Apresentamos os snapshots buscáveis do Elasticsearch
Na versão 7.10, temos a imensa satisfação de lançar a versão beta dos snapshots buscáveis, um recurso que transforma a maneira como você pode usar sua escolha de armazenamento de objetos (como AWS S3, Microsoft Azure Storage, Google Cloud Storage ou equivalente) para tomar melhores decisões entre reduzir drasticamente os custos de armazenamento ou ingerir e reter mais dados no Elastic Stack, tudo com a busca de alto desempenho que você já conhece. Embora já tivéssemos suporte para backup de dados em armazenamentos de objetos de baixo custo há muito tempo, os snapshots buscáveis agora possibilitam que você os use como uma parte ativa do armazenamento e da busca dos dados.
Usaremos snapshots buscáveis em duas novas camadas de dados: a camada cold, que também está em beta na versão 7.10, e uma camada frozen futura. Faz muito tempo que oferecemos suporte para várias camadas de dados na gestão do ciclo de vida dos dados, sendo a hot para alta velocidade e a warm com custo e desempenho mais baixos. A nova camada cold, com a tecnologia dos snapshots buscáveis, pode reduzir seus custos de armazenamento em até 50%, aumentando a densidade de armazenamento local dos seus dados somente leitura ao deixar a cópia redundante dos dados em um armazenamento de objetos de baixo custo. A camada frozen, atualmente em desenvolvimento, dará um passo adiante e armazenará os dados exclusivamente no armazenamento de objetos de baixo custo, preservando sua capacidade de serem totalmente buscáveis, com cache local para consultas rápidas em dados acessados com frequência. E, como todos os recursos que criamos, existem APIs para controlar diretamente como os snapshots buscáveis carregam, gerenciam e buscam dados do seu armazenamento de objetos. Com esses novos recursos, o gerenciamento dos seus volumes crescentes de dados na Elastic ficará mais fácil e econômico. Assim, você poderá atender aos seus requisitos de retenção de dados de maneira econômica e, ao mesmo tempo, abrir novos casos de uso, como dar à sua equipe capacidade retroativa ilimitada para investigações de segurança ou comparações de desempenho ano a ano na Black Friday.
Uma jornada em evolução
Os dados de série temporal estão em toda parte. São logs, métricas, traces, eventos de segurança. Trata-se da espinha dorsal dos casos de uso de segurança e observabilidade e muito mais. Temos trabalhado continuamente para que o gerenciamento e o dimensionamento desses dados ao longo do tempo sejam mais fáceis, rápidos e eficientes. Isso é fundamental devido à velocidade com que esses dados aumentam. Se você está coletando um terabyte de dados por dia, por exemplo, são sete terabytes por semana. Ao longo de vários anos, isso soma facilmente vários petabytes de dados. Os usuários precisam encontrar uma maneira de gerenciar esse crescimento exponencial do armazenamento e ainda ter a capacidade de fazer buscas nele.
Nossa abordagem para resolver esse problema tem sido olhar para o ciclo de vida dos dados. Quando os dados são ingeridos pela primeira vez, é provável que se façam buscas muito intensas neles. Quando você está investigando um incidente, por exemplo, precisa de acesso rápido a todos os dados relevantes para identificar e resolver o problema. Quando um invasor compromete um host ou uma aplicação, a sua capacidade de responder rapidamente geralmente determina o impacto da violação. Mas os dados também podem ser categorizados em diferentes níveis de uso, dependendo da fonte ou do tipo. Pode ser necessário manter alguns dados apenas por motivos legais ou de compliance, ou para uma busca retroativa ocasional para fins de comparação. Os usuários, portanto, precisam de diferentes níveis de armazenamento e poder de processamento para esses diferentes níveis de necessidades, seja com base no tempo de existência, na fonte de dados ou outros critérios.
Temos a missão de fornecer a você a capacidade de equilibrar custo, desempenho e recursos para atender às suas necessidades. Isso envolve investimento em todos os níveis da nossa stack, mas um pilar central de nossa abordagem são as camadas de dados para a gestão do ciclo de vida dos dados. Esse conceito não é novo e existe desde as primeiras versões do Elasticsearch. A gestão de ciclo de vida de índices (ILM) fornece algumas convenções para facilitar o gerenciamento dos dados em nós hot (máquinas rápidas com SSDs) e warm (máquinas de custo mais baixo que podem ter discos giratórios), e já temos suporte para isso no Elastic Cloud há muitos anos. A gestão de ciclo de vida de snapshots (SLM) facilita ainda mais o uso de armazenamentos de objetos de baixo custo da AWS, do Google, do Azure e de fornecedores de armazenamento local para fazer e armazenar backups. Embora esses snapshots sejam uma parte importante de muitas implantações, eles não têm sido uma parte ativa no cotidiano das camadas de dados. Por quê? Porque não era possível fazer buscas nos snapshots. No entanto, tudo isso está mudando agora com os snapshots buscáveis, que nos permitem criar camadas de dados novas e mais econômicas que aproveitam esses armazenamentos de objetos de baixo custo e dão mais utilidade aos seus backups.
