From vector search to powerful REST APIs, Elasticsearch offers developers the most extensive search toolkit. Dive into sample notebooks on GitHub to try something new. You can also start your free trial or run Elasticsearch locally today.
Elasticsearch and Lucene report card: noteworthy speed and efficiency investments
Our mission at Elastic is to make Apache Lucene the best vector database out there, and to continue to make Elasticsearch the best retrieval platform out there for search and RAG. Our investments into Lucene are key to ensure that every release of Elasticsearch brings increasing faster performance and scale.
Customers are already building the next generation of AI enabled search applications with Elastic’s vector database and vector search technology. Roboflow is used by over 500,000 engineers to create datasets, train models, and deploy computer vision models to production. Roboflow uses Elastic vector database to store and search billions of vector embeddings.
In this blog we summarize recent enhancements and optimisations that significantly improve vector search performance in Elasticsearch and Apache Lucene, over and above performance gains delivered with Lucene 9.9 and Elasticsearch 8.12.x.
The integration of vector search into Elasticsearch relies on Apache Lucene, the layer that orchestrates data storage and retrieval. Lucene's architecture organizes data into segments, immutable units that undergo periodic merging. This structure allows for efficient management of inverted indices, essential for text search. With vector search, Lucene extends its capabilities to handle multi-dimensional points, employing the hierarchical navigable small world (HNSW) algorithm to index vectors.
This approach facilitates scalability, enabling data sets to exceed available RAM size while maintaining performance. Additionally, Lucene's segment-based approach offers lock-free search operations, supporting incremental changes and ensuring visibility consistency across various data structures. The integration however comes with its own engineering challenges. Merging segments requires recomputing HNSW graphs, incurring index-time overhead. Searches must cover multiple segments, leading to possible latency overhead. Moreover, optimal performance requires scaling RAM as data grows, which may raise resource management concerns.
Lucene's integration into Elasticsearch comes with the benefit of robust vector search capabilities. This includes aggregations, document level security, geo-spatial queries, pre-filtering, to full compatibility with various Elasticsearch features. Imagine running vector searches using a geo bounding box, this is an example usecase enabled by Elasticsearch and Lucene.
Lucene's architecture lays a solid foundation for efficient and versatile vector search within Elasticsearch. Let’s explore optimization strategies and enhancements we have implemented to integrate vector search into Lucene, which delivers a high performance and comprehensive feature-set for developers.
Harnessing Lucene's architecture for multi-threaded search
Lucene's segmented architecture enables the implementation of multi-threaded search capabilities. Elasticsearch’s performance gains come from efficiently searching multiple segments simultaneously. Latency of individual searches is significantly reduced by using the processing power of all available CPU cores. While it may not directly improve overall throughput, this enhancement prioritizes minimizing response times, ensuring that users receive their search results as swiftly as possible.
Furthermore, this optimization is particularly beneficial for Hierarchical Navigable Small World (HNSW) searches, as each graph is independent of the others and can be searched in parallel, maximizing efficiency and speeding up retrieval times even further.
The advantage of having multiple independent segments extends to the architectural level, especially in serverless environments. In this new architecture, the indexing tier is responsible for creating new segments, each containing its own HSNW graph. The search tier can simply replicate these segments without incurring the CPU cost of indexation. This separation allows a significant portion of compute resources to be dedicated to searches, optimizing overall system performance and responsiveness.
Accelerating multi-graph vector search
In spite of gains achieved with parallelization, each segment's searches would remain independent, unaware of progress made by other segment searches. So our focus shifted towards optimizing the efficiency of concurrent searches across multiple segments.
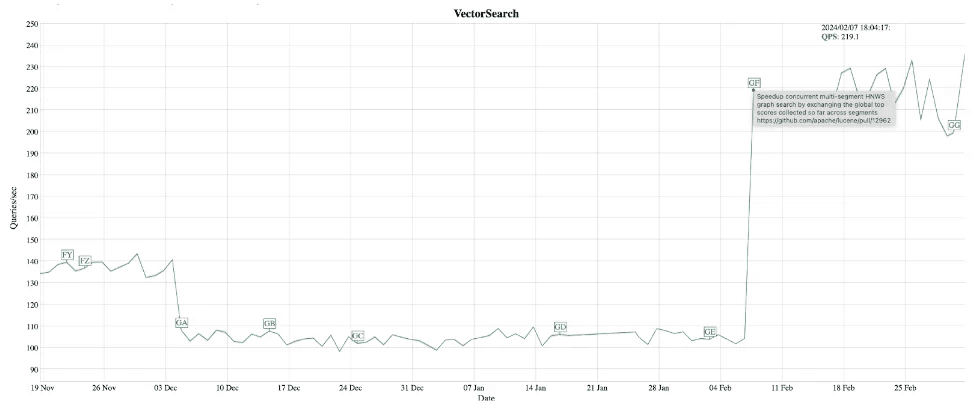
The graph shows that the number queries per second increased from 104 queries/sec to 219 queries/sec.
