Elasticsearch allows you to index data quickly and in a flexible manner. Try it free in the cloud or run it locally to see how easy indexing can be.
Don't miss the follow-up to this blog announcing Open Crawler's promotion to beta! Discover how fast deployment has become with our out-of-the-box Docker images, and explore recent enhancements such as Extraction Rules or Binary Content Extraction. Read more in the blog post Open Crawler now in beta.
There's a new crawler in town! The Open Crawler enables users to crawl web content and index it into Elasticsearch from wherever they prefer. This blog goes over the Open Crawler, compares it to the Elastic Crawler, and explains how to use it.
Background
Elastic has seen a few iterations of Crawler over the years. What started out as Swiftype's Site Search became the App Search Crawler, and then most recently the Elastic Crawler. These Crawlers are feature-rich, and allow for a robust and nuanced method for ingesting website data into Elasticsearch. However, if a user wants to run these on their own infrastructure, they are required to run the entirety of Enterprise Search as well. The Enterprise Search codebase is massive and contains a lot of different tools, so users don't have the option to run just Crawler. Because Enterprise Search is private code, it also isn't entirely clear to the user what they are running.
That has all changed, as we have released the latest iteration of Crawler; the Open Crawler!
Open Crawler allows users to crawl web content and index it into Elasticsearch from wherever they like. There are no requirements to use Elastic Cloud, nor to have Kibana or Enterprise Search instances running. Only an Elasticsearch instance is required to ingest the crawl results into.
This time the repository is open code too. Users can now inspect the codebase, open issues and PR requests, or fork the repository to make changes and run their own crawler variant.
What has changed?
The Open Crawler is considerably more light-weight than the SaaS crawlers that came before it. This product is essentially the core crawler code from the existing Elastic Crawler, decoupled from the Enterprise Search service. Decoupling the Open Crawler has meant leaving some features behind, temporarily. There is a full feature comparison table at the end of this blog if you'd like to read our roadmap towards feature-parity. We intend to reintroduce those features and reach near-feature-parity when this product becomes GA.
This process allowed us to also make improvements to the core product. For example:
- We were able to remove the limitations towards index naming
- It is now possible to use custom mappings on your index before crawling and ingesting content
- Crawl results are now also bulk indexed into Elasticsearch instead of indexed one webpage at a time
- This provided a signficant performance boost, which we get into below
How does the Open Crawler compare to the Elastic Crawler?
As already mentioned, this crawler can be run from wherever you like; your computer, your personal server, or a cloud-hosted one. It can index documents into Elasticsearch on-prem, on Cloud, and even Serverless. You are also no longer tied to using Enterprise Search to ingest your website content into Elasticsearch.
