Elastic Observability em SRE e resposta a incidentes
O caso de confiabilidade do serviço
Os serviços de software estão no centro das empresas modernas na era digital. Basta olhar para os apps no seu smartphone. Compras, serviços bancários, streaming, jogos, leitura, mensagens, compartilhamento de viagens, agendamento, busca — você escolhe. A sociedade funciona com serviços de software. O setor explodiu para atender às demandas, e as pessoas têm muitas opções para gastar seu dinheiro e atrair sua atenção. As empresas precisam competir para atrair e reter clientes, que podem trocar de serviços deslizando um dedo.
A confiabilidade do serviço é uma expectativa universal. Você espera que qualquer serviço seja rápido e funcional e, caso não seja, “desliza para a esquerda” e escolhe outro serviço que respeite o seu tempo. Houve um caso famoso no qual a Amazon perdeu cerca de 1,2 milhões de dólares por minuto durante seu tempo de inatividade no Amazon Prime Day em 2018. Mas você não precisa ser um gigante da tecnologia para defender a confiabilidade do serviço. O tempo de inatividade e a degradação podem prejudicar a reputação de qualquer empresa muito depois da perda imediata de receita. É por isso que as empresas investem pesadamente em operações, tendo gasto cerca de 5,2 bilhões de dólares em software de DevOps em 2018.
Este post do blog explora a prática da engenharia de confiabilidade do site, o ciclo de vida de resposta a incidentes e a função do Elastic Observability na maximização da confiabilidade. O conteúdo é relevante para líderes técnicos e engenheiros que têm a responsabilidade de garantir que um serviço de software atenda às expectativas de seus usuários. No final, você deverá ter um entendimento claro e básico de como as equipes de operações executam a engenharia de confiabilidade do site e a resposta a incidentes, e como alcançam seus objetivos usando uma solução de tecnologia como o Elastic Observability.
O que é SRE?
Engenharia de confiabilidade do site (SRE) é a prática de garantir que um serviço de software atenda às expectativas de desempenho de seus usuários. Em suma, o SRE mantém os serviços confiáveis. A responsabilidade é tão antiga quanto o próprio “software como serviço”. Recentemente, os engenheiros do Google cunharam o termo “engenharia de confiabilidade do site” e codificaram seu framework no que se tornou um livro amplamente influente, intitulado Site Reliability Engineering (Engenharia de Confiabilidade do Google na versão em português). Este post do blog pega emprestado os conceitos desse livro.
Os engenheiros de confiabilidade do site (SREs) são responsáveis por atingir os objetivos de nível de serviço usando indicadores como disponibilidade, latência, qualidade e saturação. Esses tipos de variáveis influenciam diretamente a experiência do usuário de um serviço. Daí vem o caso de negócios dos SREs: um serviço satisfatório gera receita, e operações eficientes controlam custos. Para tanto, os SREs costumam ter dois trabalhos: gerenciar a resposta a incidentes para proteger a confiabilidade do serviço; e instituir soluções e práticas recomendadas com as quais as equipes de desenvolvimento e operações podem otimizar a confiabilidade do serviço e reduzir o custo do trabalho.
Os SREs costumam expressar o estado desejado dos serviços em termos de SLAs, SLOs e SLIs:
- Acordo de nível de serviço (SLA) — “O que o usuário espera?” Um SLA é uma promessa que um prestador de serviços faz a seus usuários sobre o comportamento de seu serviço. Alguns SLAs são contratuais e obrigam o prestador de serviços a compensar os clientes afetados por uma violação do SLA. Outros são implícitos e baseados no comportamento do usuário observado.
- Objetivo de nível de serviço (SLO) — “Quando tomamos medidas?” Um SLO é um limite interno acima do qual o prestador de serviços toma medidas para evitar a violação de um SLA. Por exemplo, se o prestador de serviços promete um SLA de 99% de disponibilidade, um SLO mais rígido de 99,9% de disponibilidade pode dar a ele tempo suficiente para evitar uma violação do SLA.
- Indicador de nível de serviço (SLI) — “O que mensuramos?” Um SLI é uma métrica observável que descreve o estado de um SLA ou SLO. Por exemplo, se o prestador de serviços promete um SLA de 99% de disponibilidade, uma métrica como a porcentagem de pings bem-sucedidos para o serviço pode servir como seu SLI.
Aqui estão alguns dos SLIs mais comuns monitorados pelos SREs:
- A disponibilidade mensura o tempo de funcionamento de um serviço. Os usuários esperam que um serviço responda às solicitações. Essa é uma das métricas mais básicas e importantes a serem monitoradas.
- A latência mensura o desempenho de um serviço. Os usuários esperam que um serviço responda às solicitações em tempo hábil. O que os usuários percebem como “tempo hábil” varia de acordo com o tipo de solicitação que eles enviam.
- Os erros mensuram a qualidade e a correção de um serviço. Os usuários esperam que um serviço responda às solicitações de maneira bem-sucedida. O que os usuários percebem como “bem-sucedido” varia de acordo com o tipo de solicitação que eles enviam.
- A saturação mensura a utilização de recursos dos serviços. Isso pode indicar a necessidade de ampliar os recursos para atender às demandas do serviço.
Todos que desenvolvem e operam um serviço são responsáveis por sua confiabilidade, mesmo que não tenham o cargo de engenheiro de confiabilidade do site. Tradicionalmente, isso inclui:
- A equipe de produto que comanda o serviço.
- A equipe de desenvolvimento que constrói o serviço.
- A equipe de operações que executa a infraestrutura.
- A equipe de suporte que escala incidentes dos usuários.
- A equipe disponível que resolve os incidentes.
Organizações com serviços complexos podem ter uma equipe dedicada de SREs para comandar a prática e mediar as outras equipes. Para elas, os SREs são uma ponte entre “Dev” e “Ops”. Em última análise, independentemente da implementação, a confiabilidade do site é uma responsabilidade coletiva no ciclo de DevOps.
O que é resposta a incidentes?
Resposta a incidentes, no contexto de SRE, é um esforço para trazer uma implantação de um estado indesejado de volta ao estado desejado. Os SREs entendem os estados desejados e costumam gerenciar o ciclo de vida de resposta a incidentes para manter esses estados desejados. Geralmente, o ciclo de vida envolve prevenção, descoberta e resolução, com o objetivo final de automatizar o máximo possível. Vamos explorar cada um desses elementos do ciclo de vida.
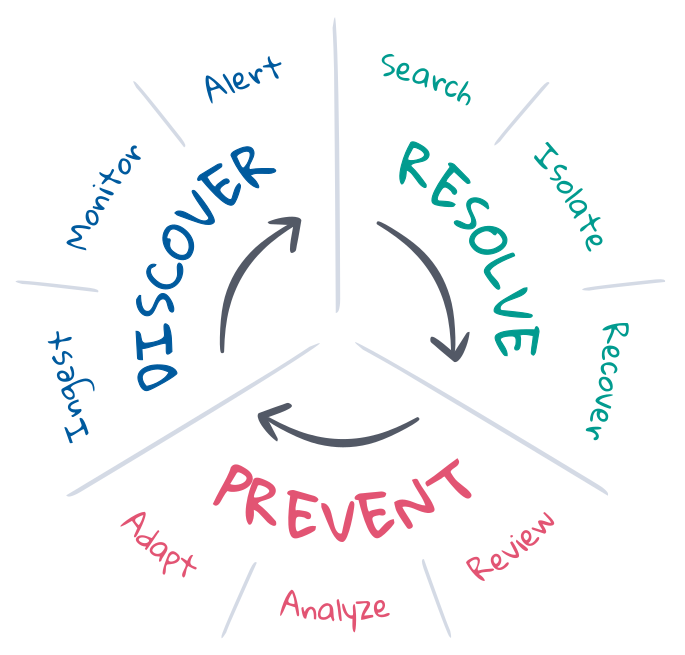
A prevenção é a primeira e a última etapa da resposta a incidentes. O ideal é que os incidentes sejam evitados com o desenvolvimento orientado por testes no pipeline de CI/CD. Mas as coisas nem sempre saem como planejado na produção. Os SREs otimizam a prevenção por meio de planejamento, automação e feedback. Antes do incidente, eles definem os critérios para o estado desejado e implementam as ferramentas necessárias para descobrir e resolver o estado indesejado. Após o incidente, fazem um postmortem para reverem o que aconteceu e discutirem como fazer a adaptação. No longo prazo, podem analisar KPIs e usar esses insights para apresentar solicitações de melhorias às equipes de produto, desenvolvimento e operações.