Recognizing the potential for further speedups, we leveraged our insights from optimizing lexical search, to enable information exchange among segment searches allowing for better coordination and efficiency in vector search.
Our strategy for accelerating multi-graph vector search revolves around balancing exploration and exploitation within the proximity graph. By adjusting the size of the expanded match set, we control the trade-off between runtime and recall, crucial for achieving optimal search performance across multiple graphs.
In multi-graph search scenarios, the challenge lies in efficiently navigating individual graphs, while ensuring comprehensive exploration to avoid local minima. While searching multiple graphs independently yields higher recall, it incurs increased runtime due to redundant exploration efforts. To mitigate this, we devised a strategy to intelligently share state between searches, enabling informed traversal decisions based on global and local competitive thresholds.
This approach involves maintaining shared global and local queues of distances to closest vectors, dynamically adapting search parameters based on the competitiveness of each graph's local search. By synchronizing information exchange and adjusting search strategies accordingly, we achieve significant improvements in search latency while preserving recall rates comparable to single-graph searches.
The impact of these optimizations is evident in our benchmark results. In concurrent search and indexing scenarios, we notice up to 60% reduction in query latencies! Even for queries conducted outside of indexing operations, we observed notable speedups and a dramatic decrease in the number of vector operations required. These enhancements, integrated into Lucene 9.10 and subsequently Elasticsearch 8.13, mark significant strides towards enhancing vector database performance for search while maintaining excellent recall rates.
Harnessing Java's latest advancements for ludicrous speed
In the area of Java development, automatic vectorization has been a boon, optimizing scalar operations into SIMD (Single Instruction Multiple Data) instructions through the HotSpot C2 compiler. While this automatic optimization has been beneficial, it has its limitations, particularly in scenarios where explicit control over code shape yields superior performance. Enter Project Panama Vector API, a recent addition to the JDK offering an API for expressing computations reliably compiled to SIMD instructions at runtime.
Lucene's vector search implementation relies on fundamental operations like dot product, square, and cosine distance, both in floating point and binary variants. Traditionally, these operations were backed by scalar implementations, leaving performance enhancements to the JIT compiler. However, recent advancements introduce a paradigm shift, enabling developers to express these operations explicitly for optimal performance.
Consider the dot product operation, a fundamental vector computation. Traditionally implemented in Java with scalar arithmetic, recent innovations leverage the Panama Vector API to express dot product computations in a manner conducive to SIMD instructions. This revised implementation iterates over input arrays, multiplying and accumulating elements in batches, aligning with the underlying hardware capabilities.
By harnessing Panama Vector API, Java code now interfaces seamlessly with SIMD instructions, unlocking the potential for significant performance gains. The compiled code, when executed on compatible CPUs, leverages advanced vector instructions like AVX2 or AVX 512, resulting in accelerated computations. Disassembling the compiled code reveals optimized instructions tailored to the underlying hardware architecture.
Microbenchmarks comparing traditional Java implementations to those leveraging Panama Vector API illustrate dramatic performance improvements. Across various vector operations and dimension sizes, the optimized implementations outperform their predecessors by significant margins, offering a glimpse into the transformative power of SIMD instructions.

Micro-benchmark comparing dot product with the new Panama API (dotProductNew) and the scalar implementation (dotProductOld).
Beyond microbenchmarks, the real-world impact of these optimizations is quite exciting to think about. Vector search benchmarks, such as SO Vector, demonstrate notable enhancements in indexing throughput, merge times, and query latencies. Elasticsearch, embracing these advancements, incorporates the faster implementations by default, ensuring users reap the performance benefits seamlessly.