But what is most exciting is that Open Crawler is also faster than the Elastic Crawler.
We ran a performance test to compare the speed of Open Crawler versus that of the Elastic Crawler, our next-latest crawler. Both crawlers crawled the site elastic.co with no alterations to the default configuration. The Open Crawler was set up to run on two AWS EC2 instances; m1.small and m1.large, while Elastic Crawler was run natively from Elastic Cloud. All were set up in the region of N. Virginia. The content was indexed into an Elasticsearch Cloud instance with identical settings (the default 360 GB storage | 8 GB RAM | Up to 2.5 vCPU).
Here are the results:
| Crawler Type | Server RAM | Server CPU | Crawl Duration (mins) | Docs Ingested (n) |
|---|---|---|---|---|
| Elastic Crawler | 2GB | up to 8 vCPU | 305 | 43957 |
| Open Crawler (m1.small) | 1.7 GB | 1 vCPU | 160 | 56221 |
| Open Crawler (m1.large) | 3.75 GB per vCPU | 2 vCPU | 100 | 56221 |
Open Crawler was almost twice as fast for the m1.small and over 3 times as fast for the m1.large!
This is also despite running on servers with less-provisioned vCPU. Open Crawler ingested around 13000 more documents, but that is because the Elastic Crawler combines website pages with identical bodies into a single document. This feature is called duplicate content handling and is in the feature comparison matrix at the end of this blog. The takeaway here is that both Crawlers encountered the same amount of web pages during their respective crawls, even if the ingested document count is different.
Here are some graphs comparing the impact of this on Elasticsearch. These compare the Elastic Crawler with the Open Crawler that ran on the m1.large instance.
CPU
Naturally the Open Crawler caused signficantly less CPU usage on Elastic Cloud, but that's because we've removed the entire Enterprise Search server. It's still worth taking a quick look at where this CPU usage was distributed.
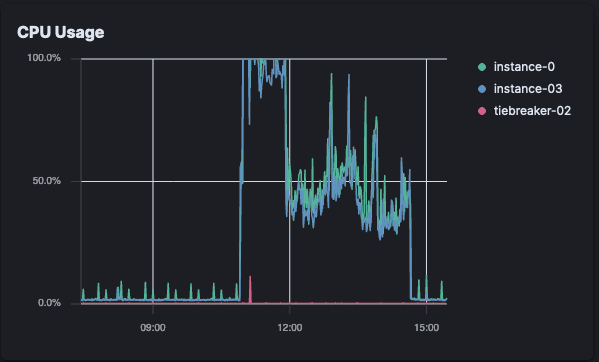
Elastic Crawler CPU load (Elastic Cloud)
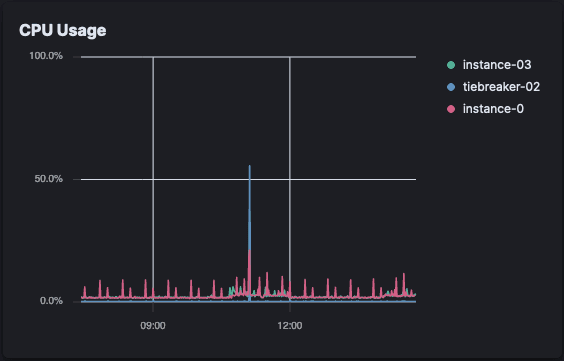
Open Crawler CPU load (Elastic Cloud)
The Elastic Crawler reached the CPU threshold immediately and consistently used it for an hour. It then dropped down and had periodic spikes until the crawl completed.
For the Open Crawler there was almost no noticable CPI usage on Elastic Cloud, but the CPU is still being consumed somewhere, and in our case this was on the EC2 instance.
EC2 CPU load (m1.large)
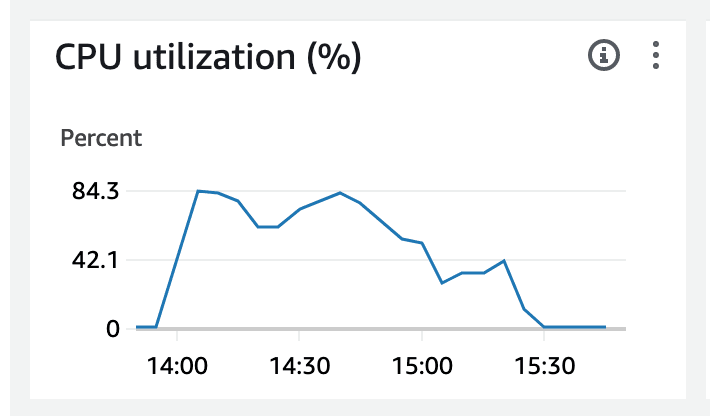
We can see here that the Open Crawler didn't reach the 100% limit threshold. The most CPU it used was 84.3%. This means there's still more room for optimization here. Depending on user setup (and optimizations we can add to the codebase), Open Crawler could be even faster.
Requests (n)
We can see a real change on Elasticsearch server load here by comparing the amount of requests made during the crawl.
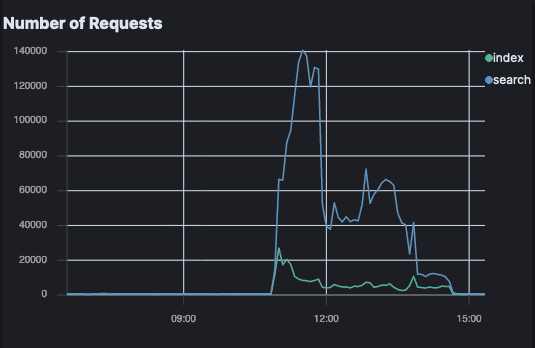
Elastic Crawler requests
Open Crawler requests
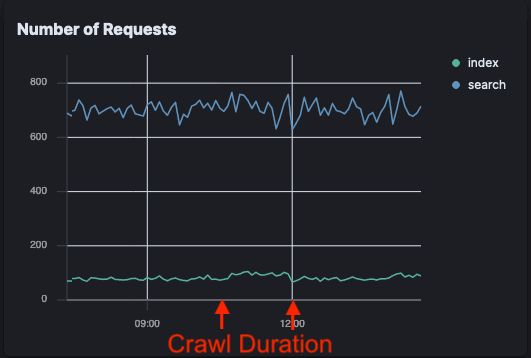
The indexing request impact from Open Crawler is so small it's not even noticeable on this graph compared to the background noise. There's a slight uptick in index requests, and no change to the search requests.
Elastic Crawler, meanwhile, has an explosion of requests; particularly search requests.
This means the Open Crawler is a great solution for users who want to reduce requests made to their Elasticsearch instance.
So why is the Open Crawler so much faster?
1. The Open Crawler makes significantly fewer indexing requests.
The Elastic Crawler indexes crawl results one at a time. It does this to allow for features such as duplicate content management. This means that Elastic Crawler performed 43,957 document indexing requests during its crawl. It also updates documents when it encounters duplicate content, so it also performed over 13000 individual update requests.
The Open Crawler instead pools crawl results and indexes them in bulk. In this test, it indexed the same amount of crawl results in only 604 bulk requests of varying sizes. That's less than 1.5% of the indexing requests made, which is a significant load reduction for Elasticsearch to manage.
2. Elastic Crawler also performs many search requests, further slowing down performance
The Elastic Crawler has its configuration and metadata managed in Elasticsearch pseudo-system indices. When Crawling it periodically checks this configuration and updates the metadata on a few of these indices, which is done through further Elasticsearch requests.
The Open Crawler's configuration is entirely managed in yaml files. It also doesn't track metadata on Elasticsearch indices. The only requests it makes to Elasticsearch are to index documents from crawl results while crawling a website.
3. Open Crawler is simply doing less with crawl results
In the tech-preview stage of Open Crawler, there are many features that are not available yet. In Elastic Crawler, these features are all managed through pseudo-system indices in Elasticsearch. When we add these features to the Open Crawler, we can ensure they are done in a way that doesn't involve multiple requests to Elasticsearch to check configuration. This means Open Crawler should still retain this speed advantage even after reaching near feature parity with Elastic Crawler.
How do I use the Open Crawler?
You can clone the repository now and follow the documentation here to get started. I recommend using Docker to run the Open Crawler if you aren't making changes to source code, to make the process smoother.
If you want to index the crawl results into Elasticsearch, you can also try out a free trial of Elasticsearch on Cloud or download and run Elasticsearch yourself from source.
Here's a quick demo of crawling the website parksaustralia.gov.au. The requirements for this are Docker, a clone/fork of the Open Crawler repository, and a running Elasticsearch instance.
1. Build the Docker image and run it
This can be done in one line with docker build -t crawler-image . && docker run -i -d --name crawler crawler-image.
You can then confirm it is running by using the CLI command to check the version docker exec -it crawler bin/crawler version.

2. Configure the crawler
Using examples in the repository you can create a configuration file. For this example I'm crawling the website parksaustralia.org.au and indexing into a Cloud-based Elasticsearch instance.
Here's an example of my config, which I creatively named example.yml.
I can copy this into the docker container using docker cp config/example.yml crawler:/app/config/example.yml
3. Validate the domain
Before crawling you can check that the configured domain is valid using docker exec -it crawler bin/crawler validate config/example.yml

4. Crawl!
Start the crawl with docker exec -it crawler bin/crawler crawl config/example.yml.

It will take a while to complete if the site is large, but you'll know it's done based on the shell output.

5. Check the content
We can then do a _search query against the index. This could also be done in Kibana Dev Tools if you have an instance of that running.
And the results!
You could even hook these results up with Semantic Search and do some cool real-language queries, like What park is in the centre of Australia?. You just need to add the name of the pipeline you create to the Crawler config yaml file, under the field elasticsearch.pipeline.
Feature comparison breakdown
Here is a full list of Elastic Crawler features as of v8.13, and when we intend to add them to the Open Crawler. Features available in tech-preview are available already.
These aren't tied to any specific stack version, but we have a general time we're aiming for each release.
- tech-preview: Today (June 2024)
- beta: Autumn 2024
- GA: Summer 2025
| Feature | Open Crawler | Elastic Crawler |
|---|---|---|
| Index content into Elasticsearch | tech-preview | ✔ |
| No index name restrictions | tech-preview | ✖ |
| Run anywhere, without Enterprise Search or Kibana | tech-preview | ✖ |
| Bulk index results | tech-preview | ✖ |
| Ingest pipelines | tech-preview | ✔ |
| Seed URLs | tech-preview | ✔ |
| robots.txt and sitemap.xml adherence | tech-preview | ✔ |
| Crawl through proxy | tech-preview | ✔ |
| Crawl sites with authorization | tech-preview | ✔ |
| Data attributes for inclusion/exclusion | tech-preview | ✔ |
| Limit crawl depth | tech-preview | ✔ |
| Robots meta tags | tech-preview | ✔ |
| Canonical URL link tags | tech-preview | ✔ |
| No-follow links | tech-preview | ✔ |
| CSS selectors | beta | ✔ |
| XPath selectors | beta | ✔ |
| Custom data attributes | beta | ✔ |
| Binary content extraction | beta | ✔ |
| URL pattern extraction (extraction directly from URLs using regex) | beta | ✔ |
| URL filters (extraction rules for specific endpoints) | beta | ✔ |
| Purge crawls | beta | ✔ |
| Crawler results history and metadata | GA | ✔ |
| Duplicate content handling | TBD | ✔ |
| Schedule crawls | TBD | ✔ |
| Manage crawler through Kibana UI | TBD | ✔ |
The TBD features are still undecided as we are assessing the future of the Open Crawler. Some of these, like Schedule crawls, can be done already using cron jobs or similar automation. Depending on user feedback and how the Open Crawler project evolves, we may decide to implement these features properly in a later release. If you have a need for one of these, reach out to us! You can find us in the forums and in the community Slack, or you can create an issue directly in the repository.
What's next?
We want to get this to GA in time for v9.0. The Open Crawler is designed with Elastic Cloud Serverless in mind, and we intend for it to be the main web content ingestion method for that version.
We also have plans to support the Elastic Data Extraction Service, so even larger binary content files can be ingested using Open Crawler.
There are many features we need to introduce in the meantime to get the same feature-rich experience that Elastic Crawler has today.
Frequently Asked Questions
What is Elastic's Open Crawler?
Open Crawler allows users to crawl web content and index it into Elasticsearch from wherever they like.
Related Content

December 16, 2025
Reducing Elasticsearch frozen tier costs with Deepfreeze S3 Glacier archival
Learn how to leverage Deepfreeze in Elasticsearch to automate searchable snapshot repository rotation, retaining historical data and aging it into lower cost S3 Glacier tiers after index deletion.

September 22, 2025
Elastic Open Web Crawler as a code
Learn how to use GitHub Actions to manage Elastic Open Crawler configurations, so every time we push changes to the repository, the changes are automatically applied to the deployed instance of the crawler.

August 6, 2025
How to display fields of an Elasticsearch index
Learn how to display fields of an Elasticsearch index using the _mapping and _search APIs, sub-fields, synthetic _source, and runtime fields.

July 14, 2025
Run Elastic Open Crawler in Windows with Docker
Learn how to use Docker to get Open Crawler working in a Windows environment.

June 24, 2025
Ruby scripting in Logstash
Learn about the Logstash Ruby filter plugin for advanced data transformation in your Logstash pipeline.