A descoberta consiste em saber quando um incidente pode ter ocorrido e alertar os canais certos para responder. A descoberta deve ser automatizada para maximizar a cobertura de resposta a incidentes, minimizar o tempo médio de descoberta (MTTD) e proteger os SLOs. A automação requer observabilidade contínua do estado de toda a implantação, monitoramento contínuo do estado desejado e alerta imediato caso ocorra um estado indesejado. A cobertura e a relevância da descoberta de incidentes dependem muito das definições de estado desejado, embora o machine learning possa ajudar a descobrir alterações inesperadas no estado que possam indicar ou explicar os incidentes.
A resolução consiste em trazer uma implantação de volta ao estado desejado. Alguns incidentes têm soluções automatizadas, como serviços de escalação automática quando a capacidade está quase saturada. Mas muitos incidentes requerem atenção humana, especialmente quando os sintomas não são reconhecidos ou a causa é desconhecida. A resolução requer os especialistas certos para investigar a causa raiz, isolar e reproduzir o problema para prescrever uma solução, e recuperar o estado desejado da implantação. Esse é um processo iterativo que pode passar por muitos especialistas, investigações e tentativas fracassadas. A busca e a comunicação são fundamentais para seu sucesso. As informações encurtam os ciclos, minimizam o tempo médio de resolução (MTTR) e protegem os SLOs.
A Elastic em SRE e resposta a incidentes
O Elastic Observability conduz o ciclo de vida de resposta a incidentes com observabilidade, monitoramento, alerta e busca. Este post do blog apresenta sua capacidade de fornecer observabilidade contínua do estado da implantação da stack completa, monitoramento contínuo de SLIs para violações de SLOs, alertas automatizados de violações para a equipe de resposta a incidentes e experiências de busca intuitivas que levam os respondentes a uma resolução rápida. Coletivamente, a solução minimiza o tempo médio de resolução (MTTR) para proteger a confiabilidade do serviço e a fidelidade do cliente.
Observabilidade e dados
Você não consegue resolver um problema se não consegue observá-lo. A resposta a incidentes requer visibilidade de toda a stack da implantação afetada ao longo do tempo. Mas os serviços distribuídos são repletos de complexidades, mesmo para um único evento lógico, conforme ilustrado abaixo. Cada componente da stack é uma fonte potencial de degradação ou falha para tudo o que está acontecendo. Os responsáveis pela resposta ao incidente devem considerar, se não controlar e reproduzir, o estado de cada componente durante a resolução. A complexidade é a ruína da produtividade. É impossível resolver um incidente dentro dos limites de um SLA rigoroso a menos que haja um único lugar para observar o estado de tudo ao longo do tempo.

O Elastic Common Schema (ECS) é a nossa resposta para o problema da complexidade. O ECS é uma especificação de modelo de dados open source para observabilidade. Ele padroniza as convenções de nomenclatura, os tipos de dados e os relacionamentos da infraestrutura e dos serviços distribuídos modernos. O esquema apresenta uma visão unificada de toda a stack de implantação ao longo do tempo, usando dados que tradicionalmente existiam em silos. Traces, métricas e logs em cada camada da stack coexistem nesse esquema para permitir uma experiência de busca integrada durante a resposta a incidentes.
A padronização do ECS torna possível manter a observabilidade com pouco esforço. Os agentes do APM e dos Beats da Elastic capturam automaticamente traces, métricas e logs das suas implantações, adaptam os dados ao esquema comum e enviam os dados para uma plataforma de busca central para investigação futura. As integrações com fontes de dados populares, como plataformas de nuvem, containers, sistemas e frameworks de aplicação facilitam o gerenciamento dos dados conforme suas implantações se tornam mais complexas.
Cada stack de implantação é exclusiva para seu negócio. É por isso que você pode estender o ECS para otimizar o seu fluxo de trabalho de resposta a incidentes. Os nomes de projetos de serviços e infraestrutura ajudam os respondentes a encontrar o que procuram — ou saber o que estão vendo. Os IDs de commit das aplicações ajudam os desenvolvedores a encontrar a origem das falhas conforme existiam no sistema de controle de versão no momento da compilação. Flags de recursos oferecem insights sobre o estado das implantações canário ou os resultados dos testes A/B. Qualquer coisa que ajude a descrever suas implantações, executar seus fluxos de trabalho ou cumprir seus requisitos de negócios pode ser incorporada ao esquema.
Monitoramento, alerta e ações
O Elastic Observability automatiza o ciclo de vida de resposta a incidentes monitorando, descobrindo e alertando sobre os SLIs e SLOs essenciais. A solução cobre quatro áreas de monitoramento: Uptime, APM, Metrics e Logs. O Uptime monitora a disponibilidade enviando heartbeats externos para os endpoints de serviço. O APM monitora a latência e a qualidade mensurando e capturando eventos diretamente das aplicações. O Metrics monitora a saturação mensurando a utilização dos recursos da infraestrutura. O Logs monitora a correção capturando mensagens de sistemas e serviços.
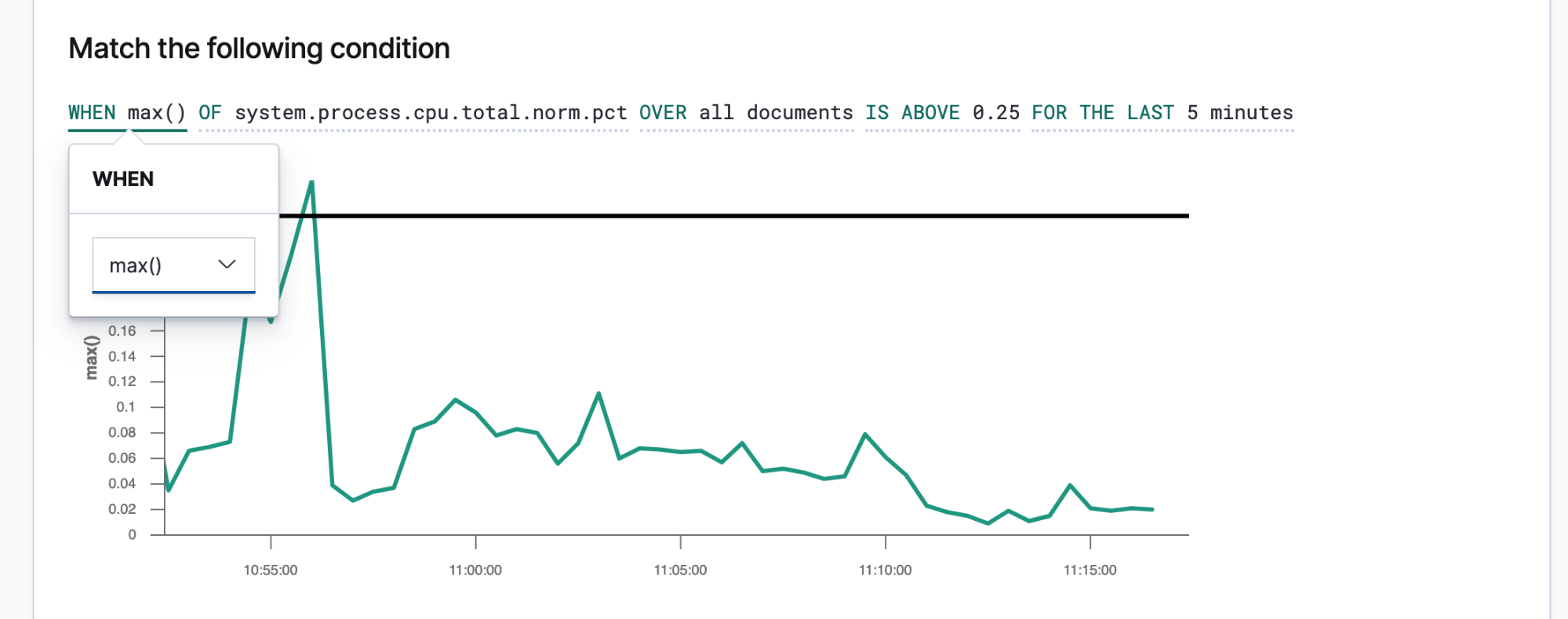
Depois de conhecer seus SLIs e SLOs, você pode defini-los como alertas e ações para compartilhar os dados certos com as pessoas certas sempre que um SLO for violado. Os alertas da Elastic são consultas programadas que disparam ações quando os resultados atendem a algumas condições. Essas condições são expressões de métricas (SLIs) e limites (SLOs). As ações são mensagens entregues a um ou mais canais, como um sistema de paging ou sistema de controle de ocorrências, para sinalizar o início de um processo de resposta a incidentes.