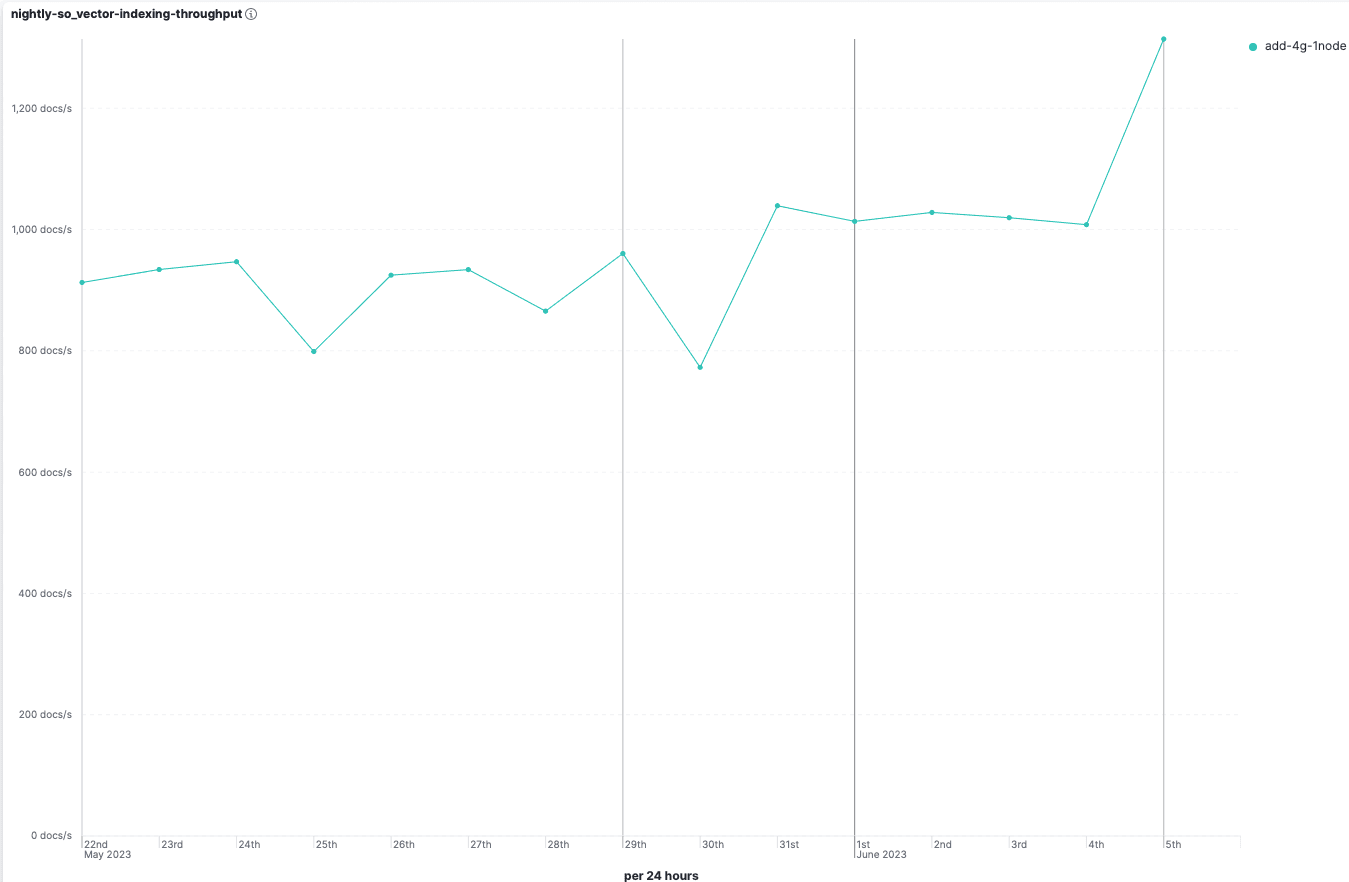
The graph shows indexing throughput increased from about 900 documents/sec to about 1300 documents/sec.
Despite the incubating status of Panama Vector API, its quality and potential benefits are undeniable. Lucene's pragmatic approach allows for selective adoption of non-final JDK APIs, balancing the promise of performance improvements with maintenance considerations. With Lucene and Elasticsearch, users can leverage these advancements effortlessly, with performance gains translating directly to real-world workloads.
The integration of Panama Vector API into Java development yields a new era of performance optimization, particularly in vector search scenarios. By embracing hardware-accelerated SIMD instructions, developers can unlock efficiency gains, visible both in microbenchmarks and macro-level benchmarks. As Java continues to evolve, leveraging its latest features promises to propel performance to new heights, enriching user experiences across diverse applications.
Maximizing memory efficiency with scalar quantization
Memory consumption has long been a concern for efficient vector database operations, particularly for searching large datasets. Lucene introduces a breakthrough optimization technique - scalar quantization - aimed at significantly reducing memory requirements without sacrificing search performance.
Consider a scenario where querying millions of float32 vectors of high dimensions demands substantial memory, leading to significant costs. By embracing byte quantization, Lucene slashes memory usage by approximately 75%, offering a viable solution to the memory-intensive nature of vector search operations.
