Get hands-on with Elasticsearch: Dive into our sample notebooks, start a free cloud trial, or try Elastic on your local machine now.
Elasticsearch Query Language (ES|QL) is designed for fast, efficient querying of large datasets. It has a straightforward syntax which will allow you to write complex queries easily, with a pipe based language, reducing the learning curve. We're going to use ES|QL to run statistical analysis and compare different odds.
If you are reading this, you probably want to know how rich you can get before actually reaching the same odds of being hit by a bus. I can't blame you, I want to know too. Let's work out the odds so that we can make sure we win the lottery rather than get in an accident!
What we are going to see in this blog is figuring out the probability of being hit by a bus and the probability of achieving wealth. We'll then compare both and understand until what point your chances of getting rich are higher, and when you should consider getting life insurance.
So how are we going to do that? This is going to be a mix of magic numbers pulled from different articles online, some synthetics data and the power of ES|QL, the new Elasticsearch Query Language. Let's get started.
Data for the ES|QL analysis
The magic number
The challenge starts here as the dataset is going to be somewhat challenging to find. We are then going to assume for the sake of the example that ChatGPT is always right. Let’s see what we get for the following question:

Cough Cough… That sounds about right, this is going to be our magic number.
Generating the wealth data
Prerequisites
Before running any of the scripts below, make sure to install the following packages:
Now, there is one more thing we need, a representative dataset with wealth distribution to compute wealth probability. There is definitely some portion of it here and there, but again, for the example we are going to generate a 500K line dataset with the below python script. I am using python 3.11.5 in this example:
It should take some time to run depending on your configuration since we are injecting 500K documents here!
FYI, after playing with a couple of versions of the script above and the ESQL query on the synthetic data, it was obvious that the net worth generated across the population was not really representative of the real world. So I decided to use a log-normal distribution (np.random.lognormal) for income to reflect a more realistic spread where most people have lower incomes, and fewer people have very high incomes.
Net Worth Calculation: Used a combination of random multipliers (np.random.uniform(0.5, 5)) and additional noise (np.random.normal(0, 10000)) to calculate net worth. Added a check to ensure no negative net worth values by using np.maximum(0, net_worths).
Not only have we generated 500K documents, but we also used the Elasticsearch python client to bulk ingest all these documents in our deployment. Please note that you will find the endpoint to pass in as hosts Cloud ID in the code above.
For the deployment API key, open Kibana, and generate the key in Stack Management / API Keys:
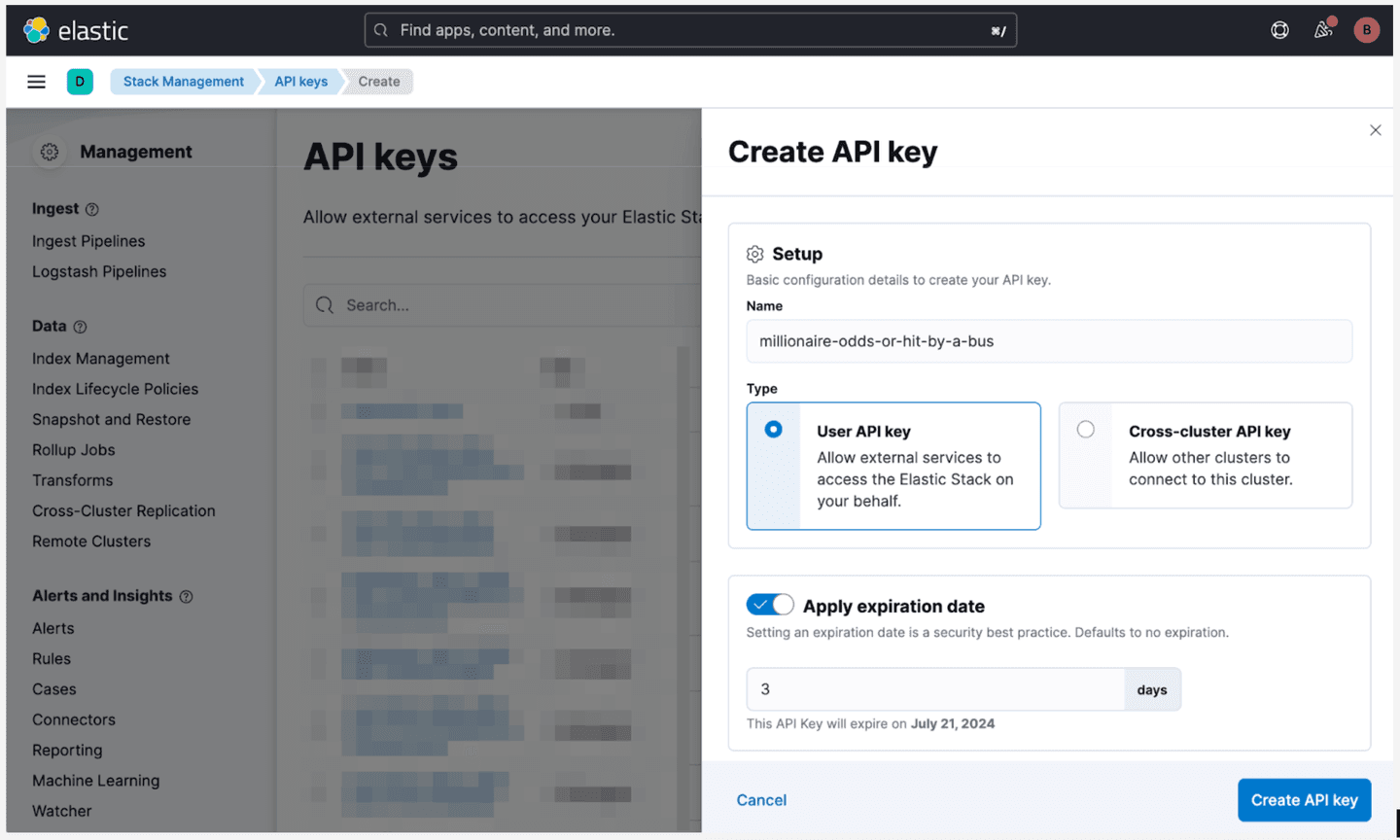
The good news is that if you have a real data set, all you will need to do is to change the above code to read your dataset and write documents with the same data mapping.