Alertas sucintos e práticos guiarão os respondentes em direção a uma resolução rápida. Os respondentes precisam ter informações suficientes para reproduzir o estado do ambiente e o problema observado. Você deve criar um modelo de mensagem que forneça esses detalhes aos respondentes. Aqui estão alguns detalhes a serem considerados, incluindo:
- Título — “Qual é o incidente?”
- Gravidade — “Qual é a prioridade do incidente?”
- Justificativa — “Qual é o impacto desse incidente para os negócios?”
- Estado observado — “O que aconteceu?”
- Estado desejado — “O que deveria acontecer?”
- Contexto — “Qual era o estado do ambiente?” Use os dados do alerta para descrever a hora, a nuvem, a rede, o sistema operacional, o container, o processo e qualquer outro contexto sobre o incidente.
- Links — “Para onde vou a seguir?” Use os dados do alerta para criar links que levem os respondentes a dashboards, relatórios de erros ou outros destinos úteis.
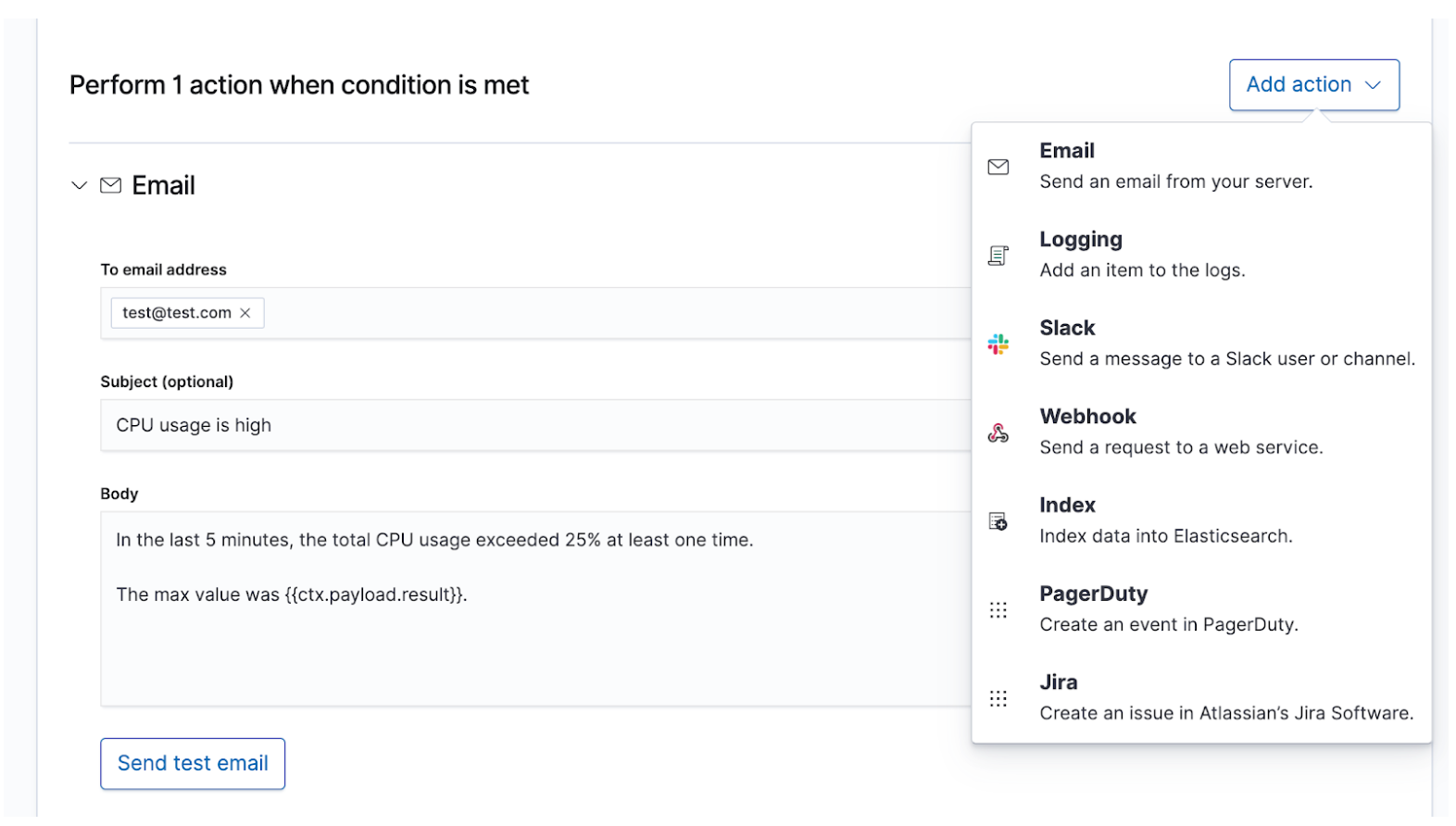
Incidentes de gravidade mais alta que requerem atenção humana imediata devem alertar a equipe de resposta a incidentes disponível por meio de canais em tempo real, como PagerDuty ou Slack. Um exemplo seria o tempo de inatividade de um serviço que requer pelo menos 99% de disponibilidade. Esse SLA permite menos de 15 minutos de tempo de inatividade por dia, o que já é menos tempo do que a equipe de resposta a incidentes pode precisar para resolver o problema. Incidentes de menor gravidade que requerem atenção humana eventual podem criar um tíquete em um sistema de controle de ocorrências como o JIRA. Um exemplo seria um aumento na latência ou nas taxas de erro para serviços que não afetam a receita diretamente. Você pode escolher alertar vários destinos de uma vez, cada um com seu próprio conteúdo de mensagem, para fins de manutenção de registros ou comunicação duplicada.
Investigação e busca
O que acontece após o envio de um alerta à equipe disponível? O caminho para a resolução varia de acordo com o incidente, mas algumas coisas são certas. Haverá pessoas com diferentes habilidades e experiências trabalhando sob pressão para resolver um problema pouco claro de forma rápida e correta, enquanto lidam com uma mangueira de incêndio de dados. Elas precisarão encontrar os sintomas relatados, reproduzir o problema, investigar a causa raiz, aplicar uma solução e ver se ela resolve o problema. Podem precisar fazer algumas tentativas. Podem descobrir que precisam explorar mais a fundo. Todo o esforço requer cafeína respostas. A informação é o que leva a resposta a incidentes da incerteza à resolução.
A resposta a incidentes é um problema de busca. A busca oferece respostas rápidas e relevantes para as perguntas. Uma boa experiência de busca é mais do que apenas “a barra de busca” — toda a interface do usuário antecipa suas perguntas e guia você para as respostas certas. Pense em sua última experiência de compras online. Conforme você navega no catálogo, a aplicação antecipa a intenção dos seus cliques e buscas para fornecer as melhores recomendações e filtros, o que influencia você a gastar mais e mais rápido. Você nunca escreve uma consulta estruturada. Talvez nem saiba o que está procurando, mas encontra rapidamente. Os mesmos princípios se aplicam à resposta a incidentes. O design da experiência de busca tem grande influência no tempo para resolver um incidente.
