Busca com IA com a privacidade em primeiro lugar e usando o LangChain e o Elasticsearch


 Share on Twitter
Share on TwitterCompartilhar no Twitter

 Share on LinkedIn
Share on LinkedInCompartilhar no LinkedIn

 Share on Facebook
Share on FacebookCompartilhar no Facebook

 Share by Email
Share by EmailCompartilhar por e-mail

 Print this page
Print this pageImprimir
Passei os últimos fins de semana no fascinante mundo da “engenharia de prompt” e aprendendo como bancos de dados vetoriais como o Elasticsearch® pode turbinar grandes modelos de linguagem (LLMs) como o ChatGPT, agindo como memória de longo prazo e um armazenamento de conhecimento semântico. No entanto, uma coisa que me incomodou (e muitos outros arquitetos de dados experientes) é que muitos dos tutoriais e demonstrações disponíveis dependem totalmente do envio dos seus dados privados a grandes empresas da web e empresas de IA baseadas na nuvem.
Os dados privados vêm em várias formas e são protegidos por mais de um motivo. Tanto para startups quanto para grandes empresas, seus dados privados às vezes são sua vantagem competitiva. Os dados internos e os dados do cliente geralmente contêm informações de identificação pessoal que, se não forem protegidas, têm consequências legais e humanas no mundo real. Nos domínios de observabilidade e segurança, a falta de cuidado ao utilizar serviços de terceiros pode ser a fonte de violações de dados. Nós até ouvimos alegações de brechas de segurança cibernética que foram associadas ao uso de ferramentas de chat de IA.
Nenhum design é isento de riscos ou totalmente privado, mesmo quando se trabalha com empresas como a Elastic, que estabeleceram fortes compromissos com a privacidade e a segurança ou se fazem implantações que estão em um verdadeiro air gap. No entanto, trabalhei com casos de uso de dados sensíveis em quantidade suficiente para saber que há um valor muito real em permitir a busca de IA com uma abordagem de privacidade em primeiro lugar. Adorei o excelente passo a passo que meu colega Jeff Vestal criou para o uso de ferramentas da OpenAI com o Elasticsearch, mas este artigo terá uma abordagem diferente.
Tenho dois objetivos para a abordagem deste projeto:
- Privado — Quando digo privado, estou falando sério. Embora eu use o Elasticsearch hospedado na nuvem, caso o caso de uso o exija, quero que funcione totalmente isolado. Vamos provar que podemos fazer a busca de IA funcionar sem enviar nosso conhecimento privado a terceiros.
- Diversão — Além disso, vamos nos divertir enquanto fazemos isso. Usaremos um scrape (raspagem de dados) da Wookieepedia, um wiki comunitário de Star Wars popular em exercícios de ciência de dados, e criaremos um auxiliar privado de curiosidades de IA. Era quase 4 de maio (o Dia de Star Wars) quando eu estava escrevendo isso e, embora já tenhamos passado dessa data no momento da publicação deste post, meu fandom dura o ano todo.
A maneira mais fácil de acompanhar e experimentar você mesmo(a) é criar uma instância do Elasticsearch no Elastic Cloud e executar por meio do caderno do Python fornecido, que implementará o projeto em pequena escala. Se você gostaria de executar o scrape completo da Wookieepedia de 180 mil parágrafos de conhecimento de Star Wars e criar uma busca de conhecimento de Star Wars bem robusta, pode seguir o código do repositório do GitHub aqui.