Apresentamos os snapshots buscáveis
Estamos muito empolgados com os snapshots buscáveis, pois eles nos permitem usar o S3 e outros armazenamentos de objetos de maneiras totalmente novas. Além de poder continuar a usar o seu armazenamento de objetos para armazenar seus dados de backup como snapshots, agora você pode dar a ele outra utilidade, mantendo-o sempre online e disponível ao tornar seus snapshots buscáveis diretamente pelo Elasticsearch. Para construir isso e proporcionar uma boa experiência, fizemos alterações em todas as camadas dos nossos produtos — do Kibana ao Elasticsearch, até o Lucene. Na verdade, usamos nosso profundo conhecimento sobre o Lucene para otimizar o mecanismo de busca para extrair apenas os subconjuntos do índice do snapshot que sejam realmente necessários para responder à sua consulta ou carregar o seu dashboard. Os snapshots buscáveis tornam o processo de recuperação de dados dos seus índices baseados em snapshots no S3 ou outro armazenamento de objetos totalmente rápido e integrado. Além disso, eles também nos permitiram desenvolver novas camadas de dados que oferecem mais valor com um custo menor.
A camada cold
A nova camada cold, disponível em beta na versão 7.10, reduz o armazenamento do cluster em até 50% em relação à camada warm. Ela mantém o mesmo nível de confiabilidade e redundância das camadas hot e warm, com suporte total para recuperação automática de falhas de hardware em qualquer um dos seus nós. Isso torna muito mais econômico fazer perguntas sobre seus dados do tipo “Como esse pico se compara ao mês passado?” ou “Este usuário se conectou a um sistema restrito nos últimos 6 meses?”.
Como fizemos isso? Bem, nas suas camadas hot e warm, metade do disco é usada para armazenar shards de réplica. Essas cópias redundantes garantem rapidez e consistência nas consultas e fornecem resiliência em caso de falha de uma máquina. Se isso acontecer, uma réplica assumirá como principal, e a indexação e as buscas continuarão inabaláveis.
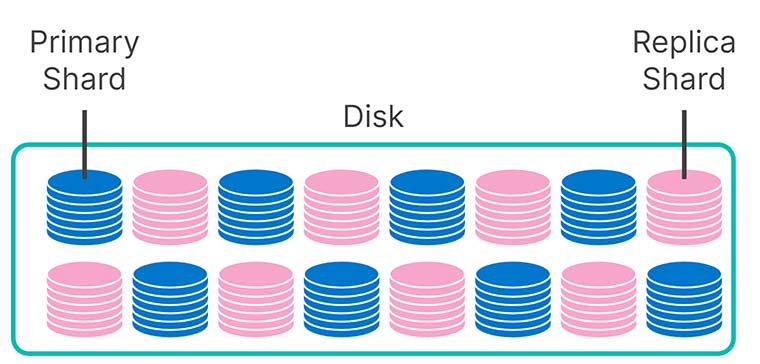
Mas quando seus dados se tornam somente leitura, a redundância pode ser facilmente descartada. Seu repositório de snapshots é perfeito para isso, já que é muito mais barato armazenar dados no S3 do que em SSDs ou discos giratórios locais. Portanto, na camada cold, seus shards de réplica são armazenados no S3 como snapshots. Como resultado, dobramos a capacidade utilizável dos seus nós cold pelo mesmo custo de antes, com impacto modesto no desempenho da consulta.
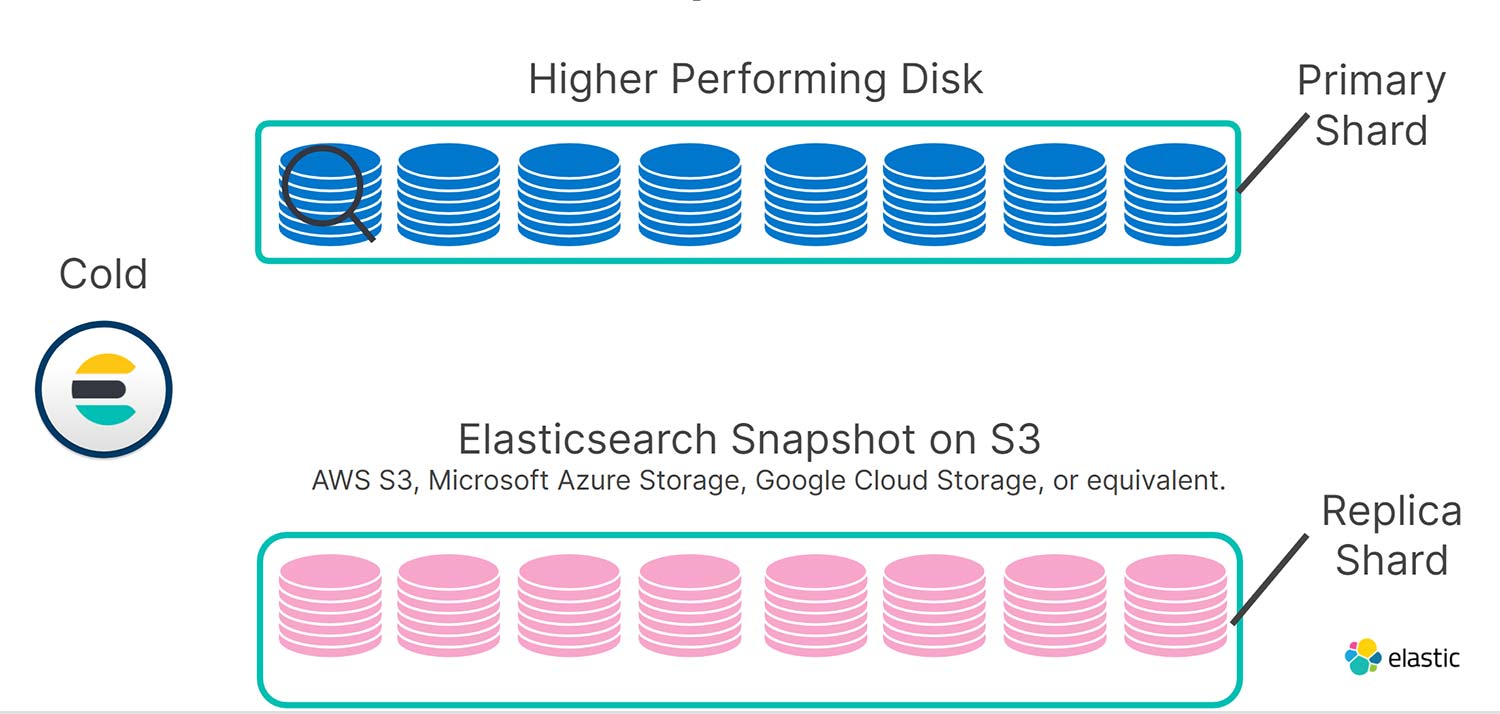
Se há uma falha em um nó local ou disco na camada cold, usamos os snapshots buscáveis para fazer a recuperação automaticamente por meio dos índices de réplica armazenados como snapshots no S3, disponibilizando-os para atender às solicitações de busca em uma fração do tempo necessário para fazer um restauração de snapshot normal. É assim que tudo se junta.
A camada frozen
Imagine que você tivesse capacidade retrospectiva ilimitada nas suas investigações de segurança ou pudesse analisar os dados brutos do APM para ver como o comportamento dos seus clientes mudou nos últimos dois anos. É aí que entra a camada frozen, abrindo possibilidades de casos de uso inteiramente novos com tipos e volumes de dados que anteriormente não eram econômicos para usar com o Elasticsearch. Pense em como o conceito de S3 buscável pode ser poderoso para os seus objetivos de negócios. Em desenvolvimento ativamente agora, a camada frozen permitirá que você faça buscas diretamente nos dados armazenados no S3 ou no armazenamento de objetos de sua escolha. Com a camada frozen, não haverá necessidade de armazenar nenhum dos seus dados localmente — tudo poderá ser armazenado apenas como snapshots no S3. E veja uma coisa interessante sobre a camada frozen: não há necessidade de extrair seus dados frozen e restaurá-los caso você precise acessá-los para uma auditoria ou investigação de segurança. Você pode simplesmente executar suas consultas diretamente nos snapshots buscáveis.
Com a camada frozen, ofereceremos algo sem precedentes: a capacidade de fazer buscas em uma quantidade quase ilimitada de dados, sob demanda, com custos próximos ao custo de armazenamento desses dados no S3. O ciclo de vida totalmente automatizado dos seus dados torna-se completo — de hot para warm, cold e depois frozen, tudo garantindo que você tenha o acesso e o desempenho na busca necessário, com o menor custo de armazenamento possível.