A busca é fundamental para ter uma resposta rápida a incidentes, não apenas porque a tecnologia é rápida, mas porque a experiência é intuitiva. Ninguém precisa aprender a sintaxe de uma linguagem de consulta. Ninguém precisa fazer referência a um esquema. Ninguém precisa ser perfeito como uma máquina. Basta buscar, e você encontrará o que procura em segundos. Você queria buscar outra coisa? A busca pode lhe dar orientação. Quer buscar por um campo específico? Comece a digitar, e a barra de busca sugerirá campos. Tem curiosidade sobre um pico em um gráfico? Clique no pico, e o resto do dashboard mostrará o que aconteceu. A busca é rápida e condescendente e, quando feita da maneira certa, dá aos responsáveis pela resposta a incidentes o poder de agir rápida e corretamente apesar de suas imperfeições humanas.
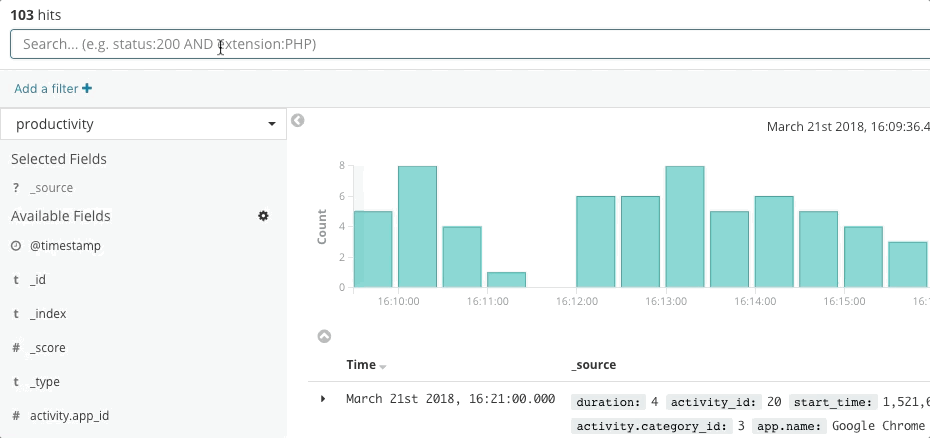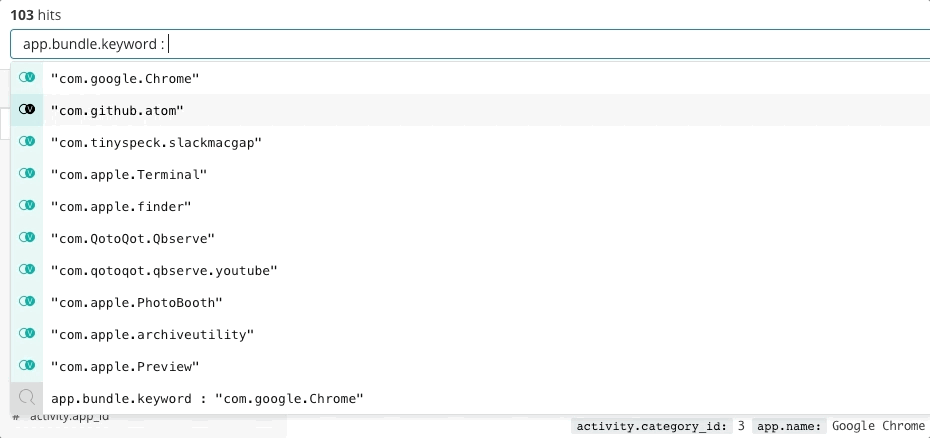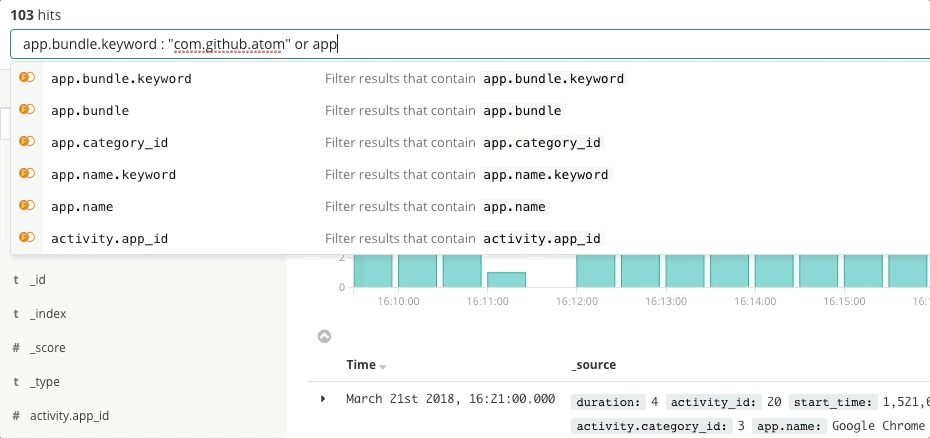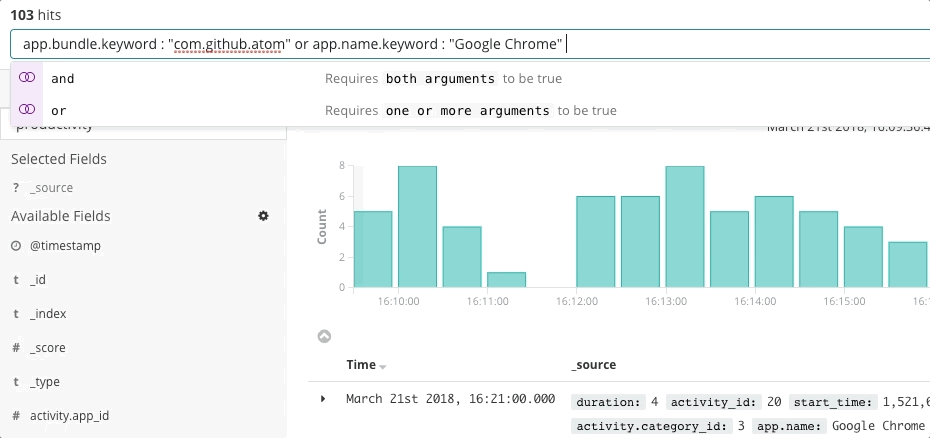
O Elastic Observability apresenta uma experiência de busca para resposta a incidentes que antecipa as perguntas, as expectativas e os objetivos dos responsáveis pela resposta a incidentes. O design oferece uma experiência familiar para cada um dos silos de dados tradicionais — Uptime, APM, Metrics, Logs — e então orienta os respondentes nessas experiências para ver a stack completa da implantação. Isso é possível porque os próprios dados existem em um esquema comum, não em silos. Efetivamente, o design responde às perguntas iniciais de disponibilidade, latência, erros e saturação e, em seguida, navega até a causa raiz usando a experiência certa para ele.
Vamos examinar alguns exemplos dessa experiência.
O Elastic Uptime responde às perguntas básicas sobre a disponibilidade do serviço, como “Quais serviços estão inativos? Quando um serviço caiu? O agente de monitoramento de tempo de funcionamento estava inativo?” Alertas de SLOs de disponibilidade podem levar o responsável pela resposta ao incidente a esta página. Depois de encontrar os sintomas de um serviço indisponível, o respondente pode seguir links para explorar os traces, as métricas ou os logs do serviço afetado e sua infraestrutura de implantação no momento da falha. Conforme o respondente navega, o contexto da investigação permanece filtrado no serviço afetado. Isso ajuda a detalhar a causa raiz do tempo de inatividade desse serviço.