Quando tudo estiver pronto, deverá ficar assim:
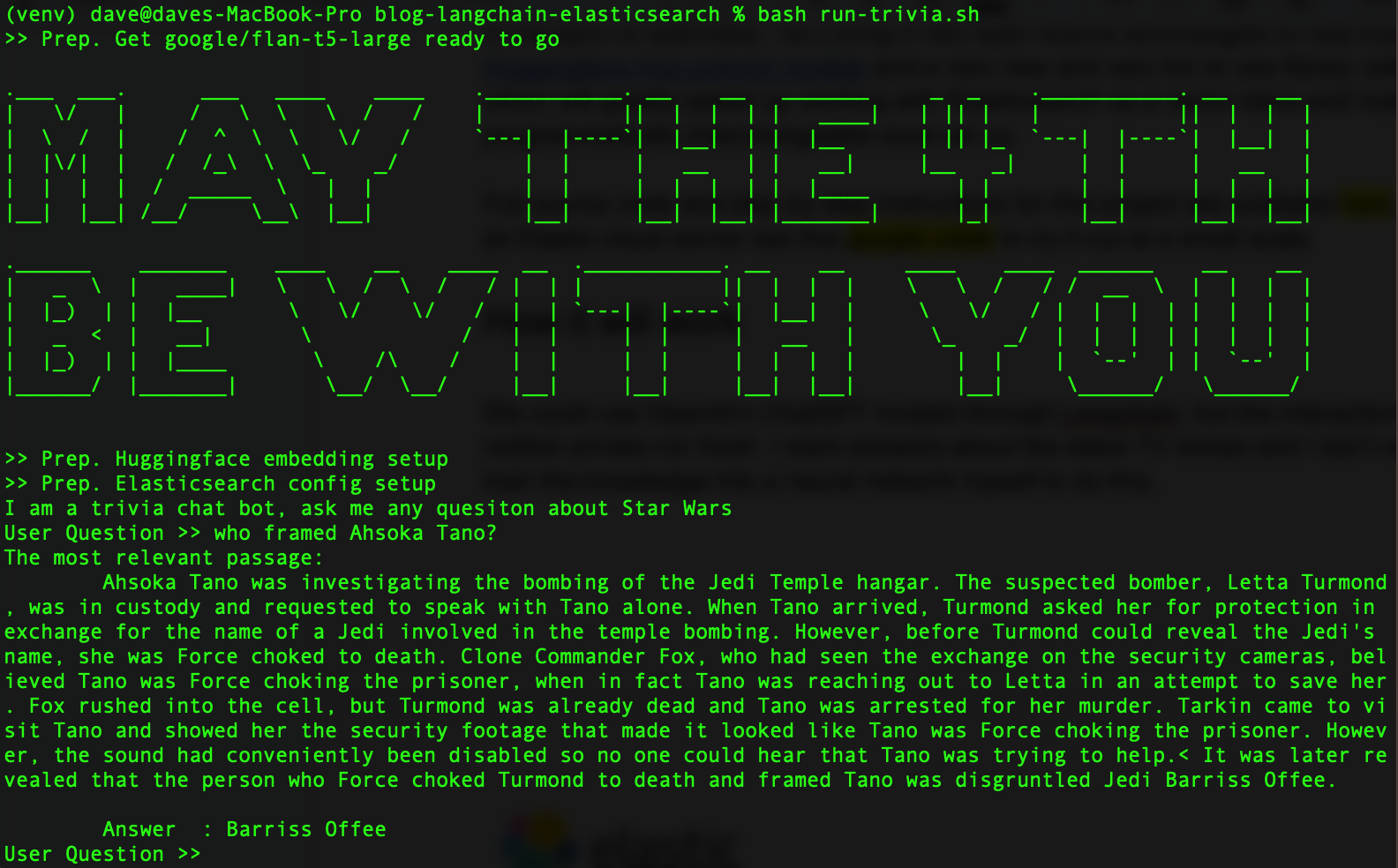
No espírito da abertura, vamos trazer duas tecnologias open source para ajudar o Elasticsearch: a biblioteca de transformadores da Hugging Face e a nova e divertida biblioteca Python chamada LangChain, que agilizarão o trabalho com o Elasticsearch como um banco de dados vetorial. Como um bônus, o LangChain tornará nossos LLMs programaticamente intercambiáveis assim que forem configurados, para que possamos experimentar vários modelos.
Como vai funcionar
O que é o LangChain? O LangChain é um framework Python e JavaScript para o desenvolvimento de aplicações alimentadas por grandes modelos de linguagem. O LangChain funcionará com as APIs da OpenAI, mas também é excelente em abstrair as diferenças entre bancos de dados e ferramentas de IA.
