibilities and techniques for SREs to use. This variety isn't just about keeping things interesting. It also represents continuous opportunities for professional growth and skill development.
SREs get to have a bird’s-eye view
One of the most distinctive aspects of the SRE role is the unique vantage point it provides within an organization. SREs maintain a comprehensive view of systems — from infrastructure foundations to high-level business objectives. This panoramic perspective enables them to identify patterns and opportunities that might go unnoticed by teams with narrower focus areas. With this broad view, they're uniquely positioned to drive measurable improvements that impact both technical metrics and business outcomes.
SREs: The Swiss Army knives of tech
The strategic nature of the role places SREs at the forefront of technological innovation. As systems become increasingly complex and distributed, their role in balancing reliability with rapid innovation becomes ever more crucial. Rather than simply maintaining existing systems, these professionals actively shape how modern technology organizations operate and scale.
Beyond technical challenges, there's a deeper satisfaction in the core mission of the role. SREs serve as both architects and guardians of critical systems that power modern businesses. They're the professionals who ensure smooth operations, step in during crises to restore stability, and implement preventive measures before problems occur.
The SRE community is also known for its strong emphasis on knowledge sharing and collaborative growth. This creates a positive environment where professionals consistently learn from each other's experiences and innovations. Such collaborative spirit has helped establish SRE as not just a job but also a community of practice.
These high satisfaction rates send a compelling message to those considering entering the field. Despite the inherent challenges and complexities of the role, the rewards — both personal and professional — appear to make it worthwhile. And if current satisfaction levels are any indication, it’s potentially even more rewarding.
The expanding SRE toolkit
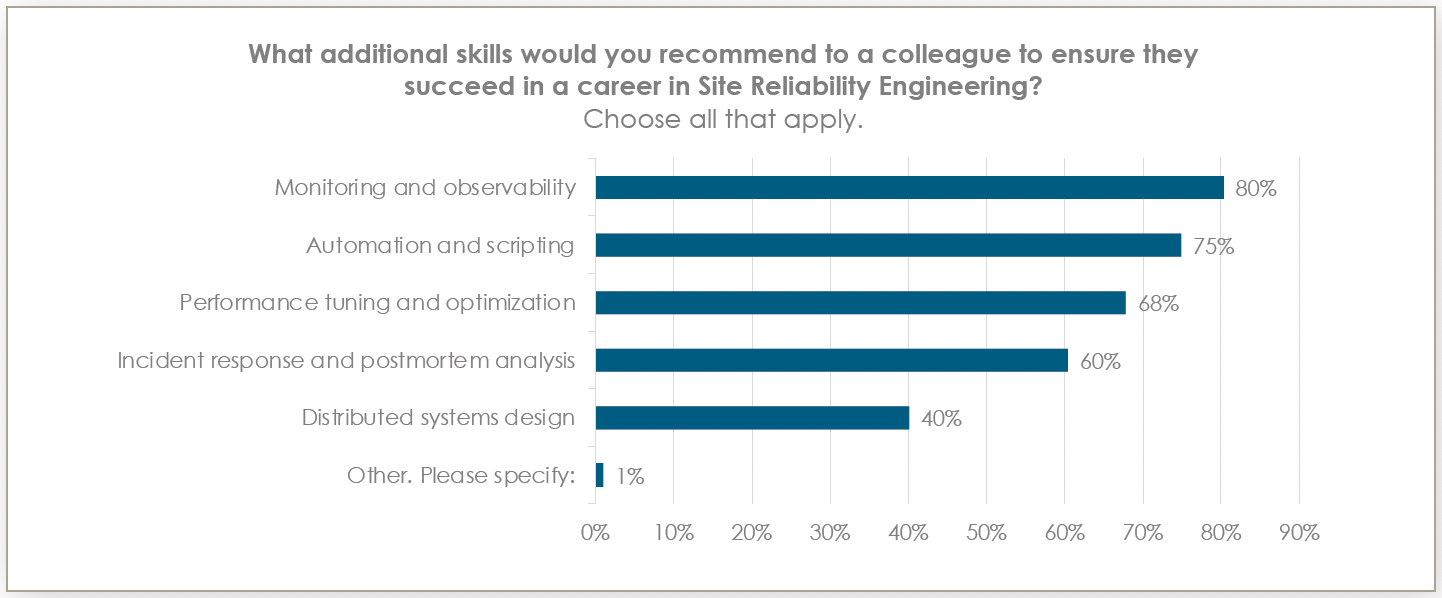
Speaking of diverse skill sets, the survey highlighted some key areas of expertise for modern SREs.