Ok we're getting there! The next step is pouring our wealth distribution.
ES|QL wealth analysis
Introducing ES|QL: A powerful tool for data analysis
The arrival of Elasticsearch Query Language (ES|QL) is very exciting news for our users. It largely simplifies querying, analyzing, and visualizing data stored in Elasticsearch, making it a powerful tool for all data-driven use cases.
ES|QL comes with a variety of functions and operators, to perform aggregations, statistical analyses, and data transformations. We won’t address them all in this blog post, however our documentation is very detailed and will help you familiarize with the language and the possibilities.
To get started with ES|QL today and run the blog post queries, simply start a trial on Elastic Cloud, load the data and run your first ES|QL query.
Understanding the wealth distribution with our first query
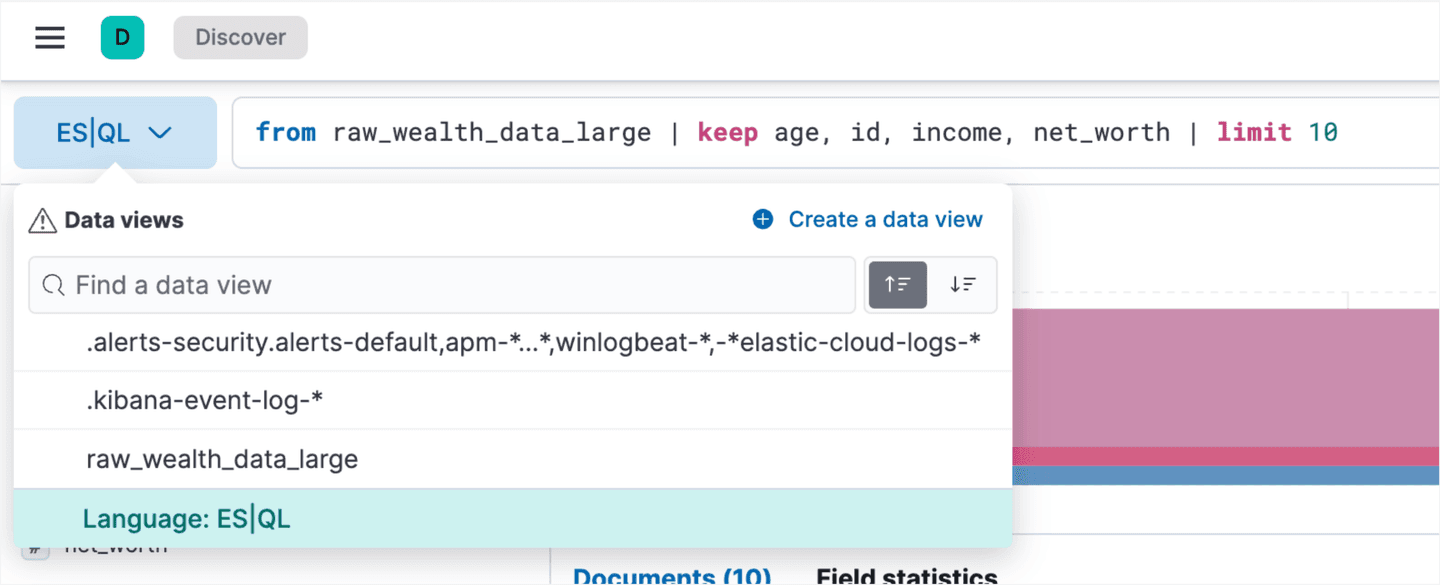
To get familiar with the dataset, head to Discover in Kibana and switch to ES|QL in the dropdown on the left hand side:
Let’s fire our first request:
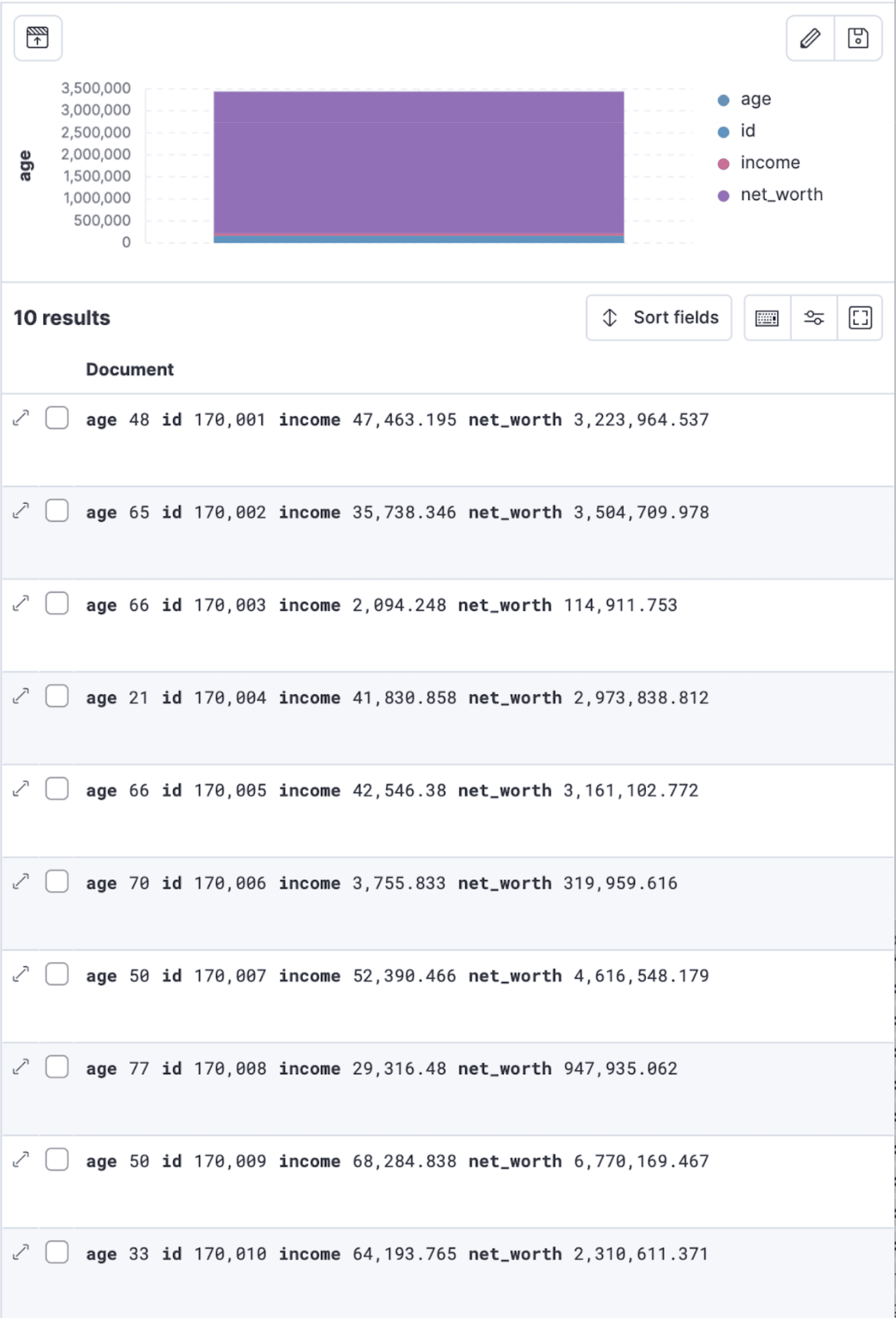
As you could expect from our indexing script earlier, we are finding the documents we bulk ingested, notice the simplicity of pulling data from a given dataset with ES|QL where every query starts with the From clause, then your index.
In the query above given we have 500K lines, we limited the amount of returned documents to 10. To do this, we are passing the output of the first segment of the query via a pipe to the limit command to only get 10 results. Pretty intuitive, right?
Alright, what would be more interesting is to understand the wealth distribution in our dataset, for this we will leverage one of the 30 functions ES|QL provides, namely percentile.
This will allow us to understand the relative position of each data point within the distribution of net worth. By calculating the median percentile (50th percentile), we can gauge where an individual’s net worth stands compared to others.
Like our first query, we are passing the output of our index to another function, Stats, which combined with the percentile function will output the median net worth:
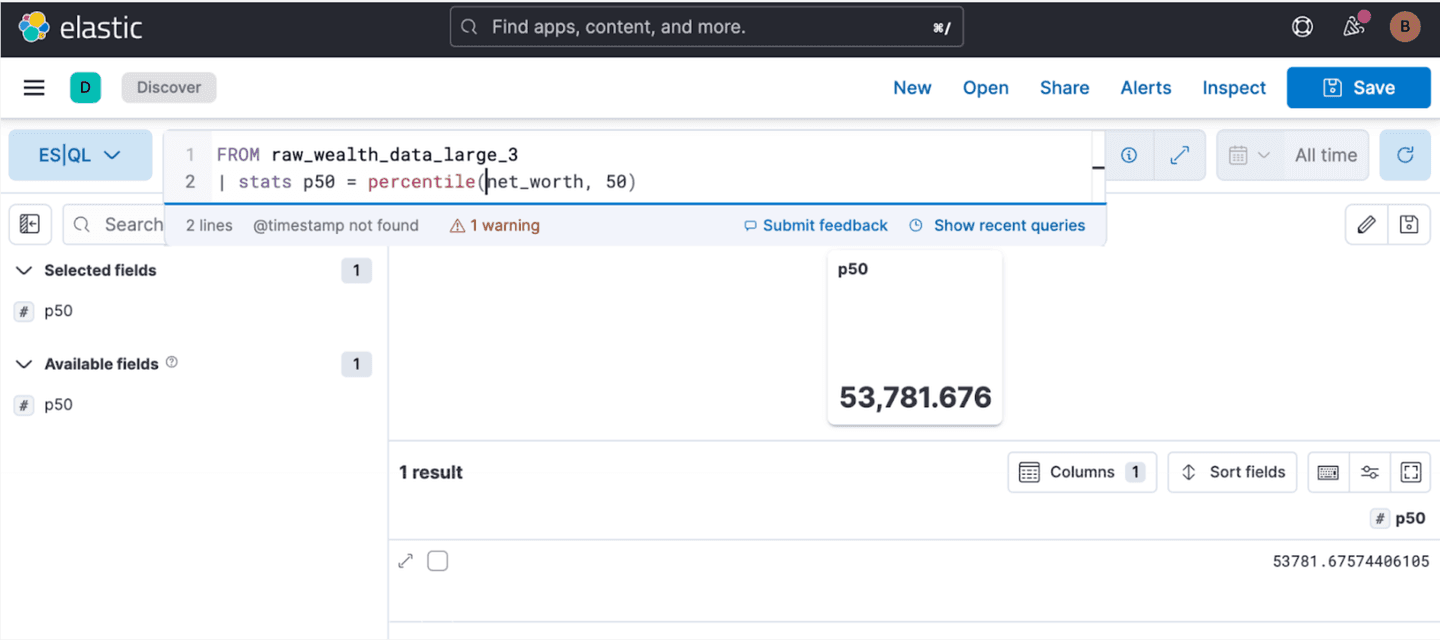
The median is about 54K, which unfortunately is probably optimistic compared to the real world, but we are not going to solve this here. If we go a little further, we can look at the distribution in more granularity by computing more percentiles:
With the below output:
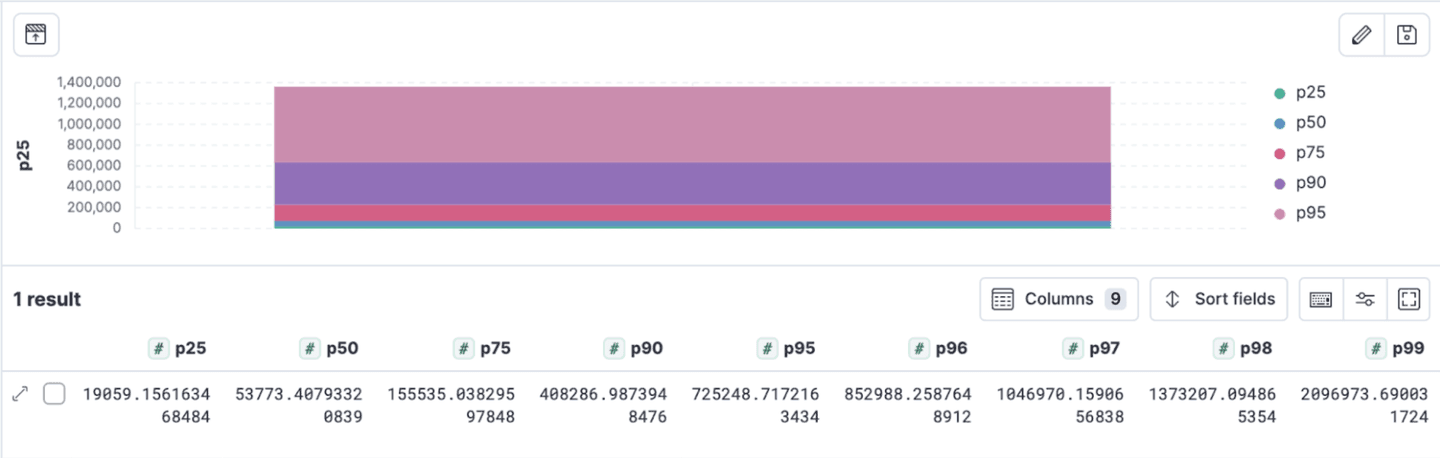
The data reveals a significant disparity in wealth distribution, with the majority of wealth being concentrated among the richest individuals. Specifically, the top 5% (95th percentile) possess a disproportionately large portion of the total wealth, with a net worth starting at $852,988.26 and increasing dramatically in the higher percentiles.
The 99th percentile individuals hold a net worth exceeding $2 million, highlighting the skewed nature of wealth distribution. This indicates that a substantial portion of the population has modest net worth, which is probably what we want for this example.
Another way to look at this is to augment the previous query and grouping by age to see if there is, (in our synthetic dataset), a relation between wealth and age:
This could be visualized in a Kibana dashboard. Simply:
- Navigate to Dashboard
- Add a new ES|QL visualization
- Copy and paste our query
- Move the age field to the horizontal axis in the visualization configuration
Which will output:
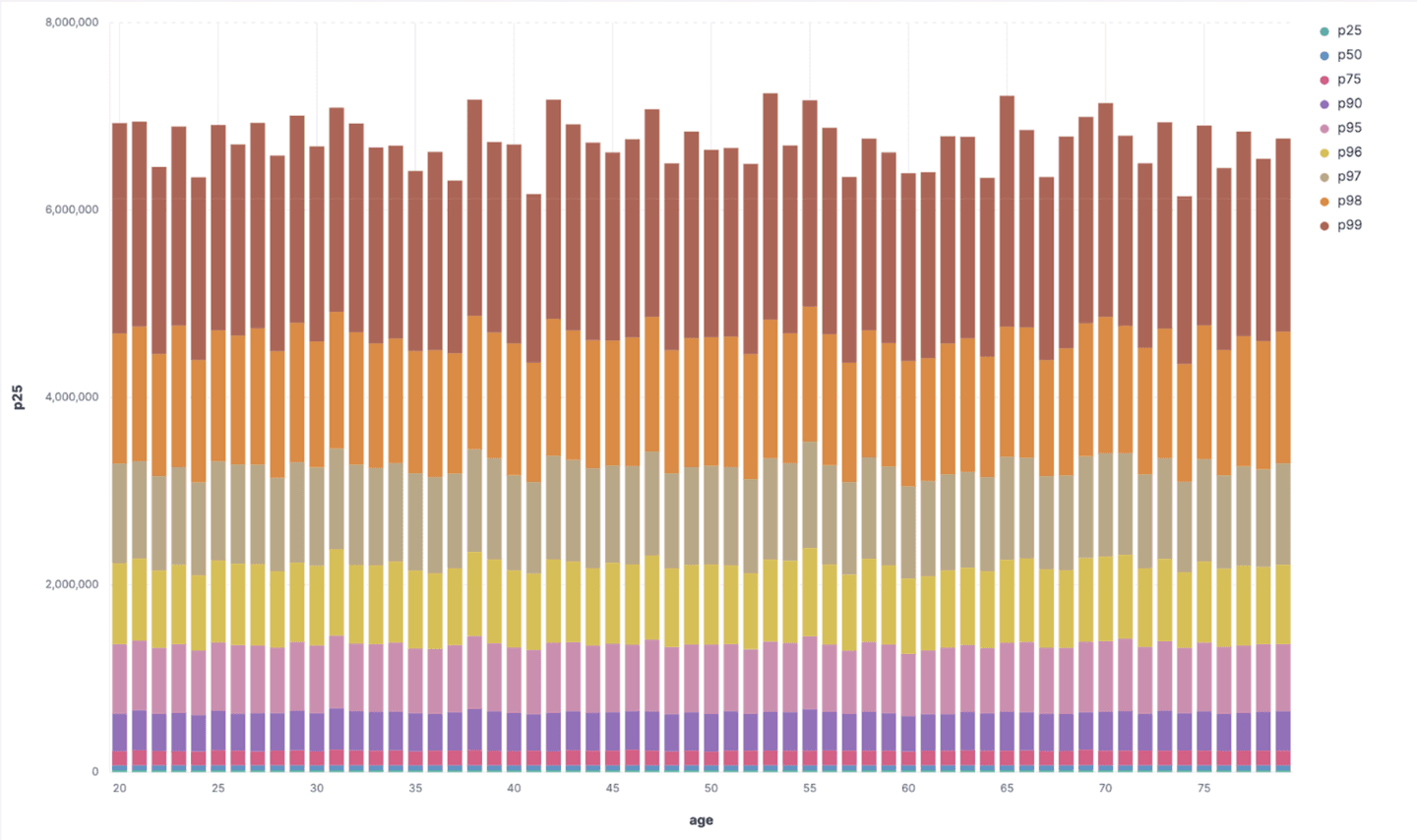
The above suggests that the data generator randomized wealth uniformly across the population age, there is no specific trend pattern we can really see.
Median Absolute Deviation (MAD)
We calculate the median absolute deviation (MAD) to measure the variability of net worth in a robust manner, less influenced by outliers.
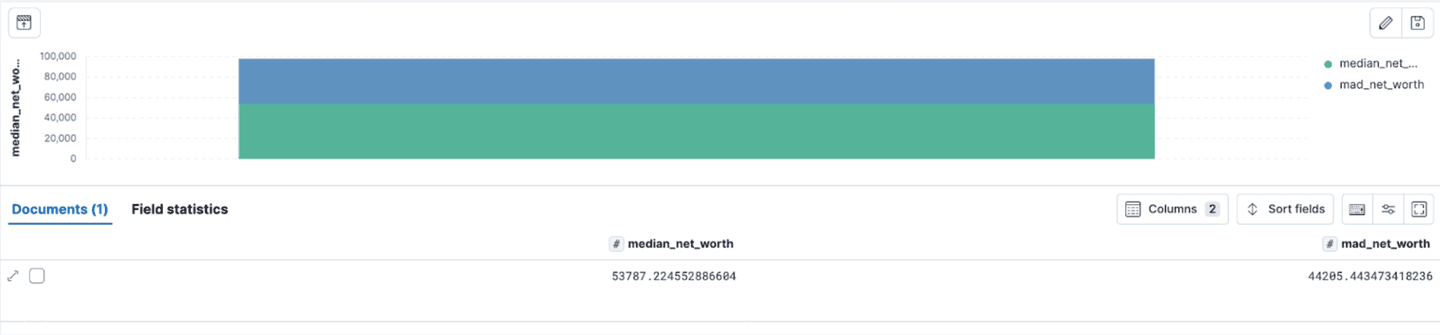
With a median net worth of 44,205.44, we can infer the typical range of Net Worth: Most individuals’ net worth falls within a range of 9,581.78 to $97,992.66.
The statistical showdown between Net Worth and Bus Collision
Alright, this is the moment to understand how rich we can get, based on our dataset, before getting hit by a bus. To do that, we are going to leverage ES|QL to pull our entire dataset in chunks and load it into a pandas dataframe to build a net worth probability distribution. Finally, we will determine where the ends meet between the net worth and bus collision probabilities.
The entire Python notebook is available here. I also recommend you read this blog post which walks you through using ES|QL with pandas dataframes.
Helper functions
As you can see in the previously referred blog post, we introduced support for ES|QL since version 8.12 of the Elasticsearch python client. Thus our notebook first defines the below functions:
The first function is straightforward and executes an ES|QL query, the second is fetching the entire dataset from our index. Notice the trick in there that I am using a counter built-in to a field in my index to paginate through the data. This is workaround I am using while our engineering team is working on the support for pagination in ES|QL.
Next, knowing that we have 500K documents in our index, we simply call these function to load the data in a data frame:
Fit Pareto distribution
Next, we fit our data to a Pareto distribution, which is often used to model wealth distribution because it reflects the reality that a small percentage of the population controls most of the wealth. By fitting our data to this distribution, we can more accurately represent the probabilities of different net worth levels.
We can visualize the pareto distribution with the code below: ``
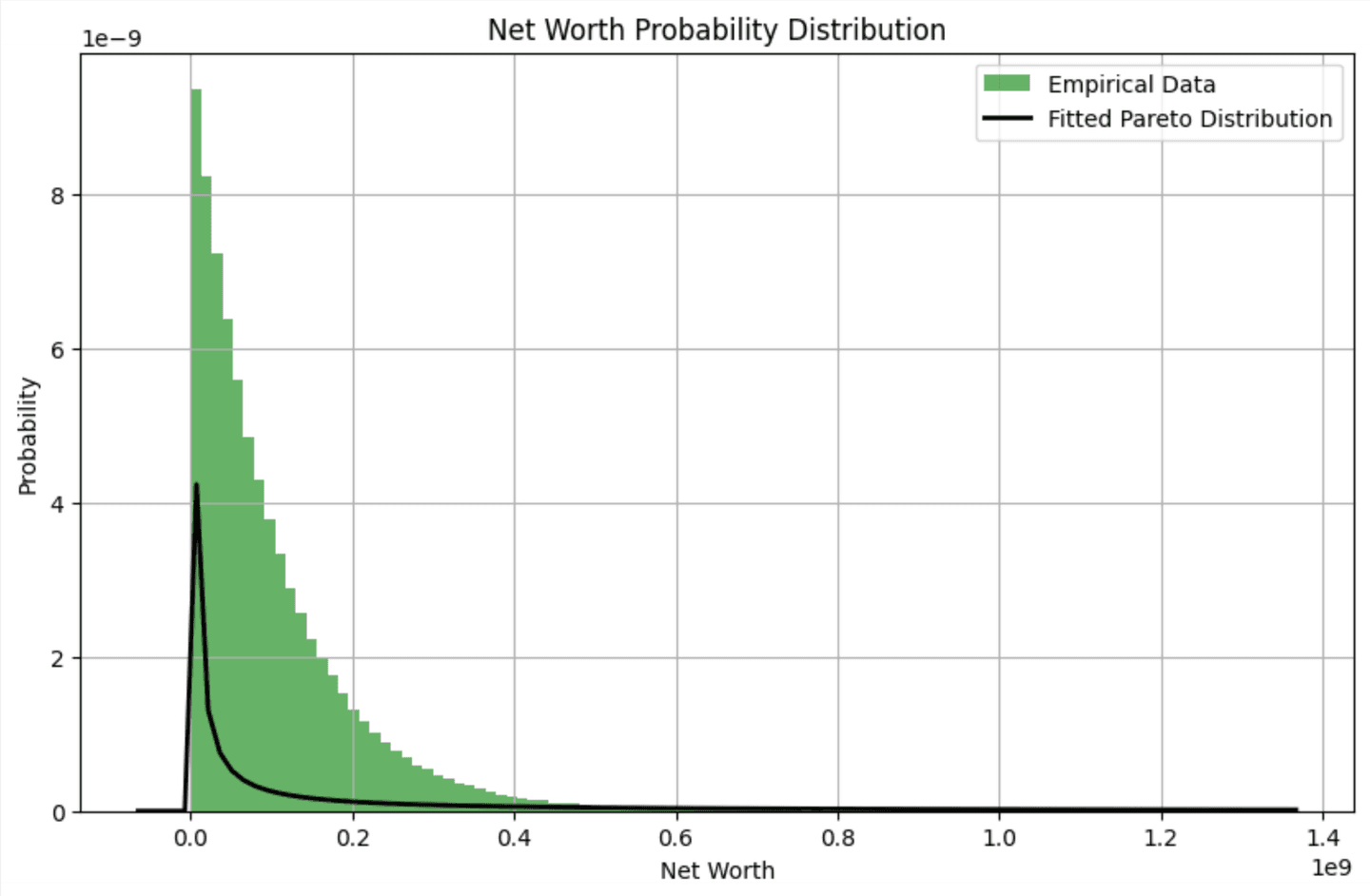
Breaking point
Finally, with the calculated probability, we determine the target net worth corresponding to the bus hit probability and visualize it. Remember, we use the magic number ChatGPT gave us for the probability of getting hit by a bus:
Conclusion
Based on our synthetic dataset, this chart vividly illustrates that the probability of amassing a net worth of approximately $12.5 million is as rare as the chance of being hit by a bus. For the fun of it, let’s ask ChatGPT what the probability is:
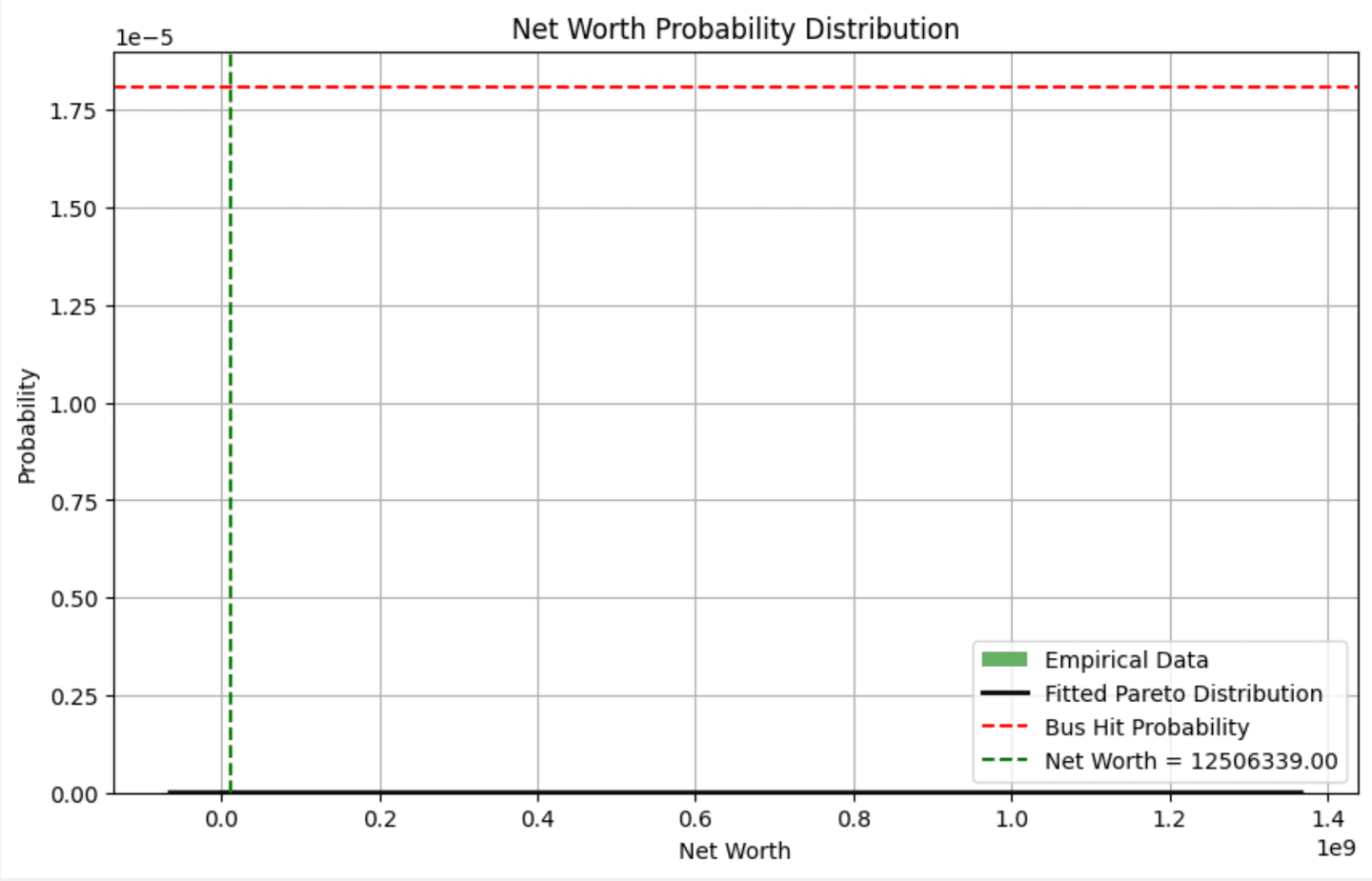

Okay… $439 million? I think ChatGPT might be hallucinating again.
Frequently Asked Questions
What is ES|QL?
ES|QL is designed for fast, efficient querying of large datasets. It has a straightforward syntax which will allow you to write complex queries easily, with a pipe based language, reducing the learning curve.
Related Content
January 19, 2026
Faster ES|QL stats with Swiss-style hash tables
How Swiss-inspired hashing and SIMD-friendly design deliver consistent, measurable speedups in Elasticsearch Query Language (ES|QL).
January 8, 2026
Hybrid search and multistage retrieval in ES|QL
Explore the multistage retrieval capabilities of ES|QL, using FORK and FUSE commands to integrate hybrid search with semantic reranking and native LLM completions.
December 12, 2025
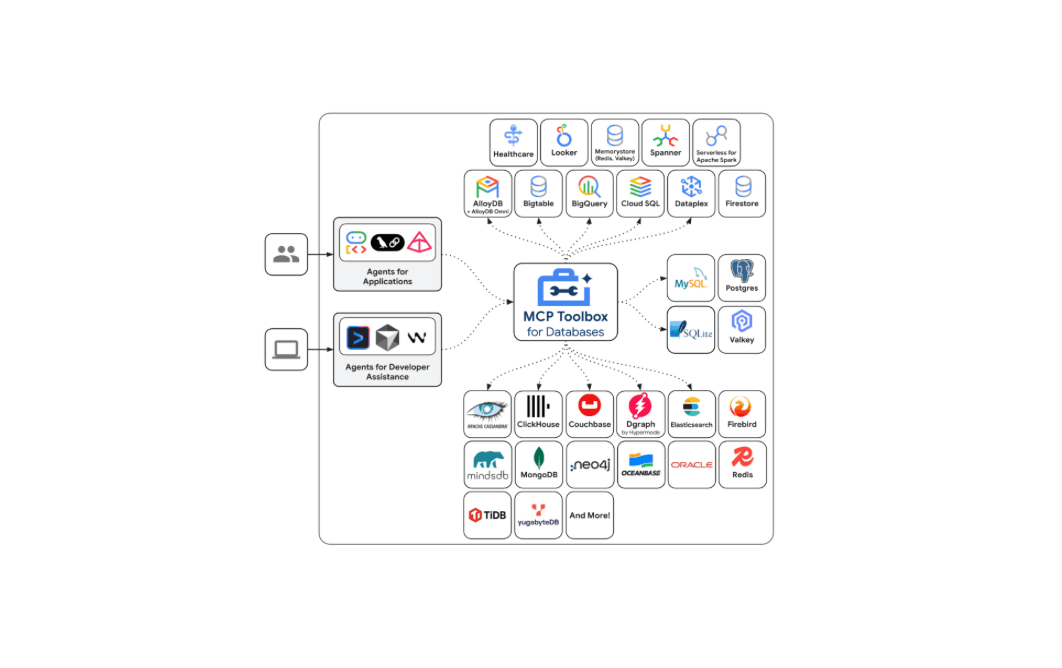
Introducing Elasticsearch support in the Google MCP Toolbox for Databases
Explore how Elasticsearch support is now available in the Google MCP Toolbox for Databases and leverage ES|QL tools to securely integrate your index with any MCP client.
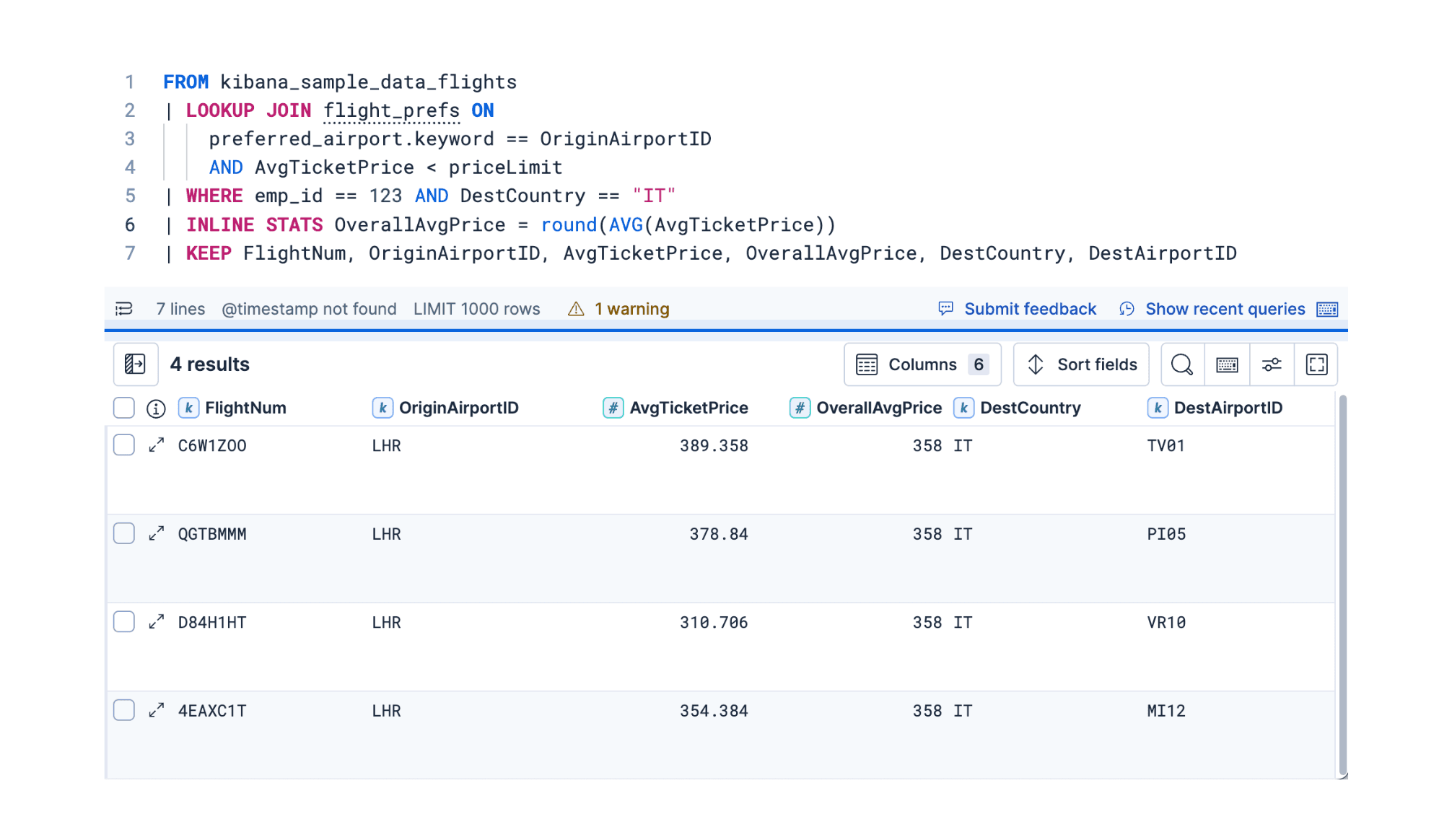
December 2, 2025
ES|QL in 9.2: Smart Lookup Joins and time-series support
Explore three separate updates to ES|QL in Elasticsearch 9.2: an enhanced LOOKUP JOIN for more expressive data correlation, the new TS command for time-series analysis, and the flexible INLINE STATS command for aggregation.

November 4, 2025
Multimodal search for mountain peaks with Elasticsearch and SigLIP-2
Learn how to implement text-to-image and image-to-image multimodal search using SigLIP-2 embeddings and Elasticsearch kNN vector search. Project focus: finding Mount Ama Dablam peak photos from an Everest trek.