Por si só, o ChatGPT não é ruim em curiosidades de Star Wars. No entanto, seu conjunto de dados de treinamento já tem vários anos e queremos respostas sobre os últimos programas de TV e eventos no universo Star Wars. Lembre-se também de que estamos fingindo que esses dados são privados demais para serem compartilhados com um grande LLM na nuvem. Poderíamos ajustar um grande modelo de linguagem nós mesmos com dados mais recentes, mas há uma maneira muito mais fácil de fazer isso que também nos permite usar sempre os dados mais recentes disponíveis.
Hoje vamos trazer um LLM menor e fácil de auto-hospedar. Eu tive bons resultados com o modelo flan-t5-large do Google, que compensa sua falta de treinamento com uma boa capacidade de analisar as respostas do contexto injetado. Usaremos a busca semântica para recuperar nosso conhecimento privado e, em seguida, injetar esse contexto com uma pergunta ao nosso LLM privado.
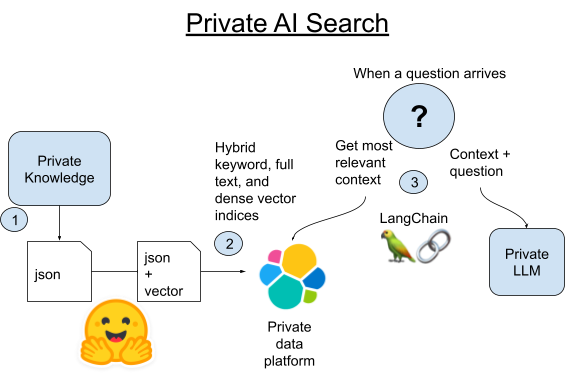
1. Raspe todos os artigos canônicos da Wookieepedia colocando os dados em arquivos Pickle do Python preparados.
2A. Carregue cada parágrafo desses artigos no Elasticsearch usando a biblioteca Vectorstore integrada do LangChain.
2B. Como alternativa, podemos comparar o LangChain com a nova maneira de hospedar transformadores pytorch no próprio Elasticsearch. Vamos implantar o modelo de embedding de texto no Elasticsearch para aproveitar a computação distribuída e acelerar o processo.
3. Quando uma pergunta chegar, encontraremos o parágrafo mais semanticamente semelhante à pergunta usando a busca vetorial do Elasticsearch. Em seguida, pegaremos esse parágrafo e o adicionaremos ao prompt de um pequeno LLM local como contexto para a pergunta e deixaremos que a magia da IA generativa obtenha uma resposta curta para nossa pergunta de curiosidades.
Configurando o ambiente do Python e do Elasticsearch
Você deverá ter o Python 3.9 ou similar na sua máquina. Eu uso o 3.9 para facilitar a compatibilidade das bibliotecas com aceleração de GPU, mas isso não será necessário para este projeto. Qualquer versão 3.X recente do Python funcionará.
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install beautifulsoup4 eland elasticsearch huggingface-hub langchain tqdm torch requests sentence_transformersSe você baixou o código de amostra, pode simplesmente extrair as versões exatas do código que eu estava usando com o comando pip install a seguir.
pip install -r requirements.txtVocê pode configurar um cluster do Elasticsearch seguindo as instruções aqui. A avaliação gratuita do Elastic Cloud é a maneira mais fácil de começar.
Crie um arquivo .env na pasta e carregue seus detalhes de conexão para o Elasticsearch.
export ES_SERVER="YOURDESSERVERNAME.es.us-central1.gcp.cloud.es.io"
export ES_USERNAME="YOUR READ WRITE AND INDEX CREATING USER"
export ES_PASSWORD="YOUR PASSWORD"Etapa 1. Raspando os dados
O repositório de código tem um pequeno conjunto de dados em Dataset/starwars_small_sample_data.pickle. Você poderá pular esta etapa se estiver trabalhando bem em pequena escala.
O código de raspagem é adaptado do excelente blog de ciência de dados de Dennis Bakhuis e de seu projeto — confira! Ele puxa apenas o primeiro parágrafo de cada artigo, e eu mudei o código para puxar tudo. Ele pode ter precisado manter os dados em um tamanho que caiba na memória principal, mas nós não temos esse problema porque temos o Elasticsearch, que nos permitiria expandir até a faixa dos petabytes.