Monitoring and observability (80%)
At the core of the SRE skill set lies monitoring and observability expertise with four out of five professionals citing it as essential to their role. This comes as no surprise. In today's complex distributed systems, the ability to gain meaningful insights from system behavior isn't just useful; it's fundamental. Modern SREs need to navigate through seas of telemetry data, identifying patterns and anomalies that could impact service reliability.
Automation and scripting (75%)
Hand in hand with observability comes the art of automation and scripting, endorsed by three-quarters of surveyed SREs. This emphasis on automation reflects a core principle of the role: eliminating repetitive tasks to focus on more strategic work. Whether it's deploying infrastructure as code, automating incident response, or creating self-healing systems, the ability to write efficient automation solutions has become invaluable.
Performance tuning and optimization (68%)
Performance tuning and optimization represents another crucial skill area with more than two-thirds of SREs highlighting its importance. In an era where milliseconds can mean the difference between user satisfaction and frustration, the ability to identify and resolve performance bottlenecks has grown critical. This isn't just about making systems faster; it's also about understanding the delicate balance between performance, reliability, and cost.
Incident response and postmortem analysis (60%)
The importance of incident response and postmortem analysis skills — cited by 60% of SREs — reflects the profession's emphasis on learning and continuous improvement. When incidents occur, the ability to respond effectively and then extract meaningful lessons from the experience can mean the difference between recurring issues and systemic improvements. This involves not only technical expertise but also the soft skills needed to facilitate blameless postmortems and drive organizational learning to improve workflows.
Distributed systems design (40%)
As systems grow more distributed and complex, expertise in distributed system design has become increasingly valuable with two out of five SREs identifying it as a key skill. Understanding how to build and maintain reliable systems across multiple regions, clouds, and technologies has become crucial as organizations expand their digital footprint.
The emergence of cost management skills
But perhaps the most interesting trend emerging from recent surveys is the growing importance of cost management skills. In an era of increasing cloud complexity and rising infrastructure costs, SREs are increasingly being called upon to balance reliability with financial efficiency. This new dimension adds another layer of complexity to the role, requiring SREs to consider the cost implications of their architectural decisions and optimization strategies.
This evolving skill set reflects broader changes in the technology landscape. As organizations continue their digital transformation journeys, the role of the SRE has expanded beyond traditional operational concerns to encompass a wider range of business-critical competencies. The modern SRE needs to be part systems engineer, part business analyst, and part strategic advisor.
For those considering a career in SRE or looking to evolve their existing role, understanding these key skills provides a valuable roadmap for professional development. The diversity of required skills also highlights why the role remains so engaging and challenging — there's always something new to learn and master in the pursuit of system reliability.
The new frontier: Cost optimization
Here's where things get interesting. The survey revealed that 85% of observability practitioners have some responsibility for cost management. For 31%, it's a formal part of their job evaluation.
This trend isn't emerging in isolation. As organizations continue their cloud migration journeys and expand their digital footprints, many are experiencing the sticker shock of rapidly escalating cloud costs. The days of treating cloud resources as an unlimited utility are waning and being replaced by a more nuanced approach that balances technical requirements with financial sustainability.
What makes this shift particularly fascinating is how naturally it aligns with the core competencies of observability practitioners and SREs. These professionals already possess deep insights into system behavior, resource utilization, and performance patterns. They understand which services are essential, which are over-provisioned, and where optimization opportunities lie. In many ways, they're ideally positioned to lead cost optimization initiatives while maintaining service reliability.
The incorporation of cost management into observability practices is transforming how teams approach system design and optimization. Decisions about data retention, sampling rates, and instrumentation density now carry financial implications that must be carefully weighed. The question is no longer just "can we collect this data?" but also "should we collect this data and at what granularity?"
The approach to observability tooling and infrastructure is changing
This evolution is also changing how organizations approach observability tooling and infrastructure. Teams are looking for solutions that provide both technical insights and cost visibility. The ability to understand the financial impact of observability decisions — from logging volumes to metric collection frequencies — has become crucial for making informed architectural choices.
The formal integration of cost management into job evaluations for 31% of practitioners signals a maturation in how organizations view the relationship between technical operations and business outcomes. It recognizes that effective system reliability isn't just about maintaining uptime and performance — it's about doing so in a cost-effective manner that supports business sustainability.
This shift also presents new opportunities for observability practitioners to demonstrate their value to organizations. By combining their technical expertise with cost optimization skills, these professionals can drive improvements that impact both system reliability and the bottom line. The ability to speak both languages — technical and financial — is becoming an increasingly valuable skill in the modern technology landscape.
Looking ahead, this trend suggests that the future of observability will be more intertwined with financial operations (FinOps) practices. The most successful practitioners will be those who can navigate this intersection effectively, making informed decisions that balance technical needs with financial constraints. As cloud costs continue to gain more attention in boardrooms, the role of observability practitioners in managing these costs will likely only grow in importance.