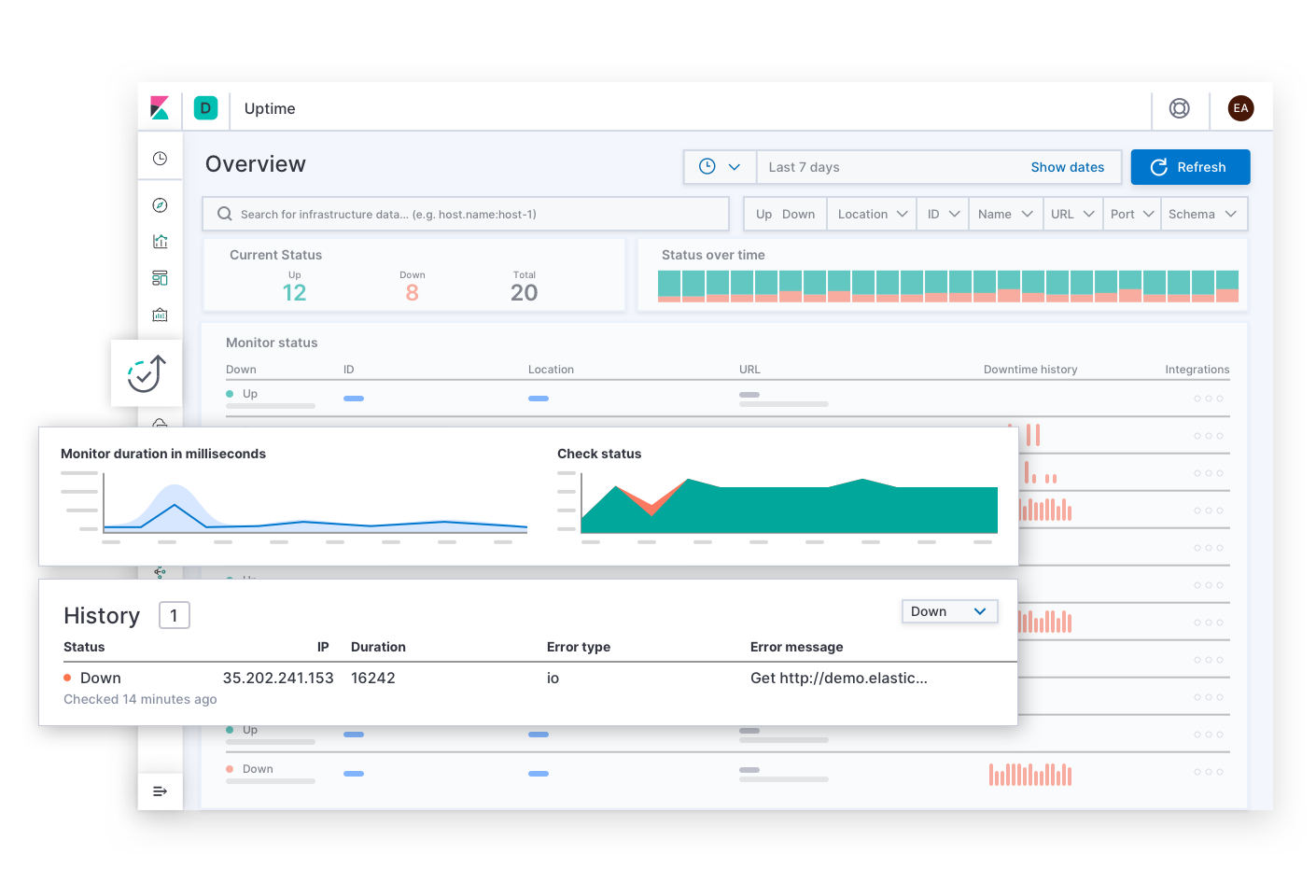
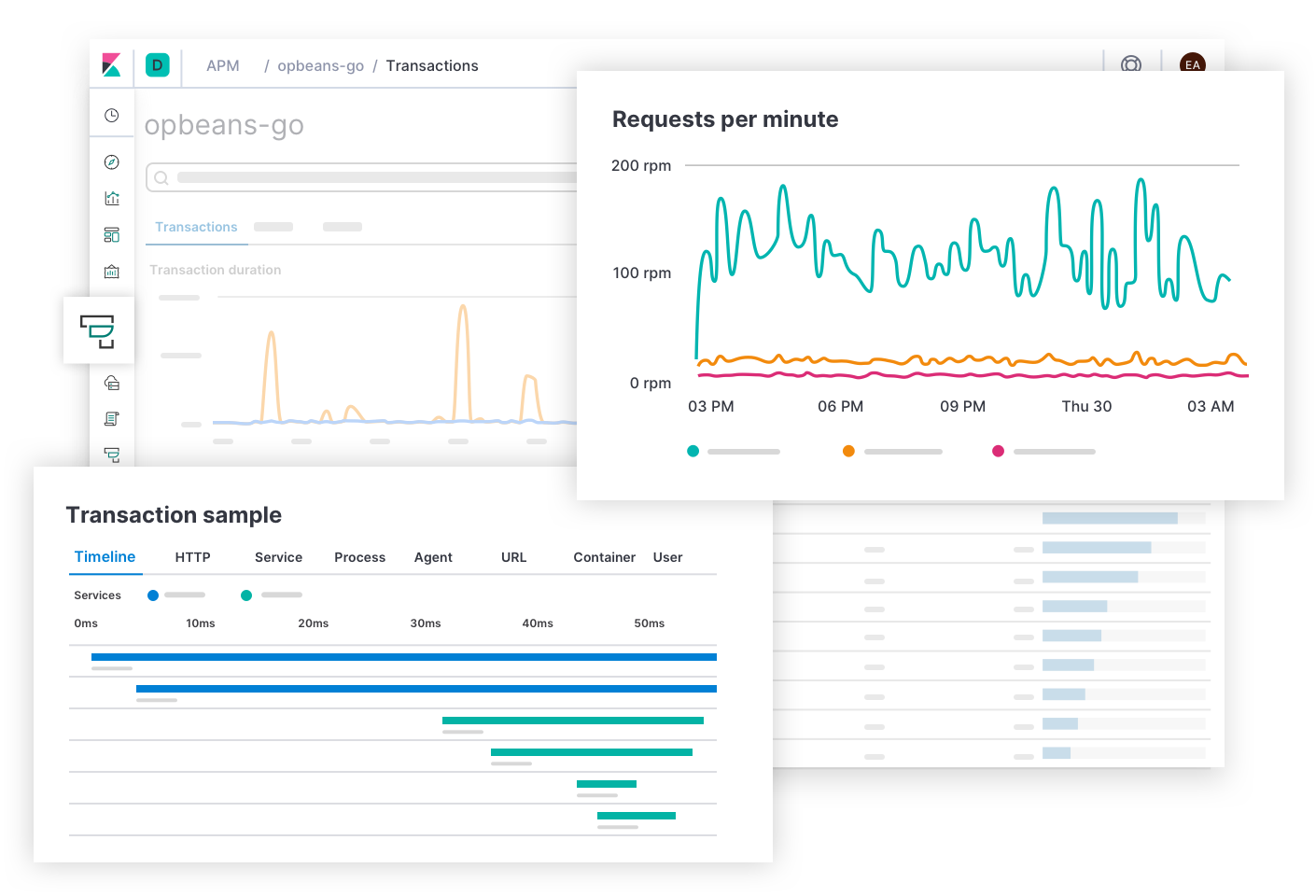
O Elastic APM responde a perguntas sobre a latência do serviço e os erros, como “Quais endpoints têm o maior impacto negativo na experiência do usuário? Quais spans estão causando lentidão nas transações? Como faço para rastrear as transações dos serviços distribuídos? Onde no código-fonte há erros? Como posso reproduzir um erro em um ambiente de desenvolvimento que corresponda ao ambiente de produção?” Alertas de SLOs de latência e erro podem levar o responsável pela resposta ao incidente a esta página. A experiência do APM fornece aos desenvolvedores de aplicações as informações de que eles precisam para encontrar, reproduzir e corrigir falhas. Os respondentes podem explorar a causa de qualquer latência navegando mais abaixo na stack para visualizar as métricas da infraestrutura de implantação de um serviço afetado.