Você também pode conectar sua própria fonte de dados privada aqui com facilidade. O LangChain tem algumas excelentes bibliotecas de utilitários para dividir seus dados de texto em pedaços mais curtos.
A raspagem não é o foco deste artigo, então confira o caderno Python se quiser executá-lo em pequena escala ou baixe o código-fonte e execute assim:
source .env
python3 step-1A-scrape-urls.py
python3 step-1B-scrape-content.py
Quando terminar, você poderá examinar os arquivos Pickle salvos como este para garantir que funcionou.
from pathlib import Path
import pickle
bookFilePath = "starwars_*_data*.pickle"
files = sorted(Path('./Dataset').glob(bookFilePath))
for fn in files:
with open(fn,'rb') as f:
part = pickle.load(f)
for key, value in part.items():
title = value['title'].strip()
print(title)Se você pulou a raspagem da web, basta alterar o bookFilePath para “starwars_small_sample_data.pickle” para usar a amostra que incluí no repositório do GitHub.
Etapa 2A. Carregando embeddings no Elasticsearch
O código completo mostra como faço isso apenas com o LangChain. A parte principal do código é percorrer os arquivos Pickle salvos como no exemplo acima, extrair uma lista de strings que sejam os parágrafos e entregá-los à função from_texts() do Vectorstore do LangChain.
from langchain.vectorstores import ElasticVectorSearch
from langchain.embeddings import HuggingFaceEmbeddings
from pathlib import Path
import pickle
import os
from tqdm import tqdm
model_name = "sentence-transformers/all-mpnet-base-v2"
hf = HuggingFaceEmbeddings(model_name=model_name)
index_name = "book_wookieepedia_mpnet"
endpoint = os.getenv('ES_SERVER', 'ERROR')
username = os.getenv('ES_USERNAME', 'ERROR')
password = os.getenv('ES_PASSWORD', 'ERROR')
url = f"https://{username}:{password}@{endpoint}:443"
db = ElasticVectorSearch(embedding=hf, elasticsearch_url=url, index_name=index_name)
batchtext = []
bookFilePath = "starwars_*_data*.pickle"
files = sorted(Path('./Dataset').glob(bookFilePath))
for fn in files:
with open(fn,'rb') as f:
part = pickle.load(f)
for ix, (key, value) in tqdm(enumerate(part.items()), total=len(part)):
paragraphs = value['paragraph']
for p in paragraphs:
batchtext.append(p)
db.from_texts(batchtext,
embedding=hf,
elasticsearch_url=url,
index_name=index_name)
Etapa 2B. Economizando tempo e dinheiro com modelos treinados hospedados
Descobri que, no meu Macbook Intel mais antigo, a criação de embeddings exigiria muitas horas de processamento. Estou sendo gentil — acho que ia levar vários dias. Acho que posso fazer isso de forma mais rápida e econômica usando os nós de machine learning (ML) dinamicamente escaláveis do serviço hospedado da Elastic. Os clusters de avaliação gratuita não permitirão que você redimensione esse nível, portanto, esta etapa pode fazer mais sentido para alguns do que para outros.
O resultado final: essa abordagem levou 40 minutos em nós que custam US$ 5/h para serem executados no Elastic Cloud, o que é muito mais rápido do que posso fazer localmente e compatível com o custo de processar os embeddings com as cobranças atuais de token da OpenAI. Fazer isso com eficiência é um tópico maior, mas estou impressionado com a rapidez com que consegui fazer um pipeline de inferência paralela funcionar no Elastic Cloud sem ter de aprender novas habilidades ou entregar meus dados a uma API não privada.
Para esta etapa, vamos deixar a geração de embeddings a cargo do próprio cluster do Elasticsearch, que pode hospedar o modelo de embedding e incorporar os parágrafos do texto de forma distribuída. Para fazermos isso, teremos de carregar os dados e usar pipelines de ingestão para garantir que a forma final corresponda ao mapeamento de índice que o LangChain usa. Execute o seguinte comando REST no Dev Tools do Kibana:
PUT /book_wookieepedia_mpnet
{
"settings": {
"number_of_shards": 4
},
"mappings": {
"properties": {
"metadata": {
"type": "object"
},
"text": {
"type": "text"
},
"vector": {
"type": "dense_vector",
"dims": 768
}
}
}
}
Em seguida, carregaremos o modelo de embedding no Elasticsearch usando a biblioteca Python do Eland.
source .env
python3 step-3A-upload-model.pyVamos para o console Elastic Cloud e redimensionaremos nosso nível de ML para 64 vCPUs no total (8x a potência do meu notebook atual).
Agora, no Kibana, implantaremos o modelo de ML treinado. Em escala, o teste de desempenho mostrou que os usuários devem começar com um thread por alocação de modelo e aumentar o número de alocações para aumentar a taxa de transferência. A documentação e as orientações podem ser encontradas aqui. Eu experimentei e, para este conjunto menor, obtive os melhores resultados com 32 instâncias em 2 threads cada. Para configurar isso, vá para Stack Management (Gerenciamento da stack) > Machine Learning. Use o recurso Synchronize saved objects (Sincronizar objetos salvos) para fazer o Kibana ver o modelo que colocamos no Elasticsearch com o código Python. Em seguida, implante o modelo no menu que aparece quando você clica nele.

Agora, vamos usar o Dev Tools novamente para criar um novo índice e um pipeline de ingestão que processa o parágrafo de texto em um documento, coloca o resultado em um campo vetorial denso chamado “vector” e copia o parágrafo para o campo “text” esperado.
PUT /book_wookieepedia_mpnet
{
"settings": {
"number_of_shards": 4
},
"mappings": {
"properties": {
"metadata": {
"type": "object"
},
"text": {
"type": "text"
},
"vector": {
"type": "dense_vector",
"dims": 768
}
}
}
}
PUT _ingest/pipeline/sw-embeddings
{
"description": "Text embedding pipeline",
"processors": [
{
"inference": {
"model_id": "sentence-transformers__all-mpnet-base-v2",
"target_field": "text_embedding",
"field_map": {
"text": "text_field"
}
}
},
{
"set":{
"field": "vector",
"copy_from": "text_embedding.predicted_value"
}
},
{
"remove": {
"field": "text_embedding"
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
Teste o pipeline para verificar se está funcionando.
POST _ingest/pipeline/sw-embeddings/_simulate
{
"docs": [
{
"_source": {
"text": "Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.",
"metadata": {
"a": "b"
}
}
}
]
}
Agora estamos prontos para carregar dados em lote usando a biblioteca Python normal para o Elasticsearch, voltando-nos para nosso pipeline de ingestão para criar corretamente o embedding vetorial e transformar nossos dados para corresponder às expectativas do LangChain.
source .env
python3 step-3B-batch-hosted-vectorize.pySucesso! Os dados são cerca de 13 milhões de tokens em termos da OpenAI, portanto, gerar esses vetores em um serviço de nuvem da OpenAI ou equivalente custaria cerca de US$ 5,40. Usando o Elastic Cloud, levou 40 minutos para máquinas que custam US$ 5/hora.
Com os dados carregados, lembre-se de redimensionar seu ML do Elastic Cloud de volta para zero ou algo mais razoável usando o console de nuvem.
Etapa 3. Vença no jogo de curiosidades de Star Wars
Agora vamos brincar com o LLM e o LangChain. Eu criei um arquivo de biblioteca lib_llm.py para conter este código.
from langchain import PromptTemplate, HuggingFaceHub, LLMChain
from langchain.llms import HuggingFacePipeline
from transformers import AutoTokenizer, pipeline, AutoModelForSeq2SeqLM
from langchain.vectorstores import ElasticVectorSearch
from langchain.embeddings import HuggingFaceEmbeddings
import os
cache_dir = "./cache"
def getFlanLarge():
model_id = 'google/flan-t5-large'
print(f">> Prep. Get {model_id} ready to go")
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(model_id, cache_dir=cache_dir)
pipe = pipeline(
"text2text-generation",
model=model,
tokenizer=tokenizer,
max_length=100
)
llm = HuggingFacePipeline(pipeline=pipe)
return llm
local_llm = getFlanLarge()
def make_the_llm():
template_informed = """
I am a helpful AI that answers questions.
When I don't know the answer I say I don't know.