For professionals in the field, this evolution presents both challenges and opportunities. Developing skills in cost optimization and financial analysis may require stepping out of traditional technical comfort zones. However, the ability to drive both technical excellence and financial efficiency positions observability practitioners as key strategic partners in their organizations' success.
Balancing act: Reliability vs. cost vs. innovation
So, how do we balance these competing priorities? Here are some strategies I've found effective:
Treat cost as a reliability concern: Just as we set SLOs for uptime or latency, consider setting objectives for cost efficiency. This mindset can help align cost management with our core mission of reliability.
Use observability for cost insights: Use your observability tools to gain visibility into cost drivers. Many platforms, including Elastic Observability, now offer features to correlate performance metrics with cost data.
Automate cost optimization: Apply your automation skills to cost management. Set up alerts for unusual spending spikes, automate resource scaling based on demand, and create self-service tools for developers to understand the cost implications of their design choices.
Collaborate across teams: Work closely with development teams to build cost-awareness into the development process. This could involve creating cost-based architectural decision trees or including cost considerations in code reviews.
Invest in FinOps knowledge: Familiarize yourself with FinOps principles and tools. This emerging practice bridges the gap between finance, technology, and business.
- Use AI/machine learning (ML) for predictive cost management: As the survey showed, AI/ML is becoming increasingly important in observability. Look for ways to apply these technologies to predict and optimize costs proactively.
The role of AI/ML in the evolving SRE landscape
Speaking of AI/ML, the survey had some interesting findings in this area:
72% of teams are already using AI/ML for observability use cases.
The top use case is correlating logs, metrics, and traces for troubleshooting.
While only 13% say they're getting high value from AI/ML today, 39% expect high value in the future.
The numbers tell an intriguing story: Nearly three-quarters of teams have already incorporated AI/ML capabilities into their observability practices, marking a significant shift in how modern organizations approach system monitoring and troubleshooting.
Today's primary challenge for AI in observability is focused on one of the field's most persistent challenges: correlating different types of telemetry data. The ability to automatically connect logs, metrics, and traces for troubleshooting has emerged as the leading use case — addressing a pain point that has long plagued observability practitioners. This application of AI helps cut through the complexity of modern distributed systems, potentially reducing investigation times from hours to minutes.
However, the current state of AI in observability presents an interesting paradox. While adoption is high, only 13% of teams report achieving high value from these technologies today. This gap between adoption and satisfaction suggests we're in a transitional period, where organizations are actively experimenting with AI capabilities but haven't yet fully optimized their implementation.
But the optimism about future value is striking with nearly 40% of teams expecting to derive high value from AI/ML in their observability practices in the coming years. This confidence indicates that while teams may be struggling with current implementations, they see clear potential for these technologies to transform their operations.
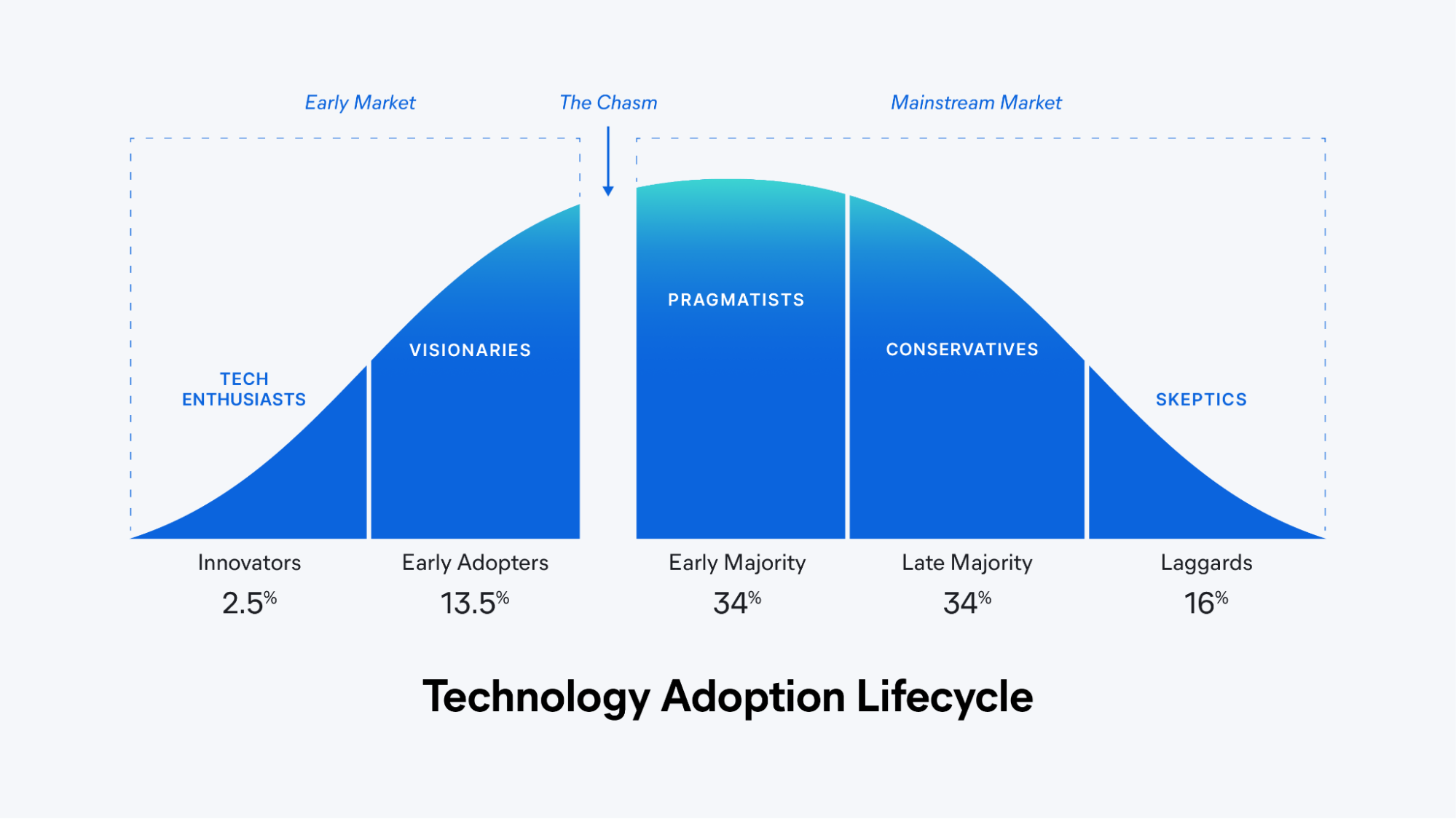