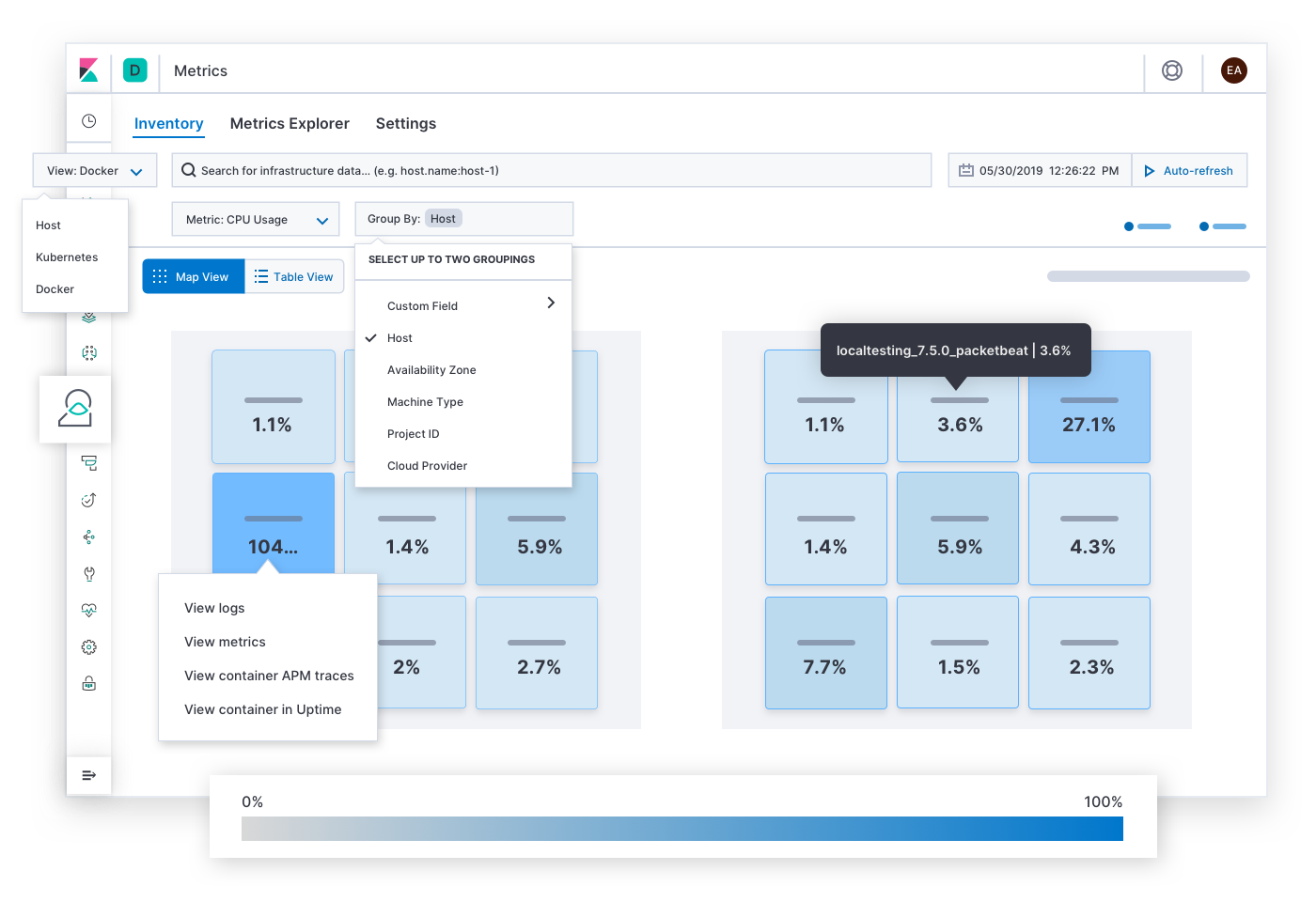
O Elastic Metrics responde a perguntas sobre saturação de recursos, como “Quais hosts, pods ou containers têm alto ou baixo consumo de memória? Armazenamento? Computação? Tráfego de rede? E se eu agrupá-los por provedor de serviços em nuvem, região geográfica, zona de disponibilidade ou algum outro valor?” Alertas de SLOs de saturação podem levar o responsável pela resposta ao incidente a esta página. Depois de encontrar sintomas de congestionamento, hot spots ou quedas de energia, o respondente pode expandir as métricas históricas e os logs da infraestrutura afetada ou fazer um detalhamento para explorar o comportamento dos serviços em execução neles.
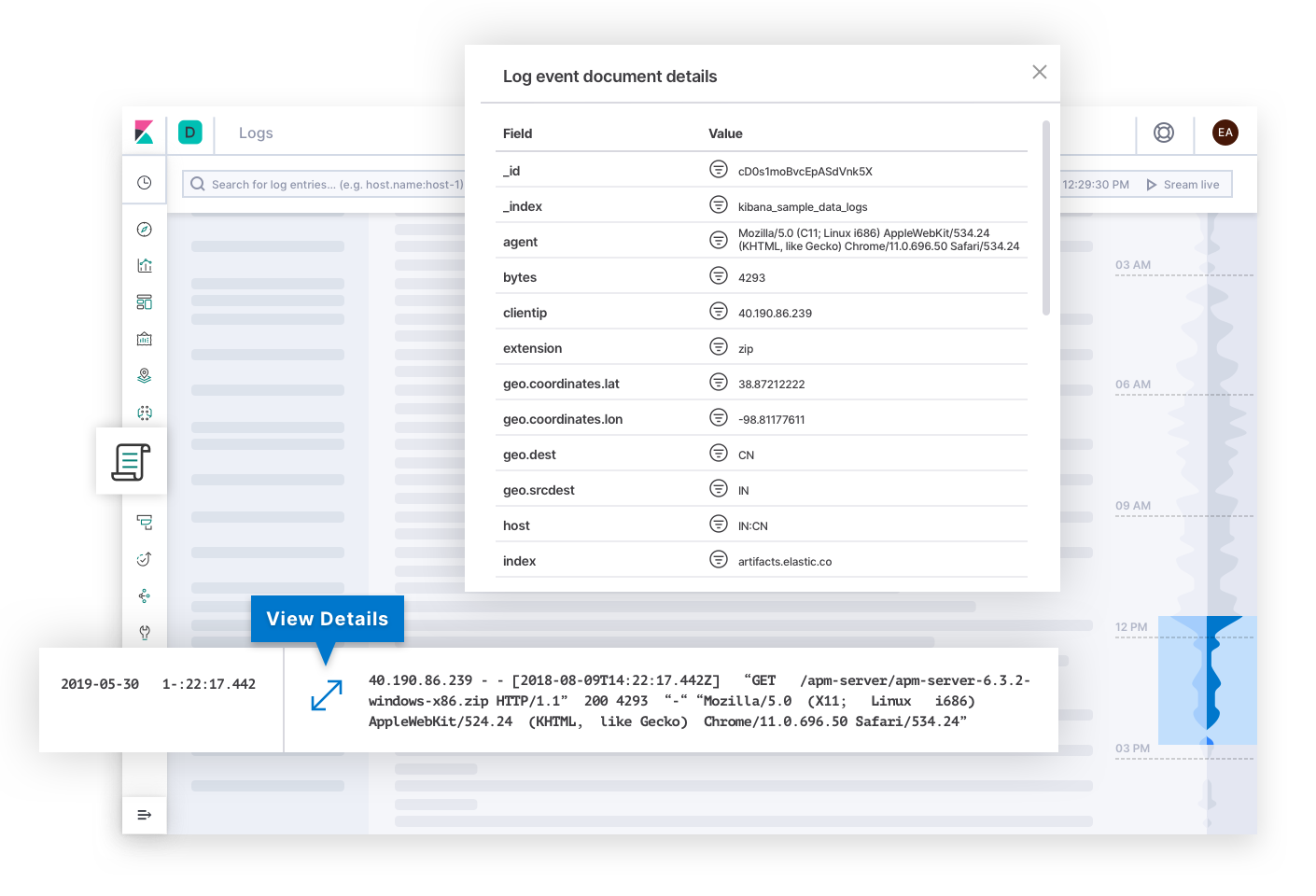
O Elastic Logs responde a perguntas sobre a fonte de fatos para eventos emitidos por sistemas e aplicações. Alertas sobre SLOs de qualidade ou correção podem levar o responsável pela resposta ao incidente a esta página. Os logs podem explicar a causa raiz da falha e se tornar o destino final da investigação. Ou podem explicar a causa de outros sintomas que acabem levando o respondente à causa raiz. Nos bastidores, a tecnologia pode categorizar os logs e descobrir tendências no texto para dar aos responsáveis pela resposta ao incidente sinais que podem explicar as alterações no estado de uma implantação.