For quantizing floats to bytes, Lucene implements Scalar quantization a lossy compression technique that transforms raw data into a compressed form, sacrificing some information for space efficiency. Lucene's implementation of scalar quantization achieves remarkable space savings with minimal impact on recall, making it an ideal solution for memory-constrained environments.
Lucene's architecture, consisting of nodes, shards, and segments, which facilitates efficient distribution and management of documents for search. Each segment stores raw vectors, quantized vectors, and metadata, ensuring optimized storage and retrieval mechanisms.
Lucene's vector quantization adapts dynamically over time, adjusting quantiles during segment merge operations to maintain optimal recall. By intelligently handling quantization updates and re-quantization when necessary, Lucene ensures consistent performance while accommodating changes in data distribution.
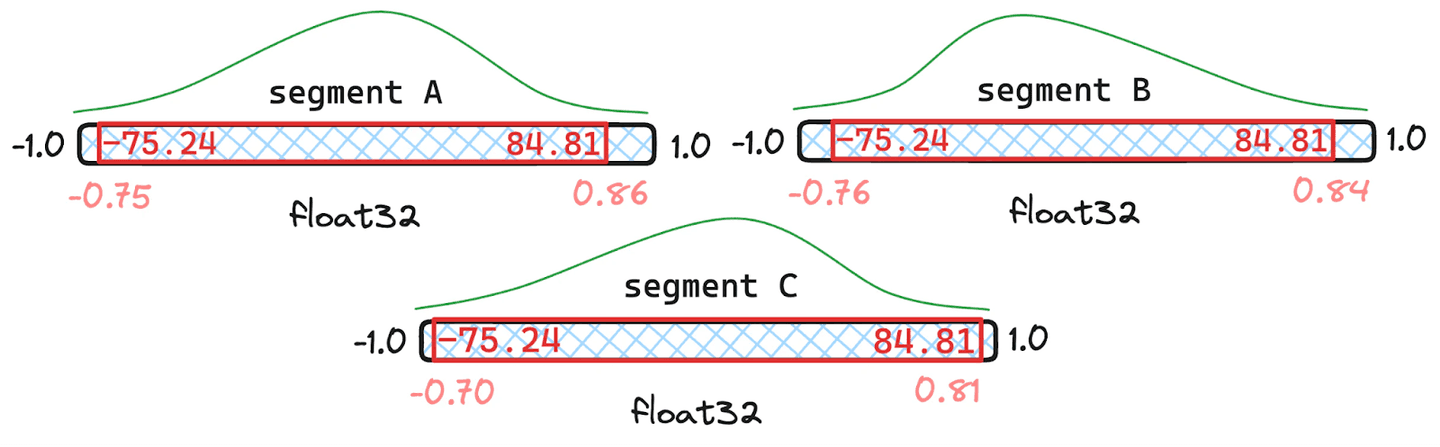
Example of merged quantiles where segments A and B have 1000 documents and C only has 100.
Experimental results demonstrate the efficacy of scalar quantization in reducing memory footprint while maintaining search performance. Despite minor differences in recall compared to raw vectors, Lucene's quantized vectors offer significant speed improvements and recall recovery with minimal additional vectors.
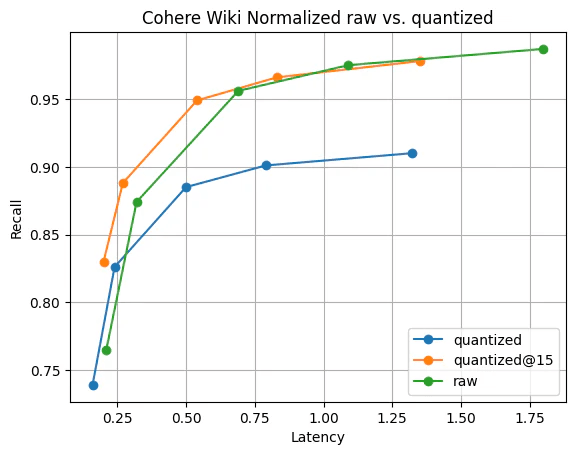
Recall@10 for quantized vectors vs raw vectors. The search performance of quantized vectors is significantly faster than raw, and recall is quickly recoverable by gathering just 5 more vectors; visible by quantized@15.
Lucene's scalar quantization presents a revolutionary approach to memory optimization in vector search operations. With no need for training or optimization steps, Lucene seamlessly integrates quantization into its indexing process, automatically adapting to changes in data distribution over time. As Lucene and Elasticsearch continue to evolve, widespread adoption of scalar quantization will revolutionize memory efficiency for vector database applications, paving the way for enhanced search performance at scale.
Achieving seamless compression with minimal impact on recall
To make compression even better, we aimed to reduce each dimension from 7 bits to just 4 bits. Our main goal was to compress data further while still keeping search results accurate. By making some improvements, we managed to compress data by a factor of 8 without making search results worse. Here's how we did it.
We focused on keeping search results accurate while making data smaller. By making sure we didn't lose important information during compression, we could still find things well even with less detailed data. To make sure we didn't lose any important information, we added a smart error correction system.
We checked our compression improvements by testing them with different types of data and real search situations. This helped us see how well our searches worked with different compression levels and what we might lose in accuracy by compressing more.
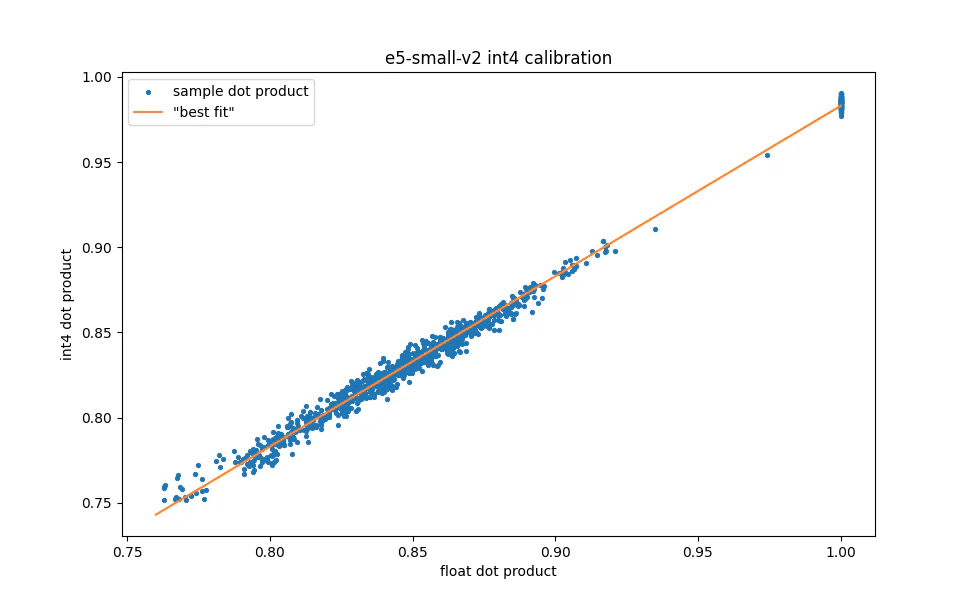
Comparison of int4 dot product values to the corresponding float values for a random sample of 100 documents and their 10 nearest neighbors.
These compression features were created to easily work with existing vector search systems. They help organizations and users save space without needing to change much in their setup. With this simple compression, organizations can expand their search systems without wasting resources.
In short, moving to 4 bits per dimension for scalar quantization was a big step in making compression more efficient. It lets users compress their original vectors by 8 times. By optimizing carefully, adding error correction, testing with real data, and offering scalable deployment, organizations could save a lot of storage space without making search results worse. This opens up new chances for efficient and scalable search applications.
Paving the way for binary quantization
The optimization to reduce each dimension to 4 bits not only delivers significant compression gains but also lays the groundwork for further advancements in compression efficiency. Specifically, future advancements like binary quantization into Lucene, a development that has the potential to revolutionize vector storage and retrieval.
In an ongoing effort to push the boundaries of compression in vector search, we are actively working on integrating binary quantization into Lucene using the same techniques and principles that underpin our existing optimization strategies. The goal is to achieve binary quantization of vector dimensions, thereby reducing the size of the vector representation by a factor of 32 compared to the original floating-point format.
Through our iterations and experiments, we want to deliver the full potential of vector search while maximizing resource utilization and scalability. Stay tuned for further updates on our progress towards integrating binary quantization into Lucene and Elasticsearch, and the transformative impact it will have on vector database storage and retrieval.
Multi-vector integration in Lucene and Elasticsearch
Several real world applications rely on text embedding models and large text inputs. Most embedding models have token limits, which necessitate chunking of longer text into passages. Therefore, instead of a single document, multiple passages and embeddings must be managed, potentially complicating metadata preservation.