Otimização para a melhor experiência do usuário
Liberar novos recursos inovadores é uma coisa, e sempre nos esforçamos para fazer isso por você. O outro elemento-chave para isso é garantir que tudo o mais funcione bem em harmonia com esses novos recursos para oferecer a você a melhor experiência do usuário possível.
- Configuração simplificada da camada de dados: simplificamos e agilizamos muito a maneira como você configura suas camadas de dados e suas políticas de ILM com novas funções atribuídas a seus nós de dados, que são usadas pelo Elastic Stack para alocar automaticamente seus dados à camada apropriada na gestão de ciclo de vida de índices.
- Busca assíncrona: embora tenhamos feito todo o possível para tornar a busca no S3 mais rápida, não fazemos mágica. É fato que as consultas no S3 levarão mais do que milissegundos. E, quando isso acontece, queremos fornecer a melhor experiência possível ao usuário. Por isso, desenvolvemos um mecanismo de busca assíncrona no Elasticsearch que aprimora significativamente a experiência no Kibana em consultas de longa execução. Agora você pode executar uma solicitação de busca de forma assíncrona sem ter de esperar os resultados. Em vez disso, você pode monitorar o andamento da solicitação e recuperar os resultados em um estágio posterior. Você poderá até recuperar resultados parciais à medida que se tornarem disponíveis antes que a busca seja concluída.
- Eficiência da consulta: introduzimos uma série de melhorias para não fazer buscas em índices sem correspondência ou que não sejam necessários. Por exemplo, os índices que sabemos que não terão correspondências são automaticamente ignorados pela pré-filtragem com base no tempo ou em outras propriedades dos dados. As buscas também são encerradas mais cedo sempre que possível, usando block-max WAND para busca de texto e consultas ordenadas para ordenar os shards que buscamos, interrompendo a busca quando temos correspondências suficientes e assim por diante.
Cada aprimoramento oferece valor por si só, mas o todo é muito maior do que a soma de suas partes. Estamos pensando sempre no panorama geral enquanto desenvolvemos os recursos e integrando-os perfeitamente a todos os recursos já disponíveis no Elastic Stack.
Resolução de casos de uso e nossas soluções
Imagine as vantagens que você poderia ter se pudesse fazer buscas em anos de logs, métricas e traces de APM de maneira fácil e econômica com snapshots buscáveis em armazenamentos de objetos como o S3. Diga adeus à restauração! Com os snapshots buscáveis e o Elastic Observability, você poderá consultar diretamente anos de dados arquivados sem ter de passar pelo processo lento e caro de restaurar índices de snapshots antes de fazer uma busca.
E se você pudesse preparar caçadores de ameaças e analistas com anos de fontes de dados de segurança de alto volume em armazenamentos de objetos como o S3, facilmente acessíveis por meio de snapshots buscáveis? Com os snapshots buscáveis e o Elastic Security, você pode coletar dados de alto volume relacionados à segurança, como IDS, NetFlow, DNS, PCAP ou dados de endpoint, em maior escala e mantê-los acessíveis por mais tempo do que antes era viável, em novas camadas de dados que reduzem os custos e preservam a capacidade de busca.
Por fim, considere a possibilidade de fazer buscas em todo o conteúdo das suas aplicações e nos registros históricos do local de trabalho contidos em armazenamentos de objetos por meio de snapshots buscáveis, sem estourar o orçamento. O Elastic Enterprise Search também se beneficiará dos novos recursos dos snapshots buscáveis que estão sendo lançados no Elastic Stack. Você poderá armazenar todo o conteúdo arquivado e histórico com possibilidade de busca e sem estourar o orçamento, independentemente de estar dando suporte a quantidades muito maiores de conteúdo de aplicações ou fazendo buscas em registros organizacionais históricos contidos em armazenamentos de objetos seguros como o S3.
A jornada continua
Estamos entusiasmados com os grandes passos que demos com as versões beta dos snapshots buscáveis e da camada cold no Elastic 7.10. E nosso entusiasmo continua com o que temos pela frente — uma camada frozen que virá logo depois, bem como camadas cold e frozen gerenciadas com controles deslizantes simples no Elastic Cloud para realmente simplificar o fluxo de inscrição e assinatura para os usuários. Como sempre, é uma jornada contínua para nós, e o que nos faz continuar é o valor agregado constante que oferecemos a você a cada lançamento.

Comece hoje mesmo
Para começar a usar os snapshots buscáveis e armazenar dados na camada cold, prepare um cluster no Elasticsearch Service ou instale a versão mais recente do Elastic Stack. Já tem o Elasticsearch em execução? Basta atualizar seus clusters para a versão 7.10 e experimentar. Se quiser saber mais, leia a documentação sobre camadas de dados e snapshots buscáveis.