Now that you have built an Elasticsearch index and loaded some documents into it, you are ready to implement full-text search.
How the Search will Work
Let's have a quick review of how the search solution will work in the tutorial application. With the Flask application running, you can go to http://localhost:5001 to access the main page, which looks like this:
The code that renders this page is implemented in the app.py file:
This is a very simple endpoint that renders an HTML template. In Flask applications templates are located in a templates sub-directory, so you will find this and other templates included with the application there.
Let's look at the implementation of the search field in file templates/index.html. Here is the relevant portion of this template:
Here you can see that this is an HTML form with a single field of type text named query. The method attribute of the form is set to POST, which tells the browser to submit this form in a POST request. The action attribute is set to the URL that corresponds to the handle_search endpoint of the Flask application. When the form is submitted, the handle_search() function will execute.
The current implementation of handle_search() is shown below:
The function obtains the text typed by the user in the text field from Flask's request.form dictionary, and stores it in the query local variable. The function then renders the index.html template, but this type it passes some additional arguments so that the page can show the search results. The four arguments that the template receives are:
query: the query text entered by the user in the form.results: a list of search resultsfrom_: the zero-based index of the first resulttotal: the total number of results
Since the search functionality is not implemented, for now the arguments that are passed to the render_template() function indicate that no results were found.
The task now is to implement a full-text query and pass actual results so that the index.html page can display them.
The Elasticsearch services uses a Query DSL (Domain Specific Language) based on the JSON format to define queries.
The Elasticsearch client for Python has a search() method that is used to submit a search query. Let's add a search() helper method in search.py that uses this method:
This method invokes the search() method of the Elasticsearch client with the index name. The query_args argument captures all the keyword arguments provided to the method, and then passes-them through to the es.search() method. These arguments are going to be how the caller specifies what to search for.
Match Queries
The Elasticsearch Query DSL offers many different ways to query an index. Looking through the sub-sections in the documentation you will familiarize with the different types of queries that are possible. The very common task of searching text is covered in the Full-Text queries section.
For the first search implementation, let's use the Match query. Below you can see an example that uses this query:
The example above is given in a format that resembles a raw HTTP request. It is useful to be familiar with this format, as it is used extensively in the Elasticsearch documentation and in the Elasticsearch API Console. Luckily this format is very easy to translate into a call using the Python client library. Below you can see the equivalent Python code for the above example:
When converting API Console examples to Python, remember that the top-level keys in the body of the query have to be converted to keyword arguments in the Python call. The examples also do not specify an index, which would be needed when making the Python call.
By looking at the query structure you can probably deduce what kind of search this is requesting. The call requests a match query on a field called name, and the text to search for is search text here.
This style of query is reasonably easy to incorporate into the tutorial applications. Open app.py and find the handle_search() method. Replace the current version with this new one:
The call to es.search() in the second line of this new version of the endpoint invokes the search() method added above in search.py, which in turns calls the search() method of the Elasticsearch client.
Can you figure out what the query is going to do? This is a match query similar to the above example. The field that is going to be searched is name, which contains the titles of the documents in the my_documents index that you built in the previous section. The text to search for is what the user typed in the search field on the web page, which is stored in the query local variable.
The part of the search response that contains the results is response['hits']. This is an object with a few keys, of which two are of interest in this implementation:
response['hits']['hits']: the list of search results.response['hits']['total']: the total number of results that are available. The number of results is given in avaluesub-key, so in practice, the expression to get the total number of results isresults['hits']['total']['value']. Note that the total number of results can be an approximation when there are a large number of results. See the response body documentation for details.
The call to render_template() in this new version of the endpoint passes the list of results in the results template argument, and the total number of results in total. The query argument receives the query string as before, and from_ is still hardcoded to 0, as it will be implemented later when pagination is added.