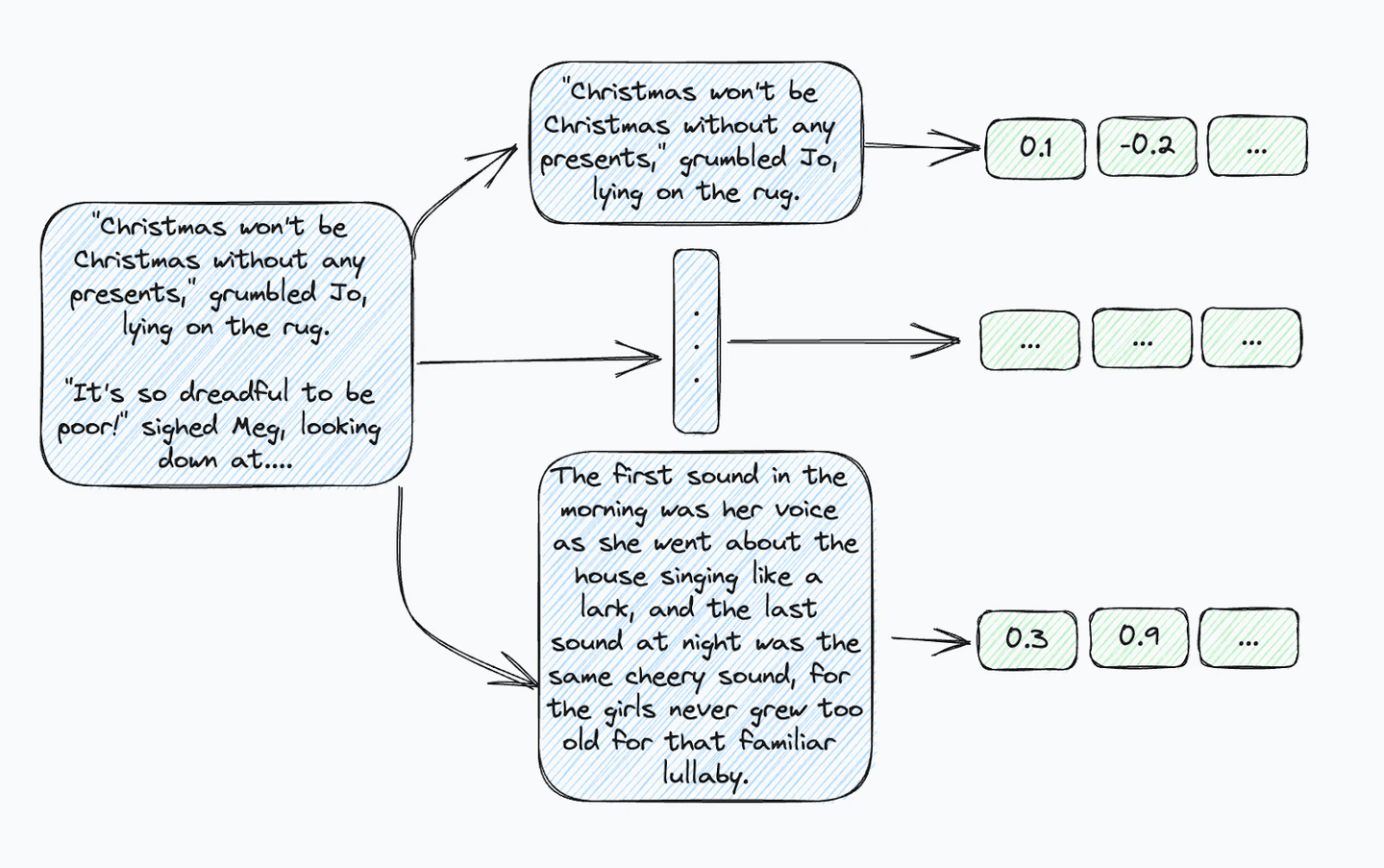
Now instead of having a single piece of metadata indicating, for example the first chapter of the book “Little Women”, you have to index that information data for every sentence.
Lucene's "join" functionality, integral to Elasticsearch's nested field type, offers a solution. This feature enables multiple nested documents within a top-level document, allowing searches across nested documents and subsequent joins with their parent documents. So, how do we deliver support for vectors in nested fields with Elasticsearch?
The key lies in how Lucene joins back to parent documents when searching child vector passages. The parallel concept here is the debate around pre-filtering versus post-filtering in kNN methods, as the timing of joining significantly impacts result quality and quantity. To address this, recent enhancements to Lucene enable pre-joining against parent documents while searching the HNSW graph.
Practically, pre-joining ensures that when retrieving the k nearest neighbors of a query vector, the algorithm returns the k nearest documents instead of passages. This approach diversifies results without complicating the HNSW algorithm, requiring only a minimal additional memory overhead per stored vector.
Efficiency is improved by leveraging certain restrictions, such as disjoint sets of parent and child documents and the monotonicity of document IDs. These restrictions allow for optimizations using bit sets, providing rapid identification of parent document IDs.
