Elasticsearch allows you to index data quickly and in a flexible manner. Try it free in the cloud or run it locally to see how easy indexing can be.
We have released version 0.2 of Open Crawler, which has also been promoted to beta!
Open Crawler was initially released (version 0.1) in June 2024 as a tech-preview. Since then, we've been iterating on the product and have added several new features.
To get access to these changes you can use the latest Docker artifact, or download the source code directly from the GitHub repository. Follow the setup instructions in our documentation to get started.
What's new in the Open Crawler?
A list of every change can be found in our changelog in the Open Crawler repository. In this blog we will go over only new features, and configuration format changes
Open Crawler features
| Feature | Description |
|---|---|
| Extraction rules | Allows for the extraction of HTML content using CSS and XPath selectors, and URL content using regex. |
| Binary content extraction | Allows for the extraction of binary content from file types supported by the Apache Tika project. |
| Crawl rules | Used to enable or disable certain URL patterns from being crawled and ingested. |
| Purge crawls | Deletes outdated documents from the index at the end of a crawl job. |
| Scheduling | Recurrent crawls can be scheduled based on a cron expression. |
Configuration changes in the Open Crawler
Among the new features, the config.yml file format has changed for a few fields, so existing configuration files will not work between 0.1 and 0.2. Notably, the configuration field domain_allowlist has been changed to domains, and seed_urls is now a subset of domains instead of a top-level field. This change was made so new features like extraction rules and crawl rules could be applied to specific domains, while allowing a single crawler to configure multiple domains for a crawl job.
Make sure to reference the updated config.yml.example file to fix your configuration. Here is an example for migrating a 0.1 configuration to 0.2:
Showcase 1: crawl rules
We're very excited to bring the crawl rules feature to Open Crawler. This is an existing feature in the Elastic Crawler. The biggest difference for crawl rules between Open Crawler and Elastic Crawler is the way these rules are configured. Elastic Crawler is configured using Kibana, while Open Crawler has crawl rules defined for a domain in the crawler.yml config file.
Crawling only specific endpoints
When determining if a URL is crawlable, Open Crawler will execute crawl rules in order from top to bottom.
In this example below, we want to crawl only the content of https://www.elastic.co/search-labs. Because this has links to other URLs within the https://www.elastic.co domain, it's not enough to limit just the seed_urls to this entry point. Using crawl rules, we need two more rules:
- An allow rule for everything under (and including) the
/search-labsURL pattern - A deny everything rule to catch all other URLs
In this example we are using a regex pattern for the deny rule.
If I want to add another URL to ingest to this configuration (for example, /security-labs), I need to:
- Add it as a
seed_url - Add it to the
crawl_rulesabove the deny all rule
Through this manner of configuration, you can be very specific about what webpages Crawler will ingest.
If you have debug logs enabled, each denied URL will show up in the logs like this:
Here's an actual example from my crawl results:
Crawling everything except a specific endpoint
This pattern is much easier to implement, as Crawler will crawl everything by default. All that is needed is to add a deny rule for URL pattern that you want to exclude.
In this example, I want to crawl the entire https://www.elastic.co website, except for anything under /search-labs. Because I want to crawl everything, seed_urls is not needed for this configuration.
Now if I run a crawl, Crawler will not ingest webpages with URLs that begins with /search-labs.
Showcase 2: extraction rules
Extraction rules are another much-asked-for feature for Open Crawler. Like crawl rules, extraction rules function almost the same as they do for Elastic Crawler, except for how they are configured. Extraction rules are configured under extraction_rulesets, which belong to a single item from domains.
Getting the CSS selector
For this example, I want to extract the authors' names for each blog article in /search-labs and assign it to the field authors. Without extraction rules, each blog's Elasticsearch document will have the author names buried in the body field.
Using my browser developer tools (in my case, the Firefox dev tools), I can visit the webpage and use the selector tool to find what CSS selectors an HTML element has. I can now see that the authors are stored in a <p> element with a few different classes, but most eye-catching is the class .author-name.

Now, to test that using the selector .author-name is enough to fetch only the author name from this field, I can use the dev tools HTML search feature. Unfortunately, I can see that using only this class name returns 11 results for this blog post.

After some investigation, I found that this is because the "Recommended articles" section at the bottom of a page also uses the .author-name class. To remedy this, we need a more restrictive selector.
Examining the HTML code directly, I can see that the side-bar containing the author name that I want to extract is nested a few levels under a class called .sticky. This class refers to the sidebar that contains the author name I want to extract.

We can combine these selectors into a single selector .sticky .author-name that will only search for .author-name classes that are nested within .sticky classes. We can then test this in the same HTML search bar as before, and ta-da!

Only one hit -- we've found our CSS selector!
Configuring the extraction rules
Now we can add the CSS selector from the previous step.
We also need to define the url_filters for this rule. This will determine which endpoints the extraction rule is executed against. All articles for search labs fall under the format https://www.elastic.co/search-labs/blog/<slug>, so this can be achieved with a simple regex pattern: /search-labs/blog/.+$.
/search-labs/blog/asserts the start of the URL.+matches any character except line breaks$marks the end of the string- This stops sub-URLs like
https://www.elastic.co/search-labs/blog/<slug>/<something-else>from having this extraction rule
- This stops sub-URLs like
In this example we will also utilize crawl rules, to avoid crawling the entire https://www.elastic.co website.
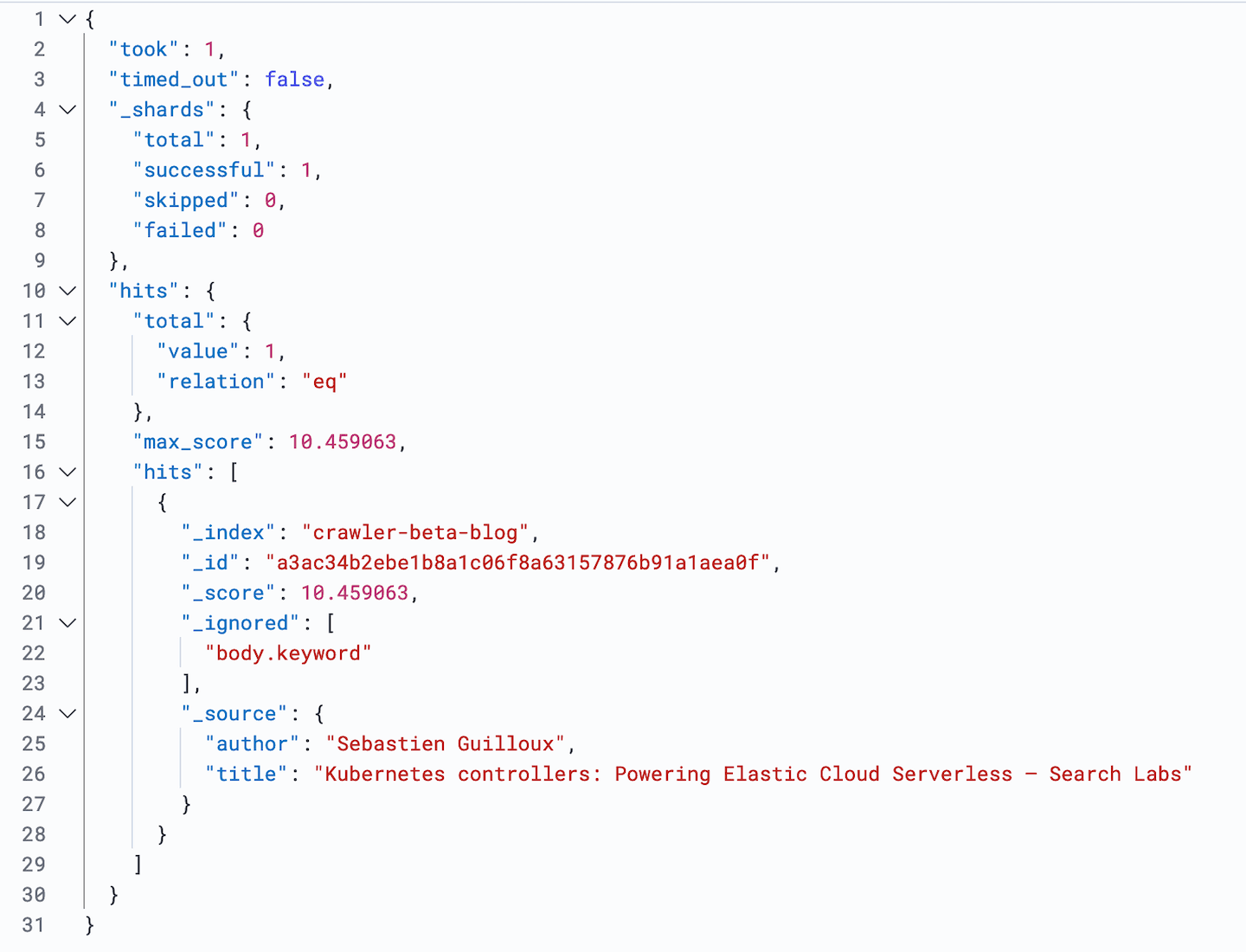
After completing a crawl with the above configuration, I can check for the new author field in the ingested documents.
I can do this using a _search query to find articles written by the author Sebastien Guilloux.
And we have a single hit!
Showcase 3: combining it all with Semantic Text
Jeff Vestal wrote a fantastic article combining Open Crawler with Semantic Text search, among other cool RAG things. Read up on that here.
Comparing with Elastic Crawler
We now maintain a feature comparison table on the Open Crawler repository to compare the features available for Open Crawler vs Elastic Crawler.
Open Crawler next steps
The next release will bring Open Crawler to version 1.0, and will also promote it to GA (generally available). We don't have a release date planned for this version yet. We do have a general idea of some features we want to include:
- Extraction using data attributes and meta tags
- Full HTML extraction
- Send event logs to Elasticsearch
This list is not exhaustive, and depending on user feedback we will include other features in the 1.0 GA release. If there are other features you would like to see included, feel free to create an enhancement issue directly on the Open Crawler repository. Feedback like this will help us prioritize what to include in the next release.
Related Content

December 16, 2025
Reducing Elasticsearch frozen tier costs with Deepfreeze S3 Glacier archival
Learn how to leverage Deepfreeze in Elasticsearch to automate searchable snapshot repository rotation, retaining historical data and aging it into lower cost S3 Glacier tiers after index deletion.

September 22, 2025
Elastic Open Web Crawler as a code
Learn how to use GitHub Actions to manage Elastic Open Crawler configurations, so every time we push changes to the repository, the changes are automatically applied to the deployed instance of the crawler.

August 6, 2025
How to display fields of an Elasticsearch index
Learn how to display fields of an Elasticsearch index using the _mapping and _search APIs, sub-fields, synthetic _source, and runtime fields.

July 14, 2025
Run Elastic Open Crawler in Windows with Docker
Learn how to use Docker to get Open Crawler working in a Windows environment.

June 24, 2025
Ruby scripting in Logstash
Learn about the Logstash Ruby filter plugin for advanced data transformation in your Logstash pipeline.