I know context: {context}
when asked: {question}
my response using only information in the context is: """
prompt_informed = PromptTemplate(
template=template_informed,
input_variables=["context", "question"])
return LLMChain(prompt=prompt_informed, llm=local_llm)
## continued below
O template_informed é a parte crítica (mas também fácil de entender) disso. O que estamos fazendo é formatar um modelo de prompt, que receberá nossos dois parâmetros: o contexto e a pergunta do usuário.
Com este código principal final continuado do código acima, temos o seguinte:
## continued from above
topic = "Star Wars"
index_name = "book_wookieepedia_mpnet"
# Create the HuggingFace Transformer like before
model_name = "sentence-transformers/all-mpnet-base-v2"
hf = HuggingFaceEmbeddings(model_name=model_name)
## Elasticsearch as a vector db, just like before
endpoint = os.getenv('ES_SERVER', 'ERROR')
username = os.getenv('ES_USERNAME', 'ERROR')
password = os.getenv('ES_PASSWORD', 'ERROR')
url = f"https://{username}:{password}@{endpoint}:443"
db = ElasticVectorSearch(embedding=hf, elasticsearch_url=url, index_name=index_name)
## set up the conversational LLM
llm_chain_informed= make_the_llm()
def ask_a_question(question):
## get the relevant chunk from Elasticsearch for a question
similar_docs = db.similarity_search(question)
print(f'The most relevant passage: \n\t{similar_docs[0].page_content}')
informed_context= similar_docs[0].page_content
informed_response = llm_chain_informed.run(
context=informed_context,
question=question)
return informed_response
# The conversational loop
print(f'I am a trivia chat bot, ask me any question about {topic}')
while True:
command = input("User Question >> ")
response= ask_a_question(command)
print(f"\tAnswer : {response}")
Conclusão
Portanto, com algum trabalho com os dados, agora usamos a IA sem expor nossos dados a um LLM hospedado por terceiros. O mundo da IA está mudando rapidamente, mas preservar a segurança e o controle dos dados privados é algo que todos devemos levar a sério devido às consequências regulatórias, financeiras e humanas das violações de dados. É improvável que isso mude. Trabalhamos com clientes que usam a busca para investigar fraudes, defender sua nação e melhorar os resultados para comunidades de pacientes vulneráveis. A privacidade é importante. Para saber mais sobre como o Elastic é utilizado nesses espaços, confira:
Você se apaixonou pelo LangChain tanto quanto eu? Como um velho e sábio Jedi disse uma vez: “Isso é bom. Você deu seu primeiro passo para um mundo maior.” Há muitas direções a seguir a partir daqui. O LangChain elimina a complexidade de trabalhar com a engenharia de prompt de IA. Sei que o Elasticsearch tem muitos outros papéis a desempenhar aqui como memória de longo prazo para IA generativa, por isso estou muito animado para ver o que sairá desse espaço em rápida mudança.
Neste post do blog, podemos ter usado ferramentas de IA generativa de terceiros, que pertencem a seus respectivos proprietários e são operadas por eles. A Elastic não tem nenhum controle sobre as ferramentas de terceiros e não temos nenhuma responsabilidade por seu conteúdo, operação ou uso, nem por qualquer perda ou dano que possa surgir do uso de tais ferramentas. Tenha cuidado ao usar ferramentas de IA com informações pessoais, sensíveis ou confidenciais. Os dados que você enviar poderão ser usados para treinamento de IA ou outros fins. Não há garantia de que as informações fornecidas serão mantidas em segurança ou em confidencialidade. Você deve se familiarizar com as práticas de privacidade e os termos de uso de qualquer ferramenta de IA generativa antes de usá-la.
Elastic, Elasticsearch e marcas associadas são marcas comerciais, logotipos ou marcas registradas da Elasticsearch N.V. nos Estados Unidos e em outros países. Todos os outros nomes de empresas e produtos são marcas comerciais, logotipos ou marcas registradas de seus respectivos proprietários.
Compartilhar
- Share on Twitter
Compartilhar no Twitter
- Share on LinkedIn
Compartilhar no LinkedIn
- Share on Facebook
Compartilhar no Facebook
- Share by Email
Compartilhar por e-mail
- Print this page
Imprimir