Searching through a vast number of documents efficiently required investing in nested fields and joins in Lucene. This work helps storage and search for dense vectors that represent passages within long texts, making document searches in Lucene more effective. Overall, these advancements represent an exciting step forward in the area of vector database retrieval within Lucene.
Wrapping up (for now)
We're dedicated to making Elasticsearch and Lucene the best vector database with every release. Our goal is to make it easier for people to search for things. With some of the investments we discuss in this blog, there is significant progress, but we're not done!
To say that the gen AI ecosystem is rapidly evolving is an understatement. At Elastic, we want to give developers the most flexible and open tools to keep up with all the innovation—with features available across recent releases until 8.13 and serverless
Related Content

January 28, 2026
Apache Lucene 2025 wrap-up
2025 was a stellar year for Apache Lucene; here are our highlights.

All about those chunks, ’bout those chunks, and snippets!
Exploring chunking and snippet extraction for LLMs, highlighting enhancements for identifying the most relevant chunks and snippets to send to models such as rerankers and LLMs.
January 20, 2026
Context engineering vs. prompt engineering
Learn how context engineering and prompt engineering differ and why mastering both is essential for building production AI agents and RAG systems.
January 2, 2026
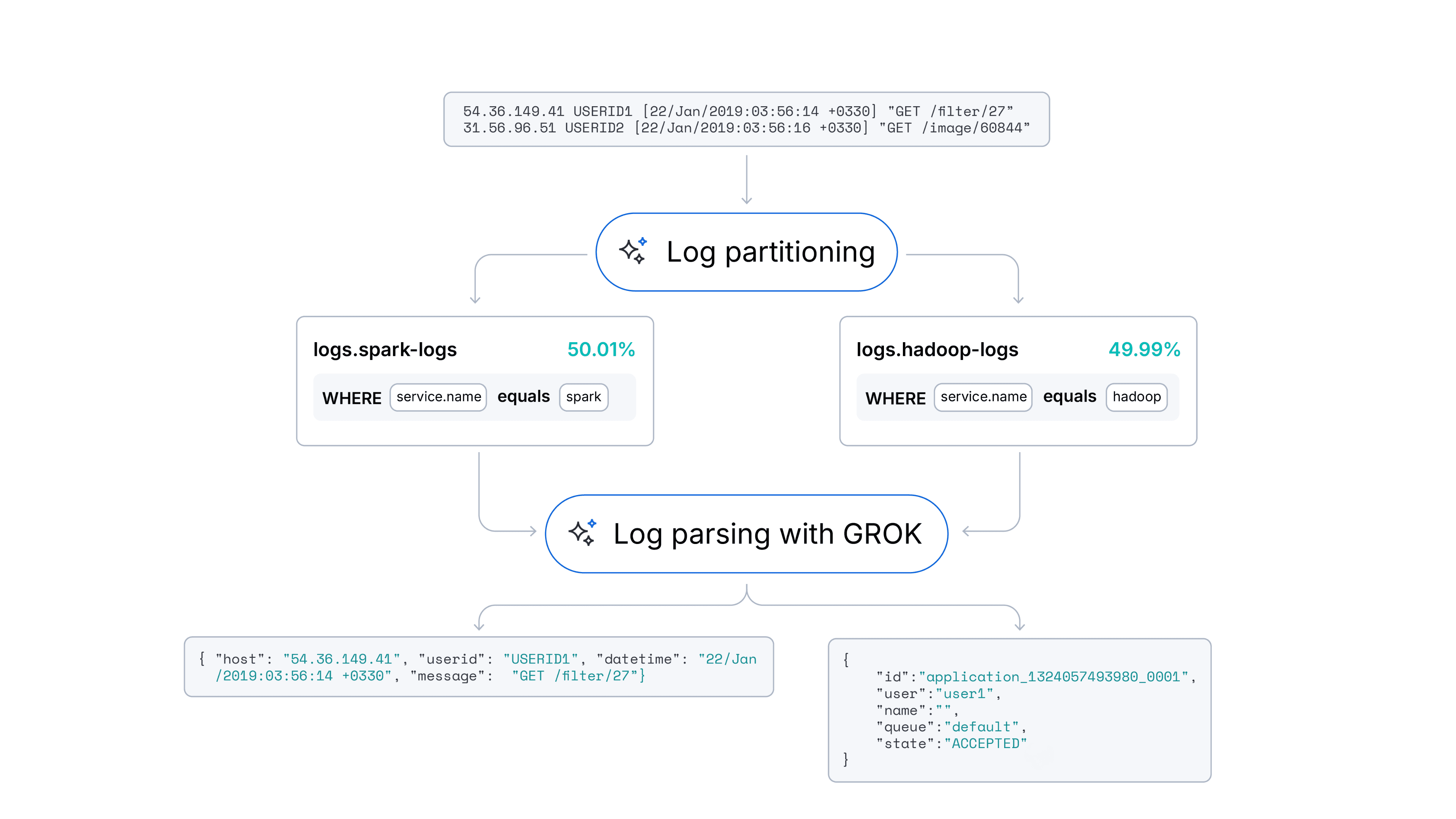
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.
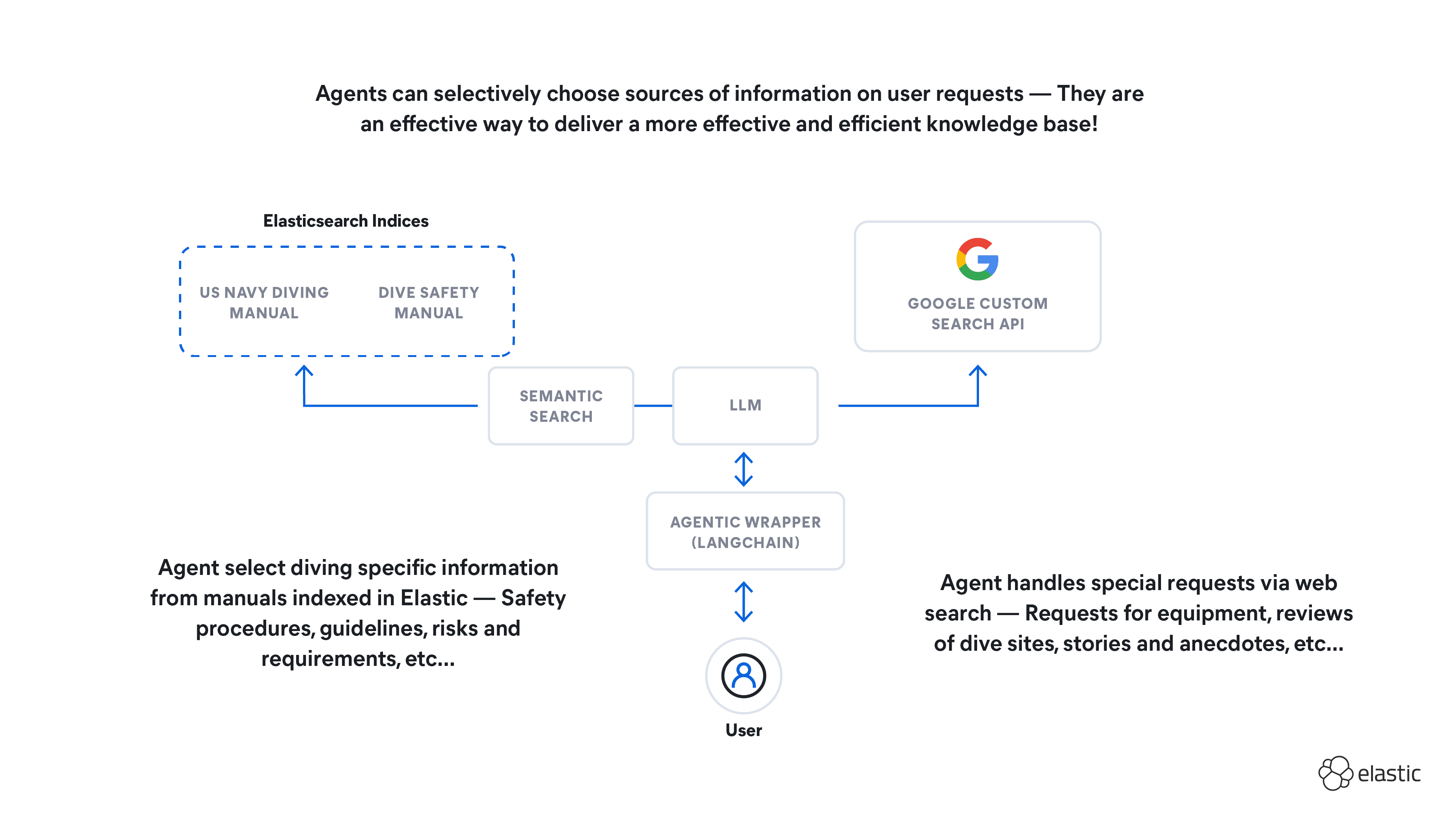
December 31, 2025
How to build an agent knowledge base with LangChain and Elasticsearch
Learn how to build an agent knowledge base and test its ability to query sources of information based on context, use WebSearch for out-of-scope queries, and refine recommendations based on user intention.