Os engenheiros da Elastic desenvolveram uma experiência de busca de larga aplicação para observabilidade, graças à contribuição de milhares de clientes e membros da comunidade. Em última análise, os SREs são os especialistas em suas próprias implantações, e você pode imaginar uma experiência diferente que seja ideal para as necessidades exclusivas da sua operação. É por isso que você pode construir seus próprios dashboards e visualizações customizados usando quaisquer dados no Elastic e compartilhá-los com quem deve usá-los. É tão simples quanto arrastar e soltar.
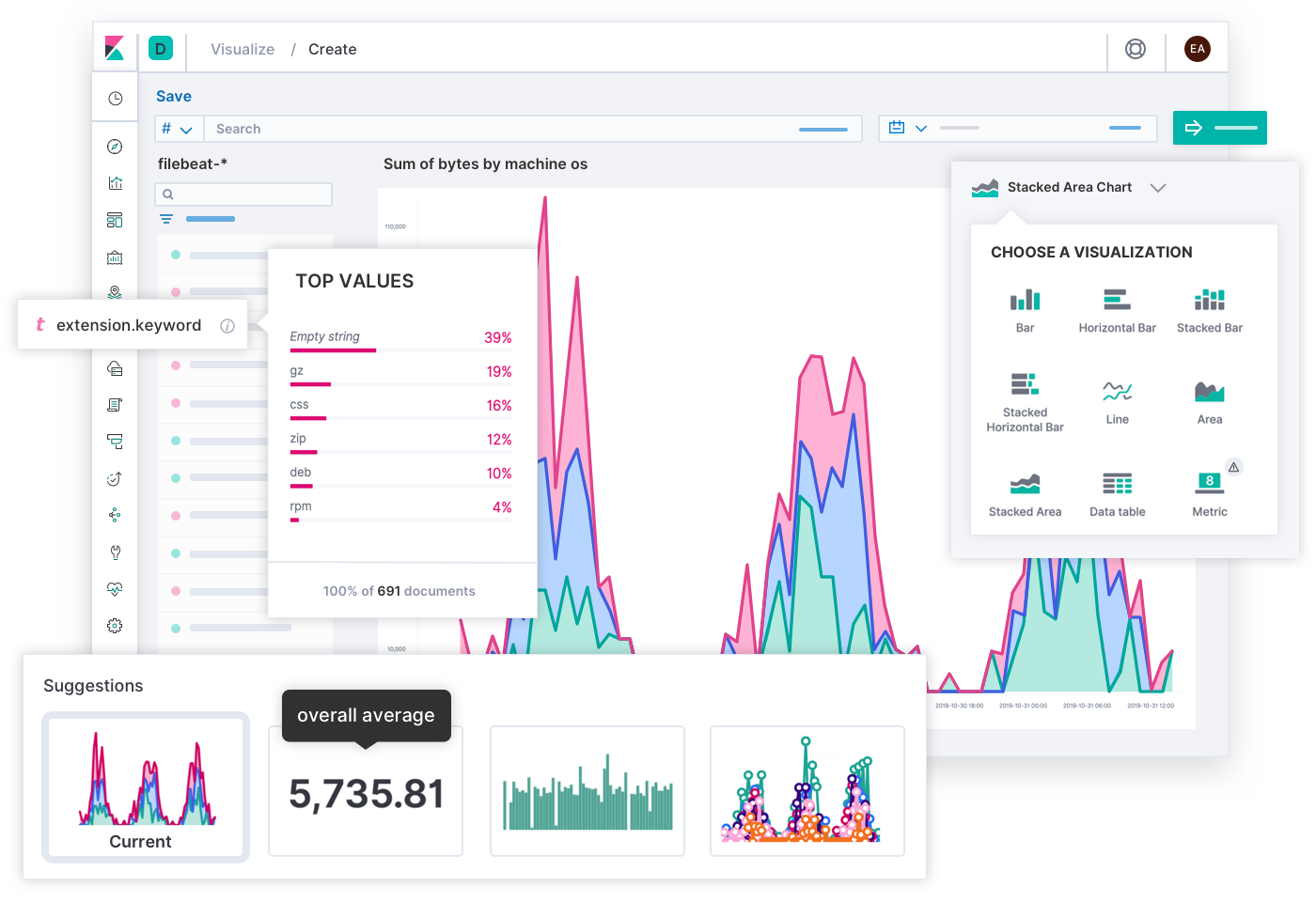
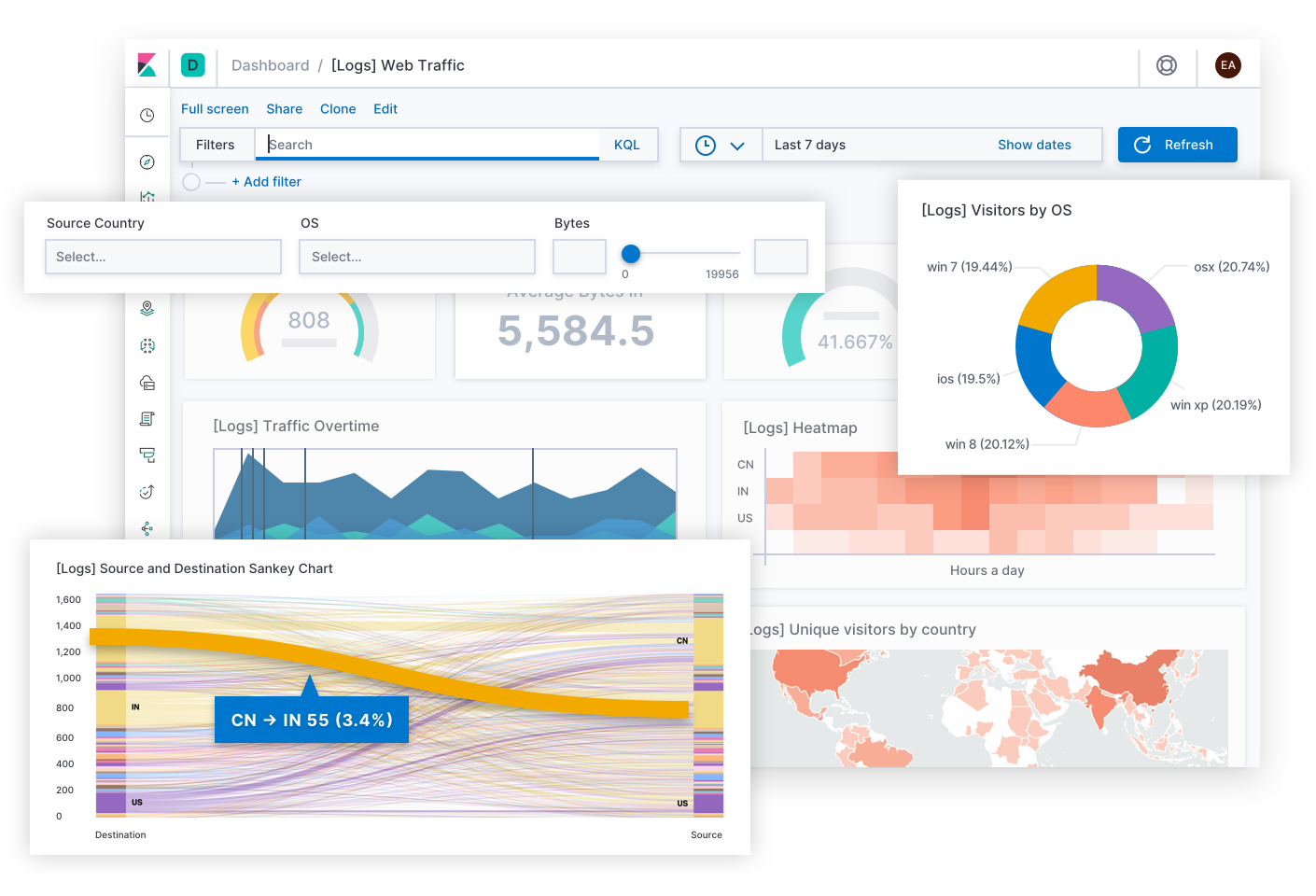
Indo além do trabalho diário, o Canvas é um meio criativo para expressar KPIs entre as equipes ou na cadeia de liderança. Pense neles como infográficos que contam histórias de negócios, em vez de dashboards que resolvem problemas técnicos. Quer melhor maneira de mostrar a experiência do usuário de hoje do que uma grade de SLOs disfarçados de carinhas felizes e tristes? Quer melhor maneira de explicar o orçamento de erros restante de hoje do que um banner que diz: “Você tem 12 minutos para testar o código em produção! (Por favor, não faça isso.)” Quando você conhece seu público, o Canvas permite que você enquadre uma situação complexa em uma história significativa que eles podem seguir.