The evolution of AI in observability mirrors a broader pattern we've seen with many technological transformations: early adoption focused on automating existing processes followed by more transformative applications that fundamentally change how we work — essentially, leaping across the chasm as seen in the technology adoption lifecycle model above. Current AI implementations often focus on augmenting traditional observability practices — making existing workflows more efficient. The real transformation will likely come as these technologies mature and enable entirely new approaches to understanding and maintaining complex systems.
Looking ahead
The potential applications of AI in observability extend far beyond correlation and troubleshooting. Imagine systems that can predict potential failures before they occur, automatically adjust their own monitoring parameters based on changing conditions, or provide natural language interfaces for complex system queries. These capabilities, while still emerging, could fundamentally change how teams approach system reliability and performance optimization.
The survey data also suggests an important shift in how organizations view the relationship between AI and human expertise. Rather than replacing human judgment, AI is increasingly seen as a tool for augmenting human capabilities — helping practitioners handle the growing scale and complexity of modern systems while freeing them to focus on more strategic work.
This evolution in AI capabilities could also help address the growing cost management responsibilities many teams face. Advanced AI systems could help optimize resource utilization, suggest cost-saving measures, and balance performance requirements with budget constraints — all while maintaining required reliability levels.
For organizations considering or currently implementing AI-enabled observability solutions, these findings suggest a measured approach: Embrace the technology's current capabilities while preparing for its evolution. Focus on use cases with proven value like telemetry correlation while building the foundational knowledge and infrastructure needed to take advantage of more advanced capabilities as they mature.
The gap between current and expected value from AI/ML in observability represents both a challenge and an opportunity. While teams may need to temper their expectations for immediate transformative results, the potential for these technologies to revolutionize observability practices remains strong. As AI capabilities and teams continue to mature, organizations will become more sophisticated in their implementations. We're also likely to see that value gap close, ushering in a new era of intelligent observability practices, including cost controls.
Embracing the evolution of an SRE
The expanding role of SREs brings both challenges and opportunities. Yes, we're being asked to wear more hats than ever before. But this also means we have more opportunities to drive strategic value for our organizations.
By embracing these new responsibilities, particularly around cost optimization and AI, we can elevate our role from "keeping the lights on" to driving business success. And isn't that why many of us got into this field in the first place — to make a real, tangible impact on our companies and the users we serve?
So, if your CTO drops a cost-cutting bombshell in your lap, try not to let your stomach drop. Instead, see it as an opportunity to flex your SRE muscles (details in this recent survey) and use your AI tools in new and impactful ways. After all, in the world of SRE, change is the only constant — and that's exactly what makes this job so exciting.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by email
- Print this page
Print