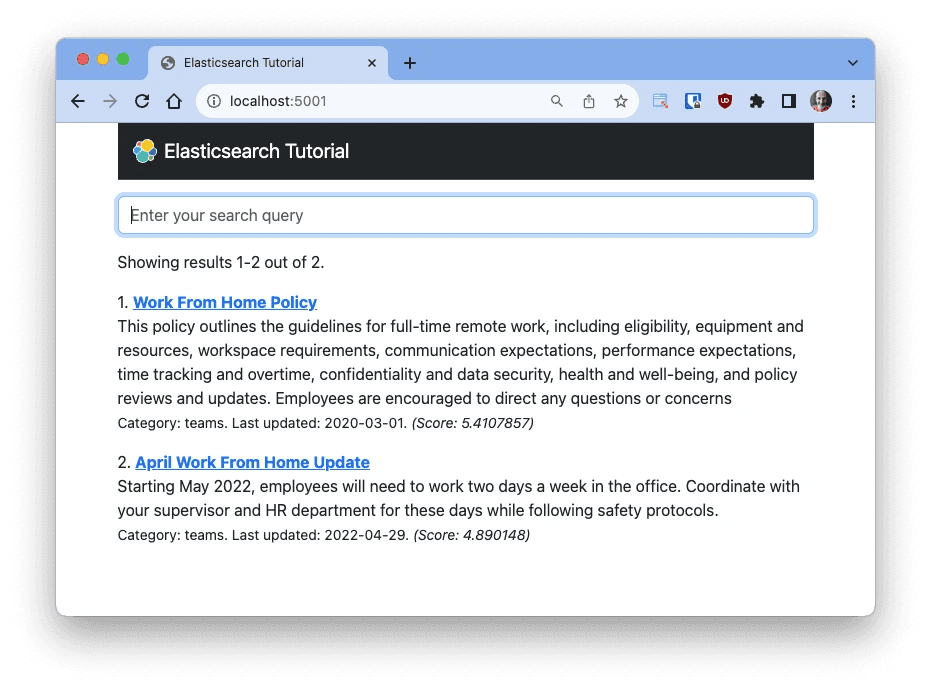
And with this, the application has a first implementation of full-text search. Go back to your web browser and navigate to http://localhost:5001 to open the application. If for any reason you do not have the Flask application running, start the application again before doing this. Enter a search text such as policy or work from home and you will see relevant results. Below you can see the results when searching for work from home:
The index.html template that you downloaded with the starter application includes all the logic to render search results. If you are curious about this, here is the section of this template that renders the result list:
From this code it is interesting to note that the data associated with a returned result is available under the _source key. There is also a _id field that contains the unique identifier assigned to the result.
A score associated with each result can be obtained from _score. The score provides a measure of relevance, with higher scores indicating a closer match to the query text. By default results are returned in order by their score, from highest to lowest. Scores in Elasticsearch are calculated using the Okapi BM25 algorithm.
If you are interested in exploring the topics covered in this section in more detail, use the following links:
Retrieving Individual Results
You may have noticed that the index.html template renders the title of each search result as a link. The link points to the third and last endpoint that came implemented in the starter Flask application, called get_document. The implementation that is provided returns a "Document not found" hardcoded text, so this is what you will see if you click on any of the results while playing with the application.
To correctly render individual documents, let's add a retrieve_document() helper method in search.py, using the get() method of the Elasticsearch client:
Here you can see how these unique identifiers that were assigned to each document are useful, as this is what the application can use to refer to individual documents.
Here is the current implementation of the get_document() endpoint:
You can see that the URL associated with this endpoint includes the document id, and the links that are rendered for each search result also have the id incorporated in the respective URLs, so all that is missing is to replace this simplistic implementation with one that retrieves the document and renders it. Replace the endpoint with this updated version:
Here the retrieve_document() method from search.py is used to obtain the requested document. The document.html is then rendered, with a title that comes from the name field, and a list of paragraphs from content.
Try running some more queries, and clicking on results, which should now allow you to see the full content.
Searching Multiple Fields
After you played with the application for a while you may have noticed that a lot of queries return no results. As you recall, the search is currently implemented on the name field of each document, which is where the document titles are stored. Documents also have summary and content fields, which have longer texts that are apt to be searched as well, but right now these are ignored.
In this section you are going to learn about another common full-text search query, the Multi-match, which requests a search to be carried out across multiple fields of an index.
Here is the example multi-match query from the documentation:
Let's use this example as a base to expand the handle_search() endpoint to run multi-match queries on the name, summary and content fields combined. Here is the updated endpoint code:
With this change, there is a lot more text to search, so much that some queries may have more than the maximum of 10 results that are returned by default. In the next chapter you will learn about dealing with long lists of results through pagination.
Previously
Create an IndexNext
Pagination