Exemplos
Vamos ver alguns exemplos práticos do Elastic Observability. Cada cenário começa com um alerta para um SLI diferente, e cada um tem um caminho exclusivo para a resolução que pode envolver pessoas de equipes diferentes. A Elastic ajuda as equipes de resposta a incidentes a progredir em direção a uma resolução rápida em diversas circunstâncias.
Disponibilidade: por que o serviço está inativo?
A Elastic envia uma mensagem para a equipe disponível depois de detectar um serviço sem resposta que requer 99% de disponibilidade. Ramesh, da equipe de operações, assume o comando. Ele clica em um link para ver o histórico de tempo de atividade. Verifica que o agente de monitoramento está íntegro, portanto, é improvável que o alerta seja um falso positivo. Navega do serviço afetado para ver as métricas de seu host e, em seguida, agrupa as métricas por hosts e containers. Nenhum container no host está relatando métricas. “O problema deve estar em uma posição mais alta na stack.” Ele reagrupa os dados por zonas de disponibilidade e hosts. Outros hosts estão íntegros na zona afetada. Porém, quando ele filtra por hosts executando uma réplica do serviço afetado, os hosts não relatam nada. “Por que os hosts estão falhando apenas para este serviço?” Ele compartilha um link para o dashboard no canal #ops no Slack. Uma engenheira diz que recentemente atualizou o manual que configura os hosts que executam esse serviço. Ela reverte as alterações e, em seguida, as métricas começam a ser transmitidas para visualização. A fuga de dados é estancada. Eles resolveram o problema em 12 minutos — ainda dentro do SLA de 99%. Posteriormente, a engenheira analisará os logs do host para solucionar o motivo de suas alterações terem derrubado o host e, em seguida, fará uma alteração adequada.
Latência: por que o serviço está lento?
A Elastic cria um tíquete no sistema de controle de ocorrências após detectar uma latência anômala em vários serviços. Os desenvolvedores da aplicação fazem uma reunião para analisar amostras de traces a fim de encontrar spans que estejam contribuindo mais para a latência. Eles veem um padrão de latência para serviços que fazem interface com um serviço de validação de dados. Sandeep, o desenvolvedor responsável por esse serviço, investiga seus spans. Os spans estão relatando consultas de longa execução ao banco de dados, que são corroboradas por uma taxa de log anômala do slowlog. Ele inspeciona as consultas e as reproduz em um ambiente local. As declarações estavam juntando colunas não indexadas, que passaram despercebidas até que uma recente inserção em massa de dados causou uma desaceleração. Sua otimização da tabela melhora a latência do serviço, mas não para o SLO necessário. Ele muda sua investigação comparando a amostra de trace a uma versão anterior de seu serviço usando filtros contextuais. Existem novos spans processando os resultados da consulta. Ele segue o trace da stack em seu ambiente local até um método que avalia um conjunto de expressões regulares para cada resultado da consulta. Ajusta o código para pré-compilar os padrões antes do loop. Depois de confirmar suas alterações, as latências dos serviços retornam a seus SLOs. Sandeep marca o problema como resolvido.
Erros: por que o serviço está gerando erros?
Esther é uma desenvolvedora de software responsável pelo serviço de cadastro de contas de uma loja online. Ela recebe uma notificação do sistema de controle de ocorrências de sua equipe. A ocorrência informa que a Elastic detectou uma taxa de erro excessiva do serviço de cadastro em produção na região de Singapura, o que pode estar prejudicando novos negócios. Ela clica em um link na descrição da ocorrência que a leva a um grupo de erros de um “Erro de decodificação de Unicode” não manipulado no endpoint de envio do formulário. Abre uma amostra e encontra detalhes sobre o culpado, incluindo o nome do arquivo, a linha de código onde o erro foi lançado, o trace da stack, o contexto sobre o ambiente e até mesmo o hash de commit do código-fonte quando a aplicação foi compilada. Vê as entradas do formulário de cadastro com alguns dados redigidos para cumprir os regulamentos de privacidade. Observa que as entradas contêm caracteres Unicode vietnamitas. Reproduz o problema em sua máquina local usando todas essas informações. Depois de corrigir o manipulador de Unicode, ela confirma suas alterações. O pipeline de CI/CD executa seus testes, que obtêm aprovação e, então, ela implanta a aplicação atualizada em produção. Esther marca o problema como resolvido e continua com seu trabalho normal.
Saturação: onde a capacidade está prestes a ser preenchida?
A Elastic cria um tíquete no sistema de controle de ocorrências após detectar uma anomalia no uso de memória, listando a região da nuvem como um influenciador. Uma operadora clica em um link para ver o uso de memória regional ao longo do tempo. A região de Berlim mostra um pico repentino indicado por um ponto vermelho, após o qual o uso aumenta lentamente com o tempo. Ela prevê que a memória se esgotará em breve se isso continuar. Visualiza as métricas de memória recentes de todos os pods no mundo inteiro. Os pods em Berlim claramente se destacam como mais saturados do que em outras regiões. Ela restringe a busca agrupando pods por nome de serviço e filtrando por Berlim. Um serviço se destaca — o serviço de recomendação de produtos. Ela expande a busca para ver réplicas desse serviço em todo o mundo. Berlim mostra o maior uso de memória e o maior número de pods de réplica. Ela detalha as transações desse serviço em Berlim. Compartilha um link para esse dashboard com o desenvolvedor da aplicação responsável pelo serviço. O desenvolvedor lê o contexto das transações. Ele vê um rótulo customizado de uma flag de recurso que foi implementada apenas em Berlim para um teste A/B. Otimiza o serviço para realizar o carregamento lento em vez do carregamento rápido de um conjunto de dados que cresce com o tempo. O pipeline de CI/CD implanta seu serviço atualizado, o uso de memória retorna ao normal, e a operadora marca o problema como resolvido. Não há indicação de que esse problema tenha afetado os negócios, mas a previsão sugeria que teria afetado se eles não tivessem detectado o pico.
Estudos de caso
Não faltam histórias de sucesso para provar o valor do Elastic Observability. Um ótimo exemplo é a Verizon Communications, um conglomerado americano de telecomunicações e integrante do Dow Jones Industrial Average (DJIA). Em seu relatório anual de 2019 para a SEC, a Verizon listou “qualidade, capacidade e cobertura de rede” e “qualidade do atendimento ao cliente” entre os principais riscos competitivos para seus negócios. Durante aquele ano, 69,3% de sua receita total de 130,9 bilhões de dólares veio de seu segmento sem fio, fazendo negócios como Verizon Wireless. Uma equipe de operações de infraestrutura da Verizon Wireless afirmou que, ao substituir sua solução de monitoramento legada pela Elastic, eles “reduziram o MTTR de 20 a 30 minutos para 2 a 3 minutos”, o que “se traduz diretamente na prestação de um serviço excelente para seus clientes”. A confiabilidade do serviço, a resposta a incidentes e o Elastic Stack são fundamentais para o posicionamento competitivo dessa empresa e de outras que precisam fornecer um serviço confiável.
O que vem a seguir?
Aqui estão as etapas que você pode seguir para maximizar a confiabilidade e inspirar confiança em seus serviços de software: